目录
一、Linux系统简介
Linux,全称GNU/Linux,是一套免费使用和自由传播的类Unix操作系统,是一个基于POSIX的多用户、多任务、支持多线程和多CPU的操作系统。
Linux的内核设计非常精巧,分成进程调度、内存管理、进程间通信、虚拟文件系统和网络接口五大部分;其独特的模块机制可根据用户的需要,实时地将某些模块插入或从内核中移走,使得Linux系统内核可以裁剪得非常小巧,很适合于嵌入式系统的需要。
Linux的基本思想有两点:第一,一切都是文件;第二,每个文件都有确定的用途。其中第一条详细来讲就是系统中的所有都归结为一个文件,包括命令、硬件和软件设备、操作系统、进程等等对于操作系统内核而言,都被视为拥有各自特性或类型的文件。至于说Linux是基于Unix的,很大程度上也是因为这两者的基本思想十分相近。同时这也是Linux与Windows的区别。
Linux的另一个特点是完全免费,但这种说法更的是指的Linux内核,而市面上使用的Linux发行版本是由不同厂商拿到Linux内核后进行二次开发的版本,并不是全部的发行版本都是免费的。
Linux主要的发行版本有:


其中redhat(红帽子)就不是免费的,而CentOS就是一个完全免费的Linux发行版本。ubuntu更多的应用在嵌入式Linux领域,CentOS广泛应用在服务器领域。
对于新手学习,可以选择一个免费的Linux发行版本,不管是哪种发行版本,它使用的Linux内核都是一样的,只要学会了Linux的内核,市面上任何发行版本,都可以很快上手使用!
Linux各个文件的用途
根目录下的文件
| / | 根目录,包含了几乎所的文件目录。 |
| /boot | 该目录默认下存放的是Linux的启动文件和内核 |
| /bin | 该目录中存放Linux的常用命令 |
| /sbin | 该目录用来存放系统管理员使用的管理程序 |
| /var | 该目录存放那些经常被修改的文件,包括各种日志、数据文件 |
| /etc | 该目录存放系统管理时要用到的各种配置文件和子目录,例如网络配置文件、文件系统、X系统配置文件、设备配置信息、设置用户信息等。 |
| /dev | 该目录包含了Linux系统中使用的所有外部设备,它实际上是访问这些外部设备的端口,访问这些外部设备与访问一个文件或一个目录没有区别。 |
| /mnt | 临时将别的文件系统挂在该目录下。 |
| /root | 超级用户的家目录。 |
| /home | 普通用户的家目录 |
| /usr | 用户的应用程序和文件几乎都存放在该目录下。 |
| /lib | 该目录用来存放系统动态链接共享库,几乎所有的应用程序都会用到该目录下的共享库。 |
| /opt | 第三方软件在安装时默认会找这个目录,所以你没有安装此类软件时它是空的,但如果你一旦把它删除了,以后在安装此类软件时就有可能碰到麻烦。 |
| /tmp | 用来存放不同程序执行时产生的临时文件,该目录会被系统自动清理干净。 |
| /proc | 可以在该目录下获取系统信息,这些信息是在内存中由系统自己产生的,该目录的内容不在硬盘上而在内存里。 |
| /misc | 可以让多用户堆积和临时转移自己的文件。 |
| /lost+found | 该目录在大多数情况下都是空的。但当突然停电、或者非正常关机后,有些文件就临时存放在这里。 |
| /media | 挂载的媒体设备目录 |
Linux中文件颜色的含义:蓝色为文件夹,绿色为可执行文件,浅蓝色为链接文件,红框文件是加了SUI权限的文件,红色为压缩文件,褐色为设备文件。
/etc目录下的文件(学习过程中遇到的)
| /etc/passwd | 用户数据库,其中的域给出了用户名、真实姓名、用户起始目录、加密口令和用户的其 他信息。 |
| /etc/group | 用户组数据库,包括组的各种数据。 |
| /etc/shadow | 用户的密码库,存放用户的密码信息 |
三、Linux常用命令
1、目录文件处理命令
ls 显示目录文件
