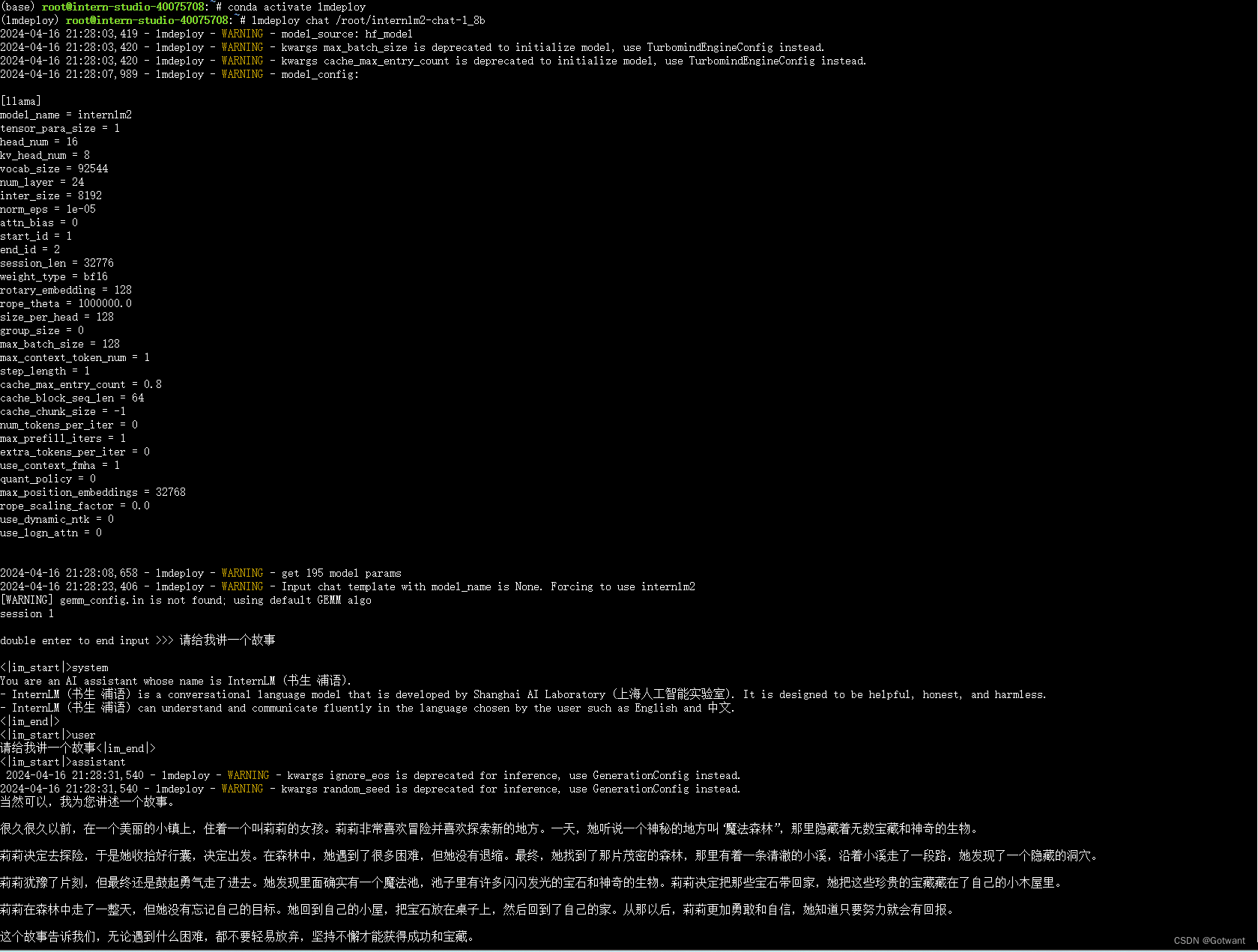
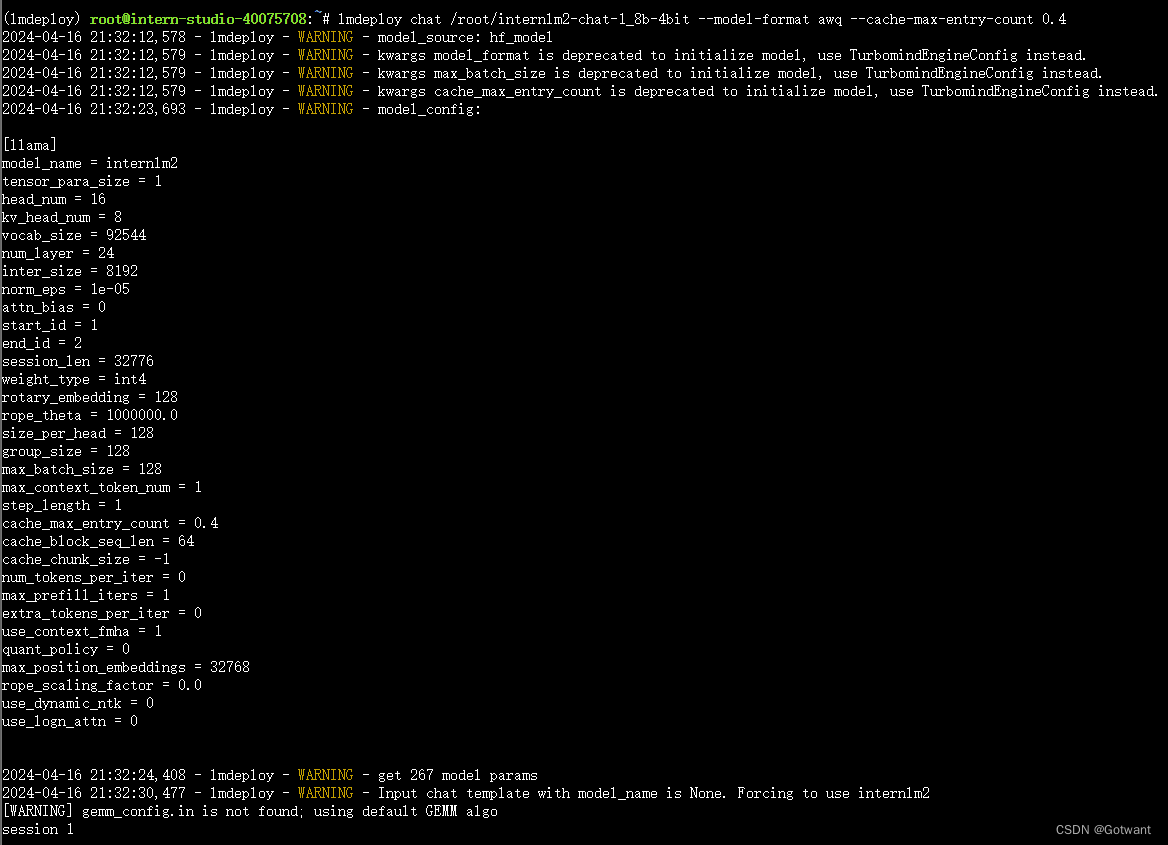
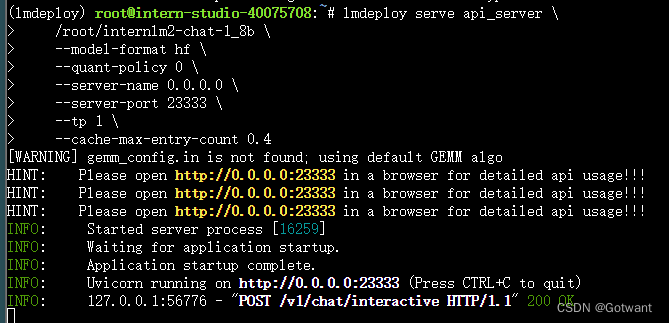
