卷积神经网络(Convolutional Neural Networks,简称CNN)是深度学习领域中的一种重要模型,主要用于图像识别和计算机视觉任务。其设计灵感来自于生物学中视觉皮层的工作原理,能够高效地处理图像和语音等数据。
基本原理
CNN是一种前馈神经网络,具有层次结构,主要由卷积层、池化层、全连接层等组成。具体来说:
- 输入层:接收输入的二维图像数据。
- 卷积层:核心层次,通过卷积操作提取图像的特征。卷积层中的每个神经元只对输入图像的一部分区域敏感,这种局部连接和权值共享的特性使得CNN在处理图像时非常高效。
- 激活函数:通常使用ReLU(Rectified Linear Unit)激活函数,以增加网络的非线性能力。
- 池化层:用于降低特征图的空间维度,减少计算量并防止过拟合。常见的池化方法包括最大池化和平均池化。
- 全连接层:将前面的特征图展平成一维向量,并通过全连接层进行分类或回归。
发展历程
CNN的发展经历了多个阶段和里程碑式的模型。最早的CNN模型是LeNet-5,由Yann LeCun在1989年提出,用于手写数字识别任务。随后,AlexNet在2012年取得了显著的成功,开启了深度学习的新纪元。此后,VGGNet、GoogleNet、ResNet等经典模型相继出现,极大地推动了CNN的发展。
应用领域
CNN在多个领域都有广泛应用,特别是在图像识别、自然语言处理、语音识别等领域。例如,在图像分类与识别方面,CNN可以实现对人脸识别、动物识别等功能。此外,CNN还被应用于药物靶体交互预测、围棋人工智能等领域。
变体与改进
为了进一步提升CNN的性能,研究者们提出了许多变体和改进模型。例如,ResNet引入了残差连接来解决深层网络训练困难的问题,SENet通过自适应通道注意力机制提高了模型的泛化能力。这些变体不仅在理论上有所创新,也在实际应用中取得了显著的效果。
总结
卷积神经网络作为深度学习的重要分支,凭借其强大的特征提取能力和广泛的应用前景,成为了当前人工智能研究的热点。未来,随着计算资源的不断增长和算法的持续优化,CNN将继续在各个领域发挥重要作用,并推动人工智能技术的进一步发展。
卷积神经网络(CNN)的历史发展和关键里程碑是什么?
卷积神经网络(Convolutional Neural Networks, CNN)的历史发展和关键里程碑可以追溯到20世纪60年代,并经历了多个重要的阶段和发展。
-
早期研究(1960年代-1980年代):
- 1962年,Hubel和Wiesel对猫大脑中的视觉系统进行了研究,这是CNN发展的最早期工作之一。
- 1980年代,CNN的初步概念开始形成,主要应用于手写识别和图像处理等领域。由于计算能力的限制,当时的CNN规模较小,主要通过手工设计特征来实现。
-
Neocognitron和LeNet-5(1980年代-1990年代):
- 1989年,LeCun提出了第一个真正意义上的卷积神经网络——LeNet-5,这标志着CNN在计算机视觉领域的正式诞生。
- 这一时期,CNN主要用于手写数字识别等任务,尽管计算能力有限,但其效果显著。
- 1989年,LeCun提出了第一个真正意义上的卷积神经网络——LeNet-5,这标志着CNN在计算机视觉领域的正式诞生。
-
深度学习时代的崛起(2000年代初至今):
- 2012年,AlexNet的出现标志着深度学习时代的到来。AlexNet在ImageNet竞赛中取得了历史性的成绩,极大地推动了CNN的发展。
- 随后,ResNet、VGG、Inception等模型相继出现,进一步提升了CNN的性能和应用范围。
- 2012年,AlexNet的出现标志着深度学习时代的到来。AlexNet在ImageNet竞赛中取得了历史性的成绩,极大地推动了CNN的发展。
-
现代进展(2010年代至今):
- 近年来,随着计算能力的提升和算法的不断优化,CNN在计算机视觉、自然语言处理等多个领域取得了巨大成功。例如,最近几年内,轻量级网络结构如MobileNets、EfficientNet等也逐渐涌现。
LeNet-5模型在手写数字识别任务中的具体应用和效果如何?