-a 显示所有文件,包括隐藏文件(隐藏文件前面带有“.”) -l 详细信息显示 -d 查看目录属性 -ld 以详细信息显示的方式查看目录属性
mkdir 创建新目录
-p 递归创建 mkdir默认只能在已经存在的目录中创建新目录,而加上-p选项 递归创建目录,就可以实现在每一级都自动创建目录,知道自己要创建的最终那一级目录。
cd 切换目录
切换到自己想在的目录, 其中 . 代表当前目录 .. 代表上一级目录 ~ 代表root的家目录
rmdir 删除空目录
pwd 显示当前目录
cp 复制目录文件
cp [选项] [原文件或目录] [目标目录]
-r 复制目录 -p 保留文件属性 -rp 复制目录的同时保留目录属性
mv 剪切文件/给文件改名
mv [原文件或目录] [目标目录]
将原文件还剪切到原目录就是改名
touch 创建空文件
cat 显示文件内容
-n 显示行号
tac 显示文件内容
与cat显示的内容是相反的,cat是正序,tat就是倒序
more 分页显示文件内容(只能向下翻页)
空格 / f 翻页 Enter 换行 q或Q 退出
less 分页显示文件内容(可上下翻页)
less显示的内容还可使用 /关键词 的方式在文件中搜索关键词,并使用 n 切换下一个
head 显示文件前面几行
-n [数字] 指定显示的行数 不指定的话默认会显示10行内容
tail 显示文件后面几行
-n [数字] 指定显示的行数 -f 动态显示文件末尾内容 不指定的话默认会显示10行内容
-n [数字] 指定显示的行数 不指定的话默认会显示10行内容
ln 生成链接文件
ln [选项] [原文件] [目标文件] -s 生成软链接 不加选项生成硬链接
软连接文件就相当于windows中的快捷方式,硬连接文件相当于对原文件的拷贝+同步更新
硬链接通过i节点识别,硬链接与原文件共用一个i节点
硬链接不能跨分区,不能针对目录使用
2、权限管理命令
八、文件系统管理
1、分区与文件系统
分区类型
主分区:最多只能分四个
扩展分区:只能有一个,也算作主分区的一种 ,也就是说主分区加扩展分区最多有四个。但是扩展分区不能存储数据和格式化,必须再划分成逻辑分区才能使用。
逻辑分区:逻辑分区是在扩展分区中划分的, 如果是IDE硬盘,Linux最多支持59个逻辑分区 ,如果是SCSI硬盘Linux最多支持11个逻辑分区
每个分区都要有自己的设备文件名/分区号,1、2、3、4这四个分区号只能给主分区或扩展分区使用,而不能给逻辑分区使用。其中sda6中的sd代表SATA硬盘接口,hd代表IDE硬盘接口,abcd代表第几块硬盘,1234代表主分区,5678代表逻辑分区。

| 分区的设备文件名 | |
| 主分区1 | /dev/sda1 |
| 主分区2 | /dev/sda2 |
| 主分区3 | /dev/sda3 |
| 扩展分区 | /dev/sda4 |
| 逻辑分区1 | /dev/sda5 |
| 逻辑分区2 | /dev/sda6 |
| 逻辑分区3 | /dev/sda7 |
文件系统
Linux是一种兼容性很高的操作系统,支持的文件系统的格式很多,大体可以分为几类:
(1)磁盘文件系统
指本地主机中实际可以访问到文件系统,或者说可以驻留在磁盘上的文件系统,包括硬盘、CD-ROM、DVD、USB存储器、磁盘阵列等。
常见文件系统格式有:EXT3、EXT4、VFAT、FAT、FAT16、FAT32、NTFS等;其中,NTFS是Windows目前主流的文件系统,作为电脑磁盘的主要文件系统格式。
- ext2:是ext文件系统的升级版本,Red Hat Linux7.2版本以前的系统默认都是ext2 文件系统。1993年发布,最大支持16TB的分区和最大2TB的文件(1TB=1024GB=1024*1024KB)
- ext3: ext3文件系统是ext2文件系统的升 级版本,最大的区别就是带日志功能,以在系统突然停止时提高文件系统的可靠性 。支持最大16TB的分区和最大2TB的文件
