一、ChatGPT 是什么
-
ChatGPT 是由 OpenAI 开发的一种基于语言模型的人工智能程序,它可以与人类进行自然语言交互。
-
基于 GPT(Generative Pre-trained Transformer)技术构建。
-
GPT 代表“生成式预训练”,它是一种基于深度学习的自然语言处理技术,利用海量的语言数据进行预训练,从而能够在多个自然 语言任务上表现出色。
1.1、ChatGPT如何使用?
ChatGPT能做的事情非常多,从普通的知识性问答,聊天,对话、教学、科研及时代码生成、代码分析、Debug的能力,ChatGPT都是具备的。
ChatGPT是一个融合了巨量人类智慧的超级结晶体,拥有了它,你可以随时获取任何领域的知识,ChatGPT通过理解你的问题,整理汇总出比较简单的、简洁的答案输出,这比我们平时自己去百度、Google搜索然后自己汇总有非常明显的优势,所以ChatGPT这种超强的知识提取和总结能力,真的很令人惊艳,如何使用ChatGPT才能最大化它的作用。
简单的说,其实就是一句话,提出好的问题,对于ChatGPT来说,问题比答案更重要,因为GPT模型本身就是基于提示(Prompt)来起作用的,它的回答,取决于你给他的提示的内容和质量,那么怎么才能提出好的问题呢?
1)、增加细节(增加提示的细节和要求)
2)、不断追问(基于ChatGPT生成的内容不断追问)
3)、心存疑问(对于ChatGPT的回答不能盲目相信)

1.2、ChatGPT 是万能的吗?
ChatGPT不是万能的,它的回答没有经过验证,因为这是它的模型自动推理产生的,这就是深度学习神经网络的局限性,在上亿、百亿、甚至千亿的网络参数中,我们不可能知道是哪些参数在发挥作用,也就是说我们不可能知道它的答案到底有多准确,所以ChatGPT本身也有几个明显的问题:
