前言
最近在研究目标检测算法–PP-PicoDet算法(百度自研**),2021年11月份新鲜出炉。官方介绍说,性能优于YOLOV5 、YOLOX等算法,主要是轻量化部署贡献很大,比如在相同的精度下,PP-PicoDet推理速度高出YOLOv5s 44%,可谓NB,所以作者第一步先搭建环境,试跑一下,记录使用PP-PicoDet算法在paddle框架下训练模型的整个过程,供大家参考交流,欢迎提问。
PP-PicoDet算法源码:GitHub源码地址
目标检测数据集+分类数据集大全
https://blog.csdn.net/DeepLearning_/article/details/127276492?spm=1001.2014.3001.5502
一、说明
PP-PicoDet算法支持COCO、Pascal VOC和wide - face数据集的PaddleDetection,本文使用的数据集标签格式是voc格式的,也就是标签为xml文件。
二、数据集准备制作
1.标注好的图片和对应标签分开存放
如下图,分别存放在JPEGImages和Annotations文件夹,JPEGImages和Annotations可以存放在dataset文件夹下,这个可自己安排,只要后面路径对得上就ok
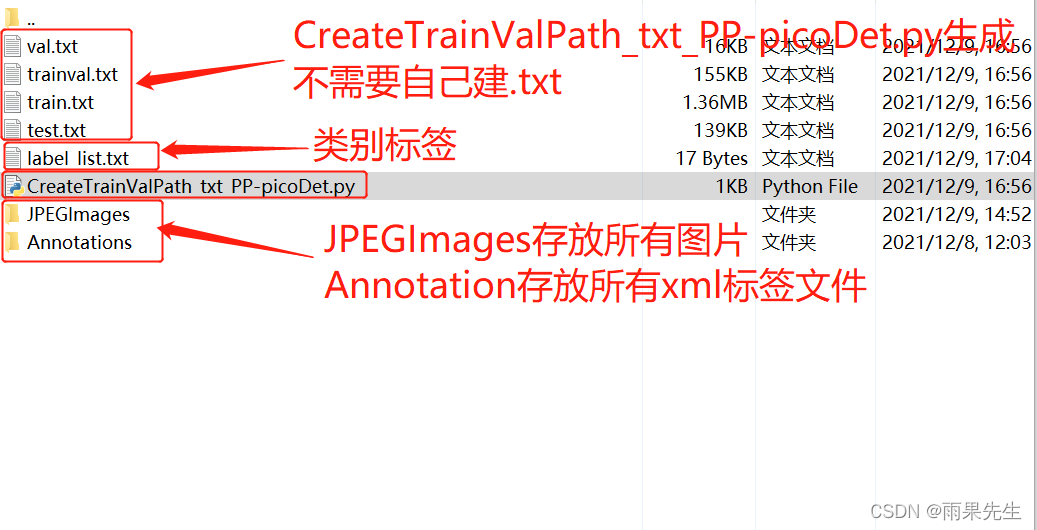
2.修改CreateTrainValPath_txt_PP-picoDet.py脚本(该脚本是博主自己写的一个,源码中没提供),生成train.txt和val.txt
CreateTrainValPath_txt_PP-picoDet.py脚本说明:
1、该脚本的功能是生成支持PP-PicoDet算法使用的train.txt和val.txt;
2、该脚本会按照9:1的比例把所有图片划分为训练集和验证集。
(注意:使用前先改成自己的路径)
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = '/PaddleDetection-2.3/dataset/VOCdevkit/VOC2007/Annotations/' #换成自己标签存放的路径
txtsavepath = '/dataset/VOCdevkit/VOC2007'
imgfilepath = '/PaddleDetection-2.3/dataset/VOCdevkit/VOC2007/JPEGImages/' #换成自己图片存放的路径
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('./trainval.txt', 'w')
ftest = open('./test.txt', 'w')
ftrain = open('./train.txt', 'w')
fval = open('./val.txt', 'w')
for i in list:
name = total_xml[i][:-4]
if i in trainval:
ftrainval.write(imgfilepath + name + '.jpg' + ' ' + xmlfilepath + name + '.xml' + '\n')
if i in train:
ftest.write(imgfilepath + name + '.jpg' + ' ' + xmlfilepath + name + '.xml' + '\n')
else:
fval.write(imgfilepath + name + '.jpg' + ' ' + xmlfilepath + name + '.xml' + '\n')
else:
ftrain.write(imgfilepath + name + '.jpg' + ' ' + xmlfilepath + name + '.xml' + '\n')
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
生成的train.txt内容格式如下:

3.label_list.txt文件内容
上面截图中说过,内容是训练数据的类别,比如训练集目标有person、dog、cat,则label_list.txt内容如下:
至此,数据集准备工作已完成!