- ext4:它是ext3文件系统的升级版。ext4 在性能 、伸缩性和可靠性方面进行了大量改进。它的变化可以说是翻天覆地的,比如向下兼容 EXT3、最大1EB文件系统和16TB文件、无限数 量子目录、Extents连续数据块概念、多块分配 、延迟分配、持久预分配、快速FSCK、日志校 验、无日志模式、在线碎片整理、inode增强、 默认启用barrier等。是CentOS 6.3的默认文件系统(1EB=1024PB=1024*1024TB)
(2)网络文件系统
指可以远程访问的文件系统,这种文件系统在服务器端仍是本地的磁盘文件系统,客户机通过网络远程访问数据。常见的文件系统格式有:NFS、Samda等;
(3)虚拟文件系统
指不驻留在磁盘上的文件系统,同时也是比较抽象难以理解的部分,虚拟文件系统(VFS)是物理文件系统(上述的文件系统都属于物理文件系统)与服务应用之间的一个接口层,它对Linux的每个文件系统的所有细节进行抽象,使得不同的文件系统在Linux核心以及系统中运行的其他进程看来,都是相同的。
2、文件系统常用命令
- df [选项] [挂载点] 文件系统查看命令
- -a 显示所有的文件系统信息,包括特殊文件系统,如 /proc、/sysfs
- -h 使用习惯单位显示容量,如KB,MB或GB等
- -T 显示文件系统类型
- -m 以MB为单位显示容量
- -k 以KB为单位显示容量。默认就是以KB为单位
- du [选项] [目录或文件名] 统计目录或文件大小
- -a 显示每个子文件的磁盘占用量。默认只统计 子目录的磁盘占用量
- -h 使用习惯单位显示磁盘占用量,如KB,MB 或GB等
- -s 统计总占用量,而不列出子目录和子文件的 占用量
一般不用du统计文件大小,可以直接使用ls -l看到文件有多大,但ls -l 不能统计目录的大小,显示的只是目录下文件名占用了多少空间。
du命令与df命令的区别
(1)df命令是从文件系统考虑的,不光要考虑 文件占用的空间,还要统计被命令或程序占用的空间最常见的就是文件已经删除 ,但是程序并没有释放空间)
(2)du命令是面向文件的,只会计算文件或目录占用的空间。
- fsck [选项] [分区设备文件名] 文件修复命令
- -a: 不用显示用户提示,自动修复文件系统
- -y:自动修复。和-a作用一致,不过有些文件系统只支持-y
- dumpe2fs [分区设备文件名] 显示磁盘状态
3、文件挂载
Linux中所有的可存储设备,比如U盘,光盘,移动硬盘都需要挂载之后才能正常使用,只不过硬盘的挂载是系统自动运行,不需要手动挂载。
挂载就是将设备文件名与挂载点(盘符)联系起来才能通过访问盘符来访问这个硬件设备,将设备与挂载点连接起来的过程就叫做挂载。
挂载命令
- mount [-t 文件系统] [-L 卷标名] [-o 特殊选项] 设备文件名 挂载点
- -t 文件系统:加入文件系统类型来指定挂载的类型,如果文件系统是硬盘,分区就写ext3、ext4 ,如果是光盘,就写iso9660
- -L 卷标名: 挂载指定卷标的分区,而不是安装设备文件名挂载
- -o 特殊选项:可以指定挂载的额外选项
mount的一些用法
- mount 查询系统中已经挂载的设备
- mount -l 查询系统中已经挂载的设备并会显示卷标名称
- mount –a 依据配置文件/etc/fstab的内容,自动挂载
mount中可用的特殊选项:
| 参数 | 说明 |
| atime/noatime | 更新访问时间/不更新访问时间。访问分区文件时,是否更新文件 的访问时间,默认为更新 |
| async/sync | 异步/同步,默认为异步 |
| auto/noauto | 自动/手动,mount –a命令执行时,是否会自动安装/etc/fstab文件内容挂载,默认为自动 |
| defaults | 定义默认值,相当于rw,suid,dev,exec,auto,nouser,async这七个选项 |
| exec/noexec | 执行/不执行,设定是否允许在文件系统中执行可执行文件,默认 是exec允许 |
| remount | 重新挂载已经挂载的文件系统,一般用于指定修改特殊权限 |
| rw/ro | 读写/只读,文件系统挂载时,是否具有读写权限,默认是rw |
