结尾
学习html5、css、javascript这些基础知识,学习的渠道很多,就不多说了,例如,一些其他的优秀博客。但是本人觉得看书也很必要,可以节省很多时间,常见的javascript的书,例如:javascript的高级程序设计,是每位前端工程师必不可少的一本书,边看边用,了解js的一些基本知识,基本上很全面了,如果有时间可以读一些,js性能相关的书籍,以及设计者模式,在实践中都会用的到。
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
高级程序设计,是每位前端工程师必不可少的一本书,边看边用,了解js的一些基本知识,基本上很全面了,如果有时间可以读一些,js性能相关的书籍,以及设计者模式,在实践中都会用的到。
// example.js
var x = 5;
var addX = function (value) {
return value + x;
};
module.exports.x = x;
module.exports.addX = addX;
上面代码通过module.exports输出变量x和函数addX。
var example = require(‘./example.js’);//如果参数字符串以“./”开头,则表示加载的是一个位于相对路径
console.log(example.x); // 5
console.log(example.addX(1)); // 6
require命令用于加载模块文件。require命令的基本功能是,读入并执行一个JavaScript文件,然后返回该模块的exports对象。如果没有发现指定模块,会报错。
(4)模块的加载机制
CommonJS模块的加载机制是,输入的是被输出的值的拷贝。也就是说,一旦输出一个值,模块内部的变化就影响不到这个值。这点与ES6模块化有重大差异(下文会介绍),请看下面这个例子:
// lib.js
var counter = 3;
function incCounter() {
counter++;
}
module.exports = {
counter: counter,
incCounter: incCounter,
};
上面代码输出内部变量counter和改写这个变量的内部方法incCounter。
// main.js
var counter = require(‘./lib’).counter;
var incCounter = require(‘./lib’).incCounter;
console.log(counter); // 3
incCounter();
console.log(counter); // 3
上面代码说明,counter输出以后,lib.js模块内部的变化就影响不到counter了。这是因为counter是一个原始类型的值,会被缓存。除非写成一个函数,才能得到内部变动后的值。
(5)服务器端实现
①下载安装node.js
②创建项目结构
注意:用npm init 自动生成package.json时,package name(包名)不能有中文和大写|-modules|-module1.js|-module2.js|-module3.js|-app.js|-package.json{"name":"commonJS-node","version":"1.0.0"}
③下载第三方模块
npm install uniq--save// 用于数组去重
④定义模块代码
//module1.js
module.exports = {
msg: ‘module1’,
foo() {
console.log(this.msg)
}
}
//module2.js
module.exports = function() {
console.log(‘module2’)
}
//module3.js
exports.foo = function() {
console.log(‘foo() module3’)
}
exports.arr = [1, 2, 3, 3, 2]
// app.js文件
// 引入第三方库,应该放置在最前面
let uniq = require(‘uniq’)
let module1 = require(‘./modules/module1’)
let module2 = require(‘./modules/module2’)
let module3 = require(‘./modules/module3’)
module1.foo() //module1
module2() //module2
module3.foo() //foo() module3
console.log(uniq(module3.arr)) //[ 1, 2, 3 ]
⑤通过node运行app.js
命令行输入 node app.js,运行JS文件
(6)浏览器端实现(借助Browserify)
①创建项目结构
|-js|-dist//打包生成文件的目录|-src//源码所在的目录|-module1.js|-module2.js|-module3.js|-app.js//应用主源文件|-index.html//运行于浏览器上|-package.json{"name":"browserify-test","version":"1.0.0"}
②下载browserify
-
全局: npm install browserify -g
-
局部: npm install browserify --save-dev
③定义模块代码(同服务器端)
注意:index.html文件要运行在浏览器上,需要借助browserify将 app.js文件打包编译,如果直接在 index.html引入 app.js就会报错!
