前言
题目: Extending Context Window of Large Language Models via Positional Interpolation
论文地址:Extending Context Window of Large Language Models via Positional Interpolation

1. 预备知识
由于PI是基于旋转位置编码RoPE进行改进,而RoPE几乎是现在主流大模型的标配,因此在这一部分简单介绍一下RoPE。这部分没有太多的推理过程,网上相关的推导有很多,这里就不重复了。
RoPE的本质是想基于绝对位置来编码相对位置。具体来说,RoPE首先通过一个变换函数来对query和key向量进行变换:
然后再计算二者间的内积:
RoPE试图找到一种变换来让最终计算的内积中包含两个位置之间的相对距离
m
−
n
m - n
m−n。RoPE提出的解决方案是:
具体来说,针对
m
m
m位置的向量
x
m
x_m
xm,其变换方式为:
其中
θ
i
=
b
−
2
(
i
−
1
)
/
d
(
b
=
10000
,
i
=
1
,
2
,
3
,
.
.
.
,
d
/
2
)
\theta_i = b^{-2(i - 1) / d}(b=10000,~i=1,2,3,...,d/2)
θi=b−2(i−1)/d(b=10000, i=1,2,3,...,d/2)。最后,变换后的两个向量求内积然后取实部即为注意力计算结果。
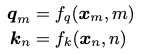
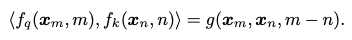
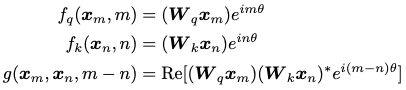
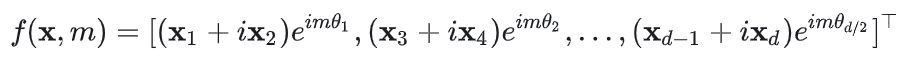
在代码编写过程中,实际使用的计算方式为:
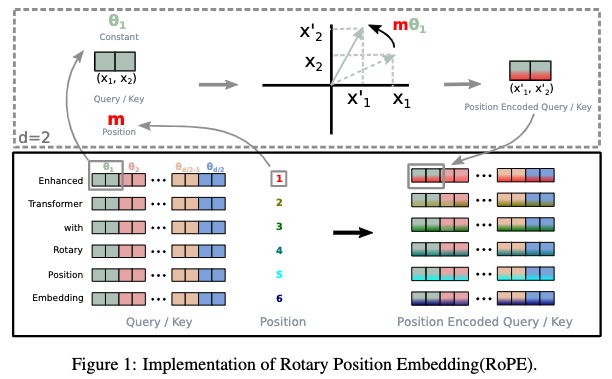
将RoPE中每个位置的向量每两两一组放在复平面上:
可以发现其本质就是将每两个维度旋转与当前位置有关的角度,进而让两个不同位置间的内积存在相对位置项。

2. PI
假设模型当前能够接受的最大长度为 L L L。事实上,RoPE是可以处理超过训练时长度的输入,也就是直接扩大可处理的长度,然后不做任何处理,即直接外推。然而,由于模型在训练期间从未见过长度超过 L L L的输入,因此当输入长度大于 L L L时,模型性能将急剧下降。