1)、中文训练语料库比英文训练语料库要少,所以中文知识也少
2)、它无法给出这个信息提供的来源,这就跟百度和Google有本质的不同,在搜索引擎中,我们知道文章是谁写的,所以ChatGPT只能使用它训练的知识
3)、无法获取最新的数据,只能获取训练时间节点的数据来提供知识
当然,以上存在的局限性可能会随着ChatGPT不断的训练和进化,它的答案会越来越好,但是答案可能出错的可能性是永远存在的。
当一个人一本正经说的时候,我们很容易就觉得他是在说真话,如果他说了很多真话之后,偶尔说几句假话,就非常具有欺骗性了,这就是ChatGPT的问题,所以大家在使用ChatGPT的时候一定要有批判性思维,不能盲从,必须要对答案进行验证。
1.3、ChatGPT 的底层原理
我们可以让ChatGPT自己来回答一下这个问题吧,目前来看最新的GPT模型回答还算比较准确。

我们都知道两个非常经典的深度学习模型,一个是RNN,一个是LSTM,循环神经网络,长短时记忆网络主要用于处理序列类型数据的经典模型,而ChatGPT是基于比这两个模型更新的Transformer架构。
二、预训练大语言模型的发展
2.1、Transformer 架构出现之前
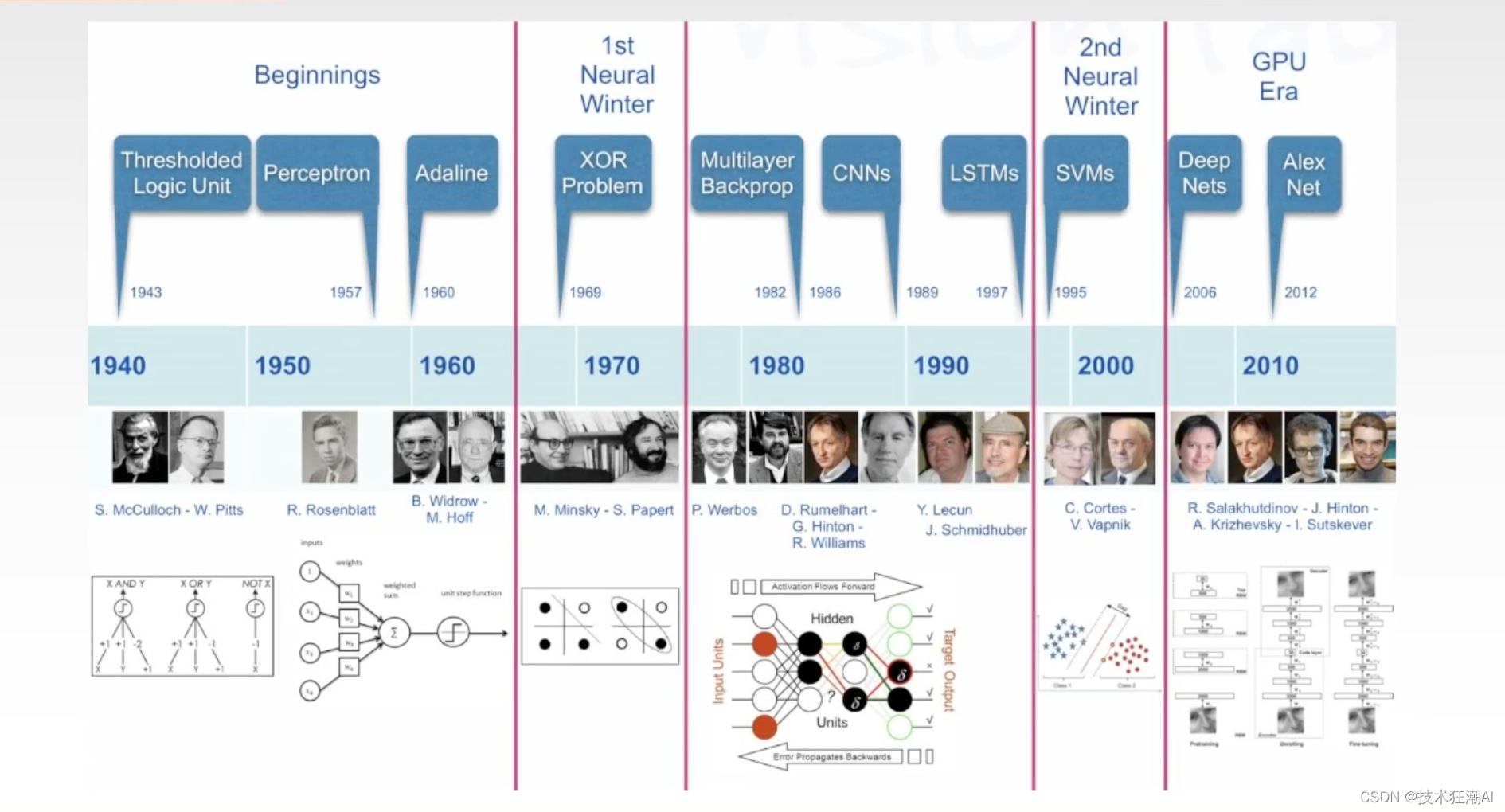
在Transformer架构和与训练大模型出现之前,NLP历史上已经有很多思潮的涌现和发展了,深度学习在NLP领域的突破其实是比较晚的,最早深度学习的突破都集中在计算机视觉领域。