④打包处理js
根目录下运行 browserify js/src/app.js-o js/dist/bundle.js
⑤页面使用引入
在index.html文件中引入 <scripttype="text/javascript"src="js/dist/bundle.js"></script>
2.AMD
CommonJS规范加载模块是同步的,也就是说,只有加载完成,才能执行后面的操作。AMD规范则是非同步加载模块,允许指定回调函数。由于Node.js主要用于服务器编程,模块文件一般都已经存在于本地硬盘,所以加载起来比较快,不用考虑非同步加载的方式,所以CommonJS规范比较适用。但是,如果是浏览器环境,要从服务器端加载模块,这时就必须采用非同步模式,因此浏览器端一般采用AMD规范。此外AMD规范比CommonJS规范在浏览器端实现要来着早。
(1)AMD规范基本语法
定义暴露模块:
//定义没有依赖的模块
define(function(){
return 模块
})
//定义有依赖的模块
define([‘module1’, ‘module2’], function(m1, m2){
return 模块
})
引入使用模块:
require([‘module1’, ‘module2’], function(m1, m2){
使用m1/m2
})
(2)未使用AMD规范与使用require.js
通过比较两者的实现方法,来说明使用AMD规范的好处。
- 未使用AMD规范
// dataService.js文件
(function (window) {
let msg = ‘www.baidu.com’
function getMsg() {
return msg.toUpperCase()
}
window.dataService = {getMsg}
})(window)
// alerter.js文件
(function (window, dataService) {
let name = ‘Tom’
function showMsg() {
alert(dataService.getMsg() + ', ’ + name)
}
window.alerter = {showMsg}
})(window, dataService)
// main.js文件
(function (alerter) {
alerter.showMsg()
})(alerter)
// index.html文件
Modular Demo 1: 未使用AMD(require.js)
最后得到如下结果:

这种方式缺点很明显:首先会发送多个请求,其次引入的js文件顺序不能搞错,否则会报错!
- 使用require.js
RequireJS是一个工具库,主要用于客户端的模块管理。它的模块管理遵守AMD规范,RequireJS的基本思想是,通过define方法,将代码定义为模块;通过require方法,实现代码的模块加载。接下来介绍AMD规范在浏览器实现的步骤:
①下载require.js, 并引入
-
官网:
http://www.requirejs.cn/ -
github :
https://github.com/requirejs/requirejs
然后将require.js导入项目: js/libs/require.js
②创建项目结构
|-js|-libs|-require.js|-modules|-alerter.js|-dataService.js|-main.js|-index.html
③定义require.js的模块代码
// dataService.js文件
// 定义没有依赖的模块
define(function() {
let msg = ‘www.baidu.com’
function getMsg() {
return msg.toUpperCase()
}
return { getMsg } // 暴露模块
})
//alerter.js文件
// 定义有依赖的模块
define([‘dataService’], function(dataService) {
let name = ‘Tom’
function showMsg() {
alert(dataService.getMsg() + ', ’ + name)
}
// 暴露模块
return { showMsg }
})
// main.js文件
(function() {
require.config({
baseUrl: ‘js/’, //基本路径 出发点在根目录下
paths: {
//映射: 模块标识名: 路径
alerter: ‘./modules/alerter’, //此处不能写成alerter.js,会报错