一些论文提出可以通过给模型喂一些长度大于
L
L
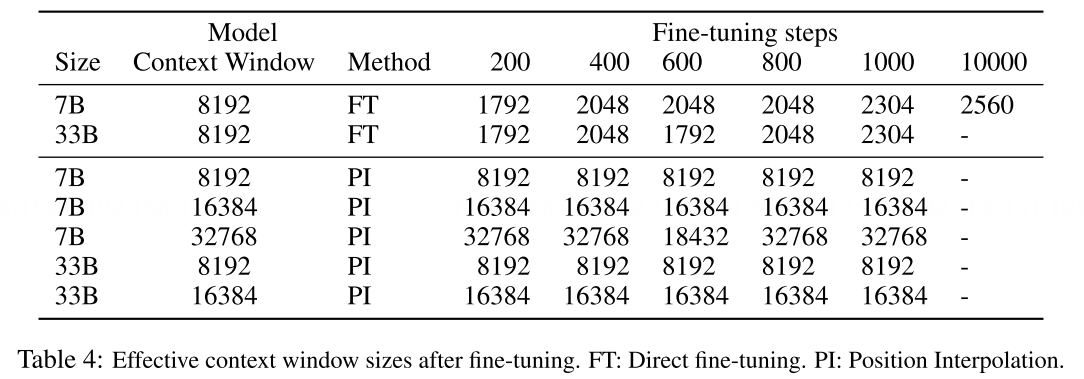
L的输入来微调模型,进而逐步将原始窗口长度扩大。实验结果如下:
实验结果证明,即使经过10000多个step的训练后,窗口长度增加的幅度仍然特别小,有效上下文窗口的增加幅度仅从2048增加到2560,这种代价是不可接受的。
为了解决这个问题,Position Interpolation被提出。PI的思想很简单:假设当前长度 L = 2048 L=2048 L=2048,虽然 f ( x m , m ) f(x_m, m) f(xm,m)中的位置索引不能超过2048,但 m m m可以为小数,于是PI提出可以将超出预设长度 L L L的位置通过缩放因子缩放到 L L L以内。令扩充后的长度为 L ′ L^{'} L′,则缩放因子被定义为 S = L ′ L S=\frac{L^{'}}{L} S=LL′。
接着,PI将RoPE的变换函数改写为以下方案:
f
′
(
x
m
,
m
)
=
f
(
x
m
,
m
S
)
f^{'}(x_m, m) = f(x_m, \frac{m}{S})
f′(xm,m)=f(xm,Sm)
将 m m m变成了 m S \frac{m}{S} Sm,本质上是线性缩小了每个位置每个维度上的旋转角度。值得注意的是,重新调整位置索引的方法不会引入额外的权重参数,也不会以任何方式修改模型架构。这使得它在实际应用中具有很强的适应性,属于即插即用的框架。在调整位置编码方式后,PI需要进一步使用 L ′ L^{'} L′长度内的样本对模型进行简单少量微调以达到最佳性能。
3. 实验
作者将LLaMA-7B, LLaMA-13B, LLaMA-33B和LLaMA-65B从2048的原始长度扩充16倍到32768。PI微调1000步,直接外推则是微调10000步。
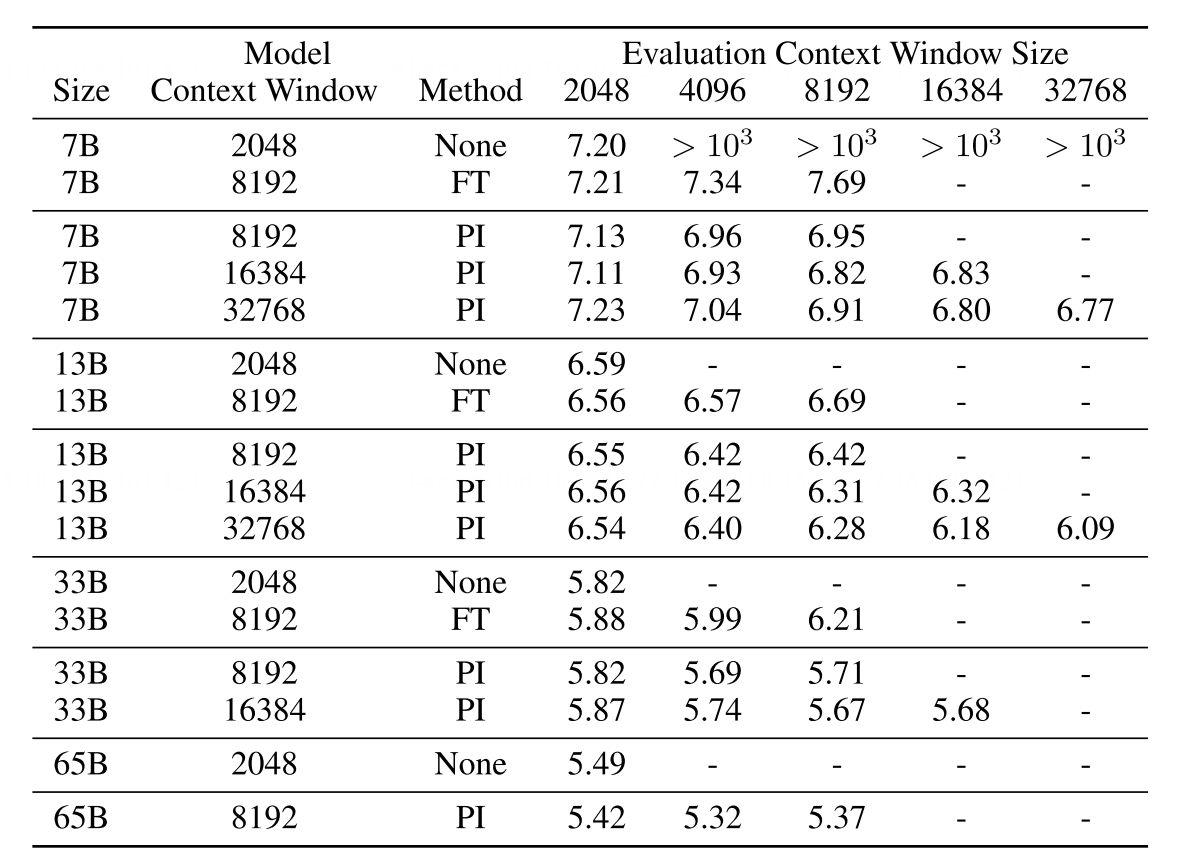
部分实验结果如下:
可以发现相比于直接外推,PI能在更短的微调步骤下实现更低的困惑度。
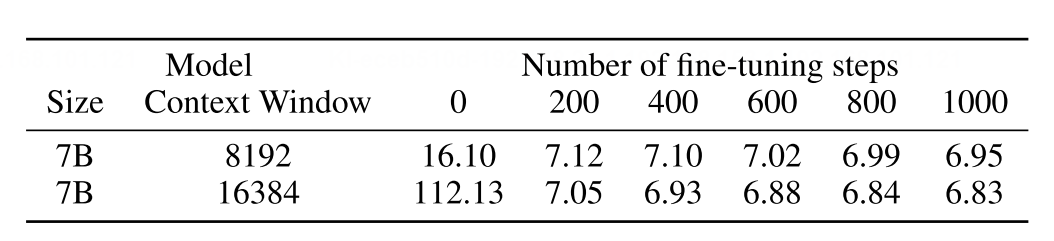
此外,作者还研究了PI微调步数和困惑度之间的关系:
实验结果表明,直接将模型不微调从2048扩充4倍到8192,模型也能保持较好的性能,并且在微调200步后性能显著提升。