1.Keepalived双机热备基础知识
1.1:Keepailved:起初是专门针对的一款强大辅助工具,主要用来提供故障切换和健康检查功能一一判断LVS负载调度器,节点服务器的可用性,当master主机出现故障时切换到backup节点保证业务正常,当matser故障主机恢复后将其重新加入群集并且业务重新切换master节点
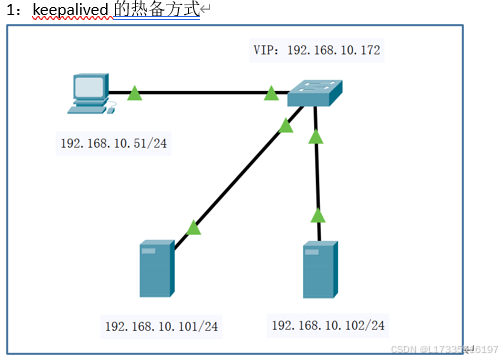
实验案例:
keepalived的配置文件说明
一.全局定义部分
全局配置又包括两个子配置1.全局定义(global definition) ;2.静态路由配置(static ipaddress/routes)
1. 全局定义(global definition) global_defs { notification_email { [email protected] [email protected] [email protected] } notification_email_from [email protected] smtp_server 192.168.200.1 smtp_connect_timeout 30 router_id LVS_DEVEL }
notification_email: 表示keepalived在发生诸如切换操作时需要发送email通知以及email发送给哪些邮件地址邮件地址可以多个每行一个
notification_email_from [email protected]: 表示发送通知邮件时邮件源地址是谁
smtp_server 127.0.0.1: 表示发送email时使用的smtp服务器地址这里可以用本地的sendmail来实现
smtp_connect_timeout 30: 连接smtp连接超时时间
router_id node1: 机器标识,fa
2.静态地址和路由配置范例
static_ipaddress
{
192.168.1.1/24 brd + dev eth0 scope global
192.168.1.2/24 brd + dev eth1 scope global
}
static_routes
{
src $SRC_IP to $DST_IP dev $SRC_DEVICE
src $SRC_IP to $DST_IP via $GW dev $SRC_DEVICE
}
这里实际上和系统里面命令配置IP地址和路由一样例如
192.168.1.1/24 brd + dev eth0 scope global 相当于: ip addr add 192.168.1.1/24 brd + dev eth0 scope global
就是给eth0配置IP地址路由同理,一般这个区域不需要配置
这里实际上就是给服务器配置真实的IP地址和路由的在复杂的环境下可能需要配置一般不会用这个来配置我们可以直接用vi /etc/sysconfig/network-script/ifcfg-eth1来配置切记这里可不是VIP不要搞混淆了切记切记
二.VRRP配置
包括三个类:1.VRRP同步组(synchroization group) 2.VRRP实例(VRRP Instance) 3.VRRP脚本
2.1.VRRP同步组(synchroization group)配置范例
vrrp_sync_group VG_1 { //注意vrrp_sync_group 后面可自定义名称如lvs_httpd ,httpd group { http mysql } notify_master /path/to/to_master.sh notify_backup /path_to/to_backup.sh notify_fault "/path/fault.sh VG_1" notify /path/to/notify.sh smtp_alert }
其中http和mysql是实例名和下面的实例名一致
notify_master /path/to/to_master.sh //表示当切换到master状态时要执行的脚本 notify_backup /path_to/to_backup.sh //表示当切换到backup状态时要执行的脚本 notify_fault "/path/fault.sh VG_1" // keepalived出现故障时执行的脚本 notify /path/to/notify.sh smtp_alert //表示切换时给global defs中定义的邮件地址发送邮件通知
2.2 VRRP实例(instance)配置范例
vrrp_instance http { //注意vrrp_instance 后面可自定义名称如lvs_httpd ,httpd state MASTER interface eth0 dont_track_primary track_interface { eth0 eth1 } mcast_src_ip <IPADDR> garp_master_delay 10 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS autp_pass 1234 } virtual_ipaddress { #<IPADDR>/<MASK> brd <IPADDR> dev <STRING> scope <SCOPT> label <LABEL> 192.168.200.17/24 dev eth1 192.168.200.18/24 dev eth2 label eth2:1 } virtual_routes { # src <IPADDR> [to] <IPADDR>/<MASK> via|gw <IPADDR> dev <STRING> scope <SCOPE> tab src 192.168.100.1 to 192.168.109.0/24 via 192.168.200.254 dev eth1 192.168.110.0/24 via 192.168.200.254 dev eth1 192.168.111.0/24 dev eth2 192.168.112.0/24 via 192.168.100.254 } nopreempt preemtp_delay 300 debug }