从2012年开始,AlexNet模型在ImageNet图像识别大赛中,取得了很大的突破,这个标志着CNN卷积神经网络的兴起,后来有GoogleNet、VGG ResNet各种深度学习模型的出现,大幅度的提升了图像分类,目标检测、语义分割等CV任务的准确性,在目标检测人脸识别有R-CNN、Fast R-CNN、YOLO SSD一系列算法;语义分割方面也有SENet UNet,再加上生成对抗网络GAN的出现,然后DCGAN、PsychoGAN这种图像生成、风格迁移领域都取得了非常显著的进展。
所以,在2018年以前,CV的发展是风生水起,在NLP领域,虽然有RNN和LSTM,但是并没有特别多的真正落地应用的突破性进展。
是什么带来了NLP领域第一轮的飞跃呢? 到了2018年之后,两个核心技术就产生了,一个就是Transformer,另外一个就是BERT,随着这两个模型的诞生,NLP的节奏逐渐就追上来了,紧接着一系列的与训练大模型像雨后春笋个般的出现了,我们就可以下载这些与训练大模型,然后通过微调,在自己的自然语言处理任务上去使用它们,这里的自然语言处理任务就是我们实际的问题,比如语音识别、文本分类、情感分类、命名实体识别、机器翻译、文本摘要、文本生成等。
2.2、用深度神经网络解决 NLP 问题
深度神经网络是怎么解决这种自然语言处理实际问题的呢,深度神经网路其实是由很多层组成的,每一层都有很多神经元,也就是节点,每个节点都有一系列参数,数据输入模型的时候,这些节点就通过这些参数对自然语言处理的数据进行运算,其实从输入空间到输出空间都有对应的函数和一个映射。
比如我们要做微博的情感分类任务,每条微博200字,我们就需要把200字转化为200个token输入进去,那输入序列就是200维,然后经过神经网络所代表的函数、经过参数的计算,最后给你输出一个二维的结果,比如0或者1,0就代表博主的情绪比较负面,1代表博主的情绪是正面的,这就是一个典型的NLP分类任务。