| suid/nosuid | 具有/不具有SUID权限,设定文件系统是否具有SUID和SGID的权限,默认是具有 |
| user/nouser | 允许/不允许普通用户挂载,设定文件系统是否允许普通用户挂载 默认是不允许,只有root可以挂载分区 |
| usrquota | 写入代表文件系统支持用户磁盘配额,默认不支持 |
| grpquota | 写入代表文件系统支持组磁盘配额,默认不支持 |
挂载光盘
- 挂载光盘命令
- mount /dev/sr0 /mnt/cdrom/
- 卸载光盘命令
- umount 设备文件名或挂载点
示例
| /mnt | 临时将别的文件系统挂在该目录下。 |
mkdir /mnt/cdrom/ 建立挂载点
mount -t iso9660 /dev/cdrom /mnt/cdrom/
挂载U盘
fdisk –l 查看U盘设备文件名
mount -t vfat /dev/sdb1 /mnt/usb/
umount 设备文件名或挂载点(卸载U盘)
查看U盘设备文件名不能使用远程工具。必须使用Linux本身,U盘与光盘不同,设备名不是固定的,挂载前要先查看正确的文件名。
这里加上Vfat是指定文件系统,文件系统能够被Linux识别才能挂载访问,fat16分区识别为fat,fat32分区识别为vfat。Linux默认不支持NTFS文件系统。
4、NTFS文件系统
Linux默认不支持NTFS文件系统,使用NTFS文件系统的移动硬盘是不能挂载使用的,要想在Linux中正确使用NTFS文件系统就需要进行手动挂载。Linux中绝大多数硬件都不需要手工按照驱动,系统会自动的给硬件按照驱动,但我们也可以手工安装驱动。
在Linux中使用NTFS文件系统有两种方式:
1、手工安装驱动,手工安装驱动需要内核来识别,我们重新把内核编译一遍,把NTFS驱动加入,就可以使用NTFS文件系统,但内核编译使用很少,并且编译工作量大,一般不使用。
2、使用第三方插件。使用NTFS-3G插件来获得Linux对NTFS文件系统的支持
使用NTFS-3G插件的方法:
(1)下载NTFS-3G插件
https://tuxera.com/opensource/ntfs-3g_ntfsprogs-2017.3.23.tgz
(2)使用文件传输软件将压缩包从windows传输到Linux
(3)解压 #tar -zxvf ntfs-3g_ntfsprogs-2013.1.13.tgz
(4) 进入解压目录 #cd ntfs-3g_ntfsprogs-2013.1.13
(5)安装NTFS-3G
编译器准备。没有指定安装目录,安装到默认位置中 #./configure
编译 #make
编译安装 #make install
(6)使用NTFS-3G插件挂载
mount [-t ntfs-3g] [分区设备文件名] [挂载点] 这里文件系统类型固定使用ntfs-3g
5、fdisk手动分区
我们一般使用fdisk命令手动对硬盘进行分区。使用fdisk命令进行分区的流程如下:
(1)没有空闲硬盘就用虚拟机添加一块新硬盘,虚拟机添加硬盘需要在关机下进行
(2)查看创建的新硬盘
使用fdisk -l 命令,查询系统中有多少可以被识别的硬盘、U盘。
(3)使用fdisk命令对硬盘进行分区分区
fdisk /dev/sdb sdb后面不能加数字 因为此时硬盘还没有分区
fdisk命令执行后是通过交互界面进行分区,交互指令如下:
| 命令 | 说明 |
| a | 设置可引导标记 |
| b | 编辑bsd磁盘标签 |
| c | 设置DOS操作系统兼容标记 |
| d | 删除一个分区 |
| l | 显示已知的文件系统类型。82为Linux swap分区,83为Linux分区 |
| m | 显示帮助菜单 |
| n | 新建分区 |
| o | 建立空白DOS分区表 |
| p | 显示分区列表 |
| q | 不保存退出 |
| s | 新建空白SUN磁盘标签 |
| t | 改变一个分区的系统ID |
| u | 改变显示记录单位 |
