微调Llama3-Chinese-8B-Instruct
微调是指在大规模预训练的基础模型上,使用特定领域或任务数据集进行少量迭代训练,以调整模型参数,提升其在特定任务上的表现。这种方法可以充分利用预训练模型的广泛知识,同时针对特定应用进行优化,达到更精准高效的效果。
Llama-3-Chinese-8B-Instruct
Llama-2已经表现的很出色了,但其仅使用了2万亿Token进行训练。相比之下,Llama-3使用了高达15万亿Token进行训练,这必将大幅提升其实力,令人高度期待。
Llama-3-Chinese-Instruct是基于Meta Llama-3的中文开源大模型,其在原版Llama-3的基础上使用了大规模中文数据进行增量预训练,并且使用精选指令数据进行精调,进一步提升了中文基础语义和指令理解能力,相比二代相关模型获得了显著性能提升。
GitHub:https://github.com/ymcui/Chinese-LLaMA-Alpaca-3
Unsloth
Unsloth是一个开源的大模型训练加速项目,可以显著提升大模型的训练速度(提高2-5 倍),减少显存占用(最大减少80%)
特点如下:
所有内核均采用OpenAI 的Triton语言编写
模型训练的精度损失为零
支持绝大多数主流的GPU设备
支持对LoRA和QLoRA的训练加速和高效显存管理
支持Flash Attention加速
开源训练速度最高达5倍,Unsloth Pro最高达30倍的训练速度
Unsloth与HuggingFace生态兼容,可以很容易将其与transformers、peft、trl等代码库进行结合
GitHub:https://github.com/unslothai/unsloth
文档:https://github.com/unslothai/unsloth/wiki
环境设置
创建虚拟环境
conda create --name unsloth_env python=3.10
conda activate unsloth_env
安装相关依赖
!pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
!pip install --no-deps "xformers<0.0.26" trl peft accelerate bitsandbytes
!pip install modelscope
下载预训练模型
支持的预置4位量化模型,可实现4倍更快的下载速度和无OOM。更多模型请查看https://huggingface.co/unsloth
fourbit_models = [
"unsloth/mistral-7b-bnb-4bit",
"unsloth/mistral-7b-instruct-v0.2-bnb-4bit",
"unsloth/llama-2-7b-bnb-4bit",
"unsloth/gemma-7b-bnb-4bit",
"unsloth/gemma-7b-it-bnb-4bit", # Gemma 7b的Instruct版本
"unsloth/gemma-2b-bnb-4bit",
"unsloth/gemma-2b-it-bnb-4bit", # Gemma 2b的Instruct版本
"unsloth/llama-3-8b-bnb-4bit", # 15万亿令牌的Llama-3
]
这里不使用预置4位量化模型,使用modelscope下载Llama3-Chinese-8B-Instruct中文开源大模型
from modelscope import snapshot_download
model_dir = snapshot_download('FlagAlpha/Llama3-Chinese-8B-Instruct',cache_dir="/root/models")
加载model、tokenizer
from unsloth import FastLanguageModel
import torch
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "/root/models/Llama3-Chinese-8B-Instruct", # 模型路径
max_seq_length = 2048, # 可以设置为任何值内部做了自适应处理
dtype = torch.float16, # 数据类型使用float16
load_in_4bit = True, # 使用4bit量化来减少内存使用
)
设置LoRA训练参数
LoRA (Low-Rank Adaptation)是一种大语言模型的低阶适配器技术,可在模型微调过程中,只更新整个模型参数的1%到10%左右,而不是全部参数。通过这种方式实现有效的模型微调和优化,提高了模型在特定任务上的性能。
model = FastLanguageModel.get_peft_model(
model,
r = 16, # 选择任何大于0的数字!建议使用8、16、32、64、128
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0, # 支持任何值,但等于0时经过优化
bias = "none", # 支持任何值,但等于"none"时经过优化
# [NEW] "unsloth" 使用的VRAM减少30%,适用于2倍更大的批处理大小!
use_gradient_checkpointing = "unsloth", # True或"unsloth"适用于非常长的上下文
random_state = 3407,
use_rslora = False, # 支持排名稳定的LoRA
loftq_config = None, # 和LoftQ
)
准备数据集
准备数据集其实就是指令集构建,LLM的微调一般指指令微调过程。所谓指令微调,就是使用指定的微调数据格式、形式。
训练目标是让模型具有理解并遵循用户指令的能力。因此在指令集构建时,应该针对目标任务,针对性的构建任务指令集。
这里使用alpaca格式的数据集,格式形式如下:
[
{
"instruction": "用户指令(必填)",
"input": "用户输入(选填)",
"output": "模型回答(必填)",
},
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
]
instruction:用户指令,要求AI执行的任务或问题
input:用户输入,是完成用户指令所必须的输入内容,就是执行指令所需的具体信息或上下文
output:模型回答,根据给定的指令和输入生成答案
这里根据企业私有文档数据,生成相关格式的训练数据集,大概格式如下:
[
{
"instruction": "内退条件是什么?",
"input": "",
"output": "内退条件包括与公司签订正式劳动合同并连续工作满20年及以上,以及距离法定退休年龄不足5年。特殊工种符合国家相关规定可提前退休的也可在退休前5年内提出内退申请。"
},
]
数据处理
定义对数据处理的函数方法
alpaca_prompt = """下面是一项描述任务的说明,配有提供进一步背景信息的输入。写出一个适当完成请求的回应。
### Instruction:
{}
### Input:
{}
### Response:
{}"""
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
instructions = examples["instruction"]
inputs = examples["input"]
outputs = examples["output"]
texts = []
for instruction, input, output in zip(instructions, inputs, outputs):
# Must add EOS_TOKEN, otherwise your generation will go on forever!
text = alpaca_prompt.format(instruction, input, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }
pass
加载数据集并进行映射处理操作
from datasets import load_dataset
dataset = load_dataset("json", data_files="./train.json", split = "train")
dataset = dataset.map(formatting_prompts_func, batched = True,)
print(dataset[0])
经处理后的一条数据格式如下:
{'output': '输出内容',
'input': '',
'instruction': '指令内容',
'text': '下面是一项描述任务的说明,配有提供进一步背景信息的输入。写出一个适当完成请求的回应。\n\n### Instruction:\n指令内容?\n\n### Input:\n\n\n### Response:\n输出内容。<|end_of_text|>'
}
训练超参数配置
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir = "models/lora/llama", # 输出目录
per_device_train_batch_size = 2, # 每个设备的训练批量大小
gradient_accumulation_steps = 4, # 梯度累积步数
warmup_steps = 5,
max_steps = 60, # 最大训练步数,测试时设置
# num_train_epochs= 5, # 训练轮数
logging_steps = 10, # 日志记录频率
save_strategy = "steps", # 模型保存策略
save_steps = 100, # 模型保存步数
learning_rate = 2e-4, # 学习率
fp16 = not torch.cuda.is_bf16_supported(), # 是否使用float16训练
bf16 = torch.cuda.is_bf16_supported(), # 是否使用bfloat16训练
optim = "adamw_8bit", # 优化器
weight_decay = 0.01, # 正则化技术,通过在损失函数中添加一个正则化项来减小权重的大小
lr_scheduler_type = "linear", # 学习率衰减策略
seed = 3407, # 随机种子
)
开始训练
trainer = SFTTrainer(
model=model, # 模型
tokenizer=tokenizer, # 分词器
args=training_args, # 训练参数
train_dataset=dataset, # 训练数据集
dataset_text_field="text", # 数据集文本字段名称
max_seq_length=2048, # 最大序列长度
dataset_num_proc=2, # 数据集处理进程数
packing=False, # 可以让短序列的训练速度提高5倍
)
显示当前内存状态
# 当前GPU信息
gpu_stats = torch.cuda.get_device_properties(0)
# 当前模型内存占用
start_gpu_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
# GPU最大内存
max_memory = round(gpu_stats.total_memory / 1024 / 1024 / 1024, 3)
print(f"GPU = {gpu_stats.name}. Max memory = {max_memory} GB.")
print(f"{start_gpu_memory} GB of memory reserved.")
可以看出当前模型占用5.633G显存