其实整个机器学习就是把它抽象出来变成一个函数的形式,我们去理解深度神经网络也不会那么复杂。
2.3、大型预训练网络 Before 2021

从早起的预训练网络ELMo开始到2021年左右,这个时期的预训练网络发展历程,可以看到预训练网络越来越大,从初代的GPT、初代的BERT到后面的RoBERTTa、BART、T5一个清晰的趋势就是模型变得越来越大,参数越来越多,它所训练的语料库也就越来越大。
比如BERT就是基于Wikidata来训练的,后面的模型就又收录了更多的公开的书籍、网络上的一些文本、语料变得越来越庞大,它的知识库也就越来越大,这是一个很典型的趋势。
2.4、大型预训练网络 As of Dec 2022
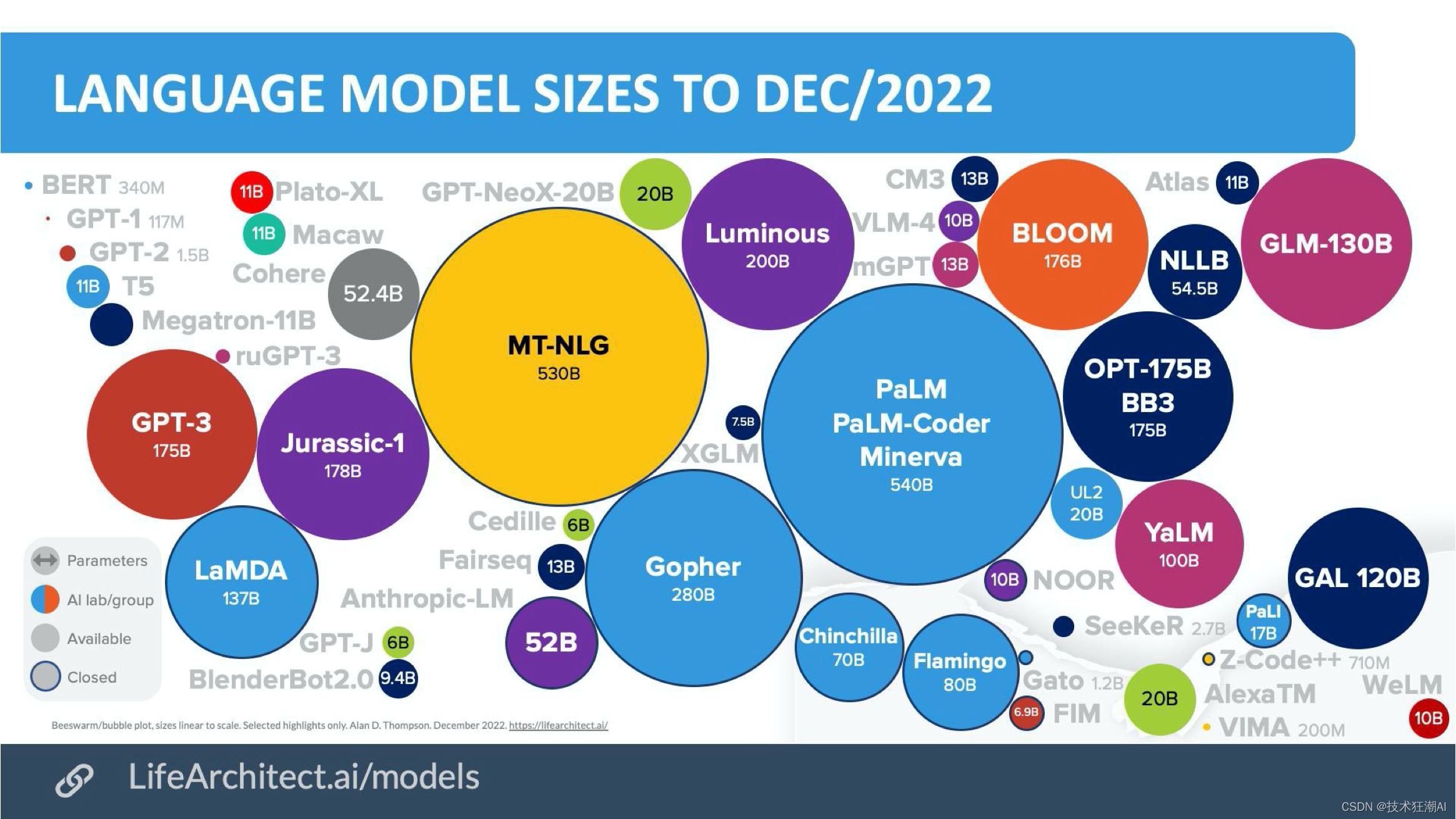
截止到2022年12月,此刻的预训练大模型就已经非常庞大了,ChatGPT所基于的GPT-3模型,它有1750亿个参数,在整个大语言模型的生态中,它还不算事最大的模型,但它的效果可能超过其它更大的模型。
2.5、Transformer 架构
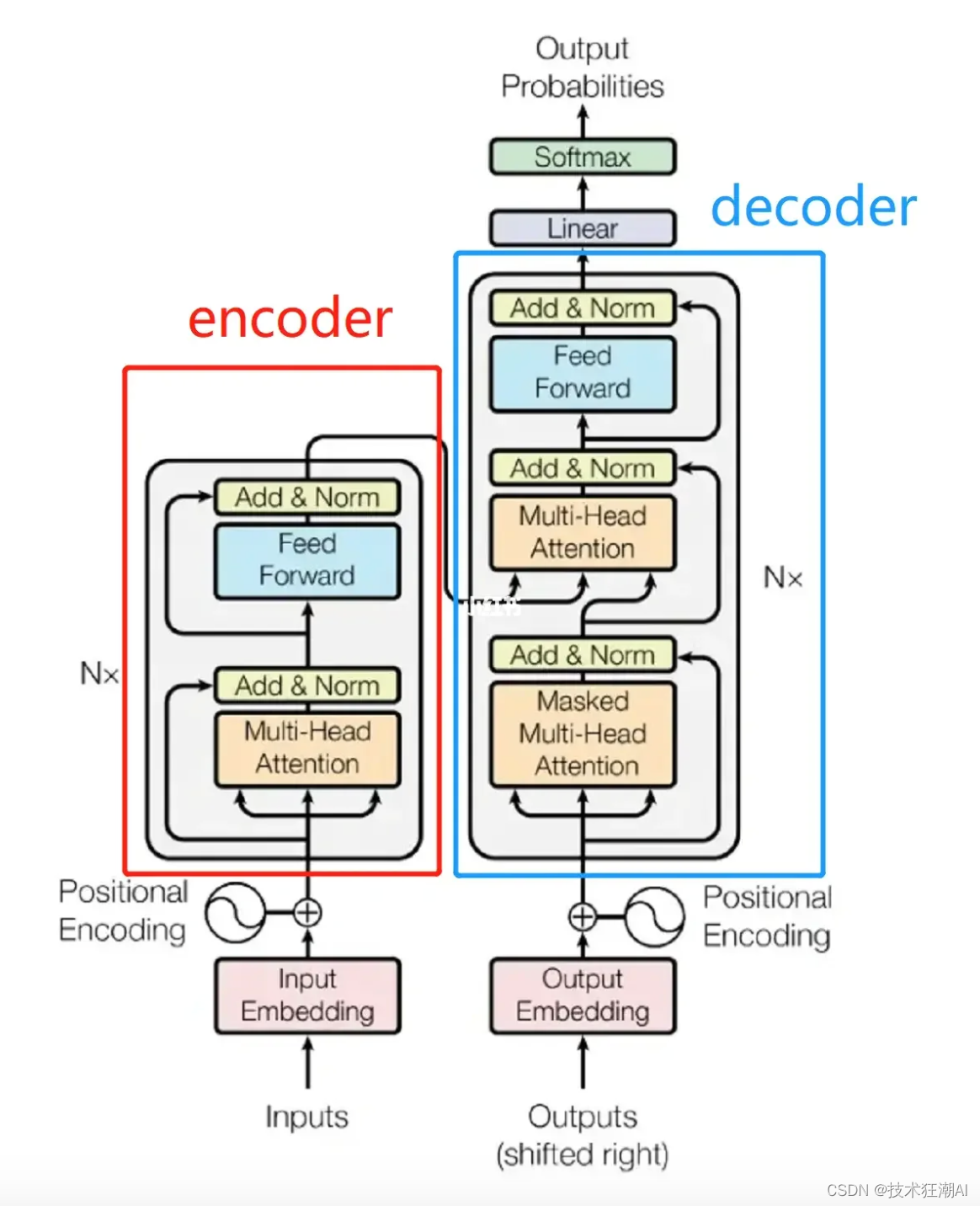
Transformer架构是所有预训练语言模型的基础,它是自然语言处理的神经网络,当然,Transformer架构现在已经延展到了CV和其它领域,很多处理自然语言处理之外的问题,也都采取了Transformer架构来解决。
它最早是由Google在 2017 年提出,它的目的就是解决传统训练模型,就是循环神经网络中存在的效率问题和并行计算问题。 