


目录
1. start()
(1) start() 的性质
之前我们已经讲过了,如何通过覆写 run() 方法,创建一个线程对象;但线程对象被创建出来,并不意味着线程就开始运行了。
- 覆写 run() 方法是提供给线程要做的事情的指令清单
- 线程对象可以认为是把李四、王五叫过来了
- 而调用 start()方法,就是喊一声:”行动起来!“,线程才真正独立去执行了。
start() 是Java 标准库/JVM 提供的方法,本质上是调用操作系统的API

- 在 idea 中查看 start() 的原码,发现关键部分被关键字 native 修饰;
- 被native这个关键字,修饰的方法,称为本地方法。

补充:
run() 是线程的入口方法,通过 JVM 自行调用,不需要手动调用;start() 是调用操作系统的 API.
(2) start() 和 Thread类 的关系
- 在 Java中,Thread 对象和操作系统中的线程 — — 对应;
- 每个 Thread对象,都只能调用一次 start() 来创建线程;
- 如果想创建多线程,就必须创建新的Thread 对象;
答: 他们属于是两个不同的输出流,没办法保证输出的顺序。
2. 终止一个线程
如何终止一个线程:
- 通过共享的标记来进行沟通
- 调用interrupt()方法来通知
(1)通过共享的标记结束线程
1. 通过共享的标记结束线程
想要终止一个线程,就是让线程中的入口方法return ,进而使得线程终止。
来看如下代码:

该代码的逻辑为:
让 t 线程执行死循环的打印,现在,我们要修改一下这个代码中的循环终止条件,以结束 t 线程.
为了避免编译器优化而出现 bug ,需要用 volatile 关键字修饰 标志位 (成员变量);
(这个关键字的功能后面介绍)。

程序运行结果:

所以让线程结束的关键,就是让线程中的入口方法 run() 能够被返回。
2. 关于 lamda 表达式的“变量捕获”
在上面的代码中还有一个小细节,我们在while的循环判断条件中,引入了一个变量;
引入的变量,是以成员变量的方式,定义这个变量的。
如果把这个变量定义成局部变量,把 isfinish 放入 main 方法中,是否可以实现刚刚的逻辑呢?



如果对于局部变量 isFinish 不做任何后续修改,那么这个变量是允许被 lamda 捕获的:

补充:
lamda 表达式“变量捕获”的语法,如果针对的对象类型,是引用类型,只要这个引用指向的对象不改变,哪怕这个对象的值被修改,这个引用类型的变量也是允许被 lamda 捕获的。

因为引用类型的局部变量,和引用类型指向的对象本体 的生命周期是不同的;
所以 lamda 的“变量捕获”语法的核心问题,还是成员变量和局部变量的生命周期问题:

对于上图 7 8 点的补充:
- 内部类可以访问外部类的成员,这样的语法不是变量捕获,自然不受到final 或者不能修改变量的限制
- 这里面的差别在于,如果写成局部变量,其生命周期,是跟着当前执行的方法,也就是mian方法走的。
- 就可能会出现,回调函数一执行,发现main方法已经结束;main方法结束,成员变量因此被销毁,所以无法在回调函数中访问到该变量,所以要去拷贝一份
- 但是一拷贝,就会出现,拷贝的新变量,和被拷贝的变量的值,可能会在修改中出现不一致,所以Java才强制限制该变量不能修改
- 而如果是成员变量的话,他的生命周期是让GC来管理的,在lamda中,不用担心访问的变量生命周期失效的问题。对应的,也就不必拷贝,也就不必限制 final 类
(2) 调用interrupt()方法
Java 的 Thread 对象中提供了现成的变量,直接进行判定,不需要自己创建了.
Thread.interrupted() 或者 Thread.currentThread().isInterrupted() 代替自定义标志位;
Thread 内部,包含了一个boolean类型的变量,作为线程是否被中断的标记.
1. isInterrupted()
| 方法 | 说明 |
| public boolean isInterrupted() | 判断对象关联的线程的标志位是否设置,调用后不清除标志位 |
isInterrupted() 方法,是用于判断当前调用该方法的线程是否终止,返回值为 true / false;
通过 线程对象引用.isInterrupted() 来代替自定义标志位 isFinished:
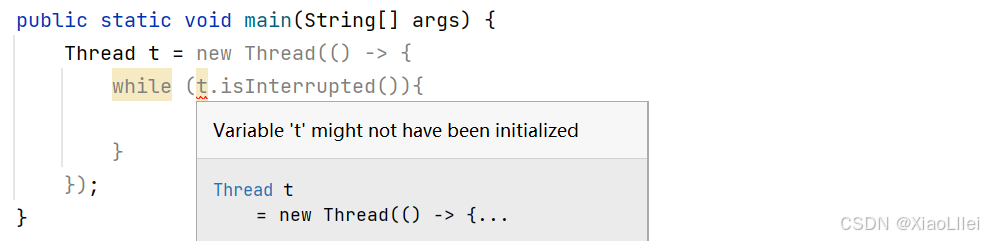
报错原因:
- 因为 lamda 表达式的定义虽然写在实例对象 new Thread 之后,但是lamda 的定义顺序在 new Thread 之前;
- 也就是 lamda 的定义顺序 ,先于声明 Thread t 的顺序,导致 lamda 表达式无法识别 t。
2. currentThread()
- currentThread() 的作用:返回当前线程对象的引用
-
- currentThread() 被 native 修饰 ,是本地方法;
- 同时也被 static 修饰,静态方法的调用不需要实例化对象,只需要通过类名就可以进行调用;
- 所以在哪个线程调用 currentThread() ,获取到的就是哪个线程的 Thread 引用。