state: state指定instance(Initial)的初始状态就是说在配置好后这台 服务器的初始状态就是这里指定的但这里指定的不算还是得要通过竞选通过优先级来确定里如果这里设置为master但如若他的优先级不及另外一台 那么这台在发送通告时会发送自己的优先级另外一台发现优先级不如自己的高那么他会就回抢占为master
interface: 实例绑定的网卡因为在配置虚拟VIP的时候必须是在已有的网卡上添加的
dont track primary: 忽略VRRP的interface错误
track interface: 跟踪接口设置额外的监控里面任意一块网卡出现问题都会进入故障(FAULT)状态例如用nginx做均衡器的时候内网必须正常工作如果内网出问题了这个均衡器也就无法运作了所以必须对内外网同时做健康检查
mcast src ip: 发送多播数据包时的源IP地址这里注意了这里实际上就是在那个地址上发送VRRP通告这个非常重要一定要选择稳定的网卡端口来发送这里相当于heartbeat的心跳端口如果没有设置那么就用默认的绑定的网卡的IP也就是interface指定的IP地址
garp master delay: 在切换到master状态后延迟进行免费的ARP(gratuitous ARP)请求,默认5s
virtual router id: 这里设置VRID这里非常重要相同的VRID为一个组他将决定多播的MAC地址
priority 100: 设置本节点的优先级优先级高的为master
advert int: 设置MASTER与BACKUP负载均衡之间同步即主备间通告时间检查的时间间隔,单位为秒,默认1s
virtual ipaddress: 这里设置的就是VIP也就是虚拟IP地址他随着state的变化而增加删除当state为master的时候就添加当state为backup的时候删除这里主要是有优先级来决定的和state设置的值没有多大关系这里可以设置多个IP地址
virtual routes: 原理和virtual ipaddress一样只不过这里是增加和删除路由
lvs sync daemon interface: lvs syncd绑定的网卡,类似HA中的心跳检测绑定的网卡
authentication: 这里设置认证
auth type: 认证方式可以是PASS或AH两种认证方式
auth pass: 认证密码
nopreempt: 设置不抢占master,这里只能设置在state为backup的节点上而且这个节点的优先级必须别另外的高,比如master因为异常将调度圈交给了备份serve,master serve检修后没问题,如果不设置nopreempt就会将调度权重新夺回来,这样就容易造成业务中断问题
preempt delay: 抢占延迟多少秒,即延迟多少秒后竞选master
debug: debug级别
notify master: 和sync group这里设置的含义一样可以单独设置例如不同的实例通知不同的管理人员http实例发给网站管理员mysql的就发邮件给DBA
3. VRRP脚本
如下所示为相关配置示例
vrrp_script check_running {
script "/usr/local/bin/check_running"
interval 10
weight 10
}
vrrp_instance http {
state BACKUP
smtp_alert
interface eth0
virtual_router_id 101
priority 90
advert_int 3
authentication {
auth_type PASS
auth_pass whatever
}
virtual_ipaddress {
1.1.1.1
}
track_script {
check_running
}
}
首先在vrrp_script区域定义脚本名字和脚本执行的间隔和脚本执行的优先级变更,如下所示:
vrrp_script check_running { script "/usr/local/bin/check_running" interval 10 #脚本执行间隔 weight 10 #脚本结果导致的优先级变更10表示优先级+10-10则表示优先级-10 }
然后在实例(vrrp_instance)里面引用有点类似脚本里面的函数引用一样先定义后引用函数名
track_script {
check_running
}
注意:
VRRP脚本(vrrp_script)和VRRP实例(vrrp_instance)属于同一个级别
keepalived会定时执行脚本并对脚本执行的结果进行分析,动态调整vrrp_instance的优先级。一般脚本检测返回的值为0,说明脚本检测成功,如果为非0数值,则说明检测失败
如果脚本执行结果为0,并且weight配置的值大于0,则优先级相应的增加, 如果weight为非0,则优先级不变
如果脚本执行结果非0,并且weight配置的值小于0,则优先级相应的减少, 如果weight为0,则优先级不变
其他情况,维持原本配置的优先级,即配置文件中priority对应的值。
这里需要注意的是:
1) 优先级不会不断的提高或者降低
2) 可以编写多个检测脚本并为每个检测脚本设置不同的weight
3) 不管提高优先级还是降低优先级,最终优先级的范围是在[1,254],不会出现优先级小于等于0或者优先级大于等于255的情况
这样可以做到利用脚本检测业务进程的状态,并动态调整优先级从而实现主备切换。
三.virtual_server配置
virtual_server配置分为两大部分:1.虚拟主机组配置; 2.虚拟主机配置
1.虚拟主机组配置文件详解
这个配置是可选的根据需求来配置吧这里配置主要是为了让一台realserver上的某个服务可以属于多个Virtual Server并且只做一次健康检查
virtual_server_group <STRING> {
# VIP port
<IPADDR> <PORT>
<IPADDR> <PORT>
fwmark <INT>
}
2. 虚拟主机配置
关于keeplived的虚拟主机配置有三种如下所示
virtual server IP port
virtual server fwmark int
virtual server group string