因为Transformer模型使用了自注意力机制(self-attention)来捕捉输入序列的上下文关系,所以它就使得每个词都能够建立和整个序列其它词之间的连接,从而它就可以有效的捕捉文本中的长距离依赖关系,它不需要像RNN这样来循环的一直去用递归的方式回访过去的数据,所以它跟传统的神经网络相比,它快,它不需要一个词接一个词地处理,它是做整体的并行处理,所以它在训练速度和上下文捕捉这种性能方面的表现都更加优秀。
另外一点就是,Transformer架构它还可以通过堆叠多个层来构建深度学习模型,所以它也是一种深度学习模型,它能够堆叠,所以它就能够不断的来扩大规模,进一步提高模型的性能,现在最新的研究表示,模型越大,它就越有可能出现更多的涌现能力(不知道什么能力就突然被解锁了),就好比今天这个模型还不能对话,随着模型的参数越来越大,层数越来越多的时候,它突然可能就拥有了和你流畅对话的能力,这是一个很不可思议的事情。
所以,现在Transformer模型在NLP任务中已经全面取代了RNN为代表的循环神经网络模型,循环神经网络模型在实际的应用中,以后就不多了。
2.6、Seq2Seq:序列到序列
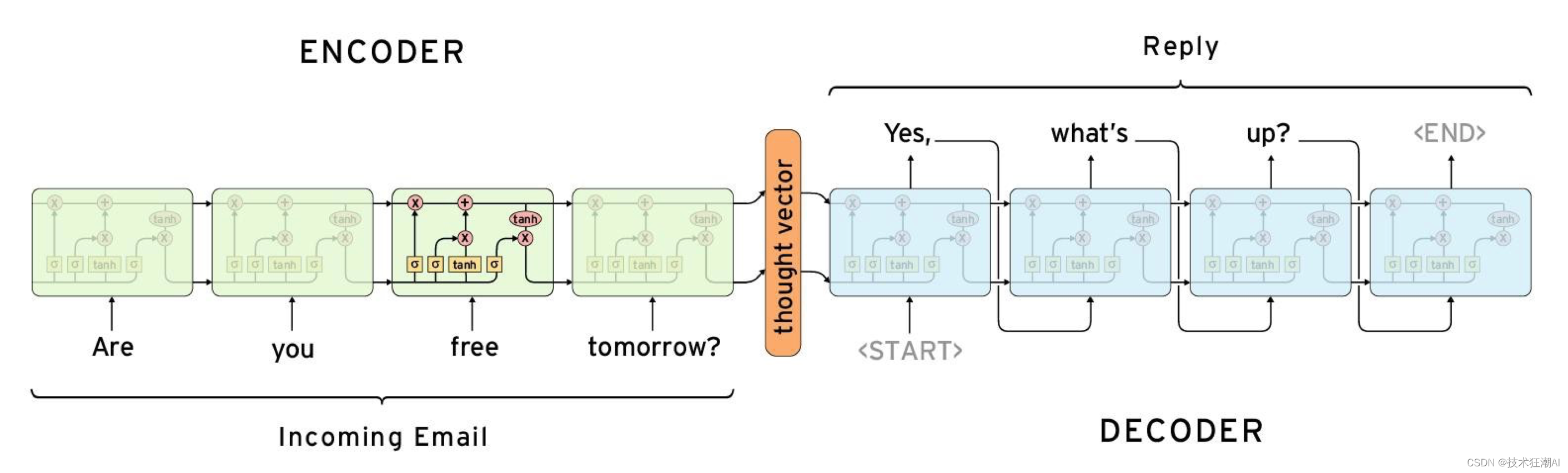
Transformer本身是一种序列到序列的架构,在Seq2Seq架构中,输入的序列会被深度神经网络处理产生一个输出的文本序列,比如机器翻译、聊天机器人就是很典型的场景。
序列到序列有两个结构,一个是编码器,一个是解码器,其中编码器负责将输入序列编码成一个固定长度的向量表示,然后解码器需要负责把这个向量再生成对应的输出序列,在一个ChatBox中,输入序列通常就是用户的提问,输出序列就是ChatBox的回答或者响应了,这其实就是一个把编码给逐渐解码,然后形成我们最后所需要的答案的一个过程。
当我们训练的时候就会给它一些语料, 一个问题的答案应该是怎么样的,它看到这些就自己不断的纠错,然后神经网络就会给出越来越接近我们期望的答案。
