Navigating the Digital World as Humans Do: UNIVERSAL VISUAL GROUNDING FOR GUI AGENTS
前言
一篇图prompt的前沿工作,利用强化学习的方法来探索图中需要添加prompt的节点以及prompt的规模,实现了对必要节点添加轻量prompt的过程,在多个下游任务上取得了SOTA的效果。文章思路清晰,逻辑严谨,深入浅出,实验丰富,是不可多得的值得深入学习的工作。| Paper | https://arxiv.org/pdf/2408.03195 |
|---|---|
| Code | https://github.com/JasonZhujp |
Abstract
“pre-train, prompt”的范式最近在图表征领域展现了其泛化性和数据高效性。一开始的图prompt tuning方法为GNN特定的训练策略设定,限制了其应用性,因此,通用的prompt方法通过直接将prompt输入到图的表征空间,去除了对预训练策略的依赖从而受到欢迎。然而,如何加以及加多少prompt是当前领域所存在的问题,受到NLP中充分预训练的模型处理下游任务时需要更少条件信号的启发,本文主张将必要且轻量的prompt策略性地加入到某些节点中,以增强下游任务的性能。这涉及到一个组合优化的问题, 需要往哪个节点上加prompt,以及具体要加多少。为此作者提出了RELIEF,利用RL的方法来解决这些问题。在每一步中,RL代理选择一个节点并确定prompt,旨在最大化累计性能增益。在小样本场景中通过和各种预训练策略方法的实验表明,RELIEF在分类性能和数据效率方面优于微调和其它基于prompt的方法。
Motivation
GNNs在知识图谱,社交媒体,推荐系统都有广泛应用,为了增强模型的泛化能力,很多工作都投身于预训练的GNN模型。但是这种基于预训练和微调的范式有如下问题:
- 上下游任务不一致,导致负迁移。
- 小样本场景模型泛化能力不够。
借鉴NLP领域Prompt学习取得的巨大成功,现有工作将“pre-train, prompt”范式扩展到图领域。现有方法可以分为两类:
- 依赖预训练策略。但是在多任务、多自监督技术的预训练下,Prompt方法可能会失败。
- 预训练策略无关。兼容性强,通用且高效。
但是现有预训练无关的工作对Prompt learning没有深入思考,在NLP中,强大的模型只需要合适的条件信号就能够符合下游任务的要求,这对于遵循消息传递机制的GNN模型来说更是如此。
Solution
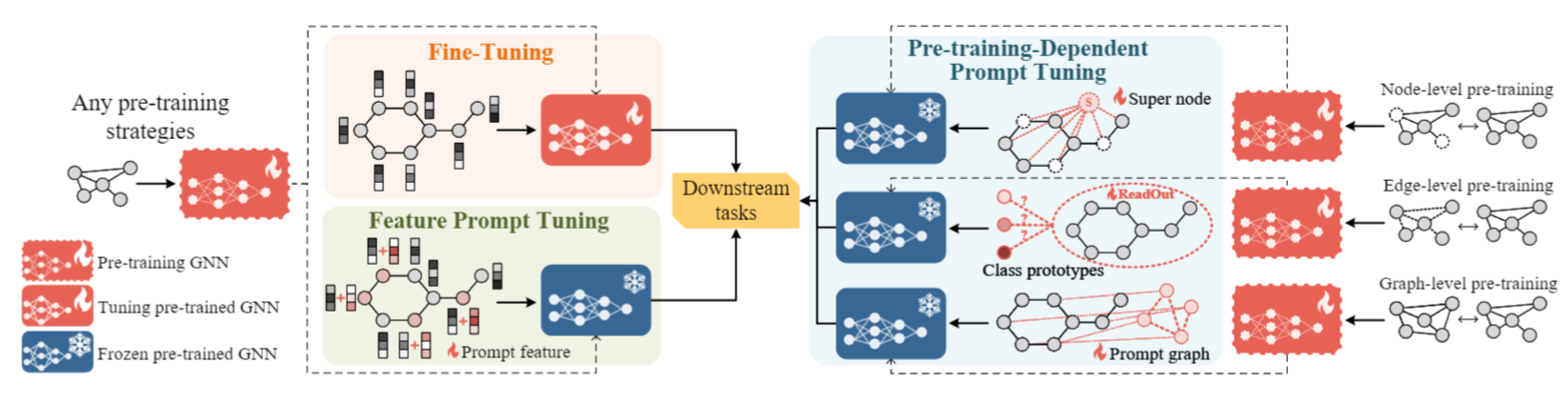
作者推测对于一个充分预训练的GNN模型,补充合适的条件信号就足够应用于下游任务了,对每个节点都加Prompt反而会导致过拟合。因此,策略性地将必要且轻量的prompt加入到原始图中,可以让GNN释放最大的预训练能力,从而泛化到各种下游任务。
选择什么节点、加入多少prompt是一个组合优化的问题,为此,作者采用可以高效搜索的RL方法,并提出基于RL增强的图表征prompt方法,名为RELIEF。作者将注入prompt的过程建模为序列决策问题,整个过程如下:
- RL代理选择需要进行prompt的节点。
- RL代理决定prompt的内容。
- prompt后的图输入预训练好的GNN中进行评估。
- 接着,RL代理生成的新prompt加入先前的图中,如此反复直到最大步数。
方法的目标是最大化下游任务预期的累积性能提升,此外还加入策略泛化的技术来保证训练的稳定性和高效性。作者还设计了两个metrics:prompt coverage ratio 和 average prompt magnitude,来量化prompt对原始输入的影响力。
RELIEF
Incorporating Feature Prompts as MDP
在强化学习领域中,环境通常用一个MDP建模。本方法将prompt构建成MDP,设计细节如下。
Action Space