4. 修改配置文件
本文作者使用的是picodet_s_320_voc.yml来训练模型的,其他类似操作,文件在“PaddleDetection-2.3/configs/picodet”路径下,需要修改的配置文件一共有5个(包括picodet_s_320_voc.yml),
(1)修改前的picodet_s_320_voc.yml内容如下:
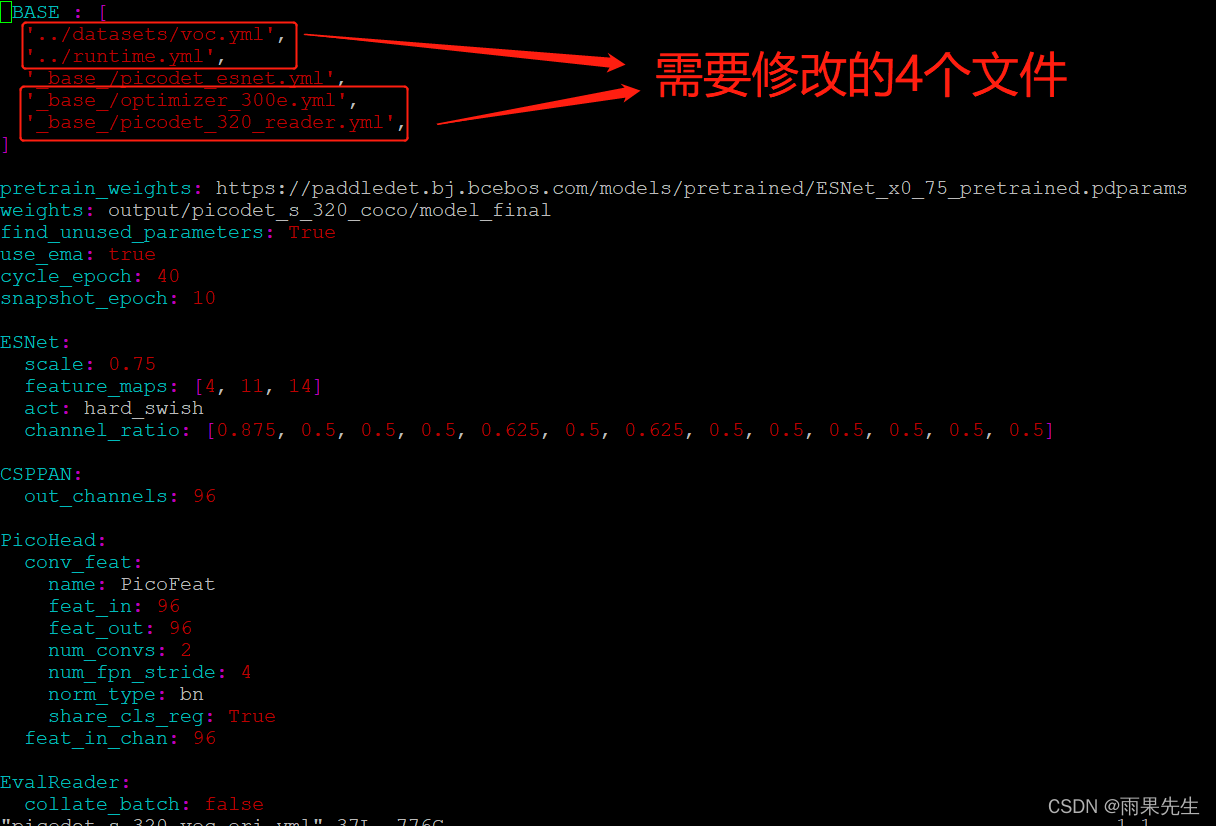
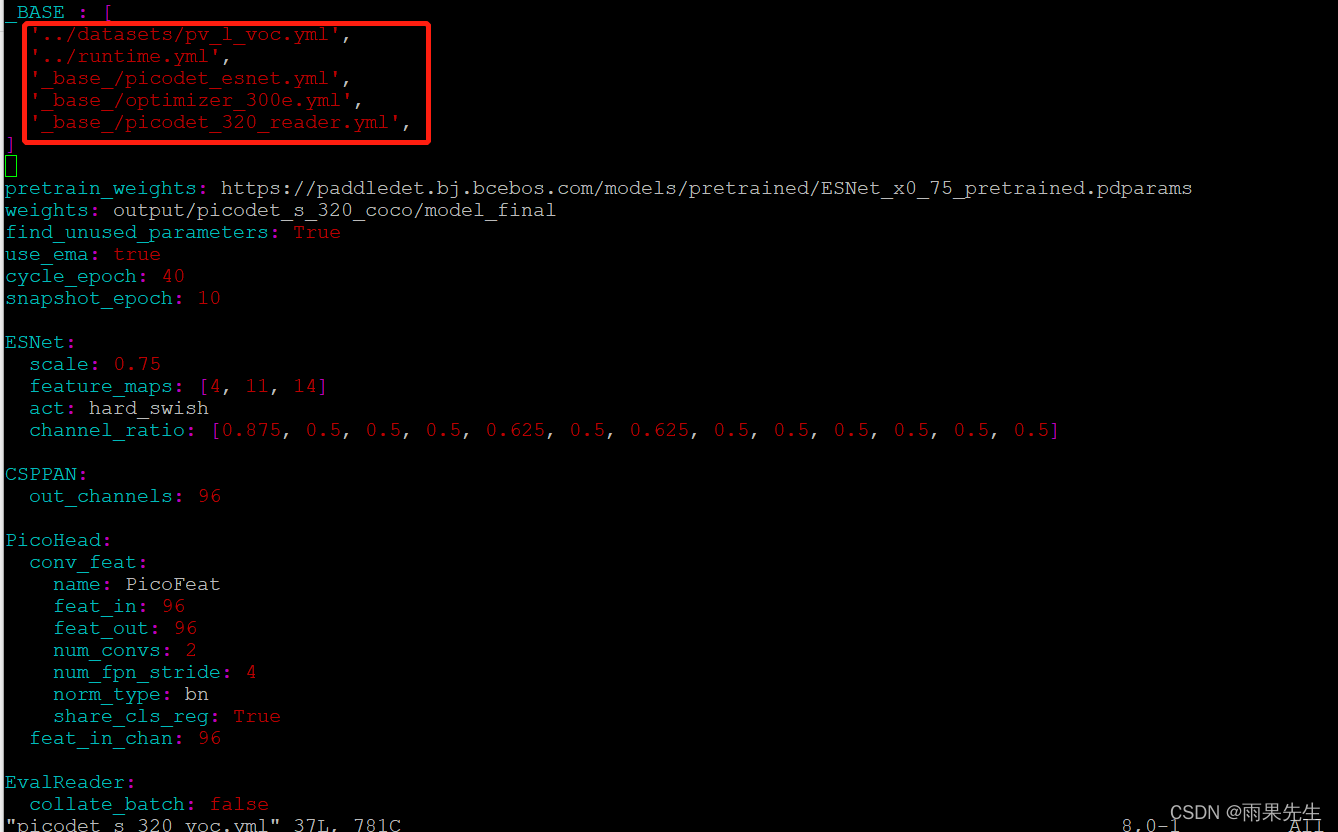
修改后的picodet_s_320_voc.yml内容如下:
(2)修改前的voc.yml内容如下:
修改后的voc.yml内容如下:
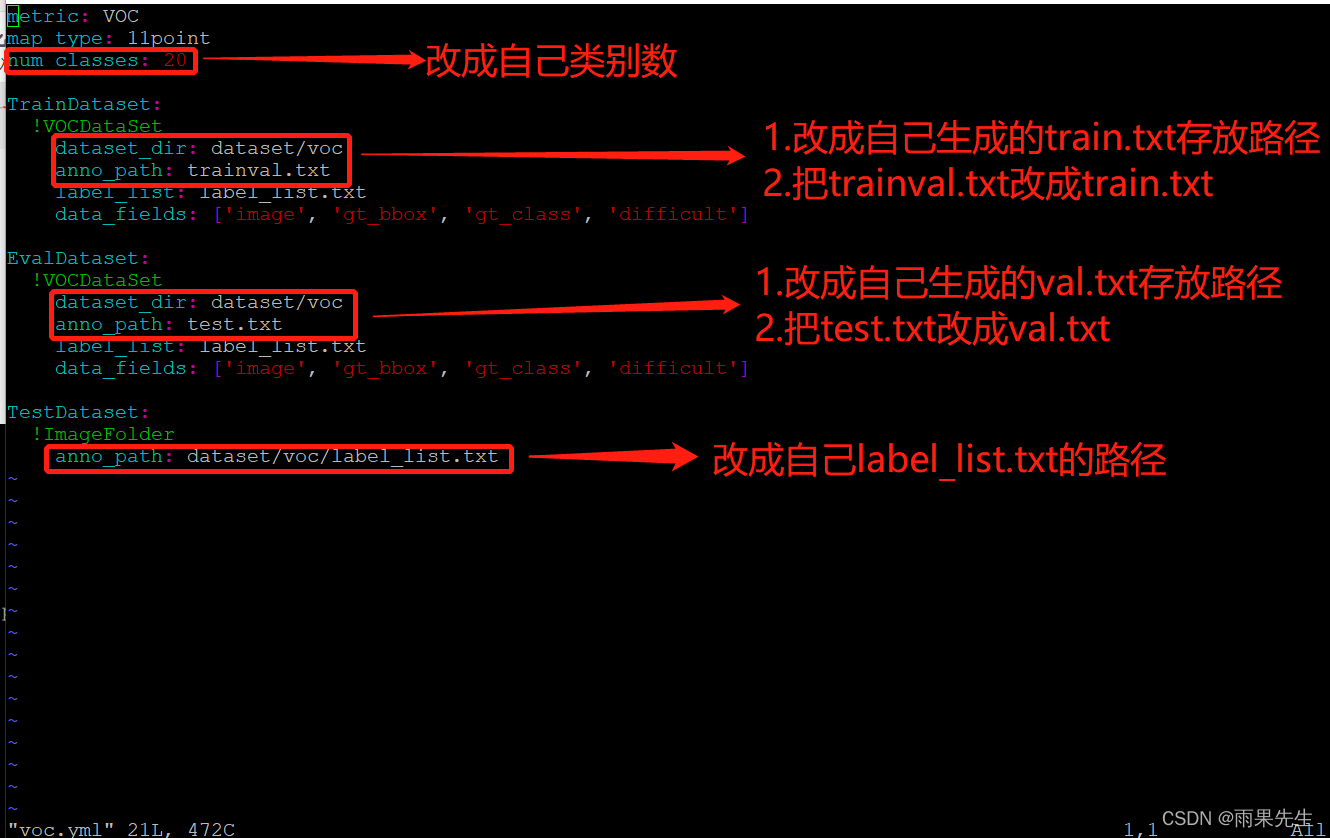
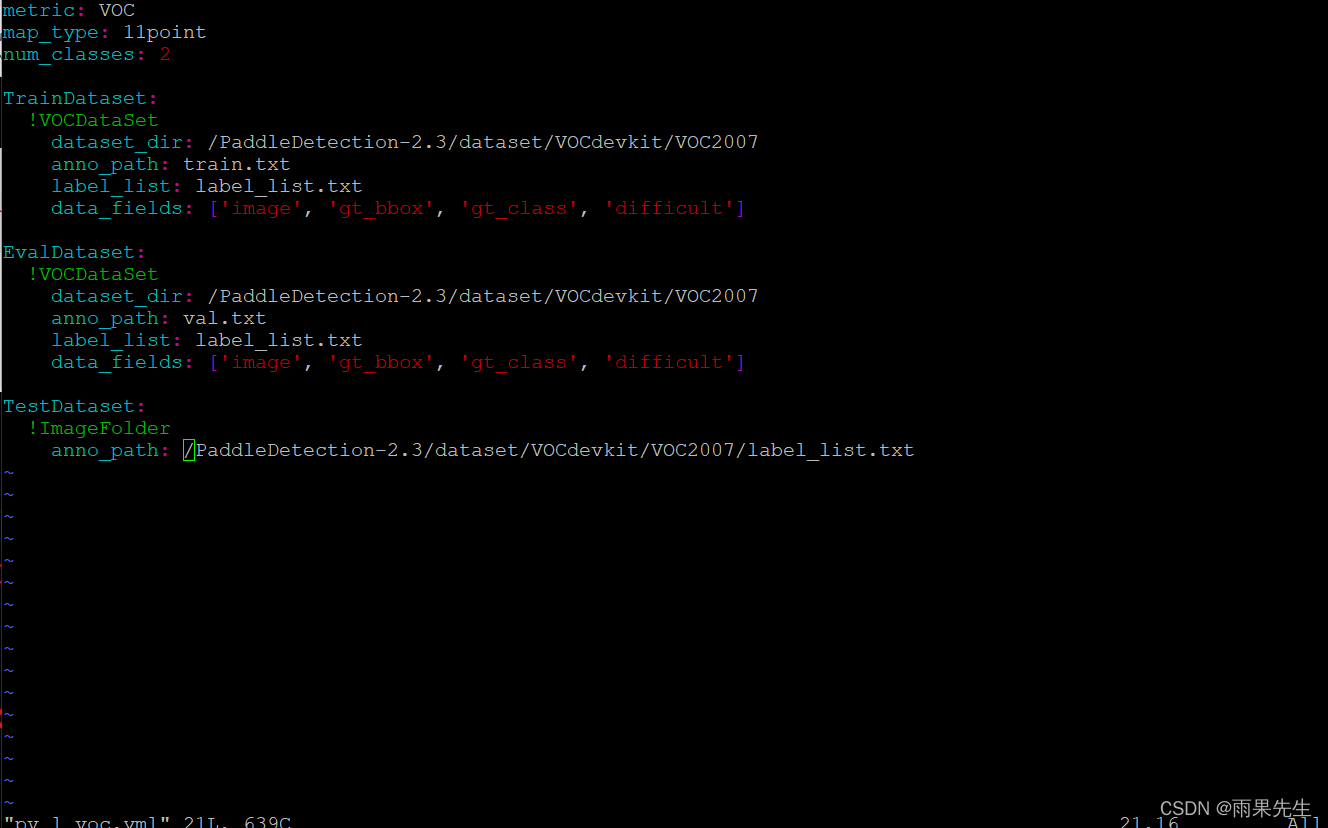
(3)修改后的vruntime.yml内容如下:
(4)修改后的picodet_320_reader.yml内容如下:

epoch: 300 #迭代次数,自定义修改
LearningRate:
base_lr: 0.05 #学习率,本文使用的是单个GPU训练,所以0.4除以8,等于0.05,默认是8块GPU训练