2.7、BERT vs GPT
两个最经典的基于Transformer的预训练模型,Google的BERT模型和OpenAI的GPT-3
BERT
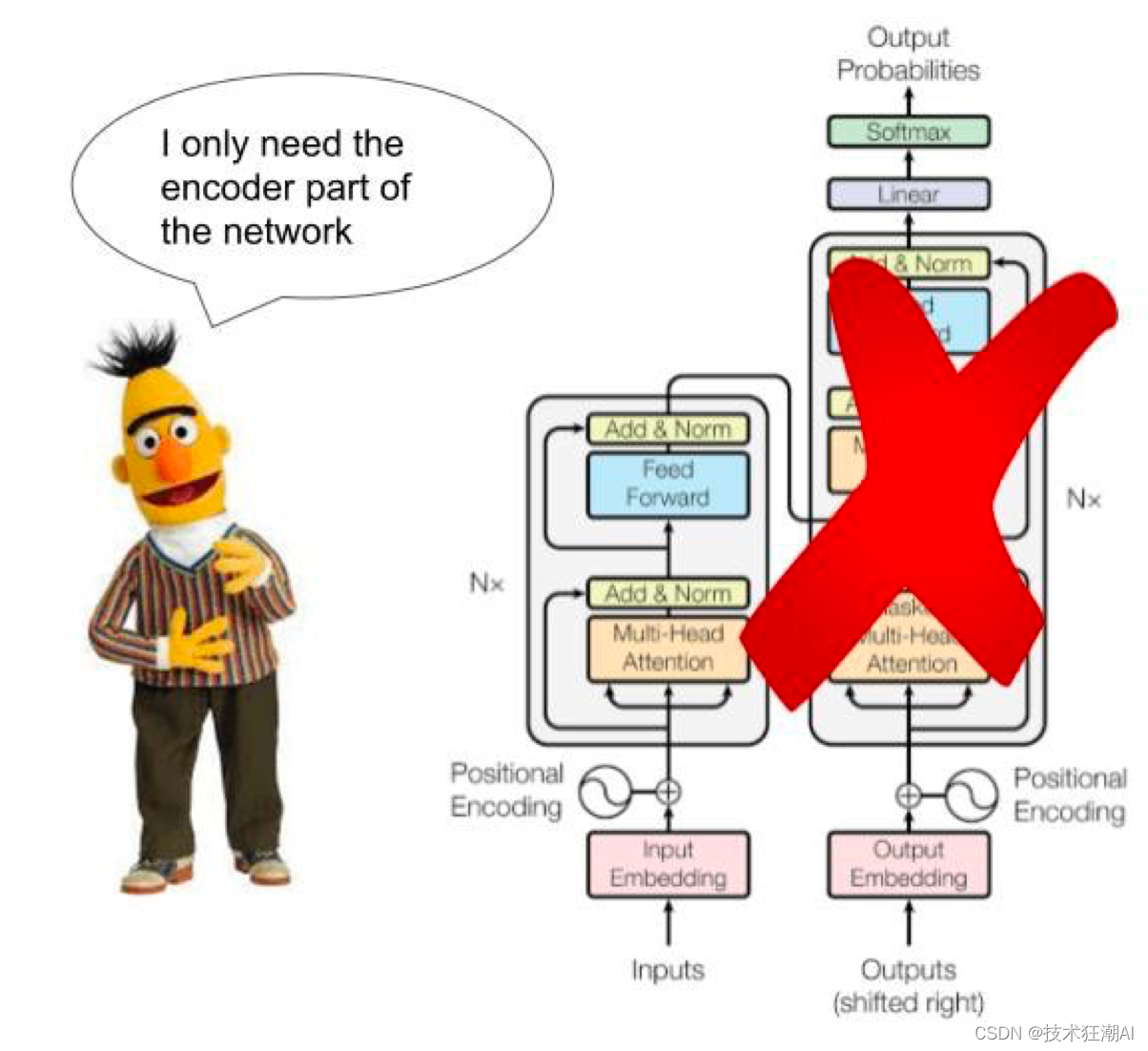
1)、Bidirectional Encoder Representations from Transformers
——双向编码,同时考虑了左右两边的词
2)、Masked Language Model(MLM)——擅长做完形填空
3)、Next Sentence Prediction(NSP)——是不是下一句
4)、Fine-tuning ——微调完成下游任务
BERT只需要编码器的内容,不需要生成文本。
GPT-3
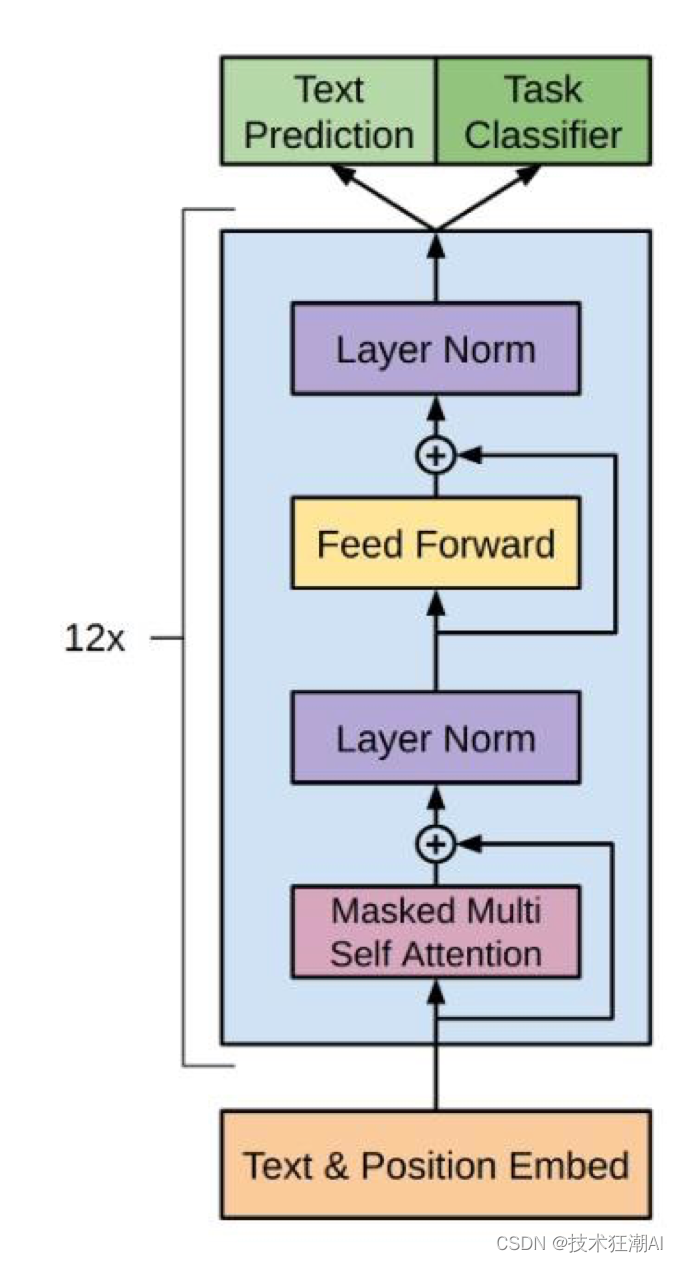
1)、Generative Pre- trained Transformer 生成式
2)、Autoregressive 自回归
3)、Prompt/Instruction 基于提示/指令,完成下游任务
BERT和GPT两个模型没有优劣而言,它是针对不同的任务类型设计的,BERT比较擅长于掌控全局,它就能够做很好的自然语言推理任务,比如情感分类、完形填空、命名实体识别、关系抽取这些都依赖优秀的全文理解能力;而GPT它的目标就是文本生成,所以对于聊天机器人或者问答系统来说,它就有比较天然的优势了。
2.8、从 GPT 到 ChatGPT 的演变
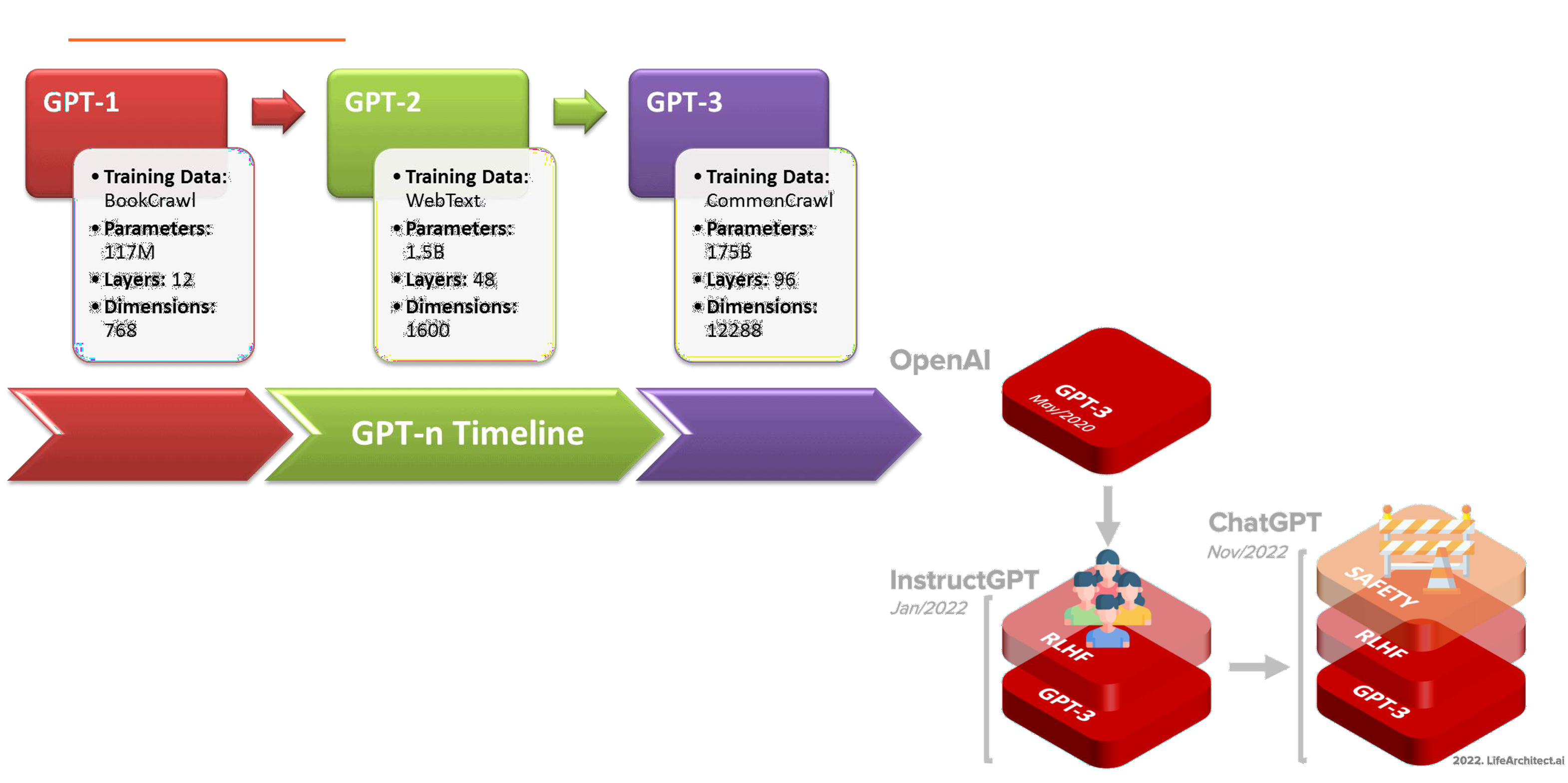