通常我们比较常用的是第一种配置语法下面以第一种比较常用的方式来配详细解说一下相关配置项说明
virtual_server 192.168.1.2 80 {
delay_loop 3
lb_algo rr|wrr|lc|wlc|lblc|sh|dh
lb_kind NAT|DR|TUN
persistence_timeout 120
persistence_granularity <NETMASK>
protocol TCP
ha_suspend
virtualhost <string>
sorry_server <IPADDR> <PORT>
real_server <IPADDR> <PORT> {
weight 1
inhibit_on_failure
notify_up <STRING> | <QUOTED-STRING>
notify_down <STRING> | <QUOTED-STRING>
HTTP_GET
{
url {
path /
digest <STRING>
status_code 200
}
connect_port 80
bindto <IPADD>
connect_timeout 3
nb_get_retry 3
delay_before_retry 2
}
配置项说明
virtual_server 192.168.1.2 80
含义设置一个virtual server: VIP:Vport
delay_loop 3
含义:健康检查的时间间隔
lb_algo rr|wrr|lc|wlc|lblc|sh|dh
含义:设置LVS调度算法
lb_kind NAT|DR|TUN
含义:设置LVS集群模式
persistence_timeout 120
含义:设置会话保持时间秒为单位即以用户在120秒内被分配到同一个后端realserver,超过此时间就重新分配
persistence_granularity <NETMASK>
含义:设置LVS会话保持粒度ipvsadm中的-M参数默认是0xffffffff即每个客户端都做会话保持
protocol TCP
含义:设置健康检查用的是TCP还是UDP
ha_suspend
含义:suspendhealthchecker’s activity
virtualhost <string>
含义:HTTP_GET做健康检查时检查的web服务器的虚拟主机即host头
sorry_server <IPADDR> <PORT>
含义:设置backupserver就是当所有后端realserver节点都不可用时就用这里设置的也就是临时把所有的请求都发送到这里
real_server <IPADDR> <PORT>
含义:设置后端真实节点主机的权重等设置主要后端有几台这里就要设置几个
weight 1
含义:设置给每台的权重0表示失效(不知给他转发请求知道他恢复正常)默认是1
inhibit_on_failure
含义:表示在节点失败后把他权重设置成0而不是冲IPVS中删除
notify_up <STRING> | <QUOTED-STRING>
含义:设置检查服务器正常(UP)后要执行的脚本
notify_down <STRING> | <QUOTED-STRING>
含义:设置检查服务器失败(down)后要执行的脚本
注:keepalived检查机制说明
keepalived健康检查方式有:HTTP_GET|SSL_GET|TCP_CHECK|SMTP_CHECK|MISC_CHECK几种如下所示
1:TCP_CHECK:工作在第4层,keepalived向后端服务器发起一个tcp连接请求,如果后端服务器没有响应或超时,那么这个后端将从服务器池中移除。
2:HTTP_GET:工作在第5层,向指定的URL执行http请求,将得到的结果用md5加密并与指定的md5值比较看是否匹配,不匹配则从服务器池中移除;此外还可以指定http返回码来判断检测是否成功。HTTP_GET可以指定多个URL用于检测,这个一台服务器有多个虚拟主机的情况下比较好用。
3:SSL_GET:跟上面的HTTP_GET相似,不同的只是用SSL连接
4:MISC_CHECK:用脚本来检测,脚本如果带有参数,需将脚本和参数放入双引号内。脚本的返回值需为:
0) 检测成功
1) 检测失败,将从服务器池中移除
2-255)检测成功;如果有设置misc_dynamic,权重自动调整为 退出码-2,如退出码为200,权重自动调整为198=200-2。
5:SMTP_CHECK:用来检测邮件服务的smtp的
#HTTP/HTTPS方式
HTTP_GET|SSL_GET { 设置健康检查方式
url { 设置要检查的URL可以有多个
path / 设置URL具体路径
digest <STRING> #检查后的摘要信息这些摘要信息可以通过genhash命令工具获取
status_code 200 设置返回状态码
}
connect_port 80 设置监控检查的端口
bindto <IPADD> 设置健康检查的IP地址
connect_timeout 3 设置连接超时时间
nb_get_retry 3 设置重连次数
delay_before_retry 2 设置重连间隔
}
#TCP方式
TCP_CHECK {
connect_port 80 设置监控检查的端口
bindto <IPADD> 设置健康检查的IP地址
connect_timeout 3 设置连接超时时间
nb_get_retry 3 设置重连次数
delay_before_retry 2 设置重连间隔
}
#SMTP方式 (这个可以用来给邮件服务器做集群)
SMTP_CHECK {
host {
connect_ip <IP ADDRESS>
connect_port <PORT> #默认检查25端口
14 KEEPALIVED
bindto <IP ADDRESS>
}
connect_timeout <INTEGER>
retry <INTEGER>
delay_before_retry <INTEGER>
# "smtp HELO"|·-ê§à"
helo_name <STRING>|<QUOTED-STRING>
}
#MISC方式 这个可以用来检查很多服务器只需要自己会些脚本即可
MISC_CHECK {