schedulers:
- !CosineDecay
max_epochs: 300
- !LinearWarmup
start_factor: 0.1
steps: 300
OptimizerBuilder:
optimizer:
momentum: 0.9
type: Momentum
regularizer:
factor: 0.00004
type: L2
(5)修改后的optimizer_300e.yml内容如下:
只修改batch_size参数
worker_num: 6
TrainReader:
sample_transforms:
- Decode: {}
- RandomCrop: {}
- RandomFlip: {prob: 0.5}
- RandomDistort: {}
batch_transforms:
- BatchRandomResize: {target_size: [256, 288, 320, 352, 384], random_size: True, random_interp: True, keep_ratio: False}
- NormalizeImage: {is_scale: true, mean: [0.485,0.456,0.406], std: [0.229, 0.224,0.225]}
- Permute: {}
batch_size: 32 #根据自己显卡内存修改batchsize
shuffle: true
drop_last: true
collate_batch: false
EvalReader:
sample_transforms:
- Decode: {}
- Resize: {interp: 2, target_size: [320, 320], keep_ratio: False}
- NormalizeImage: {is_scale: true, mean: [0.485,0.456,0.406], std: [0.229, 0.224,0.225]}
- Permute: {}
batch_transforms:
- PadBatch: {pad_to_stride: 32}
batch_size: 8 #根据自己显卡内存修改batchsize
shuffle: false
TestReader:
inputs_def:
image_shape: [1, 3, 320, 320]
sample_transforms:
- Decode: {}
- Resize: {interp: 2, target_size: [320, 320], keep_ratio: False}
- NormalizeImage: {is_scale: true, mean: [0.485,0.456,0.406], std: [0.229, 0.224,0.225]}
- Permute: {}
batch_transforms:
- PadBatch: {pad_to_stride: 32}
batch_size: 1
shuffle: false
5.训练
执行命令:
1、export CUDA_VISIBLE_DEVICES=0 #windows和Mac下不需要执行该命令
2、python tools/train.py -c configs/picodet/picodet_s_416_coco.yml
6.成功训练过程截图如下

7.训练完生成模型
总结
**其实整个过程并不复杂,主要通过脚本把数据集处理好,另外配置好对应文件即可,有问题可以留言交流!如果本文对你有帮助,谢谢来个三连!
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/DeepLearning_/article/details/121835969
环境搭建这块参考本文作者另外一篇博客(更新中)。