Domain Generalization Via Aggregation and Separation for Audio Deepfake Detection
IEEE Transactions on Information Forensics and Security
- 影响因子:6.3
- JCR2区,中科院1区(TOP)
通过聚合和分离进行音频深度伪造检测的领域泛化
摘要
本文提出了一种用于音频深度伪造检测( ADD )的聚合分离域泛化( ASDG )方法。不同方法产生的虚假语音表现出不同的幅频响应,而不是真实语音。此外,训练集中的欺骗攻击可能跟不上现实世界深度伪造分布不断变化的多样性。鉴于此,我们试图学习一个理想的特征空间,能够聚合真实语音并分离虚假语音,以实现在未见到的目标域检测中更好的泛化性。具体来说,我们首先提出了一种基于轻量级卷积神经网络( LCNN )的特征生成器,用于生成特征空间并将特征分类为真假。同时,利用单边域对抗学习使得只有来自不同域的真实语音不可区分,从而使得真实语音在特征空间中的分布得以聚合。进一步地,在聚合真实语音分布的同时,采用三元组损失分离虚假语音的分布。最后,为了检验模型的可推广性,我们用3个不同的英文数据集进行训练,并在跨语言和噪声数据集的苛刻条件下进行评估。大量实验表明,ASDG在跨域任务中优于基准模型,与RawNet2相比,等错误率( Equal Error Rate,EER )最高降低了39.24 %。证明了所提出的聚合分离域泛化方法可以作为提高模型泛化能力的有效策略。
结论
- 在本文中,我们介绍了一种聚合和分离的领域泛化(ASDG)方法,并将其应用到ADD任务中。我们使用改进的LCNN作为区分真假图像的主干。此外,还设计了一种三元组挖掘方法,用于分离虚假语音和聚合真实语音。同时,单边域分类器使得来自不同域的真实语音无法区分,便于真实语音的进一步聚合。
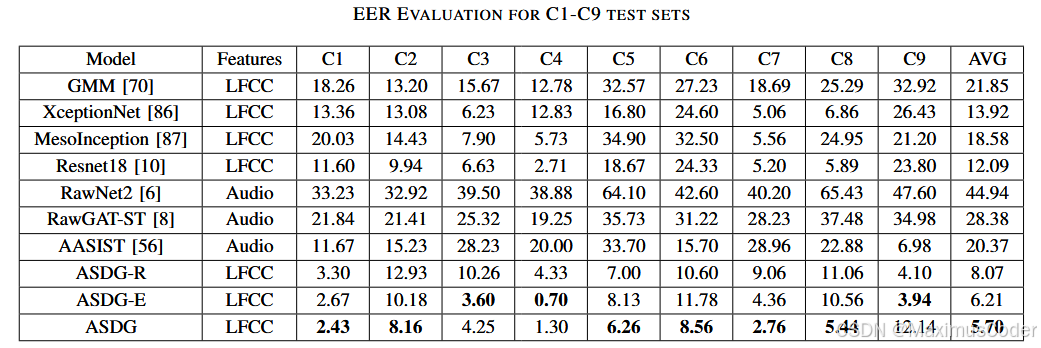