给定具有n个节点的图 G \mathcal{G} G,一个离散的动作 a a a用于从节点集合 { v 1 , … , v n } \{v_1, \dots, v_n\} {v1,…,vn}中挑选 v a v_a va,一个连续的动作 z ∈ R 1 × D z \in \mathbb{R}^{1 \times D} z∈R1×D用于决定赋予节点 v a v_a va的值向量。因此, t t t时刻的prompt(混合动作)可以表示为 ( a t , z t ) = p t a , z (a_t, z_t) = p^{a,z}_t (at,zt)=pta,z,进一步,prompt矩阵可以定义为 P = { p 1 , … , p n } ∈ R n × D \mathbf{P} = \{p_1, \dots, p_n\} \in \mathbb{R}^{n \times D} P={p1,…,pn}∈Rn×D,对于经过prompt后的图,其prompted特征 X ∗ \mathbf{X}^\ast X∗通过 X ∗ = X + P \mathbf{X}^\ast = \mathbf{X} + \mathbf{P} X∗=X+P更新。
State Transition
状态空间被定义为经过预训练GNN后图的节点表征, t t t时刻的状态被表示为:
s t : = f θ ( G t − 1 ∗ ) = f θ ( X t − 1 ∗ , A ) = f θ ( X + P t − 1 , A ) = { h 1 , t − 1 ∗ , … , h n , t − 1 ∗ } ∈ R n × d \begin{aligned} s_{t} & :=f_{\theta}\left(\mathcal{G}_{t-1}^{*}\right)=f_{\theta}\left(\mathrm{X}_{t-1}^{*}, \mathrm{~A}\right)=f_{\theta}\left(\mathrm{X}+\mathrm{P}_{t-1}, \mathrm{~A}\right) \\ & =\left\{h_{1, t-1}^{*}, \ldots, h_{n, t-1}^{*}\right\} \in \mathbb{R}^{n \times d} \end{aligned} st:=fθ(Gt−1∗)=fθ(Xt−1∗, A)=fθ(X+Pt−1, A)={h1,t−1∗,…,hn,t−1∗}∈Rn×d
其中 h i , t − 1 ∗ h^*_{i,t-1} hi,t−1∗是图 G t − 1 ∗ \mathcal{G}^*_{t-1} Gt−1∗中节点 v i v_i vi的表征, d d d是表征的维度。当前的状态基于先前的步骤。为了解决不同图包含不同数量节点影响batch训练的情况,作者设置了一个最大节点数量 N N N,节点不足用零向量填充。因此, t t t时刻的状态可以表示为:
s t : = f θ ( X t − 1 ∗ , A ) ∥ 0 ( N − n ) × d = { h 1 , t − 1 ∗ , … , h n , t − 1 ∗ , 0 n + 1 , … , 0 N } ∈ R N × d \begin{aligned} s_t & :=f_\theta\left(\mathrm{X}_{t-1}^*, \mathrm{~A}\right) \| \mathbf{0}_{(N-n) \times d} \\ & =\left\{h_{1, t-1}^*, \ldots, h_{n, t-1}^*, 0_{n+1}, \ldots, 0_N\right\} \in \mathbb{R}^{N \times d} \end{aligned} st:=fθ(Xt−1∗, A)∥0(N−n)×d={h1,t−1∗,…,hn,t−1∗,0n+1,…,0N}∈RN×d
当代理在 t t t时刻执行动作 p t a , z p^{a,z}_t pta,z时,prompt矩阵更新为:
P t = P t − 1 + p t a , z = { p 1 , t − 1 , … , p a , t − 1 + p t a , z , … , p n , t − 1 } \mathbf{P}_t=\mathbf{P}_{t-1}+p_t^{a, z}=\left\{p_{1, t-1}, \ldots, p_{a, t-1}+p_t^{a, z}, \ldots, p_{n, t-1}\right\} Pt=Pt−1+pta,z={p1,t−1,…,pa,t−1+pta,z,…,pn,t−1}
此时状态转移矩阵更新为: X t ∗ = X + P t \mathbf{X}^\ast_t = \mathbf{X} + \mathbf{P}_t Xt∗=X+Pt。被prompt后的图输入到预训练的GNN中可以获得新的节点表征,从而构建下一步的状态。
Reward Function
理想的奖励函数是目标引导的,在探索过程提供动作价值的引导信号。虽然图分类任务常用AUC或者F1-score作为指标,但是无法作为奖励来衡量每个图中每步插入的prompt质量。而Loss可以从每张图中获取并能捕获表现相关的概念,因此采用loss下降作为奖励。具体来说,给定两个相邻的步骤,奖励 r ( s t , a t , z t , s t + 1 ) r(s_t,a_t,z_t,s_{t+1}) r(st,at,zt,st+1),即 r t r_t rt,定义为:
r t = L t − 1 − L t = L ( g ϕ ( f θ ( G t − 1 ∗ ) ) , y ) − L ( g ϕ ( f θ ( G t ∗ ) ) , y ) r_t=\mathcal{L}_{t-1}-\mathcal{L}_t=\mathcal{L}\left(g_\phi\left(f_\theta\left(\mathcal{G}_{t-1}^*\right)\right), y\right)-\mathcal{L}\left(g_\phi\left(f_\theta\left(\mathcal{G}_t^*\right)\right), y\right) rt=Lt−1−Lt=L(gϕ(fθ(Gt−1∗)),y)−L(gϕ(fθ(Gt∗)),y)
其中 L ( ⋅ ) \mathcal{L(·)} L(⋅)与下游任务的损失关联。这样损失下降奖励为正,损失上升奖励为负,最终,累积的奖励映射了$T $步的总体损失,可以衡量模型最终性能的提升。
Policy Network Architecture
RELIEF部署了H-PPO,包括并行的两个actor网络以及一个单一的critic网络,构成策略网络 Π ω \Pi_\omega Πω,其中 ω \omega ω是网络的参数。三个网络在开始的几个层共享编码状态信息。鉴于状态空间是提示后的图的状态表征,作者使用预训练的GNN模型 f θ f_{\theta} fθ作为状态的编码器。接着,将不同输出维度的MLPs连接到三个网络,以实现相应的功能。网络前向传播如下所示:
p ( a ∣ s ) ← Softmax ( MLP a ( f θ ( G ∗ ) ) ) μ ( s , a ) ← MLP z ( f θ ( G ∗ ) ) [ a ] V ( s ) ← MLP c ( Flatten ( f θ ( G ∗ ) ) ) \begin{aligned} & p(a \mid s) \leftarrow \operatorname{Softmax}\left(\operatorname{MLP}_a\left(f_\theta\left(\mathcal{G}^*\right)\right)\right) \\ & \boldsymbol{\mu}(s, a) \leftarrow \operatorname{MLP}_z\left(f_\theta\left(\mathcal{G}^*\right)\right)[a] \\ & V(s) \leftarrow \operatorname{MLP}_c\left(\operatorname{Flatten}\left(f_\theta\left(\mathcal{G}^*\right)\right)\right) \\ \end{aligned} p(a∣s)←Softmax(MLPa(fθ(G∗)))μ(s,a)←MLPz(fθ(G∗))[a]V(s)←MLPc(Flatten(fθ(G∗)))