| v | 验证分区表 |
| w | 保存退出 |
| x | 附加功能(仅专家) |
(4) 执行fdisk命令后要重启,分区才能有效,如果不想重启可以使用#partprobe命令重新读取分区表信息,但不总是有效,如果无效还是要重启。
(5) 格式化分区
#mkfs -t ext4 /dev/sdb1
(6) 建立挂载点并挂载
mkdir /disk1
mkdir /disk5
mount /dev/sdb1 /disk1/
mount /dev/sdb5 /disk5/
注意:使用fdisk命令手工创建的分区在挂在后只是临时挂载,每次重新启动后挂载会失效,都需要手动挂载,若想实现自动挂载,需要将配置写入Linux系统配置文件中。
6、分区自动挂载与fstab文件修复
手动创建分区之后,使用mount命令进行手动挂载,但重启之后挂载会消失,要重新手动挂载。
要实现自动挂载,就是要写入系统配置文件/etc/fstab文件内
因为fstab文件在系统启动中极为重要,我们也要学习一下fstab文件的修复方法
/etc/fstab文件中各个字段的意义:
第一字段:分区设备文件名或UUID(硬盘通用唯一识别码)
第二字段:挂载点
第三字段:文件系统名称
第四字段:挂载参数
第五字段:指定分区是否被dump备份,0代表不备份,1 代表每天备份,2代表不定期备份
第六字段:指定分区是否被fsck检测,0代表不检测,其 他数字代表检测的优先级,那么当然1的优先级比2高
将分区挂载信息写入/etc/fstab配置文件的步骤:
(1)使用vim编辑器打开/etc/fstab配置文件
(2)按照/etc/fstab配置文件中各个字段的意义,在底部加入要写入的分区挂载信息

(3) 在写入文件之后先不要着急重启,我们可以先用mount -a命令来实现系统自动重新挂载,如果出现错误会提示,不至于系统崩溃。
/etc/fstab文件修复方法
如果一旦写错了,出现了报错,可以在开机显示之后出现一个让你输入root用户密码的界面,再输入密码之后,可以使用vim /etc/fstab进入fstab文件修改错误,如果出现文件只有只读权限,不能修改,强制保存也不行,退出文件,然后输入命令:mount -o remount,rw / ,重新把根分区挂载读写权限,就可以保存了,
该种fstab文件修复方式只能在根分区没有错误的情况下,在本机登陆,不能使用服务器或者远程连接的情况下才能修复。
7、新建swap分区
swap 分区通常被称为交换分区,这是一块特殊的硬盘空间,即当实际内存不够用的时候,操作系统会从内存中取出一部分暂时不用的数据,放在交换分区中,从而为当前运行的程序腾出足够的内存空间。也就是说,当内存不够用时,我们使用 swap 分区来临时顶替。这种“拆东墙,补西墙”的方式应用于几乎所有的操作系统中。
#free 查看内存与swap分区使用状况
-m:将内存按MB字节显示
cached(缓存):是指把读取出来的数据保存在内存当中,当再次读取时,不用读取硬盘而直接从内存当中读取,加速了数据的读取过程
buffer(缓冲):是指在写入数据时,先把分散的写入操作保存到内存当中,当达到一定程度再集中写入硬盘, 减少了磁盘碎片和硬盘的反复寻道,加速了数据的写入过程
新建一个swap分区的流程:
(1)#fdisk /dev/sdb 新建一个分区
在fdisk的交互界面中将新建分区的分区ID改为82(82是swap分区对应的ID号)
(2)#mkswap /dev/sdb1 分区完之后需要格式化,这里不能使用mkfs进行格式化
(3)swapon /dev/sdb1 将新建立的分区加入swap分区
如果不想用了,使用命令取消:swapoff /dev/sdb1 取消swap分区
swap分区开机自动挂载方法设置
(1)vi /etc/fstab 打开fstab配置文件
(2)将swap分区的挂载信息输入fstab配置文件中
注意:swap前面没有/,他不是根分区下的
(3)修改之后使用mount -a 命令来检测错误
九、Shell基础与编程
(一)Shell简介
什么是Shell?