misc_path <STRING>|<QUOTED-STRING> #外部程序或脚本
misc_timeout <INT> #脚本或程序执行超时时间
misc_dynamic
#这个就很好用了可以非常精确的来调整权重是后端每天服务器的压力都能均衡调配这个主要是通过执行的程序或脚本返回的状态代码来动态调整weight值使权重根据真实的后端压力来适当调整不过这需要有过硬的脚本功夫才行哦
#返回0健康检查没问题不修改权重
#返回1健康检查失败权重设置为0
#返回2-255健康检查没问题但是权重却要根据返回代码修改为返回码-2例如如果程序或脚本执行后返回的代码为200#那么权重这回被修改为 200-2
}
以上就是keepalived的配置项说明虽然配置项很多但很多时候很多配置项保持默认即可。如下为一个keepalived的配置参考模板样例
global_defs {
notification_email {
[email protected]
}
notification_email_from [email protected]
smtp_server 127.0.0.1
stmp_connect_timeout 30
router_id web_cluster
}
#static_ipaddress {
#192.168.1.1/24 brd + dev eth0 scope global
#192.168.1.2/24 brd + dev eth1 scope global
#}
#static_routes {
#src $SRC_IP to $DST_IP dev $SRC_DEVICE
#src $SRC_IP to $DST_IP via $GW dev $SRC_DEVICE
#}
#vrrp_sync_group lvsg_1 {
#group {
#lvs_http
#}
#notify_master /path/to/to_master.sh
#notify_backup /path_to/to_backup.sh
#notify_fault "/path/fault.sh VG_1"
#notify /path/to/notify.sh
#smtp_alert
#}
vrrp_script check_running {
script "/usr/local/bin/check_running"
interval 10
weight 10
}
vrrp_instance lvs_http {
state MASTER
interface eth0
#dont_track_primary
track_interface {
eth0
eth1
}
mcast_src_ip 127.0.0.1
garp_master_delay 10
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
autp_pass 1234
}
virtual_ipaddress {
#<IPADDR>/<MASK> brd <IPADDR> dev <STRING> scope <SCOPT> label <LABEL>
192.168.200.17/24 dev eth1
#192.168.200.18/24 dev eth2 label eth2:1
}
#virtual_routes {
# src <IPADDR> [to] <IPADDR>/<MASK> via|gw <IPADDR> dev <STRING> scope <SCOPE> tab
#src 192.168.100.1 to 192.168.109.0/24 via 192.168.200.254 dev eth1
#192.168.110.0/24 via 192.168.200.254 dev eth1
#192.168.111.0/24 dev eth2
#192.168.112.0/24 via 192.168.100.254
#}
track_script {
check_running
}
nopreempt
preemtp_delay 300
#debug
}
#virtual_server_group <STRING> {
# VIP port
#<IPADDR> <PORT>
#<IPADDR> <PORT>
#fwmark <INT>
#}
virtual_server 192.168.1.2 80 {
delay_loop 3
lb_algo rr
lb_kind DR
persistence_timeout 120
#persistence_granularity <NETMASK>
protocol TCP
#ha_suspend
#virtualhost <string>
sorry_server 127.0.0.1
real_server 192.168.0.100 80 {
weight 1
#inhibit_on_failure
#notify_up <STRING> | <QUOTED-STRING>
#notify_down <STRING> | <QUOTED-STRING>
HTTP_GET {
url {
path /
digest <STRING>
status_code 200
}
connect_port 80
#bindto <IPADD>
connect_timeout 3
nb_get_retry 3
delay_before_retry 2
}
}
}
测试LVS+Keepalived高可用性:
1:用客户端访问网站
http://192.168.10.172
刷新页面并观察网页的变化
2:在客户端使用脚本测试
[root@localhost ~]# for i in $(seq 10); do curl http://192.168.10.172 ;done
3:注意事项
(1)生产环境中可以使用NFS服务器保证网站代码的一致性,在测试环境中为了观察效果,web服务器池中的网站代码可以不一样,更加便于观察实验效果。
(2)测试计算机不要使用master调度器,在master调度器上访问VIP时,调度器不会将访问的请求调度到web服务器,而是自己尝试解析;在web服务器上测试时只能访问到自己的网页,无法实现调度。所以客户端一定要使用独立的测试计算机,或者使用处于BACKUP状态的调度器。