Linux 中的正则表达式应用工具(grep,sed,awk)
- 什么是正则表达式
任何一个有经验的系统管理员,都会告诉你:“正则表达式真是挺重要的!”为什么很重要呢?因为日常生活就使用的到啊!举个例子来说,在你日常使用 vim 作文书处理或程序撰写时使用到的“搜寻/取代”等等的功能,这些举动要作的漂亮,就得要配合正则表达式来处理。
简单的说,正则表达式就是处理字串的方法,他是以行为单位来进行字串的处理行为, 正则表达式通过一些特殊符号的辅助,可以让使用者轻易的达到“搜寻/删除/取代”某特定字串的处理程序!
正则表达式基本上是一种“表达式”,只要工具程序支持这种表达式,那么该工具程序就可以用来作为正则表达式的字串处理之用。例如 vi,grep,awk,sed 等等工具,因为他们支持正则表达式,所以这些工具就可以使用正则表达式的特殊字符来进行字串的处理。但例如 cp,ls 等指令并未支持正则表达式,所以就只能使用 bash 自己本身的万用字符而已。
1. grep 全局搜索正则表达式
- grep
Global search regular expression and print out the line
全面搜索研究正则表达式并显示出来
grep命令是一种强大的文本搜索工具根据用户指定的 “模式”对目标文本进行匹配检查,打印匹配到的行由正则表达式或字符及基本文本字符所编写的过滤条件
1.1 grep 基本操作
grep 的基本操作
grep root filename # 按指定信息匹配内容
grep ^root filename # 找到文件中 root 开头的行
grep root$ filename # 找到文件中以 root 结尾的行执行如下:
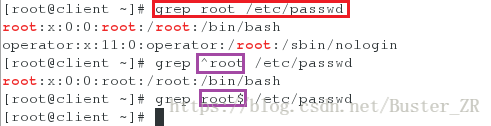
grep 选项操作
grep [-acinv] [--color=auto] '搜寻字串' filename
选项与参数:
-a :将 二进制 文件以 text 文件的方式搜寻数据
-c :计算找到 '搜寻字串' 的次数
-i :忽略大小写的不同,所以大小写视为相同
-n :顺便输出行号
-v :反向选择,亦即显示出没有 '搜寻字串' 内容的那一行!
-E :同时搜寻多条字符示例如下:
grep -E “root|student” /etc/passwd 同时检索 /etc/passwd 下的 root,student 两串字符

grep -nvE “root|student” /etc/passwd 显示行号并反选
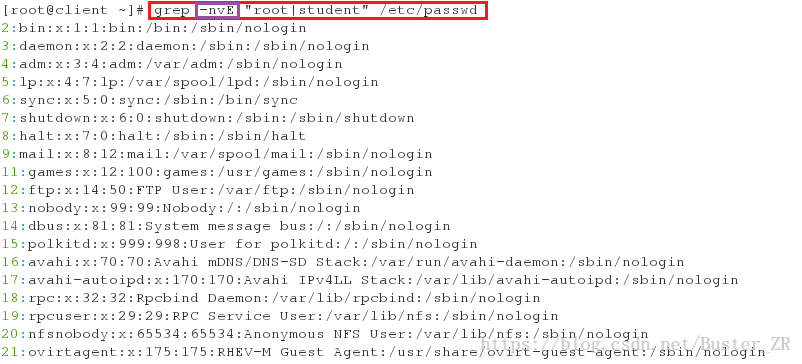
1.2 grep 中字符的匹配次数设定
| 参数 | 含义 |
|---|---|
| * | 字符出现【0-任意次】 |
| \? | 字符出现【0-1次】 |
| + | 字符出现【1-任意次】 |
| {n} | 字符出现【n次】 |
| {m,n} | 最少出现 m 次,最多出现 n 次 |
| {0,n} | 字符出现【0-n 次】 |
| {m,} | 字符出现【至少 m 次】 |
| (xy){n}xy | 关键字出现【n次】 |
| .* | 关键字之间匹配任意字符 |
示例如下:
编辑测试文件 test