dataService: ‘./modules/dataService’
}
})
require([‘alerter’], function(alerter) {
alerter.showMsg()
})
})()
// index.html文件
④页面引入require.js模块:
在index.html引入 <scriptdata-main="js/main"src="js/libs/require.js"></script>
**此外在项目中如何引入第三方库?**只需在上面代码的基础稍作修改:
// alerter.js文件
define([‘dataService’, ‘jquery’], function(dataService, $) {
let name = ‘Tom’
function showMsg() {
alert(dataService.getMsg() + ', ’ + name)
}
$(‘body’).css(‘background’, ‘green’)
// 暴露模块
return { showMsg }
})
// main.js文件
(function() {
require.config({
baseUrl: ‘js/’, //基本路径 出发点在根目录下
paths: {
//自定义模块
alerter: ‘./modules/alerter’, //此处不能写成alerter.js,会报错
dataService: ‘./modules/dataService’,
// 第三方库模块
jquery: ‘./libs/jquery-1.10.1’ //注意:写成jQuery会报错
}
})
require([‘alerter’], function(alerter) {
alerter.showMsg()
})
})()
上例是在alerter.js文件中引入jQuery第三方库,main.js文件也要有相应的路径配置。小结:通过两者的比较,可以得出AMD模块定义的方法非常清晰,不会污染全局环境,能够清楚地显示依赖关系。AMD模式可以用于浏览器环境,并且允许非同步加载模块,也可以根据需要动态加载模块。
3.CMD
CMD规范专门用于浏览器端,模块的加载是异步的,模块使用时才会加载执行。CMD规范整合了CommonJS和AMD规范的特点。在 Sea.js 中,所有 JavaScript 模块都遵循 CMD模块定义规范。
(1)CMD规范基本语法
定义暴露模块:
//定义没有依赖的模块
define(function(require, exports, module){
exports.xxx = value
module.exports = value
})
//定义有依赖的模块
define(function(require, exports, module){
//引入依赖模块(同步)
var module2 = require(‘./module2’)
//引入依赖模块(异步)
require.async(‘./module3’, function (m3) {
})
//暴露模块
exports.xxx = value
})
引入使用模块:
define(function (require) {
var m1 = require(‘./module1’)
var m4 = require(‘./module4’)
m1.show()
m4.show()
})
(2)sea.js简单使用教程
①下载sea.js, 并引入
-
官网: http://seajs.org/
-
github : https://github.com/seajs/seajs
然后将sea.js导入项目: js/libs/sea.js
②创建项目结构
|-js|-libs|-sea.js|-modules|-module1.js|-module2.js|-module3.js|-module4.js|-main.js|-index.html
③定义sea.js的模块代码
// module1.js文件
define(function (require, exports, module) {
//内部变量数据
var data = ‘atguigu.com’
//内部函数
function show() {
console.log('module1 show() ’ + data)
}
//向外暴露
exports.show = show
})
// module2.js文件
define(function (require, exports, module) {
module.exports = {