Discrete Actor
代表离散策略 π d ( a ∣ s ) \pi_d(a|s) πd(a∣s)。给定状态 s s s的提示后图的节点表征,通过 MLP a \operatorname{MLP}_a MLPa后跟随SOFTMAX操作将 s s s转换为离散动作概率 p ( a ∣ s ) ∈ R n p(a|s)\in \mathbb{R} ^n p(a∣s)∈Rn。然后,代理根据这个概率,要么抽样选择一个节点 v a v_a va,要么贪心地选择最高概率的节点作为离散动作,分别对应随机策略或者确定性策略。注意到零填充节点的 p ( a ∣ s ) p(a|s) p(a∣s)为0,因此将有效动作从 N N N减少到 n n n。
Continuous Actor
代表连续策略 π c ( s ∣ a ) \pi_c(s|a) πc(s∣a)。给定状态 s ∈ R N × d s \in \mathbb{R}^{N \times d} s∈RN×d, MLP z \operatorname{MLP}_z MLPz为每个节点输出一个参数 μ ∈ R 1 × D \mu \in \mathbb{R}^{1 \times D} μ∈R1×D(一共 N N N个),然后选择索引为 [ a ] [a] [a]的 μ \mu μ与所选的离散动作配对。随后,代理基于 ( μ , σ ) (\mu, \sigma) (μ,σ)构建高斯分布,并随机采样一个向量 z ∈ R 1 × D z \in \mathbb{R}^{1 \times D} z∈R1×D作为提示特征 p a , z p^{a,z} pa,z,或者直接用 μ \mu μ作为确定性的动作,其中标准差 σ ∈ R 1 × D \sigma \in \mathbb{R}^{1 \times D} σ∈R1×D可以是学习到的或者是预定义的。为了让 p a , z p^{a,z} pa,z输出在一个理想的范围, z z z的每个维度的大小都限制在 [ − z m a x , z m a x ] [-z_{\mathrm{max}}, z_\mathrm{max}] [−zmax,zmax]范围内,其中 z m a x z_\mathrm{max} zmax是控制每步加入prompt规模的超参数。
Critic
用于评估状态价值函数。本质上它是将状态 s s s映射到一个实数值 V ( s ) ∈ R V(s) \in \mathbb{R} V(s)∈R。但是这存在一个维度不一致性,即状态空间是节点级别的粒度,而价值估计是基于全局视角的。因此作者采用FLATEEN操作将状态 s s s的维度从 N × d N \times d N×d转换为 1 × N d 1 \times Nd 1×Nd。接着被平展的向量通过 M L P c \mathrm{MLP}_c MLPc处理得到输出值,该值即为对 V ( s ) V(s) V(s)的估计。
值得注意的是,策略网络中的状态编码器就是预训练好的GNN,在策略学习时处于冻结状态。这意味着通过更新MLPs的参数,actors能够将状态映射为动作,Critic能够将状态映射为状态值。这种训练架构已经被广泛采用到LLM的RLHF训练中。
Overall Framework of RELIEF
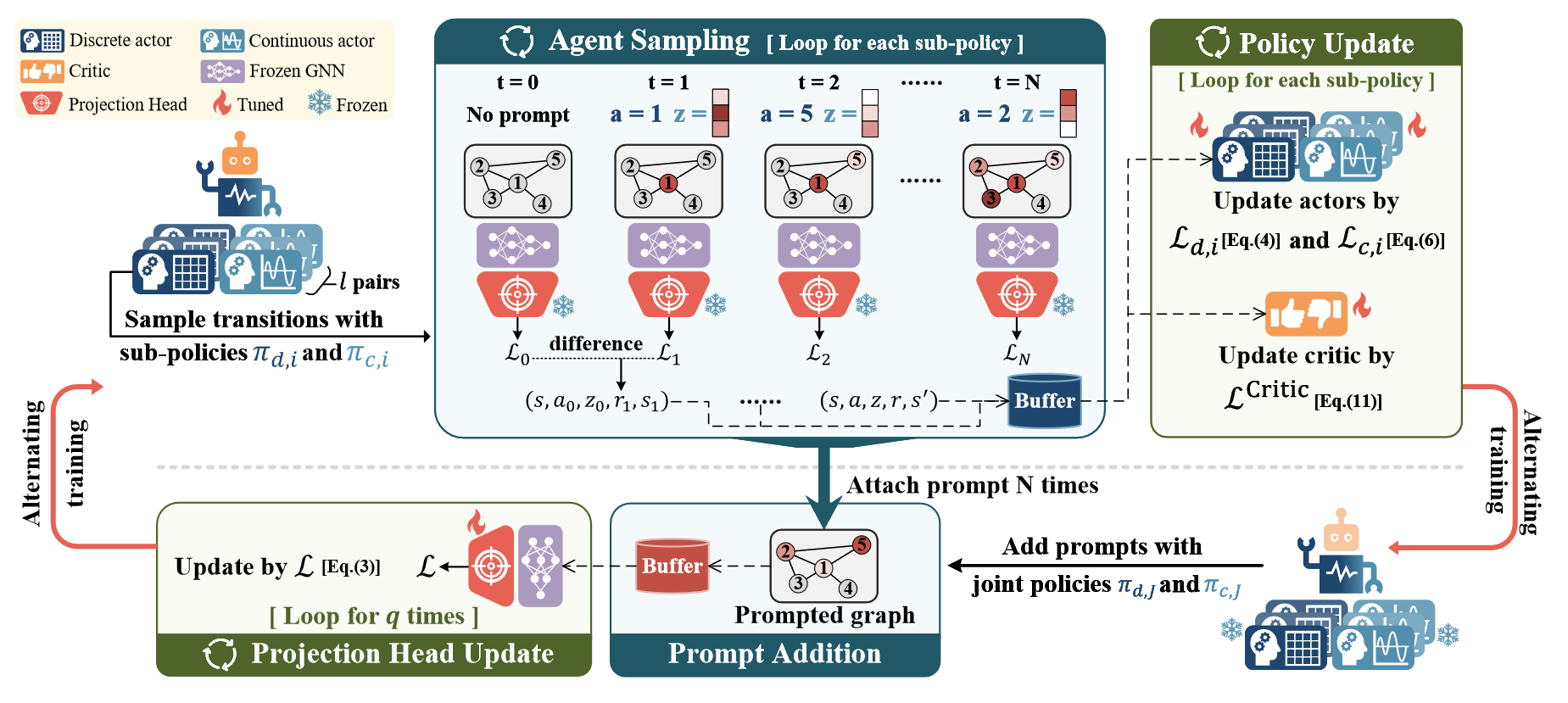
RELIEF包含两个可训练模块,策略网络和投影头,如上图所示。通过这两个模块的协调可以极大提升模型在下游任务上的性能。两个模块的训练分开进行,如下所述。
Policy network training