- 目前的ADD模型与我们的模型的不同之处在于,我们专注于提高模型的泛化能力,即即使在未知领域也能取得良好的性能。我们期望在有限的数据集中生成一个理想的ADD特征空间,并通过对特征空间的可视化来实现目标。根据测试结果,我们提出的模型在外域ADD任务中表现出最好的性能,在干净条件下实现了最低的EER为5.70 %。未来的工作将集中在更多的领域泛化和迁移学习方法在ADD任务中的应用。
背景
当前的ADD模型在跨域泛化能力方面存在显著不足。这些不足主要源于缺乏大规模和多样化的数据集,导致模型在真实场景中的表现不佳。尽管深度学习方法在ADD任务中通常优于传统方法,但它们的可解释性较差,这使得模型的决策过程难以理解。
早期的ADD方法在同一域内的数据库测试中表现良好,但在跨域情况下却面临挑战。这些挑战主要是由于不同的通道、编解码器、压缩格式和录音设备等因素造成的。这些因素影响了ADD模型的判别能力,尤其是在面对未见过的伪造攻击时,模型可能会产生不准确的判断。
为了提高模型在跨域数据集上的泛化能力,研究者们提出了数据增强(DA)技术,以增加数据分布的多样性。然而,单靠数据增强方法并不足以解决问题,因为在现实场景中存在大量未见过的伪造攻击类型。因此,文章的研究重点是通过聚合和分离的方法来改善模型的泛化能力,同时增强模型隐藏状态的可解释性,以应对这些挑战
内容成果
提出的方法
ASDG方法的核心思想是通过聚合真实语音的特征分布和分离伪造语音的特征分布,来构建一个理想的特征空间。这一过程主要通过以下几个关键组件实现:
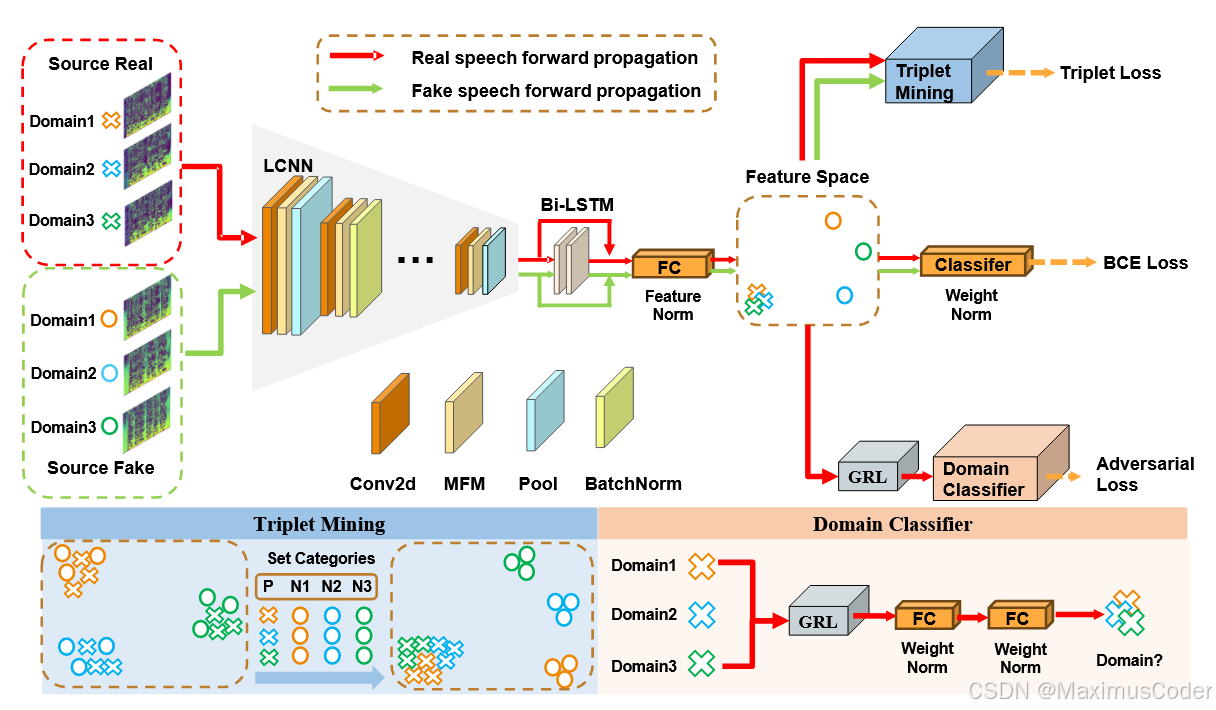
红线和绿线分别表示真实和虚假语音的前向传播路径。由 FC 组成的分类器将特征压缩为 1 维以进行二进制交叉熵损失,同时实现三元组挖掘以优化特征空间。真实语音特征将被发送到域分类器以识别域,并使用梯度反向层 (GRL) 使真实特征无法区分。
特征生成器
轻量级卷积神经网络(LCNN):使用LCNN作为特征生成器,旨在从输入的音频信号中提取有效的特征。这些特征被分类为真实和伪造,以便后续处理。
单侧域对抗学习
对抗域判别器:在ASDG中,采用单侧域对抗学习策略,使得来自不同域的真实语音特征在特征空间中不可区分。具体来说,输入到域判别器的仅为真实数据集,而不包括伪造数据。这种方法的目的是将真实语音的分布聚合在一起,形成一个紧凑的特征集。