进行测试:
指定关键字至少出现两次;指定关键字至少出现一次
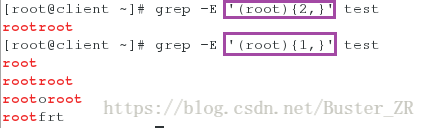
* 指定字符出现0-任意次;? 指定字符出现1-任意次

2. sed
- sed (stream editor)行编辑器
用来操作纯ASCII码的文本处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space)可以指定仅仅处理哪些行- sed
符合模式条件的处理不符合条件的不予处理;
处理完成之后把缓冲区的内容送往屏幕;
接着处理下一行,这样不断重复,直到文件末尾
sed 的基本格式
sed 命令格式
sed [-nefr] [动作]
选项与参数:
-n :使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN 的数据一般都会被列出到屏幕上。
但如果加上 -n 参数后,则只有经过 sed 特殊处理的那一行(或者动作)才会被列出来。
-e :直接在命令行界面上进行 sed 的动作编辑;
-f :直接将 sed 的动作写在一个文件内,-f filename 则可以执行 filename 内的 sed 动作;
-r :sed 的动作支持的是延伸型正则表达式的语法。(默认是基础正则表达式语法)
-i :直接修改读取的文件内容,而不是由屏幕输出。
动作说明:[n1[,n2]]function
n1,n2 :不见得会存在,一般代表“选择进行动作的行数”
举例来说,如果我的动作需要在 10 到 20 行之间进行的,则“ 10,20[动作行为]”
function 有下面这些
a :新增,a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)
c :取代,c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行
d :删除,因为是删除啊,所以 d 后面通常不接
i :插入,i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行
s :取代,可以直接进行取代的工作。通常这个 s 的动作可以搭配正则表达式进行示例:
- p 显示模式
sed -n '/^UUID/p' fstab #选取 fstab 文件中以 UUID 开头的行
sed -n '/UUID$/p' fstab #选取 fstab 文件中以 UUID 结尾的行
sed -n '2,6p' fstab #选取 fstab 文件中的 2 到 6 行
sed -n '2,6!p' fstab #选取 fstab 文件中的非 2 到 6 行执行如下:
选取 2-6 行,与不显示 2-6 行
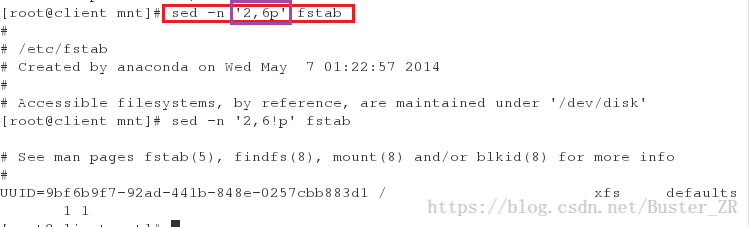
选取 fstab 文件中以 UUID 开头的行

- d 删除模式
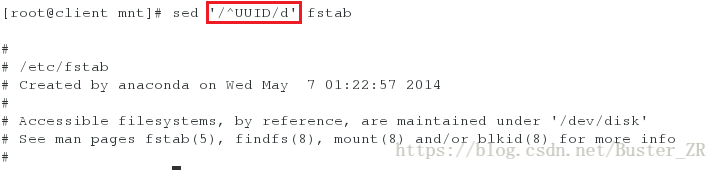
sed '/^UUID/d' fstab # 不显示以 UUID 开头的行
sed '/^#/d' fstab # 不显示以 # 开头的行
sed '1,4d' fstab # 不显示以 1-4 行
sed '/^UUID/!d' fstab # 不显示不是以 UUID 开头的行执行如下:
不显示以 UUID 开头的行
不显示以 # 开头的行