执行训练
trainer_stats = trainer.train()

显示最终内存和时间统计数据
# 计算总的GPU使用内存(单位:GB)
used_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
# 计算LoRA模型使用的GPU内存(单位:GB)
used_memory_for_lora = round(used_memory - start_gpu_memory, 3)
# 计算总的GPU内存使用百分比
used_percentage = round(used_memory / max_memory * 100, 3)
# 计算LoRA模型的GPU内存使用百分比
lora_percentage = round(used_memory_for_lora / max_memory * 100, 3)
print(f"{trainer_stats.metrics['train_runtime']} seconds used for training.")
print(f"{round(trainer_stats.metrics['train_runtime'] / 60, 2)} minutes used for training.")
print(f"Peak reserved memory = {used_memory} GB.")
print(f"Peak reserved memory for training = {used_memory_for_lora} GB.")
print(f"Peak reserved memory % of max memory = {used_percentage} %.")
print(f"Peak reserved memory for training % of max memory = {lora_percentage} %.")
可以看出模型训练时显存增加了0.732G
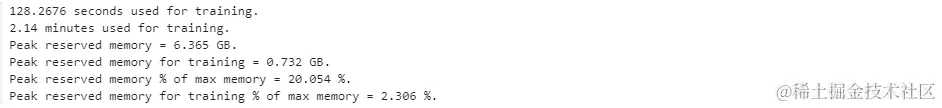
模型推理
FastLanguageModel.for_inference(model) # 启用原生推理速度快2倍
inputs = tokenizer(
[
alpaca_prompt.format(
"内退条件是什么?", # instruction
"", # input
"", # output
)
], return_tensors = "pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens = 64, use_cache = True)
tokenizer.batch_decode(outputs)
可以看出模型回答跟训练数据集中的数据意思基本一致。

保存LoRA模型
注意:这仅保存 LoRA 适配器,而不是完整模型
lora_model="models/llama_lora"
model.save_pretrained(lora_model)
tokenizer.save_pretrained(lora_model)
# 保存到huggingface
# model.push_to_hub("your_name/lora_model", token = "...")
# tokenizer.push_to_hub("your_name/lora_model", token = "...")

加载模型
注意:从新加载模型将额外占用显存,若GPU显存不足,需关闭、清除先前加载、训练模型的内存占用
加载刚保存的LoRA适配器用于推断,他将自动加载整个模型及LoRA适配器。adapter_config.json定义了完整模型的路径。
import torch
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "models/llama_lora",
max_seq_length = 2048,
dtype = torch.float16,
load_in_4bit = True,
)
FastLanguageModel.for_inference(model)
执行推理
alpaca_prompt = """
下面是一项描述任务的说明,配有提供进一步背景信息的输入。写出一个适当完成请求的回应。
### Instruction:
{}
### Input:
{}
### Response:
{}
"""
inputs = tokenizer(
[
alpaca_prompt.format(
"内退条件是什么?", # instruction
"", # input
"", # output
)
], return_tensors = "pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens = 64, use_cache = True)
tokenizer.batch_decode(outputs)
保存完整模型
# 合并到16bit 保存到本地 OR huggingface
model.save_pretrained_merged("models/Llama3", tokenizer, save_method = "merged_16bit",)
model.push_to_hub_merged("hf/model", tokenizer, save_method = "merged_16bit", token = "")
# 合并到4bit 保存到本地 OR huggingface
model.save_pretrained_merged("models/Llama3", tokenizer, save_method = "merged_4bit",)
model.push_to_hub_merged("hf/model", tokenizer, save_method = "merged_4bit", token = "")
这里合并到16bit
保存为GGUF格式
将模型保存为GGUF格式
# 保存到 16bit GGUF 体积大
model.save_pretrained_gguf("model", tokenizer, quantization_method = "f16")
model.push_to_hub_gguf("hf/model", tokenizer, quantization_method = "f16", token = "")
# 保存到 8bit Q8_0 体积适中
model.save_pretrained_gguf("model", tokenizer,)
model.push_to_hub_gguf("hf/model", tokenizer, token = "")
# 保存到 q4_k_m GGUF 体积小
model.save_pretrained_gguf("model", tokenizer, quantization_method = "q4_k_m")
model.push_to_hub_gguf("hf/model", tokenizer, quantization_method = "q4_k_m", token = "")
在执行转换过程中遇到如下问题
RuntimeError: Unsloth: Quantization failed! You might have to compile llama.cpp yourself, then run this again.
You do not need to close this Python program. Run the following commands in a new terminal:
You must run this in the same folder as you're saving your model.
git clone --recursive https://github.com/ggerganov/llama.cpp
cd llama.cpp && make clean && make all -j
Once that's done, redo the quantization.
安装提示编译llama.cpp
git clone --recursive https://github.com/ggerganov/llama.cpp
cd llama.cpp && make clean && make all -j
发现任然出现上述错误,截止目前,经查证,官方项目确实存在该Bug。因此使用手动方式进行转换操作。
参考:[llama.cpp 转换、量化和合并]
!python ./models/llama.cpp/convert.py ./models/Llama3 --outtype f16 --vocab-type bpe --outfile ./models/Llama3-FP16.gguf


如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
