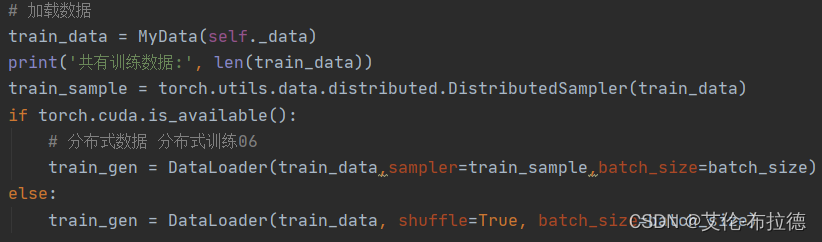
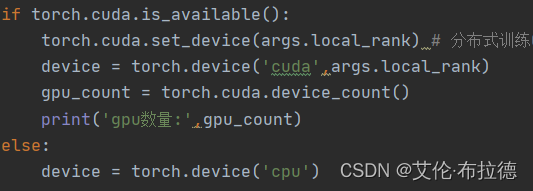
pytorch中共有两种多GPU的训练方法,一种是利用nn.DataParallel实现,实现简单,另一种是用采用分布式并行训练DistributedDataParallel和DistributedSampler结合多进程实现。
torch.nn.DataParallel(DP)
首先说下DP中的参数:
(1) module即表示你定义的模型
(2) device_ids表示你训练时用到的gpu device
(3) output_device这个参数表示输出结果的device,默认就是在第一块卡上,因此第一块卡的显存会占用的比其他卡要更多一些。
当调用nn.DataParallel的时候,input数据是并行的,但是output loss却不是这样的,每次都会在output_device上相加计算,这就造成了第一块GPU的负载远远大于剩余其他的显卡。
DP的优势是实现简单,不涉及多进程,核心在于使用nn.DataParallel将模型wrap一下,代码其他地方不需要做任何更改。
DP的整个过程是,首先在前向过程中,你的输入数据会被划分成多个子部分(以下称为副本)送到不同的device中进行计算,而你的模型module是在每个device上进行复制一份,也就是说,输入的batch是会被平均分到每个device中去,但是你的模型module是要拷贝到每个devide中去的,每个模型module只需要处理每个副本即可,然后再将每张卡上的输出都收集到output_device(默认为cuda:0)上并合。

概括来说就是:DataParallel 会自动帮我们将数据切分 load 到相应 GPU,将模型复制到相应 GPU,进行正向传播计算梯度并汇总到output_device上汇总。
可以看出,nn.DataParallel没有改变模型的输入输出,因此其他部分的代码不需要做任何更改,非常方便。但弊端是,后续的loss计算只会在output_device上进行,没法并行,因此会导致负载不均衡的问题。
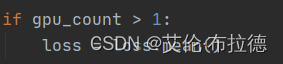
另外需要注意,使用多GPU时,loss需要mean。
DistributedDataParallel(DDP)
分布式数据并行(distributed data parallel),是通过多进程实现的。
(1)从一开始就会启动多个进程(进程数等于 GPU 数),每个进程独享一个 GPU,每个进程都会独立地执行代码。这意味着每个进程都独立地初始化模型、训练,当然,在每次迭代过程中会通过进程间通信共享梯度,整合梯度,然后独立地更新参数。
(2)数据并行。
(3)进程通过local_rank变量来标识自己,local_rank为0的为master,其他是slave。
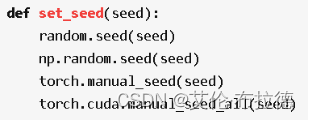
(4)因为每个进程都会初始化一份模型,为保证模型初始化过程中生成的随机权重相同,需要设置随机种子。
(5)模型保存时,可以只用保存local_rank为0,也就是master的模型结构即可。
要实现分布式数据训练必须以如下方式运行代码:
其中,nproc_per_node表示机器需要创建多少个进程(使用几个GPU就创建几个);nnodes表示机器数量。