Shell是一个命令行解释器,它为用户提供 了一个向Linux内核发送请求以便运行程 序的界面系统级程序,用户可以用Shell来 启动、挂起、停止甚至是编写一些程序。
Shell还是一个功能相当强大的编程语言, 易编写,易调试,灵活性较强。Shell是解释执行的脚本语言,在Shell中可以直接调用Linux系统命令。
我们用使用的Linux交互界面就是一个Shell。
Shell的分类
Bourne Shell:从1979起Unix就开始使用 Bourne Shell,Bourne Shell的主文件名为 sh。
C Shell: C Shell主要在BSD版的Unix系 统中使用,其语法和C语言相类似而得名
Shell的两种主要语法类型有Bourne和C, 这两种语法彼此不兼容。Bourne家族主要 包括sh、ksh、Bash、psh、zsh; C家族主 要包括:csh、tcsh。
Bash: Bash与sh兼容,现在使用的Linux 就是使用Bash作为用户的基本Shell。
查看Linux支持的Shell的方法:
#/etc/shells
会显示:
/bin/sh
/bin/bash
/sbin/nologin
/bin/tcsh
/bin/csh
这些都是Linux支持的Shell
(二)Shell的脚本执行方式
1、echo输出命令
echo [选项] [输出内容]
-e: 支持反斜线控制的字符转换
| 控制字符 | 作用 |
| \\ | 输出\本身 |
| \a | 输出警告音 |
| \b | 退格键,也就是向左删除键 |
| \c | 取消输出行末的换行符。和“-n”选项一致 |
| \e | ESCAPE键 |
| \f | 换页符 |
| \n | 换行符 |
| \r | 回车键 |
| \t | 制表符,也就是Tab键 |
| \v | 垂直制表符 |
| \0nnn | 按照八进制ASCII码表输出字符。其中0为数字零,nnn是三位八进制数 |
| \xhh | 按照十六进制ASCII码表输出字符。其中hh是两位十六进制数 |
使用实例:
(1)echo -e “ab\bc”
输出:ac 删除左侧字符
(2)echo -e "a\tb\tc\nd\te\tf"
输出:
a b c
d e f \t是制表符(tab) \n是换行符
(3)echo -e “\x61\t\x62\t\x63\n\x64\t\x65\t\x66”
输出:
a b c
d e f 按照十六进制ASCII码也同样可以输出
(4)echo -e "\e[1;31m abcd \e[0m"
输出:
红色的abcd
固定格式:\e[1 表示开启颜色区别 \e[0m 表示结束颜色区别 31m表示红色
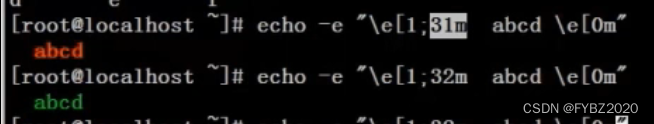
还有其他:
30m=黑色,31m=红色,32m=绿色,33m=黄色,34m=蓝色,35m=洋红,36m=青色,
37m=白色
2、脚本程序编写
新建脚本文件:#vim hello.sh
脚本文件内容:
#!/bin/Bash
#The first program
#Author: L78
echo -e ‘Hello World!’
注意:
#!/bin/Bash 这一条不能省略,它不是注释,是标识,它代表我以下写的程序是Shell,所有的Shell脚本都要写这样一句话。除了这一句,其他的#内容都是注释了
‘Hello World!’如果要加感叹号就得是单引号,如果没有感叹号才可以是双引号,这感叹号有意义。
3、脚本执行方式
编写好后的Shell脚本文件有两种执行方式:
(1)赋予执行权限,直接运行
#chmod 755 hello.sh
#./hello.sh
所有程序必须用绝对路径或者相对路径执行
(2)通过Bash调用执行脚本
#bash hello.sh
bash命令不需要给脚本文件执行权限就可以执行脚本。
如果从Windows里面拷贝一个脚本到Linux 虽然有的时候格式一样但是还是会报错,这便是因为两个系统中脚本的格式不同,比如Windows中的回车在脚本中用^M$表示,而Linux中为$,(可以用cat -A [文件名] 来查询)所以需要转换,此时用到一个命令:dos2unix [文件名],转换后,Linux就可以执行,通过没有这个命令可以使用yum安装。
(三)Bash的基本功能
1、历史命令与命令补全
#history [选项] [历史命令保存文件] 查看我们输入过的历史命令
-c: 清空历史命令
-w: 把缓存中的历史命令写入历史命令保存文件 ~/.bash_history