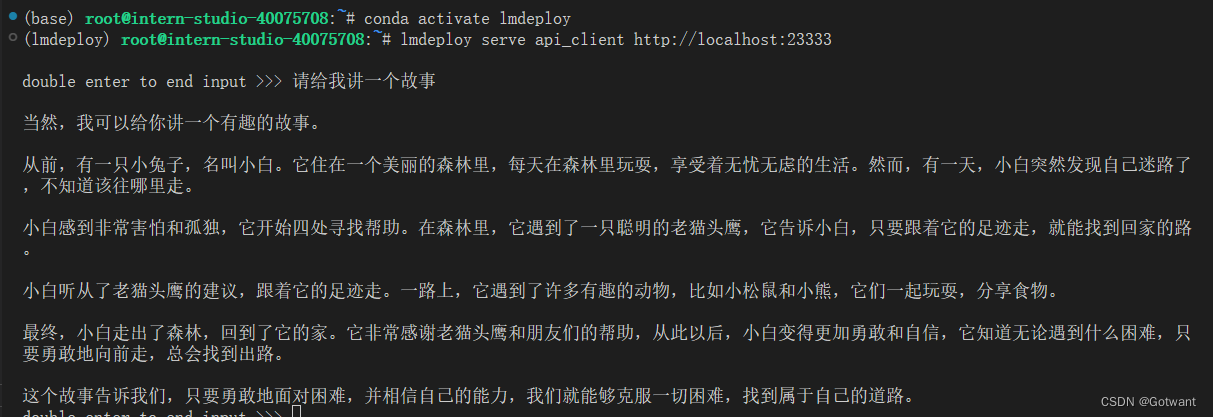
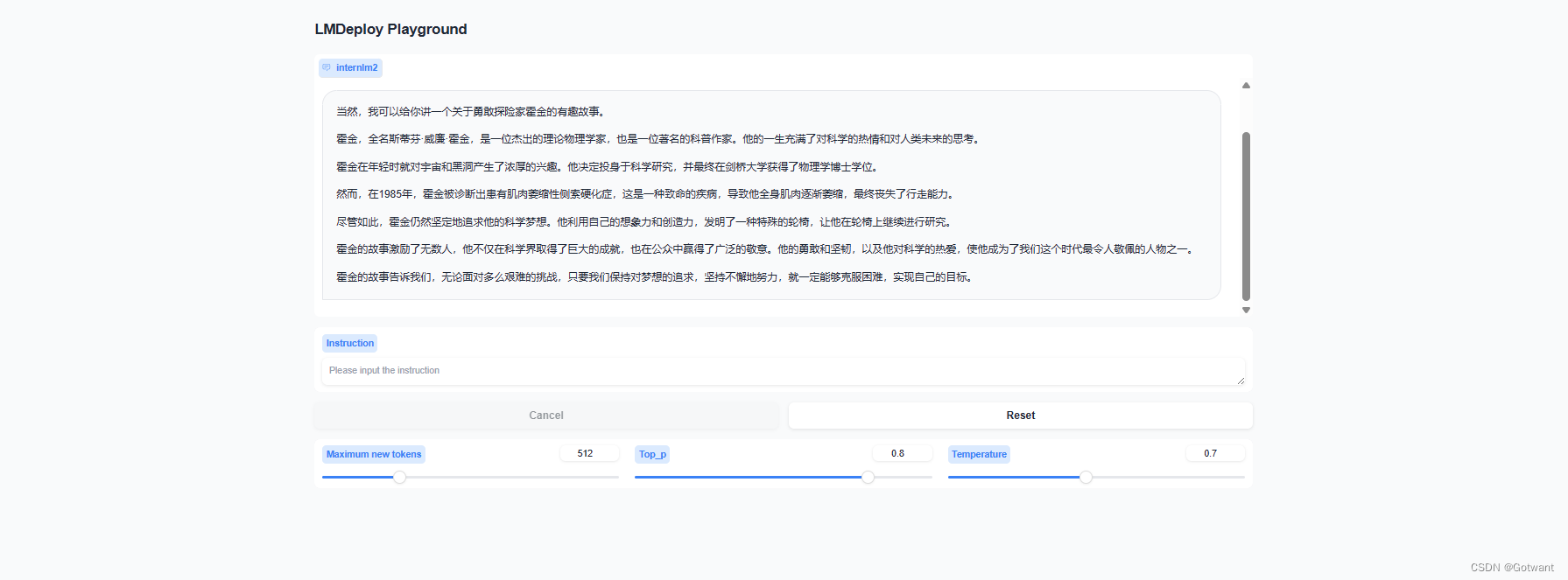
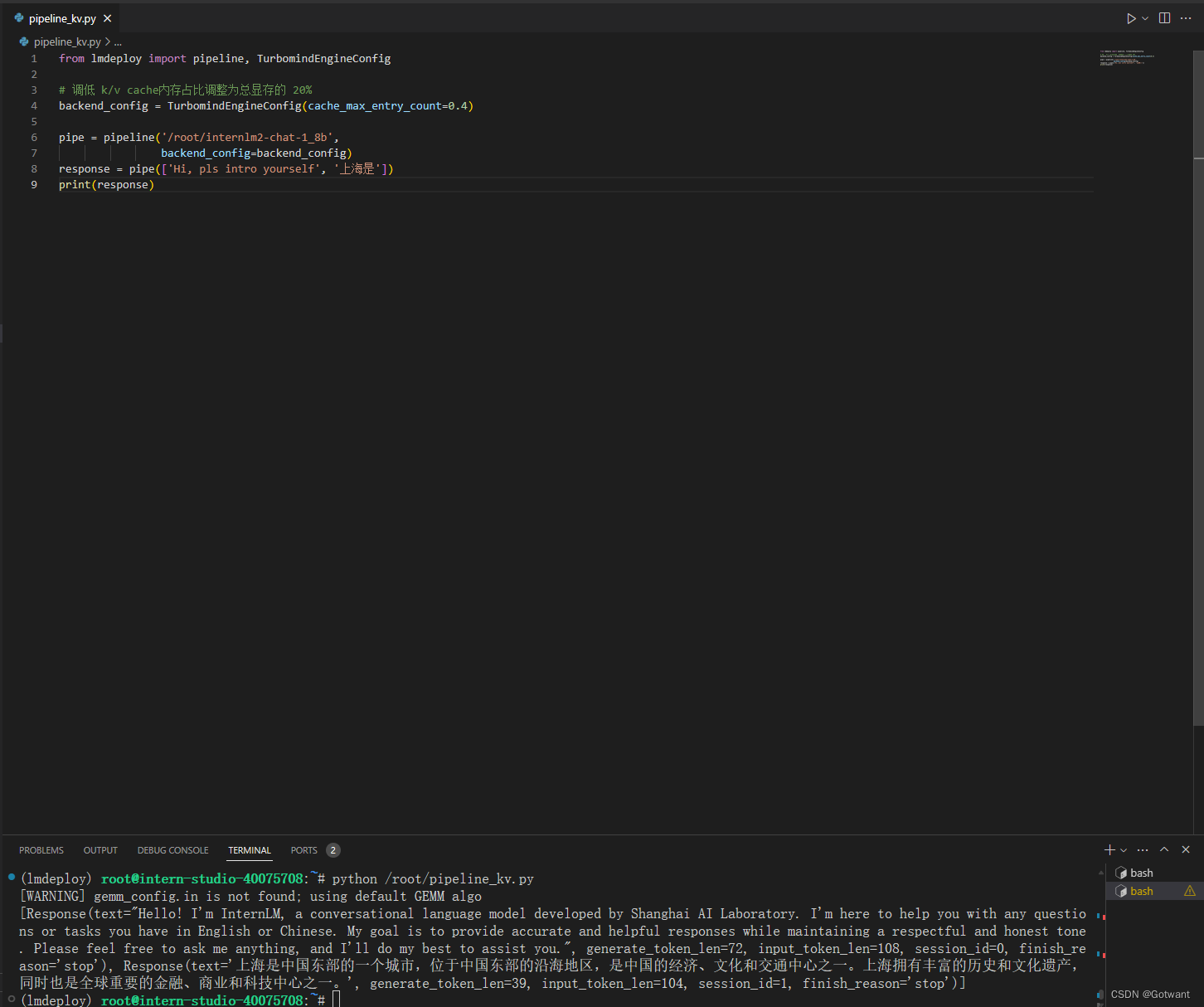