GPT是OpenAI的序列生成模型系列,能够产生高质量的自然语言文本。从GPT-1到GPT-3,它的原理其实是很类似的,但是它的参数数量每次都是翻很多倍的增长,GPT-2到GPT-3,参数翻了100倍,输入数据维度也翻了接近8倍,可以使它一次性理解很多很多的token,也就是一次性输入很大的文本都可以同时理解。
到了GPT-3的时候,已经能够生成非常流畅、准确的自然语言文本了,它生成的文本质量基本能够跟人类的写作相媲美,参数数量增加的好处就是让它能够更好的学习自然语言的规律,能够理解序列中更多的上下文信息,生成更连贯更准确的文本,GPT-3还增加了多语言的支持,能够处理更复杂的任务。
ChatGPT是怎么从GPT-3模型的基础上再进一步演进的呢? 因为它是GPT-3模型上转么负责聊天机器人任务上的应用,它是GPT-3.5,叫做3.5优化版,它作为GPT的第三代,在万亿词汇量通用文字数据集上面训练完成的。
它还有另一个兄弟模型,叫InstructGPT,都是建立在GPT-3.5基础上,为了让ChatGPT表现出色,OpenAI对预训练数据集还做了微调,给它增加了基于人类反馈的强化学习,让它更能够了解人类想听什么,能够更好的处理哪些是人类想要的答案。
ChatGPT在InstructGPT基础上又增加了一层Stafety Layer,因为它是一个面向大众的聊天工具,它不能说错话,不能够说危害公众安全的回复,不可以宣传不应该宣传的东西,这个很重要,要控制它的回答是合理的。
三、ChatGPT 的训练过程
ChatGPT系列模型的基本思路是让AI在通用的数据上学习文字接龙,掌握生成后续文本的能力,这样的训练有一个好处,就是它不需要人类去标注,只需要把一大堆的语料库输给它,它就会自己去训练,然后你可以给它打分,遮住下文让它去预测。

一个问题可能有很多个答案,作为一个聊天对话机器人来说,我们想得到比较确定性的答案,GPT在进行文本生成的时候,需要进行一些人类的指导,让人类告诉它,什么样的回答才是我最想听到的,这就是基于人类反馈的训练的核心思路。它的RLHF训练过程主要有三步:
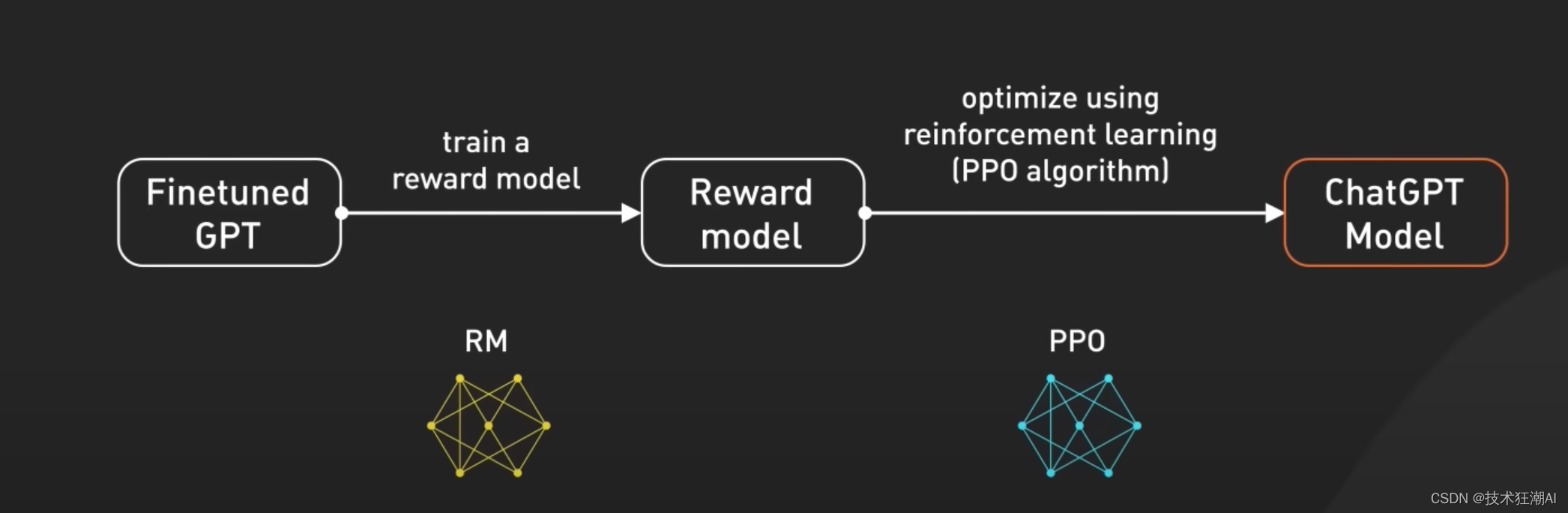
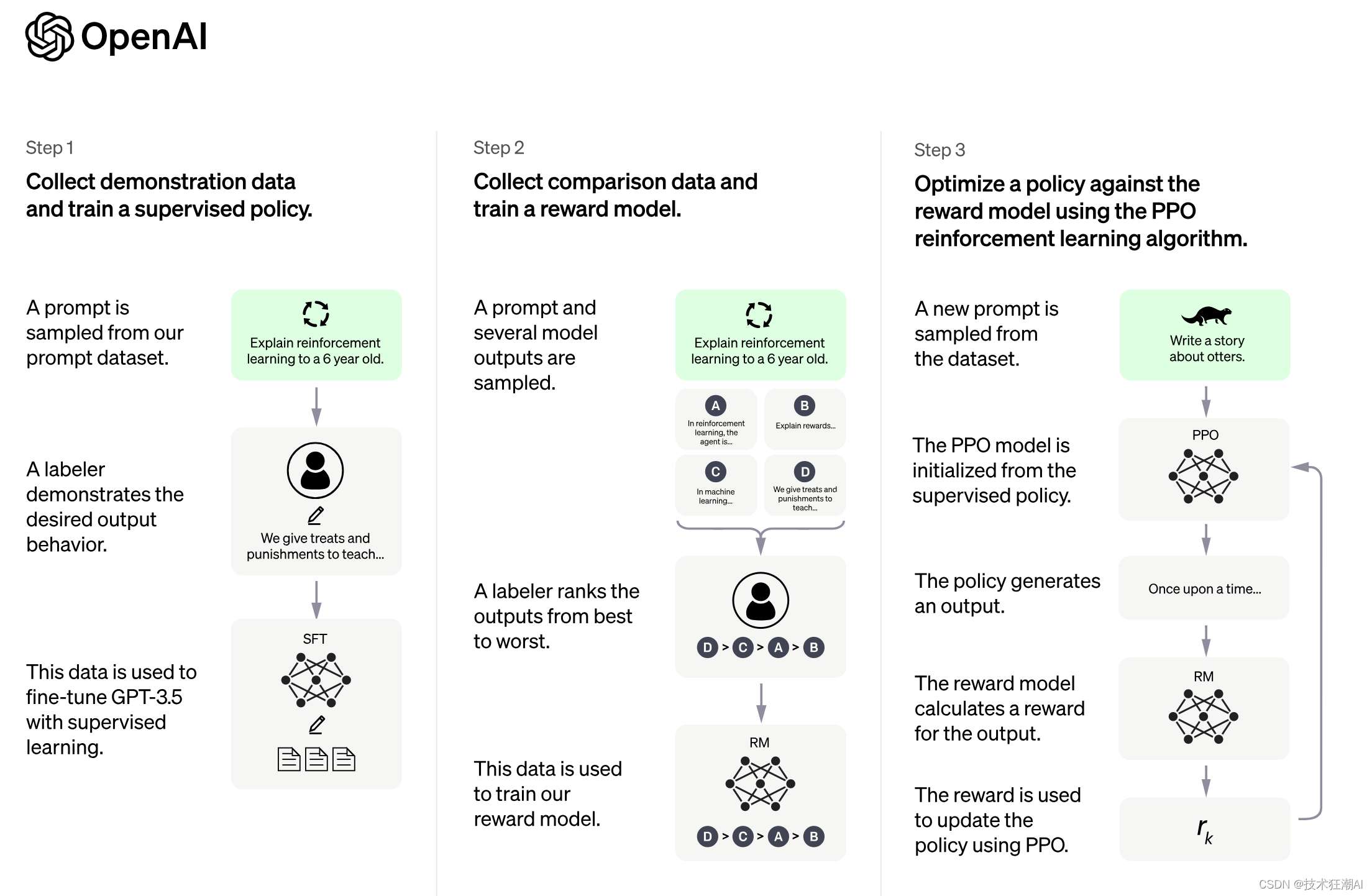
3.1、监督调优模型
收集演示数据,用监督学习去训练生成规则(把一些问题写出答案,把问题和答案都丢给GPT去训练,这个是有监督的训练,已经有答案了,让AI一葫芦画瓢,这种方法可以引导AI往人类所期望的方向去做答)
但是,我们不可能人工穷举出所有可能的问题和答案,这个显然是不现实的,所以OpenAI只是提供了可能几万个这种有答案的数据,主要是为了让它在这个基础上进行泛化,然后提供一个方向上的引导,就是告诉模型,你就往这个方向上去答。
3.2、训练回报模型
让简化版的GPT监督训练之后变得更强,通过人工标注所有输出的优劣势
先让ChatGPT输出很多个答案,然后基于它所生成的答案给他排序,我们只需要人工标注哪个答案是最好的,所以OpenAI做了大量的这种标注,
3.3、使用 PPO 模型微调 SFT 模型
通过PPO强化学习算法,实现模型的自我优化,强化学习就是让AI在不断的试错过程中自我调整优化策略,然后最大化预期的长期奖励,简单来说,就是让AI自己去不断尝试,前两步学习的模型在强化学习这一步都能派上用场。
首先用监督版学习的ChatGPT来初始化PPO模型,让Reward模型去指导它,去给回答一个评分,然后AI就基于这个评分去调整自己的参数,试图在下一个回答中得到更高的分数,不断的重复这个过程,这个幼儿版的ChatGPT就成熟起来了,能够自我更新了。
经历这样的三个步骤,一个真正的ChatGPT就训练好了,就能形成我们人类更期待的回答。