msg: ‘I Will Back’
}
})
// module3.js文件
define(function(require, exports, module) {
const API_KEY = ‘abc123’
exports.API_KEY = API_KEY
})
// module4.js文件
define(function (require, exports, module) {
//引入依赖模块(同步)
var module2 = require(‘./module2’)
function show() {
console.log('module4 show() ’ + module2.msg)
}
exports.show = show
//引入依赖模块(异步)
require.async(‘./module3’, function (m3) {
console.log('异步引入依赖模块3 ’ + m3.API_KEY)
})
})
// main.js文件
define(function (require) {
var m1 = require(‘./module1’)
var m4 = require(‘./module4’)
m1.show()
m4.show()
})
④在index.html中引入
最后得到结果如下:

4.ES6模块化
ES6 模块的设计思想是尽量的静态化,使得编译时就能确定模块的依赖关系,以及输入和输出的变量。CommonJS 和 AMD 模块,都只能在运行时确定这些东西。比如,CommonJS 模块就是对象,输入时必须查找对象属性。
(1)ES6模块化语法
export命令用于规定模块的对外接口,import命令用于输入其他模块提供的功能。
/** 定义模块 math.js **/
var basicNum = 0;
var add = function (a, b) {
return a + b;
};
export { basicNum, add };
/** 引用模块 **/
import { basicNum, add } from ‘./math’;
function test(ele) {
ele.textContent = add(99 + basicNum);
}
如上例所示,使用import命令的时候,用户需要知道所要加载的变量名或函数名,否则无法加载。为了给用户提供方便,让他们不用阅读文档就能加载模块,就要用到export default命令,为模块指定默认输出。
// export-default.js
export default function () {
console.log(‘foo’);
}
// import-default.js
import customName from ‘./export-default’;
customName(); // ‘foo’
模块默认输出, 其他模块加载该模块时,import命令可以为该匿名函数指定任意名字。
(2)ES6 模块与 CommonJS 模块的差异
它们有两个重大差异:
① CommonJS 模块输出的是一个值的拷贝,ES6 模块输出的是值的引用。
② CommonJS 模块是运行时加载,ES6 模块是编译时输出接口。
第二个差异是因为 CommonJS 加载的是一个对象(即module.exports属性),该对象只有在脚本运行完才会生成。而 ES6 模块不是对象,它的对外接口只是一种静态定义,在代码静态解析阶段就会生成。
下面重点解释第一个差异,我们还是举上面那个CommonJS模块的加载机制例子:
// lib.js
export let counter = 3;
export function incCounter() {
counter++;
}
// main.js
import { counter, incCounter } from ‘./lib’;
console.log(counter); // 3
总结
三套“算法宝典”
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
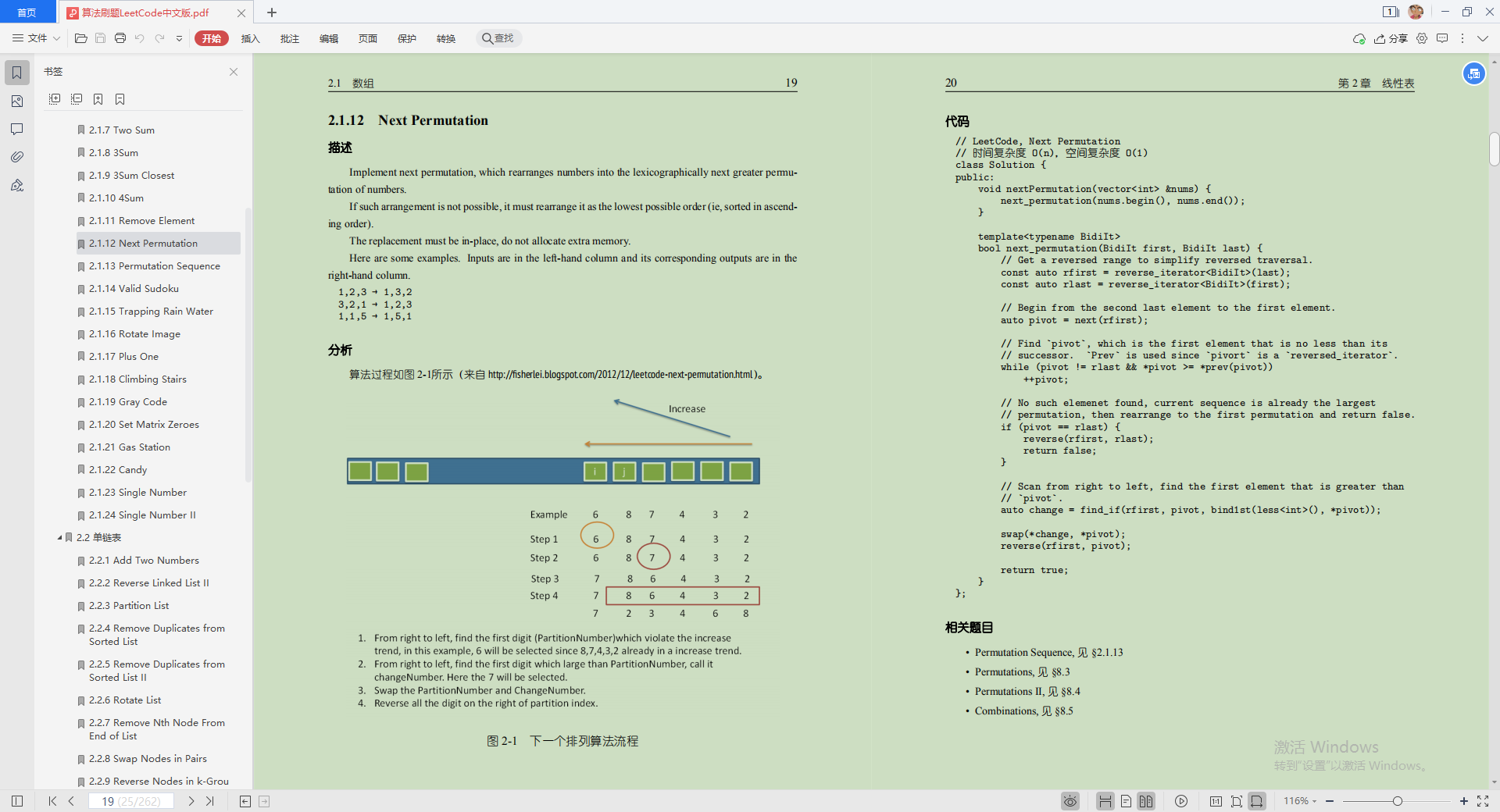
算法刷题LeetCode中文版(为例)
人与人存在很大的不同,我们都拥有各自的目标,在一线城市漂泊的我偶尔也会羡慕在老家踏踏实实开开心心养老的人,但是我深刻知道自己想要的是一年比一年有进步。
最后,我想说的是,无论你现在什么年龄,位于什么城市,拥有什么背景或学历,跟你比较的人永远都是你自己,所以明年的你看看与今年的你是否有差距,不想做咸鱼的人,只能用尽全力去跳跃。祝愿,明年的你会更好!