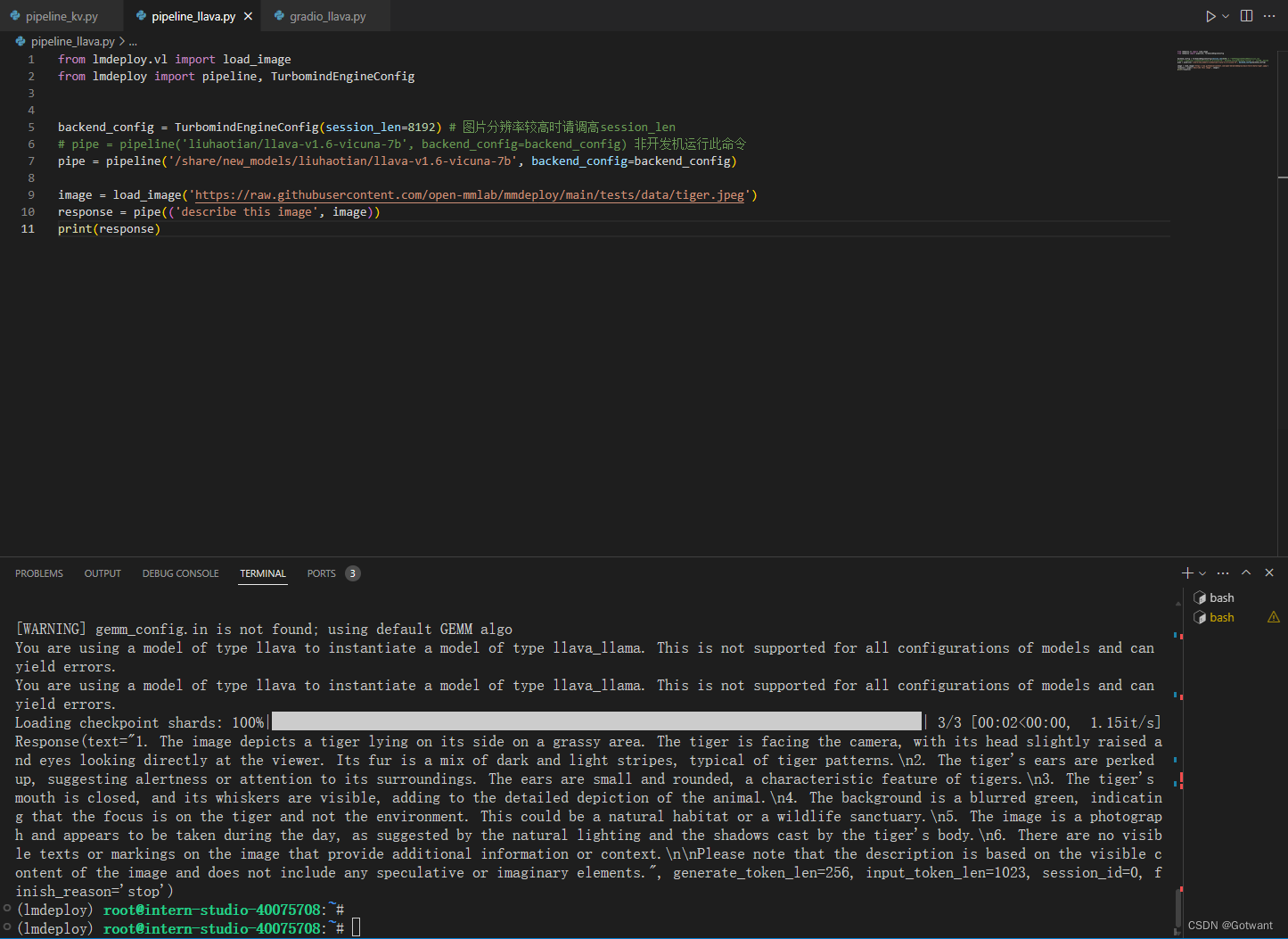
具体笔记在下面的链接里 书生浦语第二期第五节课笔记(LMDeploy 量化部署 LLM-VLM 实践)-CSDN博客 基础作业 进阶作业 1.设置KV Cache最大占用比例为0.4,开启W4A16量化,以命令行方式与模型对话。 2.以API Server方式启动 lmdeploy,开启 W4A16量化,调整KV Cache的占用比例为0.4,分别使用命令行客户端与Gradio网页客户端与模型对话。 3.使用W4A16量化,调整KV Cache的占用比例为0.4,使用Python代码集成的方式运行internlm2-chat-1.8b模型。 4.使用 LMDeploy 运行视觉多模态大模型 llava gradio demo。