对于下图中的代码,是在 lambda 中 (也就是在 t 线程 的入口方法中) 调用的 currentThread();
Thread.currentThread() 的返回结果就是t :

补充:
在while的循环判断条件中,返回的是Thread类的成员;
注意:
String类的成员,不能通过 引用. 成员 这种写法来访问 String类 中的成员
同理,currentThread() 在 main 方法中调用;
此时 Thread.currentThread() 返回结果就是 主线程 main


3. interrupt()
| 方法 | 说明 |
| public void interrupt() | 中断对象关联的线程,如果线程正在阻塞,则以异常方 式通知,否则设置标志位 |
| public static boolean interrupted() | 判断当前线程的中断标志位是否设置,调用后清除标志位 |
interrupt() 方法,除了设置 boolean变量(标志位)之外,还能够唤醒像 sleep 这样的阻塞方法。
我们来看下面代码的逻辑:
让 t 线程 执行3s 的打印后,main 线程执行 t.interrupt() 终止 t 线程

执行结果:

抛出异常的原因:

使用 thread 对象的 interrupted() 方法,通知线程结束,thread 收到通知的方式有两种:
1. 如果线程因为调用 wait / join / sleep 等方法而阻塞挂起,则以 InterruptedException 异常的形式通知,清除中断标志。
- 当出现 InterruptedException 的时候,要不要结束线程取决于catch 中代码的写法.可以选择忽略这个异常,也可以跳出循环结束线程(把 catch 代码块中的抛出异常,直接改成break);
2. 否则,只是内部的一个中断标志被设置,thread 可以通过
- Thread.interrupted() 判断当前线程的中断标志被设置,清除中断标志;
- Thread.currentThread().isInterrupted() 判断指定线程的中断标志被设置,不清除中断标志;
这种方式通知收到的更及时,即使线程正在sleep 也可以马上收到。
第二种终止线程的方法的总结:

3. join()
| 方法 | 说明 |
| public void join() | 等待线程结束 |
| public void join(long millis) | 等待线程结束,最多等 millis 毫秒 |
| public void join(long millis, int nanos) | 同理,但可以更高精度 |
使用方法:

从最终的执行结果中,三个打印日志的顺序,我们可以得到以上的代码的执行逻辑 :
- 让 t1 线程在创建好后,执行其中的 run() 方法;
- 此时会 先打印第一个日志,然后 t1线程 执行 join() ,表示 t1 要阻塞等待主线程执行完毕,才可以继续执行;
- 而主线程要执行的,就是休眠 3s 后,打印 主线程结束的日志;
- 主线程结束后,t1 线程的 join() 执行完毕,打印 t1线程的结束日志
通过代码逻辑,我们可以明白 join() 的用法 :
- 如图中的代码,是在 t1 线程中,执行 主线程对象的引用 所调用的 join() 方法,表示让 t1 线程 先等待 主线程 结束,t1 中的 join() 才执行完毕,才可以执行后续 t1 的内容。
总结:
- 在 线程A 中,执行 线程B 对象的引用所调用的 join(),表示让 线程A 阻塞等待 线程B执行完毕;
- 如果不给 join() 传参数,则是无止境地等待 线程B 执行直到结束;
- 传参数则 线程A 会阻塞等待 线程B 执行到一定的时间,会恢复两个线程并发执行的状态。
4. sleep()
sleep() 是我们熟悉的一组方法,有一点要记得:
因为线程的调度是不可控的,所以,这个方法只能保证实际休眠时间是大于等于参数设置的休眠时间的。
| 方法 | 说明 |
| public static void sleep(long millis) throws InterruptedException | 休眠当前线程 millis 毫秒 |
| public static void sleep(long millis, int nanos) throws InterruptedException | 可以更高精度的休眠 |

5. Java中线程生命周期的定义
(1) 线程状态
在Java 中,线程的生命周期可以细化为以下几个状态:
| 状态 | 说明 |
| New(初始状态) | 线程对象创建后,但未调用start() 方法。 |
| Runnable(可运行状态) | 调用start()方法后,线程进入就绪状态,等待CPU 调度。 |
| Blocked(阻塞状态) | 线程试图获取一个对象锁而被阻塞。 |
| Waiting(等待状态) | 线程进入等待状态,需要被显式唤醒才能继续执行。 |
| Timed Waiting(含等待时间的等待状态) | 线程进入等待状态,但指定了等待时间,超时后会被唤醒。 |
| Terminated(终止状态) | 线程执行完成或因异常退出 |
(2) 线程状态转移


(3) 操作系统中线程的生命周期:
- 操作系统中线程的生命周期通常包括以下五个阶段
状态 说明 新建(New) 线程对象被创建,但尚未启动。
就绪(Runnable) 线程被启动,处于可运行状态,等待CPU调度执行。
运行(Running) 线程获得CPU资源,开始执行run()方法中的代码。
阻塞(Blocked) 线程因为某些操作(如等待锁、I/O操作)被阻塞,暂时停止执行。
终止(Terminated) 线程执行完成或因异常退出,生命周期结束。