三元组损失
三元组损失函数:为了有效分离伪造语音的特征,ASDG采用了三元组损失函数。该损失函数通过选择一个锚点(真实样本)、一个正样本(同类真实样本)和一个负样本(伪造样本),来优化特征空间,使得真实样本之间的距离更近,而伪造样本则被推远。这种方法有助于在特征空间中形成清晰的分界,增强模型对伪造语音的识别能力。
三元组损失函数通常表示为:
其中:
- a 是锚点样本(真实样本)
- p 是正样本(同类真实样本)
- n 是负样本(伪造样本)
- d(x,y) 是样本 x 和 y 之间的距离
- α 是一个超参数,表示边界阈值
对抗损失函数
对抗损失函数可以表示为:
其中:
- D(x) 是判别器的输出,表示样本 x 为真实样本的概率
- Preal 是真实样本的分布
- Pfake 是伪造样本的分布
总损失函数
总损失函数可以表示为:
其中 λ 是平衡三元组损失和对抗损失的超参数。
理想特征空间
特征空间的构建:通过上述方法,ASDG旨在构建一个理想的特征空间,其中真实语音的特征聚集在一起,形成一个单一的簇,而伪造语音的特征则分散在更广泛的区域。这种特征空间的构建有助于提高模型在不同域和未见攻击上的泛化能力。
实验验证
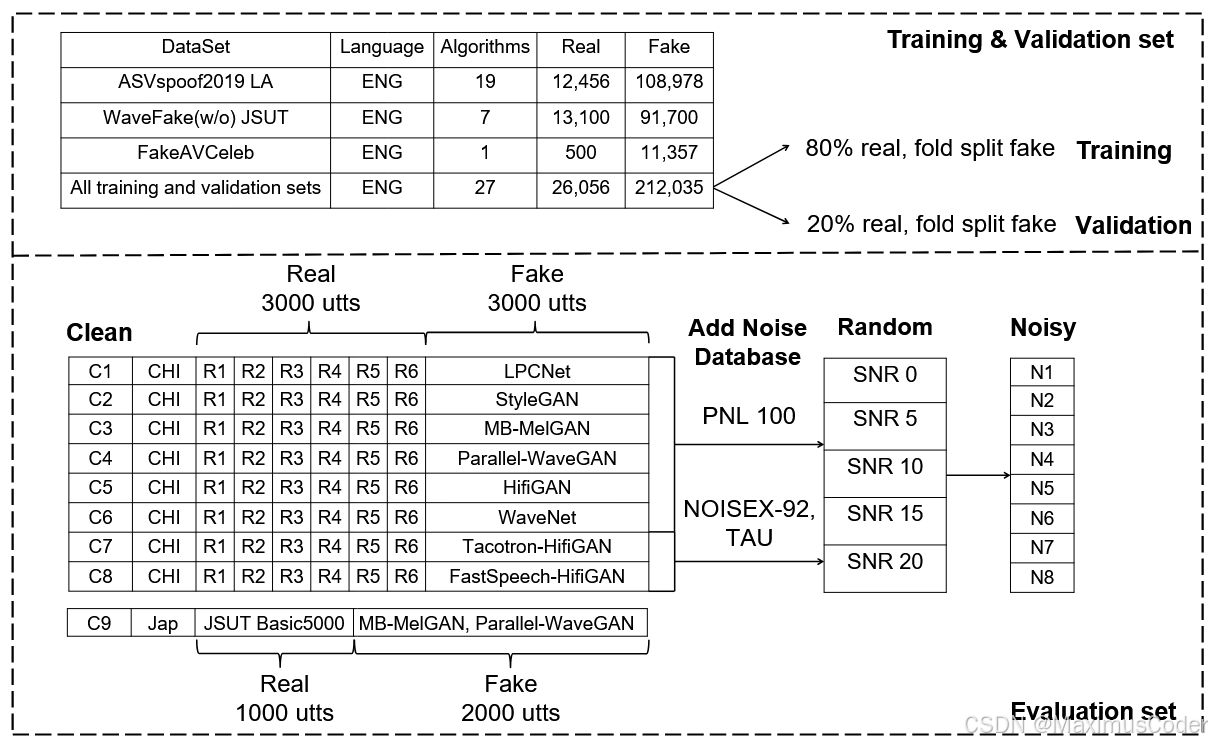
跨域和噪声条件下的测试:为了验证ASDG的有效性,文章在多个不同的英语数据集上进行了训练,并在跨语言和噪声条件下进行了评估。实验结果显示,ASDG在跨域任务中显著优于基线模型,降低了等错误率(EER)达39.24%。
数据集分布
EER评估结果
贡献点
提出了一种聚合与分离的域泛化方法(ASDG),旨在提高音频深度伪造检测(ADD)的泛化能力。该方法通过聚合来自不同域的真实语音特征并分离伪造语音特征,构建了一个理想的特征空间。文章引入了三元组损失函数和单侧域对抗学习,显著提升了模型对伪造语音的识别能力。通过在多个英语数据集上的广泛实验,ASDG在跨域任务中表现优异,降低了等错误率(EER)达39.24%。这些贡献不仅增强了模型的性能,还为音频深度伪造检测领域提供了新的思路和可解释性,具有重要的研究价值。