给定冻结的预训练GNN模型 f θ f_{\theta} fθ,策略网络 Π ω \Pi_\omega Πω,投影头 g ϕ g_\phi gϕ,包含 n n n个节点的图 G \mathcal{G} G,通过 L ( g ϕ ( f θ ( G ) ) , y ) \mathcal{L} (g_\phi ( f_\theta (\mathcal{G}) ), y) L(gϕ(fθ(G)),y)计算的初始的损失 L 0 \mathcal{L}_0 L0。
在每一步中,代理根据策略 π c \pi_c πc和 π d \pi_d πd采样特征提示 p t a , z p^{a,z}_t pta,z添加到节点 v a v_a va中,然后将提示后的图输入到GNN中,并根据投影头获取预测结果计算当前损失,接着根据当前损失和先前损失计算即时奖励。这样代理收集了一个转移,表示为一个元组 ( s , a , z , r , s ′ ) (s, a, z, r, s') (s,a,z,r,s′)。Prompt添加的过程重复 n n n次,理论上给每个节点提示的机会。值得注意的是,两个actor都采用随机策略,以便在训练中更好探索。
接着,收集到的 n n n步转移用于更新策略网络。两个actor独立采用PPO替代目标 L PPO \mathcal{L}^\text{PPO} LPPO进行训练,而critic通过MSE损失 L Critic \mathcal{L}^\text{Critic} LCritic进行训练。上述过程处理batch图,以提高采样和训练效率。
Projection head training
训练投影头的目的是协调投影头与提示后的图表征来使预测和其正确的标签对齐。在通过 n n n步获得提示的图后,作者将连续策略修改为确定性策略,以确保在相同状态和离散动作下获得相同的提示向量值。这保证了提示图的稳定性,从而确保了一致的表征,这些表征与标签一起用来监督投影头的更新。给定 m m m个采样的图,投影头更新目标如下:
min ϕ 1 m ∑ i = 1 m L ( g ϕ ( f θ ( G i ∗ ) ) , y ) \min_{\phi}{ \frac{1}{m} \sum^{m}_{i=1} \mathcal{L}\left(g_\phi \left( f_\theta(\mathcal{G}^\ast_i) \right), y \right)} minϕm1∑i=1mL(gϕ(fθ(Gi∗)),y)
其中损失函数与奖励损失相同。为了加快投影头与策略对齐的速度,投影头更新 q q q次。
总的来说,如上两个交替的过程(一次策略更新, q q q次投影头更新),定义了一个训练周期。在评估阶段,作者直接应用训练好的两个actor,将特征提示逐步加入到下游任务的图中。这些提示后的图通过GNN和训练过的投影头进行转换,以生成预测结果,然后通过下游指标进行评估。
Policy Generalization
在有限环境(如小样本场景)中训练,一般的RL算法容易出现过拟合的情况,导致对未见场景泛化能力差。为了解决这个问题,本文引入了一种策略泛化策略LEEP,它可以与PPO无缝结合,从而兼容本文的方法。本质上,LEEP是一种为离散动作空间设计的集成方法,为PPO的目标添加正则项用于更新actor网络。LEEP通过利用所有子策略来学习通用的策略。为了泛化离散策略 π d ( s ∣ a ) \pi_d(s|a) πd(s∣a),需要学习 l l l个离散子策略 { π d , 1 , . . . , π d , l } \{\pi_{d,1},...,\pi_{d,l}\} {πd,1,...,πd,l}。每个 π d , i \pi_{d,i} πd,i从训练图子集 D i \mathcal{D}_i Di收集转换,该子图是通过bootstrap采样从整个训练集 D \mathcal{D} D中抽取的。每个 π d , i \pi_{d,i} πd,i通过最大化期望更新,同时又要最小化与离散联合策略 π d , J \pi_{d,J} πd,J之间的距离:
L d , i = L d , i P P O − α d E s ∼ π d , i , D i [ D K L ( π d , i ( a ∣ s ) ∥ π d , J ( a ∣ s ) ) ] \mathcal{L}_{d, i}=\mathcal{L}_{d, i}^{\mathrm{PPO}}-\alpha_d \mathbb{E}_{s \sim \pi_{d, i}}, \mathcal{D}_i\left[D_{\mathrm{KL}}\left(\pi_{d, i}(a \mid s) \| \pi_{d, J}(a \mid s)\right)\right] Ld,i=Ld,iPPO−αdEs∼πd,i,Di[DKL(πd,i(a∣s)∥πd,J(a∣s))]
离散联合策略 π d , J \pi_{d,J} πd,J通过如下公式计算:
π d , J ( a ∣ s ) = max i = 1 , … , l π d , i ( a ∣ s ) ∑ a ′ max i = 1 , … , l π d , i ( a ′ ∣ s ) \pi_{d, J}(a \mid s)=\frac{\max _{i=1, \ldots, l} \pi_{d, i}(a \mid s)}{\sum_{a^{\prime}} \max _{i=1, \ldots, l} \pi_{d, i}\left(a^{\prime} \mid s\right)} πd,J(a∣s)=∑a′maxi=1,…,lπd,i(a′∣s)maxi=1,…,lπd,i(a∣s)
表明为了获得由
π
d
,
J
\pi_{d,J}
πd,J给出的离散动作概率,作者对每个动作
a
a
a的所有$l
$个子策略取最大概率,然后将这些最大值归一化。
由于RELIEF需要混合动作空间,作者将LEEP扩展到连续动作空间。类似的,作者也是学习 l l l个离散子策略 { π c , 1 , . . . , π c , l } \{\pi_{c,1},...,\pi_{c,l}\} {πc,1,...,πc,l}。换言之,作者采用 l l l个并行的H-PPO算法,但是只有一个critic。每个连续的子策略 π c , i \pi_{c,i} πc,i通过最大化下面目标实现:
L c , i = L c , i P P O − α c E s ∼ π c , i , D i [ D K L ( π c , i ( a ∣ s ) ∥ π c , J ( a ∣ s ) ) ] \mathcal{L}_{c, i}=\mathcal{L}_{c, i}^{\mathrm{PPO}}-\alpha_c \mathbb{E}_{s \sim \pi_{c, i}}, \mathcal{D}_i\left[D_{\mathrm{KL}}\left(\pi_{c, i}(a \mid s) \| \pi_{c, J}(a \mid s)\right)\right] Lc,i=Lc,iPPO−αcEs∼πc,i,Di[DKL(πc,i(a∣s)∥πc,J(a∣s))]
连续联合策略 π c , J \pi_{c,J} πc,J定义为:
π c , J ( z ∣ s , a ) = 1 l ∑ i = 1 l π c , i ( z ∣ s , a ) = 1 l ∑ i = 1 l μ i ( s , a ) \pi_{c, J}(z \mid s, a)=\frac{1}{l} \sum_{i=1}^l \pi_{c, i}(z \mid s, a)=\frac{1}{l} \sum_{i=1}^l \mu_i(s, a) πc,J(z∣s,a)=l1∑i=1lπc,i(z∣s,a)=l1∑i=1lμi(s,a)
即将所有子策略的平均 μ i \mu_i μi作为连续联合策略。
总的来说,策略网络包含 l l l个离散actor, l l l个连续actor以及一个critic。在策略训练阶段,离散和连续actor对按序独立更新,然后对critic进行更新。在训练投影头和推理阶段,应用联合策略来生成prompt特征。伪代码如下:

Metrics for Quantifying Prompts Impact
为了测量prompt对原始输入的扰动,本文引入了两个metrics:
- Prompt Coverage Ratio (PCR)
- Average Prompt Magnitude (APM)
PCR通过下面公式计算:
PCR ( G ) = 1 n ∑ i = 1 n 1 [ p i ≠ 0 1 × D ] ∈ [ 0 , 1 ] \operatorname{PCR}(\mathcal{G})=\frac{1}{n} \sum_{i=1}^n 1\left[p_i \neq 0_{1 \times D}\right] \in[0,1] PCR(G)=n1∑i=1n1[pi=01×D]∈[0,1]
PCR表示整个Prompt过程中节点至少被Prompt一次的比例。
APM用于衡量插入prompt的大小,采用维度上平均的有效特征提示的L1-范数来描述,计算如下:
APM ( G ) = 1 n ∑ i = 1 n 1 D 1 [ p i ≠ 0 1 × D ] ⋅ ∥ p i ∥ 1 ∈ [ 0 , + ∞ ) \operatorname{APM}(\mathcal{G})=\frac{1}{n} \sum_{i=1}^n \frac{1}{D} 1\left[p_i \neq 0_{1 \times D}\right] \cdot\left\|p_i\right\|_1 \in[0,+\infty) APM(G)=n1∑i=1nD11[pi=01×D]⋅∥pi∥1∈[0,+∞)
APM可以表示有效Prompt的规模,为“轻量化”设定了标准。
PCR和APM分别从广泛性和显著性两个角度来衡量prompt的质量,适用于任何特征prompt评估的方法。
Experiments
Few-shot Graph Classification
本文采用5层GIN作为GNN模型的基础架构,在化学数据集上预训练,并在MoleculeNet的分子特性预测Benchmark上进行prompt微调,数据集的细节见附录。
为了展示RELIEF的通用性,本文对GIN模型采用了图级别和节点级别四种常见的预训练策略:
- Deep Graph Infomax (Infomax)
- Attribute Masking (AttrMasking)
- Context Prediction (ContextPred)
- Graph Contrastive Learning (GCL)
这些方法的细节描述也在附录。
实验结果如下:
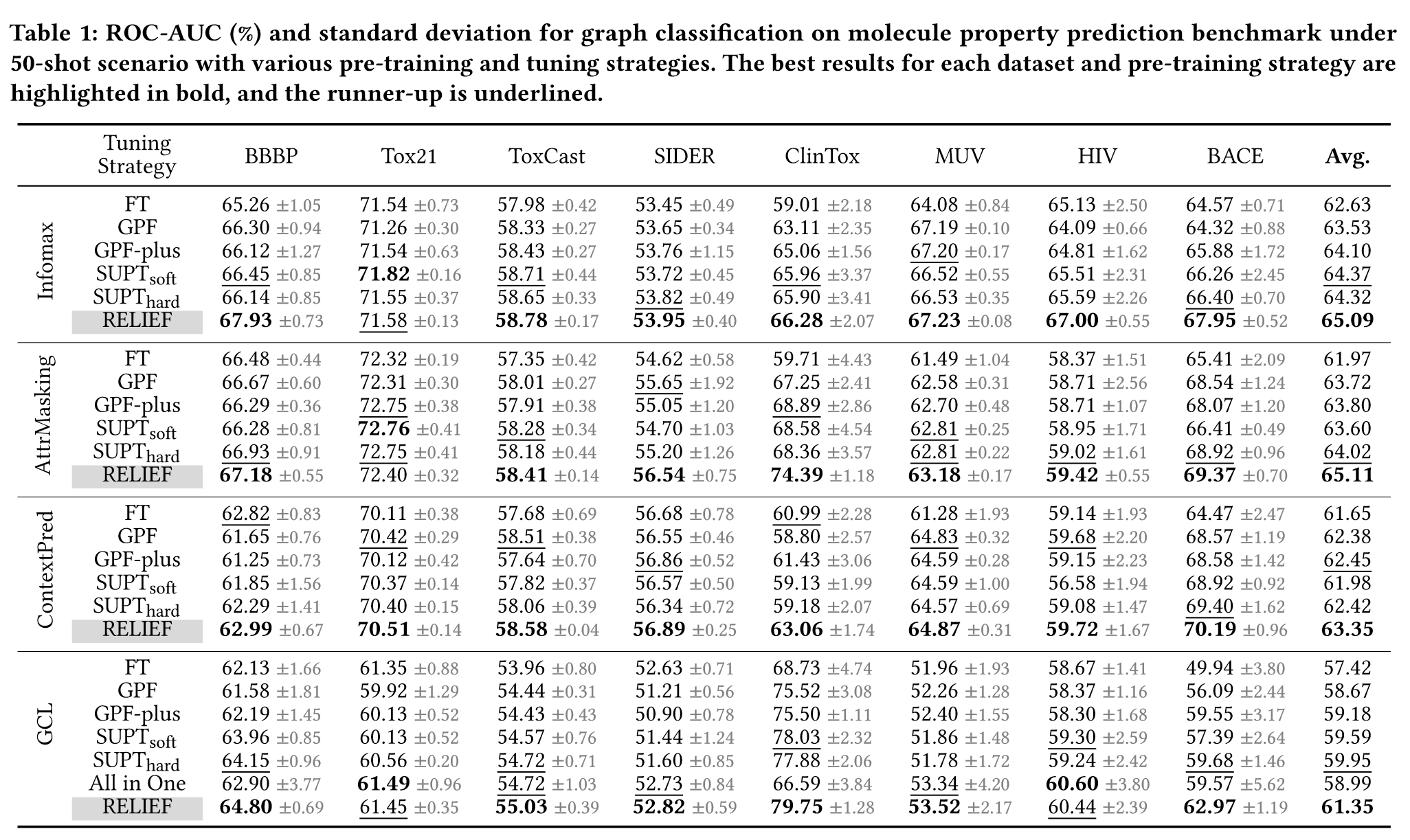
根据上表结果,RELIEF在小样本场景实现了卓越的性能,在28/32个任务上超过了baseline,甚至超过了微调的方法。此外,作者还发现在All in one中,插入节点较少的提示图可以产生更好的效果,这间接印证了本文的动机。
下图是RELIEF使用Infomax预训练的BACE数据集上的调整过程:
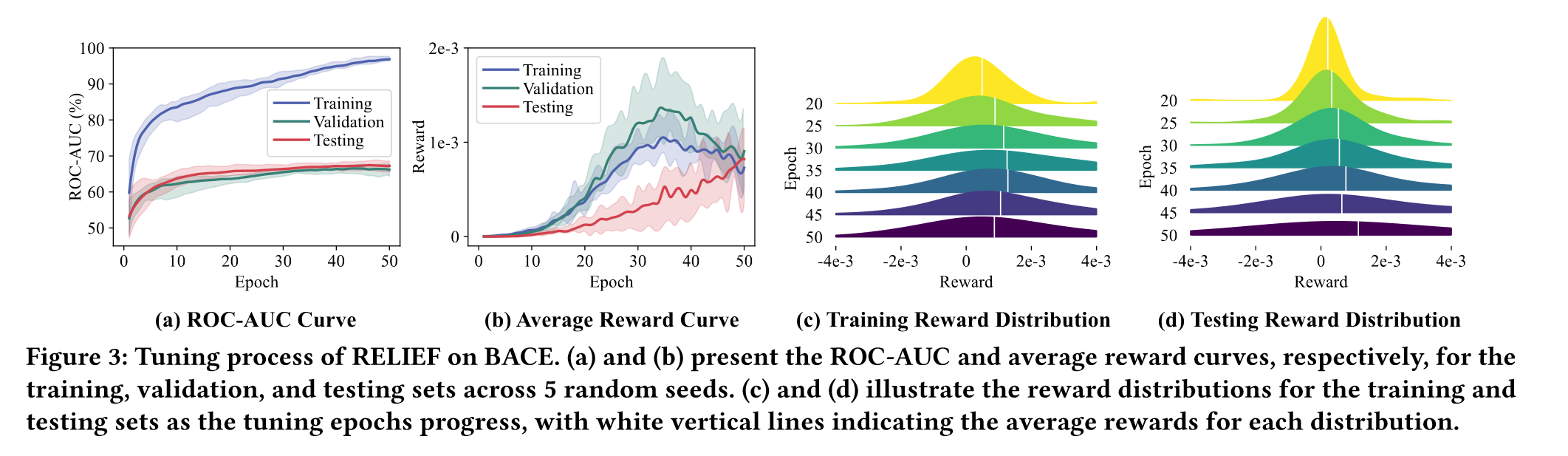
ROC-AUC表现出平滑递增的趋势,奖励曲线和奖励分布随着训练步数不断优化,此外,作者根据PCR和AMP来衡量prompt对输入图的影响,并将它们相乘来表示总体的影响。如下表所示:
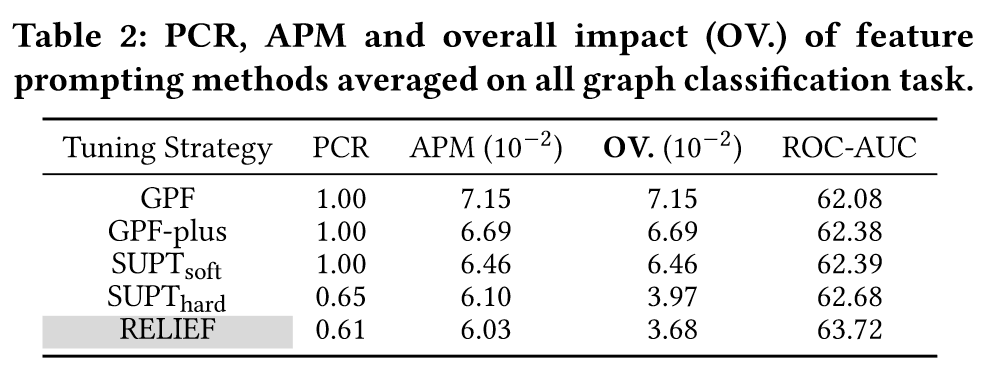
RELIEF表现出最小的PCR,APM和OV,以及更好的ROC-AUC,同时相比于依赖先验的SUPThard方法,更加灵活且性能更好。
Data Efficiency
为了评估特征prompt方法的数据高效性,作者每5%的数据量相加进行训练,直到ROC-AUC的性能和微调一样。结果如下:
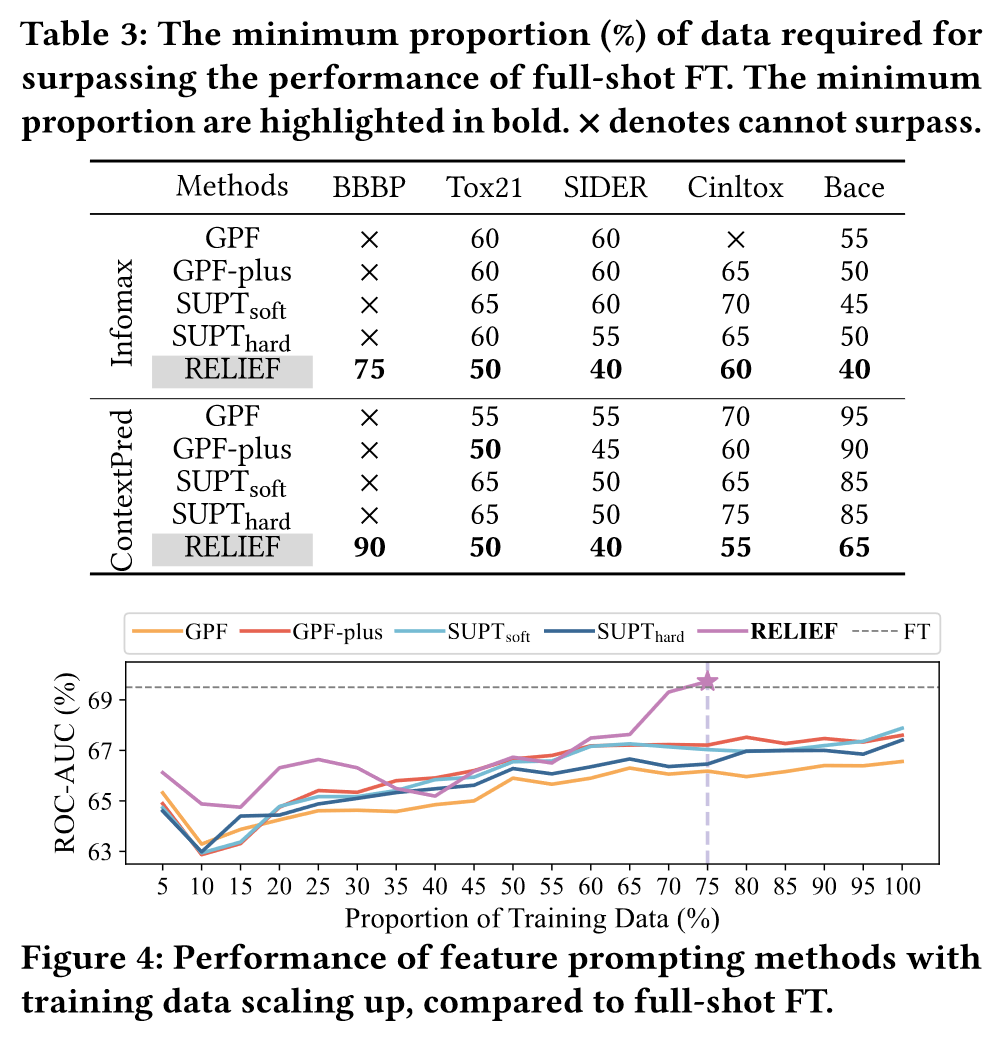