不显示以 1-4 行

不显示不是以 UUID 开头的行

- a 添加模式
添加到关键字下
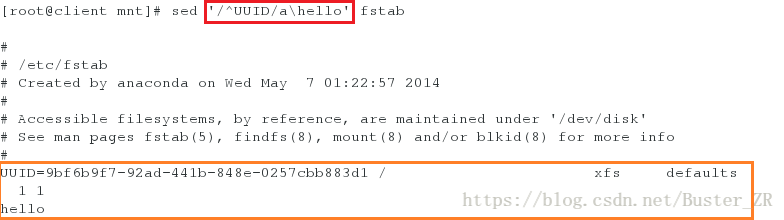
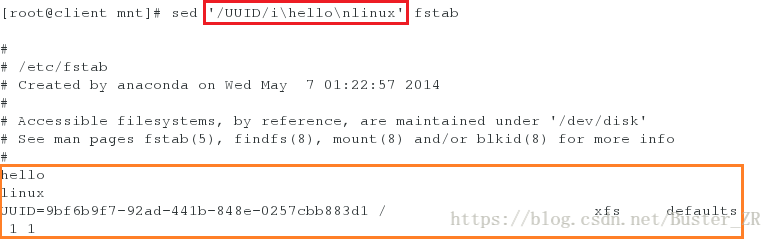
sed '/^UUID/a\hello' sed fstab #将 hello 添加到 UUID 开头的行下
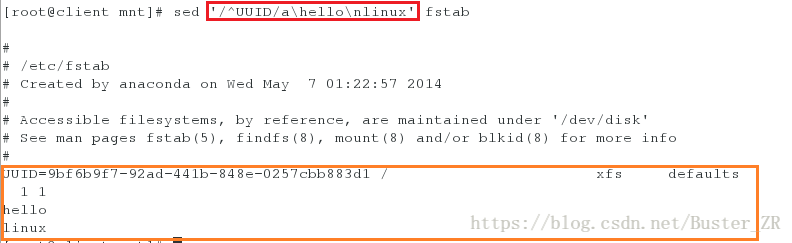
sed '/^UUID/a\hello\nlinux' fstab #换行添加 linux执行如下:
将 hello 添加到 UUID 开头的行下
换行添加 linux
- i 插入模式
插入到关键字上一行
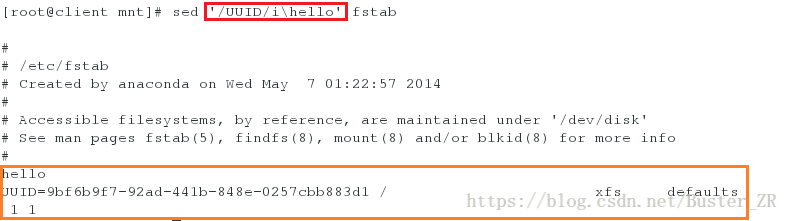
sed '/UUID/i\hello' fstab #将 hello 插入到 UUID 开头的上一行
sed '/UUID/i\hello\nlinux' fstab #换行插入 linux将 hello 插入到 UUID 开头的上一行
换行插入 linux
- w 写入模式
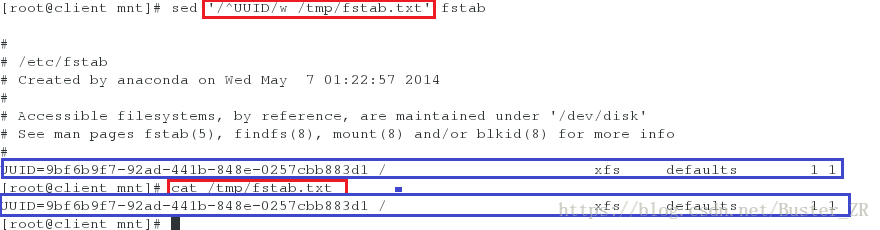
sed '/^UUID/w /tmp/fstab.txt' fstab
# 将 UUID 开头的行写入到 /tmp/fsstab.txt 下
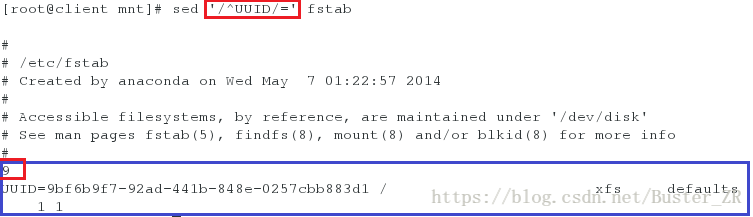
sed '/^UUID/=' fstab
# 显示 UUID 开头行的行号
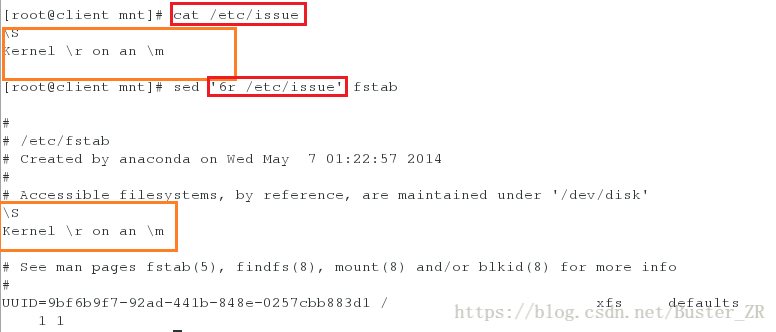
