1、窗口函数的分类
窗口函数,即数据划分窗口后可以调用的处理函数。
l 全量函数:窗口先缓存所有元素,等到触发条件后对窗口内的全量元素执行计算。
l 增量函数:窗口保存一份中间数据,每流入一个新元素,新元素与中间数据两两合一,生成新的中间数据。
2、增量聚合函数
指窗口每进入一条数据就计算一次
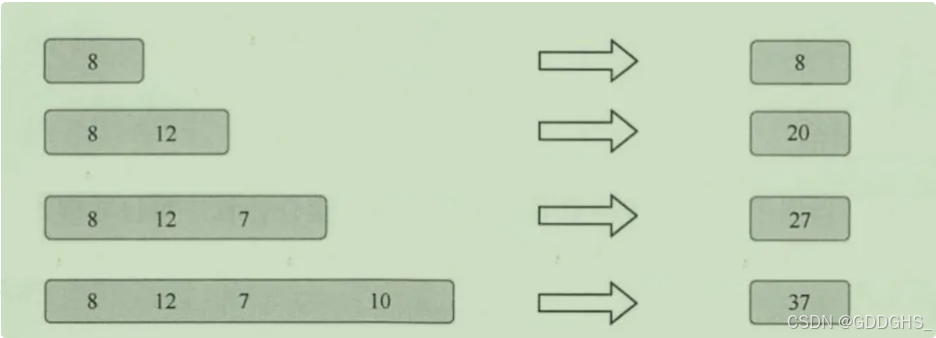
实现方法(常见的增量聚合函数如下):
reduce(reduceFunction)
aggregate(aggregateFunction)
sum()
min()
max()reduce接受两个相同类型的输入,生成一个同类型输出,所以泛型就一个 <T>
maxBy、minBy、sum这3个底层都是由reduce实现的
aggregate的输入值、中间结果值、输出值它们3个类型可以各不相同,泛型有<T, ACC, R>
AggregateFunction 【了解】
AggregateFunction 比 ReduceFunction 更加的通用,它有三个参数:输入类型(IN)、累加器类型(ACC)和输出类型(OUT)。
输入类型是输入流中的元素类型,AggregateFunction有一个add方法可以将一个输入元素添加到一个累加器中。该接口还具有创建初始累加器(createAccumulator方法)、将两个累加器合并到一个累加器(merge方法)以及从累加器中提取输出(类型为OUT)的方法。
package com.bigdata.windows;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class _04_AggDemo {
public static final Tuple3[] ENGLISH = new Tuple3[] {
Tuple3.of("class1", "张三", 100L),
Tuple3.of("class1", "李四", 40L),
Tuple3.of("class1", "王五", 60L),
Tuple3.of("class2", "赵六", 20L),
Tuple3.of("class2", "小七", 30L),
Tuple3.of("class2", "小八", 50L)
};
public static void main(String[] args) throws Exception {
//1. env-准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setParallelism(1);
//2. source-加载数据
DataStreamSource<Tuple3<String,String,Long>> dataStreamSource = env.fromElements(ENGLISH);
KeyedStream<Tuple3<String,String,Long>, String> keyedStream = dataStreamSource.keyBy(new KeySelector<Tuple3<String,String,Long>, String>() {
@Override
public String getKey(Tuple3<String,String,Long> tuple3) throws Exception {
return tuple3.f0;
}
});
//3. transformation-数据处理转换
// 三个参数:输入类型(IN)、累加器类型(ACC)和输出类型(OUT)
keyedStream.countWindow(3).aggregate(new AggregateFunction<Tuple3<String,String,Long>, Tuple3<String,Long,Integer>, Tuple2<String,Double>>() {
// 初始化一个中间变量
Tuple3<String,Long,Integer> tuple3 = Tuple3.of(null,0L,0);
@Override
public Tuple3<String,Long,Integer> createAccumulator() {
return tuple3;
}
@Override
public Tuple3<String,Long,Integer> add(Tuple3<String, String, Long> value, Tuple3<String,Long,Integer> accumulator) {
long tempScore = value.f2 + accumulator.f1;
int length = accumulator.f2 + 1;
return Tuple3.of(value.f0, tempScore,length);
}
@Override