其中×代表无法超过微调的性能。可以看到RELIEF仅需要最少的数据就可以超过微调的效果。图四是模型性能随着数据变化的趋势,RELIEFT呈现明显的改进直到超过微调,而其他方法无法超过微调的效果。RELIEFT的数据效率归因于强化学习的范式:
- 通过一次优化一个特征prompt来降低学习难度。
- Prompt的逐步插入和评估可以让代理面对各种模式,起到数据增强的效果。
Additional Experiments
除了图分类任务,作者还做了节点分类任务的实验(详见附录A),结果如下:
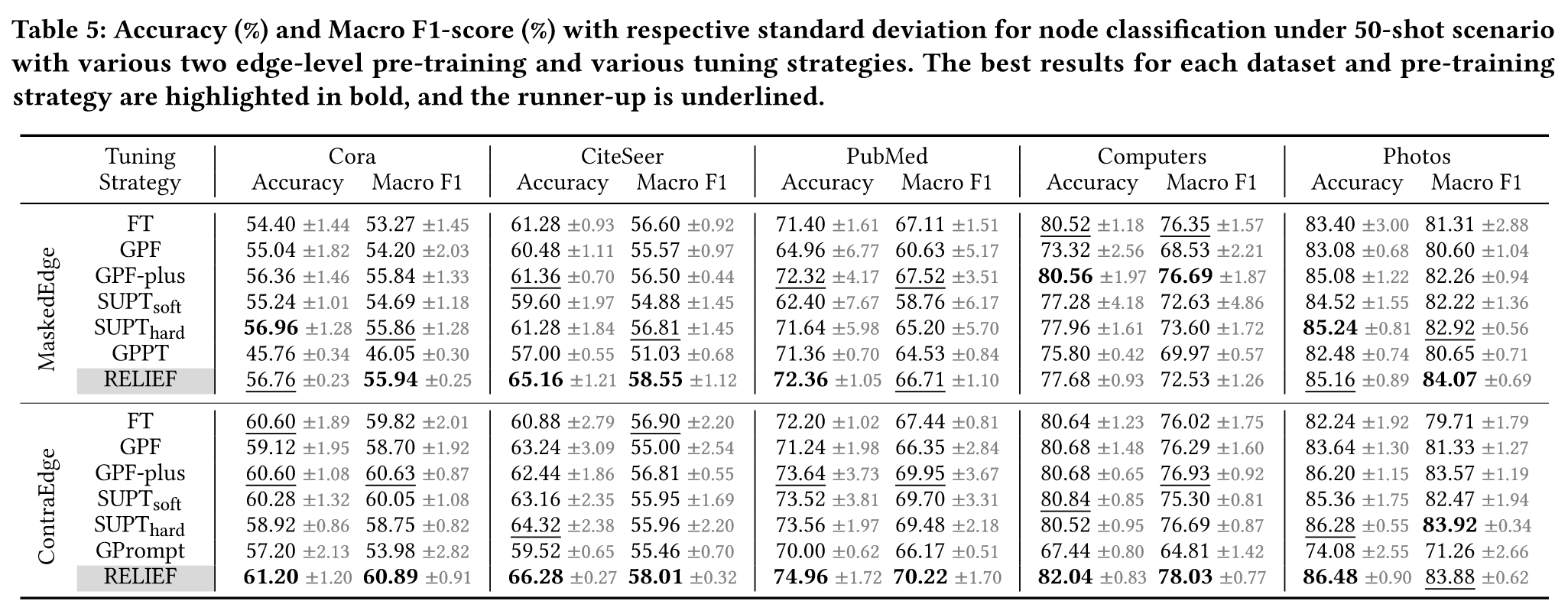
实验表明RELEIF在各个数据集上都有最好的表现,尤其是GNN模型经过充分预训练的情况下。
对于RELIEF在MaskedEdge预训练后,在Computers数据集上测试效果不如预期,作者对此做了case study。作者调整了大量参数,发现预训练GNN的损失无法稳定下降,这表明GNN训练不充分。
为了调查GPF-plus和RELIEF之间的差异,作者检查了包含和不包含prompt的测试accuracy曲线,如下图所示:
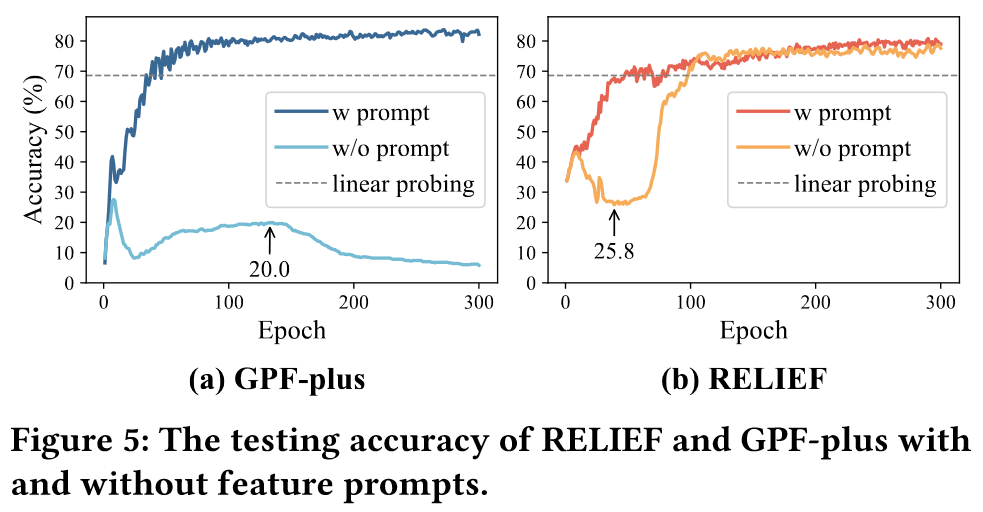
在没有Prompt的情况下,GPF-plus的accuracy最多到20%然后下降,RELIEF先下降后上升,最终达到75.1%且能够收敛。作者认为accuracy的显著差异是因为Prompt的干扰。首先GPF-plus的平均提示幅度是RELEIF的四倍,并且GPF-plus是在所有节点上都加入Prompt。其次,丢掉Prompt后,GPF-plus的accuracy从68.6掉到7,这意味着prompt的特征已经覆盖了原始的特征,导致预训练过程变得无效。相比之下,RELIEF保留了原始的特征知识并进一步泛化,将其准确率从68.6提升到77.6。
消融实验见附录C,作者将RELIEF和其三个变体进行比较:
- 随机离散策略
- 随机连续策略
- 只训练投影头
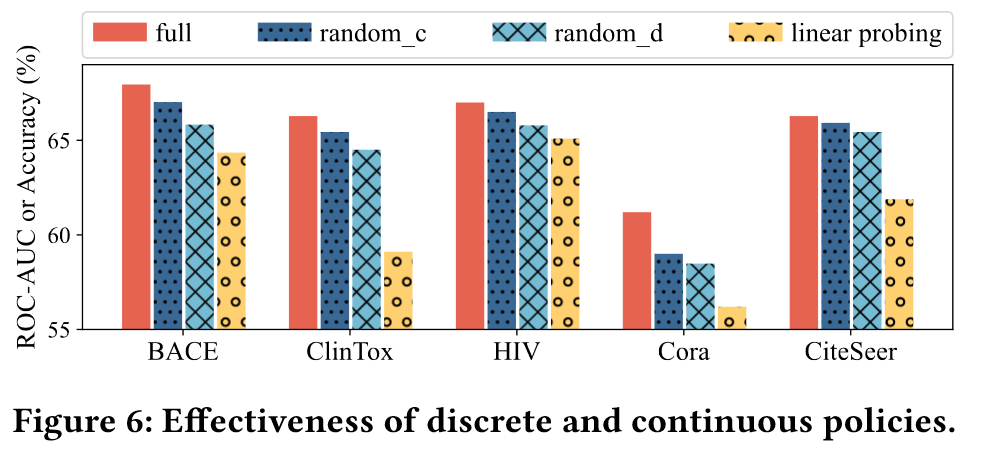
结果如上图所示,表明停用策略或者只使用部分策略,prompt的性能会显著下降。
附录D是参数有效性分析,包括每步prompt的规模,子策略的数量,以及策略泛化技术的有效性等。分析结果证实了RELIEF在各种超参数设置下都能有稳健的性能。
Why RELIEF works?
最后作者又强调了一下为什么RELIEF能够在图分类、节点分类任务上取得好的性能:
- 方法强大:RL在组合优化问题上有显著优势。
- 必要的Prompt:不是每个节点都有必要添加Prompt的。
- Prompt轻量:RELIEF可以保留预训练知识,并提高预训练知识的泛化能力。
Conclusion
本文提出了一个基于强化学习的图feature Prompt的方法,通过探索必要定量的prompt实现了图中轻量化prompt的过程,在few-shot场景大大提升了下游任务的性能。
本文无论是方法、写作还是实验都是非常solid的,整个故事清晰明了,从动机上就很符合认知上的逻辑。方法采用RL,特别适合图中选节点、控制prompt规模这样组合优化的问题。场景选择也非常准确,RL的优势就是快速定位到准确的节点,生成合适的prompt,这完全适配few-shot场景的需求。在实验上,为了证明RELIEF的泛化性能,作者尝试各种主流的预训练方法,以及选择了多个常见的下游任务的数据集进行实验。对于表现不好的数据集,作者也做了详细的case study的分析,并发现了图Prompt中一个重要的前提——GNN必须充分预训练。
这篇工作几乎无可挑剔,至少对于我这个专门做大模型的人来说,读起来完全不费力,也完全理解了Prompt工作在图领域的应用。拜读完这篇工作,我在想图为什么不能很好和大模型结合呢,本篇工作证明了图feature prompt可以很好泛化到各种下游任务中,有点图基础模型的意思了,但我认为,真正的图基础模型,应该是和LLM结合的,它能做的不只只是分类任务,应该能够各种生成任务,比如图QA,或者利用图结构信息完成更多LLM复杂推理任务,这才是图存在真正的意义。