sed '6r /etc/issue' fstab #
# 将 /etc/issue 的内容插入到 fsatab 的第六行下执行如下:
将 UUID 开头的行写入到 /tmp/fsstab.txt 下
显示 UUID 开头行的行号
将 /etc/issue 的内容插入到 fsatab 的第六行下
- s 替换模式
sed 's/\//#/' fstab # 将每行第一个‘\’ 替换为‘#’
sed 's/\//#/g' fstab # 将全文的‘\’ 替换为‘#’
sed 's@^/@#@g' fstab # @ 分隔符可与 / 分隔符互换执行如下:
@ 分隔符可与 / 分隔符互换
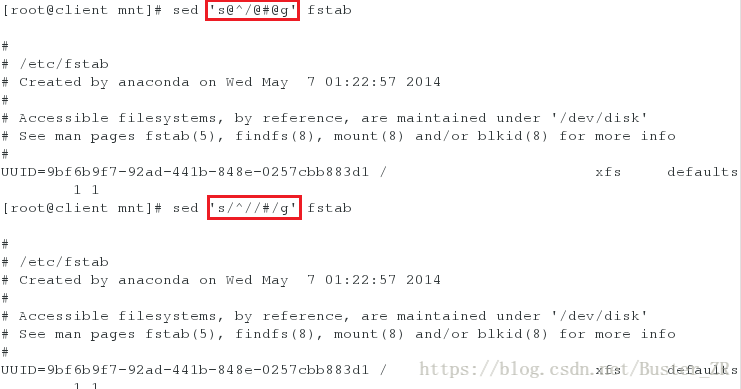
将全文的‘\’ 替换为‘#’
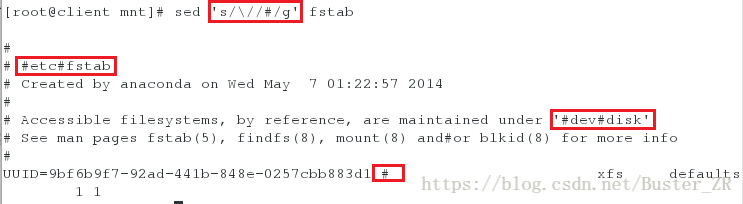
- sed 其他模式
-n :使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN 的数据一般都会被列出到屏幕上。
但如果加上 -n 参数后,则只有经过 sed 特殊处理的那一行(或者动作)才会被列出来。
sed -n '/^UUID/=' fstab #只显示 UUID 开头行的行号
sed -n -e '/^UUID/p' -e '/^UUID/=' fstab
#-e 可执行多个限定,只显示 UUID 行,并只显示 UUID 行行号
sed -n -e '/^UUID/p;/^UUID/=' fstab
#-e 的另一种表示方式执行如下:
-e 可执行多个限定,只显示 UUID 行,并只显示 UUID 行行号,及其另一种表示方式