历史命令默认会保存1000条,可以在环境 变量配置文件/etc/profile中进行修改,找到HISTSIZE=1000进行修改,随意修改到100000条都可以,修改之后重启使配置文件生效
历史命令的调用
(1)使用上、下箭头调用以前的历史命令
(2)使用“!n”重复执行第n条历史命令
(3)使用“!!”重复执行上一条命令
(4)使用“!字串”重复执行最后一条以该字 串开头的命令
在Bash中,命令与文件补全是非常方便与常用的功能,我们只要在输入命令或文件时,按“Tab”键就会自动进行补全,命令补全功能建议经常使用,好处很多。
2、命令别名与快捷键
#alias 别名=‘原命令’ 设定命令别名
#alias 查询命令别名
命令执行时顺序
1 第一顺位执行用绝对路径或相对路径执行的命令。
2 第二顺位执行别名。
3 第三顺位执行Bash的内部命令。
4 第四顺位执行按照$PATH环境变量定义的 目录查找顺序找到的第一个命令。
删除别名
#unalias 别名
使命令别名永久生效的方法:
#vim /root/.bashrc 修改配置文件/root/.bashrc
Bash中常用快捷键
| 快捷键 | 作用 |
| ctrl+a | 把光标移动到命令行开头。如果我们输入的命令过长,想要把光标移 动到命令行开头时使用。 |
| ctrl+e | 把光标移动到命令行结尾。 |
| ctrl+c | 强制终止当前的命令。 |
| ctrl+l | 清屏,相当于clear命令。 |
| ctrl+u | 删除或剪切光标之前的命令。我输入了一行很长的命令,不用使用退 格键一个一个字符的删除,使用这个快捷键会更加方便 |
| ctrl+k | 删除或剪切光标之后的内容。 |
| ctrl+y | 粘贴ctrl+U或ctrl+K剪切的内容。 |
| ctrl+r | 在历史命令中搜索,按下ctrl+R之后,就会出现搜索界面,只要输入 搜索内容,就会从历史命令中搜索。 |
| ctrl+d | 退出当前终端。 |
| ctrl+z | 暂停,并放入后台。这个快捷键牵扯工作管理的内容,我们在系统管 理章节详细介绍。 |
| ctrl+s | 暂停屏幕输出 |
| ctrl+q | 恢复屏幕输出。 |
注意:ctrl+z 快捷键一定要谨慎使用,如果使用的多了,系统会占用大量存储空间来存放暂停的数据,用多了系统会变卡!!!
3、输入输出重定向
标准输入输出
| 设备 | 设备文件名 | 文件描述符 | 类型 |
|---|---|---|---|
| 键盘 | /dev/stdin | 0 | 标准输入 |
| 显示器 | /dev/sdtout | 1 | 标准输出 |
| 显示器 | /dev/sdterr | 2 | 标准错误输出 |
输出重定向
就是改变输出方向,比如由屏幕输出到文件,非常有用
| 类型 | 符号 | 作用 |
| 标准输出重定向 | 命令 > 文件 | 以覆盖的方式,把命令的正确输出输 出到指定的文件或设备当中。 |
| 标准输出重定向 | 命令 >> 文件 | 以追加的方式,把命令的 正确输出输出到指定的文 件或设备当中。 |
| 标准错误输出重定向 | 错误命令 2>文件 | 以覆盖的方式,把命令的 错误输出输出到指定的文 件或设备当中。 |
| 标准错误输出重定向 | 错误命令 2>>文件 | 以追加的方式,把命令的错误输出输出到指定的文件或设备当中。 |
在输入报错文件中 2和>>必选连着写,中间不能有空格。
标准错误输出不常用
| 类型 | 符号 | 作用 |
| 正确输出和错误输出同时保存 | 命令 > 文件 2>&1 | 以覆盖的方式,把正确输 出和错误输出都保存到同 一个文件当中。 |
| 正确输出和错误输出同时保存 | 命令 >> 文件 2>&1 | 以追加的方式,把正确输 出和错误输出都保存到同 一个文件当中。 |
| 正确输出和错误输出同时保存 | 命令 &>文件 | 以覆盖的方式,把正确输出和错误输出都保存到同一个文件当中。 |
| 正确输出和错误输出同时保存 | 命令 &>>文件 | 以追加的方式,把正确输出和错误输出都保存到同一个文件当中。 |
| 正确输出和错误输出同时保存 | 命令 >> 文件1 2>>文件2 | 把正确的输出追加到文件1中,把错误的输出追加到文件2中。 |
#命令 >> 文件 2>&1 ,#命令 &>>文件 两种保存都一样,只不过是格式不同
另一个用法:
#命令 &>/dev/unll 不管命令是否正确,直接丢人这个文件夹,不保存任何数据,在写shell脚本时有用
输入重定向
不通过键盘输入,通过文件输入,在实际中用的不多,用在给源码包打补丁
#wc [选项] [文件名]
-c 统计字节数
-w 统计单词数
-l 统计行数
用法:
# 命令 < 文件 把文件作为命令的输入
# 命令 << 标识符 一直输入,直到输入标识停止输入把标识符之间内容作为命令的输入
4、多命令顺序执行与管道符
| 多命令执行符 | 格式 | 作用 |
| ; | 命令1 ;命令2 | 多个命令顺序执行,命令之间没有任何逻辑联系,就算第一条报错,第二条也会执行 |
| && | 命令1 && 命令2 | 逻辑与,当命令1正确执行,则命令2才会执行 当命令1执行不正确,则命令2不会执行 |
| || | 命令1 || 命令2 | 逻辑或,当命令1 执行不正确,则命令2才会执行 当命令1正确执行,则命令2不会执行 |
使用符号,来设定多个命令的执行顺序。
磁盘文件复制:
#dd if=输入文件 of=输出文件 bs=字节数 count=个数
if=输入文件 指定源文件或源设备
of=输出文件 指定目标文件或目标设备
bs=字节数 指定一次输入/输出多少字节,即把这些字节看做 一个数据块
count=个数 指定输入/输出多少个数据块
这条命令可以把系统文件,磁盘都复制了,功能非常强大
使用多命令顺序例子:
#date ; dd if=/dev/zero of=/root/testfile bs=1k count=100000 ; date
管道符
#命令1 | 命令2 命令1的正确输出作为命令2的操作对象
用单竖杠表示管道符号
5、通配符与其它特殊符号
通配符是用来匹配文件名的。
| 通配符 | 作用 |
| ? | 匹配一个任意字符 |
| * | 匹配0个或任意多个任意字符,也就是可以匹配任何内容 |
| [] | 匹配中括号中任意一个字符。例如:[abc]代表一定匹配 一个字符,或者是a,或者是b,或者是c |
| [-] | 匹配中括号中任意一个字符,-代表一个范围。例如:[a-z] 代表匹配一个小写字母 |
| [^] | 逻辑非,表示匹配不是中括号内的一个字符。例如:[^0- 9]代表匹配一个不是数字的字符 |
Bash中的其它特殊符号及用途
| 符号 | 作用 |
| ‘ ’ | 单引号。在单引号中所有的特殊符号,如“$”和“`”(反引号)都 没有特殊含义。 |
| “ ” | 双引号。在双引号中特殊符号都没有特殊含义,但是“$”、“`” 和“\”是例外,拥有“调用变量的值”、“引用命令”和“转义符”的特殊含义。 |
| `` | 反引号。反引号括起来的内容是系统命令,在Bash中会先执行它。 和$()作用一样,不过推荐使用$(),因为反引号非常容易看错。 |
| $() | 和反引号作用一样,用来引用系统命令。 |
| # | 在Shell脚本中,#开头的行代表注释。 |
| $ | 用于调用变量的值,如需要调用变量name的值时,需要用$name 的方式得到变量的值。 |
| \ | 转义符,跟在\之后的特殊符号将失去特殊含义,变为普通字符。 如$将输出“$”符号,而不当做是变量引用。 |
(四)Bash变量
1、Bash变量简介
(1)变量是什么:
变量是计算机内存的单元,其中存放的值可以改变。当Shell脚本需要保存一些信息 时,如一个文件名或是一个数字,就把它 存放在一个变量中。每个变量有一个名字 ,所以很容易引用它。使用变量可以保存 有用信息,使系统获知用户相关设置,变量也可以用于保存暂时信息。
(2)变量设置规则:
- 变量名称可以由字母、数字和下划线组成 ,但是不能以数字开头。如果变量名是 “2name”则是错误的。
- 在Bash中,变量的默认类型都是字符串型 ,如果要进行数值运算,则必需指定变量类型为数值型。
- 默认变量类型全都是字符串型,和其他语言不太一样
- 变量用等号连接值,等号左右两侧不能有空格。
- 变量的值如果有空格,需要使用单引号或双引号包括。
- 在变量的值中,可以使用“\”转义符。
- 如果需要增加变量的值,那么可以进行变量值的叠加。不过变量需要用双引号包含 “$变量名”或用${变量名}包含。
- 如果是把命令的结果作为变量值赋予变量 ,则需要使用反引号或$()包含命令。
- 环境变量名建议大写,便于区分。
(3)变量的分类:
- 用户自定义变量
- 环境变量:这种变量中主要保存的是和系统操作环境相关的数据。
- 位置参数变量:这种变量主要是用来向脚本当 中传递参数或数据的,变量名不能自定义,变量作用是固定的。
- 预定义变量:是Bash中已经定义好的变量,变量名不能自定义,变量作用也是固定的。
2、用户自定义变量(本地变量)
(1)变量定义
#name=“yang yang”
(2)变量叠加
#aa=123
#aa="$aa"456
#aa=${aa}789
(3)变量调用
#echo $变量名
(4)变量查看
#set
(5)变量删除
#unset 变量名