public Tuple2<String, Double> getResult( Tuple3<String,Long,Integer> accumulator) {
return Tuple2.of(accumulator.f0,(double) accumulator.f1 / accumulator.f2);
}
@Override
public Tuple3<String, Long, Integer> merge(Tuple3<String, Long, Integer> a, Tuple3<String, Long, Integer> b) {
return Tuple3.of(a.f0,a.f1+b.f1,a.f2+b.f2);
}
}).print();
//4. sink-数据输出
//5. execute-执行
env.execute();
}
}3、全量聚合函数
指在窗口触发的时候才会对窗口内的所有数据进行一次计算(等窗口的数据到齐,才开始进行聚合计算,可实现对窗口内的数据进行排序等需求)
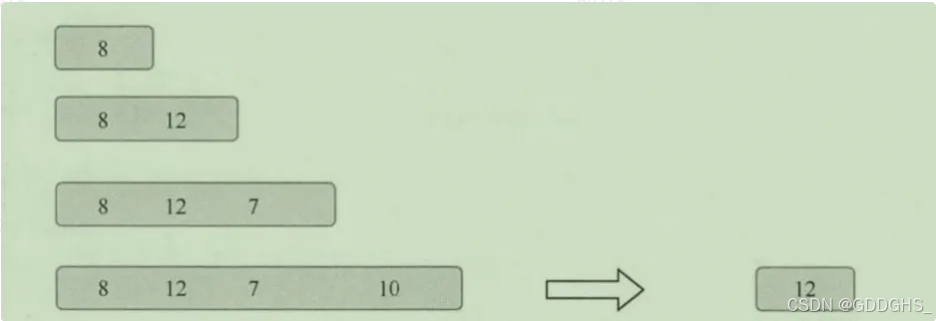
实现方法
apply(windowFunction)
process(processWindowFunction)
全量聚合: 窗口需要维护全部原始数据,窗口触发进行全量聚合。
ProcessWindowFunction一次性迭代整个窗口里的所有元素,比较重要的一个对象是Context,可以获取到事件和状态信息,这样我们就可以实现更加灵活的控制,该算子会浪费很多性能,主要原因是不增量计算,要缓存整个窗口然后再去处理,所以要设计好内存。package com.bigdata.day04;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow;
import org.apache.flink.util.Collector;
public class Demo03 {
public static void main(String[] args) throws Exception {
//1. env-准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//2. source-加载数据
Tuple3[] ENGLISH = new Tuple3[] {
Tuple3.of("class1", "张三", 100L),
Tuple3.of("class1", "李四", 40L),
Tuple3.of("class1", "王五", 60L),
Tuple3.of("class2", "赵六", 20L),
Tuple3.of("class2", "小七", 30L),
Tuple3.of("class2", "小八", 50L)
};
// 先求每个班级的总分数,再求每个班级的总人数
DataStreamSource<Tuple3<String,String,Long>> streamSource = env.fromElements(ENGLISH);
KeyedStream<Tuple3<String, String, Long>, String> keyedStream = streamSource.keyBy(v -> v.f0);
// 每个分区中的数据都达到了3条才能触发,哪个分区达到了三条,哪个就触发,不够的不计算
// //Tuple3<String, String, Long> 输入类型
// //Tuple2<Long, Long> 累加器ACC类型,保存中间状态 第一个值代表总成绩,第二个值代表总人数
// //Double 输出类型
// 第一个泛型是输入数据的类型,第二个泛型是返回值类型 第三个是key 的类型, 第四个是窗口对象
keyedStream.countWindow(3).apply(new WindowFunction<Tuple3<String, String, Long>, Double, String, GlobalWindow>() {
@Override
public void apply(String s, GlobalWindow window, Iterable<Tuple3<String, String, Long>> input, Collector<Double> out) throws Exception {
// 计算总成绩,计算总人数
int sumScore = 0,sumPerson=0;
for (Tuple3<String, String, Long> tuple3 : input) {
sumScore += tuple3.f2;
sumPerson += 1;
}
out.collect((double)sumScore/sumPerson);
}
}).print();
//5. execute-执行
env.execute();
}
}