只显示 UUID 开头行的行号

sed 'G' test #给每一行内容后加上空行
sed '$!G' test #只给最后一行后不加空行
sed '$P' test #只复制最后一行内容
sed '=' test|sed 'N; s/\n/ /'
#生成行号,并将两行间的换行变成空格执行如下:
编辑生成测试文件 test

给每一行内容后加上空行;只给最后一行后不加空行

生成行号,并将两行间的换行变成空格

3. awk 报告生成器
- awd 报告生成器基本用法
awk处理机制:awk会逐行处理文本,支持在处理第一行之前做一些准备工作以及在处理完最后一行做一 些总结性质的工作,在命令格式上分别体现如下:
BEGIN{ }:读入第一行文本之前执行,一般用来初始化操作
{ }:逐行处理,逐行读入文本执行相应的处理,是最常见的编辑指令
END{ }:处理完最后一行文本之后执行,一般用来输出处理结果
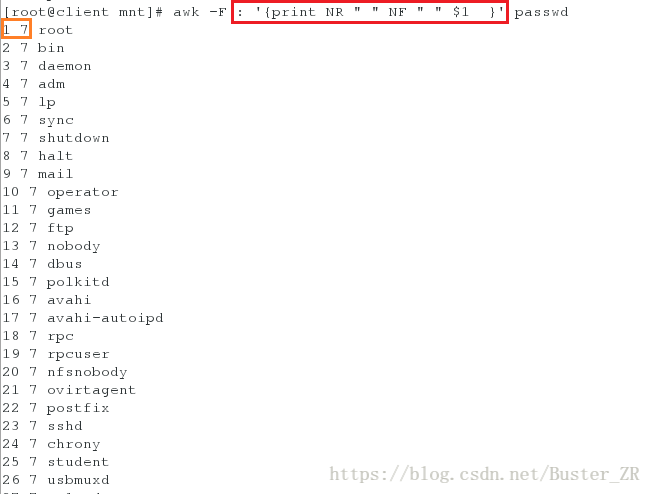
awk 通过 print 的功能将字段数据列出来
awk -F : '{print NR " " NF " " $1 }' passwd
-F :分隔符类型,默认为空格
NR :第几行
NF :有几列
$1 :以“:”为分隔符的第一列数据示例如下:
awk -F : 'BEGIN{print "NAME"}{print $1}END{print "END"}' passwd
# BEGIN {print "NAME"} 处理数据前,执行显示"NAME"字符
# END {print "END"} 处理数据后,执行显示"END"字符执行如下:

awk '/bash$/' passwd # 列出以 bash 结尾的行执行如下:

可以用来统计一个文件有多少行
awk 'BEGIN{N=0}{N++}END{print N}' /etc/passwd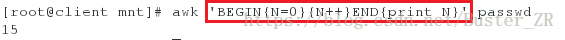
对指定行与内容进行显示
awk -F : '/^ro/{print}' passwd
# 以:为分隔符,显示以 ro 字符开头的行
awk -F : '/^[a-d]/{print $1,$6}' passwd
# 显示以字母 a-d 开头的行的第 1 列,第 6 列
awk -F : '/^a|nologin$/{print $1,$7}' passwd
# 显示以 a 开头,以 nologin 结尾的行的第 1 列,第 7 列
awk -F : '$6~/bin$/{print $1,$6}' passwd
# 显示从第 6 列开始,以 bin 结尾的列所在行的第 1 列,第 6 列
awk -F : '$7!~/nologin$/{print $1,$6}' passwd
# 显示除了从第 7 列开始以 nologin 结尾的行的第 1 列,第 6 列执行如下:
以:为分隔符,显示以 ro 字符开头的行;显示以字母 a-d 开头的行的第 1 列,第 6 列

显示以 a 开头,以 nologin 结尾的行的第 1 列,第 7 列;显示除了从第 7 列开始以 nologin 结尾的行的第 1 列,第 6 列