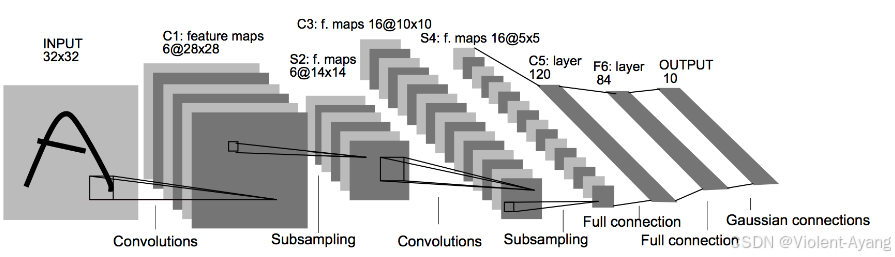
LeNet-5模型在手写数字识别任务中具有显著的应用和效果。LeNet-5是由Yann LeCun等人于1998年设计的经典卷积神经网络,主要用于手写数字识别。该模型在MNIST数据集上的准确率约为99.2%,甚至在某些情况下可以达到99.05%的识别准确率。
LeNet-5模型通过其卷积层、激励层、池化层和全连接层的设计,能够有效地处理图像数据并进行分类。在实际应用中,LeNet-5被广泛用于自动化识别系统,能够快速、准确地识别手写数字。例如,在物探工区的手写数字识别任务中,LeNet-5表现出较好的准确性、时效性和可重复性。
此外,LeNet-5模型不仅在学术研究中得到了广泛应用,还在工业实践中得到了验证。例如,有研究通过Keras高层API搭建并优化了LeNet-5网络模型,并在手写数字识别任务中取得了0.98的准确率。这进一步证明了LeNet-5在手写数字识别中的有效性和可靠性。
AlexNet模型对深度学习领域的影响及其在图像识别中的应用案例。
AlexNet模型对深度学习领域的影响及其在图像识别中的应用案例可以从以下几个方面进行详细探讨:
对深度学习领域的影响
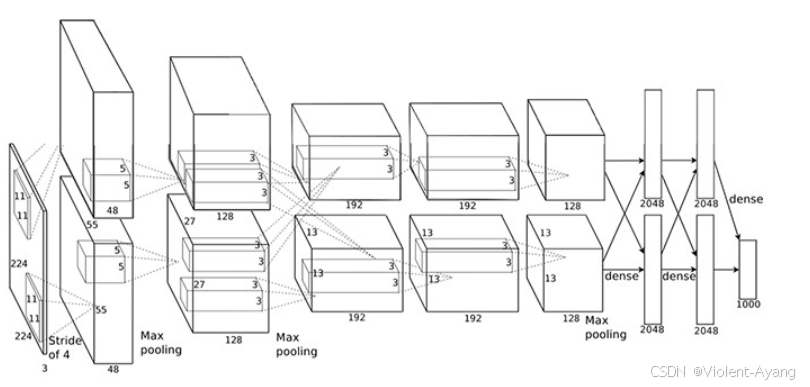
AlexNet的出现被认为是深度学习与计算机视觉领域的一次革命性突破。其成功不仅依赖于早期神经网络研究的积累,还得益于计算能力的提升,特别是GPU并行计算技术的发展。
AlexNet在2012年ImageNet Large Scale Visual Recognition Competition(ILSVRC)中以15.3%的top-5测试错误率赢得第一名,这一成绩奠定了深度学习在计算机视觉领域中的地位。它刺激了更多使用卷积神经网络和GPU来加速深度学习的研究。
AlexNet的成功引发了更多的深层卷积神经网络的研究,如VGG、GoogLeNet等。这些后续的研究进一步推动了深度学习技术的发展和应用。
在图像识别中的应用案例
基于Keras框架利用卷积神经网络类AlexNet算法实现猫狗分类识别是一个典型的应用案例。该案例通过图片数据增强、保存h5模型和加载模型等步骤,展示了AlexNet在实际图像分类任务中的应用。
另一个应用案例是使用AlexNet网络识别14种鲜花。这个案例通过层叠的卷积层和Dropout技术抑制过拟合,展示了AlexNet在复杂图像分类任务中的强大能力。
AlexNet模型还可以应用于人员口罩识别的任务。通过收集包含人员戴口罩和未戴口罩的图像数据集,并使用AlexNet模型对图像进行处理,可以实现高效的口罩佩戴检测。
ResNet与其他改进模型(如SENet、ResNet)在性能上的比较研究。
ResNet(残差网络)在性能上与其他改进模型如SENet和EfficientNet进行了多方面的比较研究。
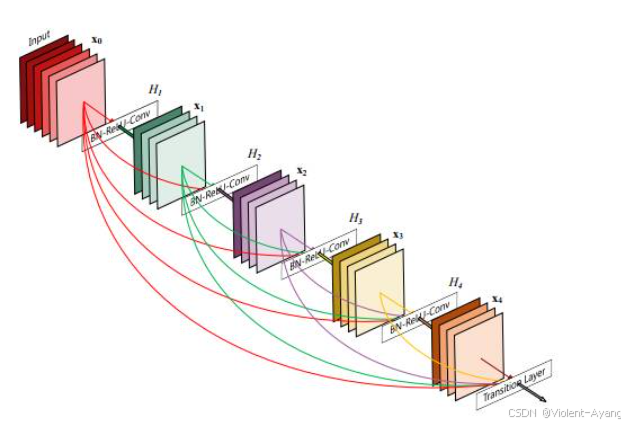
ResNet通过引入 shortcut 连接技术,有效解决了深层网络的退化问题,使得网络可以训练到更深的层次。这种设计不仅提高了模型的训练效果,还显著提升了整体性能。此外,ResNet的改进版本甚至可以训练超过3000层的网络,进一步提高了精度。
与此同时,SENet(Squeeze-and-Excitation Network)作为另一种改进模型,其核心在于通过自适应地调整通道的重要性来提升模型性能。研究表明,在某些特定情况下,SENetV2的表现优于原始ResNet,尽管其参数数量比原始ResNet多出500万。这表明SENet在特定任务中可能具有更好的适应性和性能。
另一方面,谷歌大脑和UC伯克利的研究发现,对于提升ResNet模型性能而言,改进训练方法和扩展策略比单纯的架构变化更为重要。这意味着在实际应用中,除了关注模型架构的优化外,还需要综合考虑训练方法和数据扩展策略的改进。
ResNet通过其独特的 shortcut 连接技术和深度扩展能力,在性能上有显著提升。而SENet则通过自适应通道重要性调整来优化模型性能。
CNN在自然语言处理和语音识别领域的最新进展和挑战。
卷积神经网络(CNN)在自然语言处理和语音识别领域都有显著的进展,但也面临着一些挑战。
自然语言处理领域的进展
- 应用场景:CNN在自然语言处理中的应用越来越广泛,主要应用于文本分类、情感分析、信息提取和语言模型等方面。
- 技术发展:随着深度学习技术的发展,CNN在自然语言处理领域的应用也在不断深化。例如,CNN可以用于处理具有网格结构的数据,适用于语音信号的时域和频域特征提取。
- 算法改进:深度学习的发展使得CNN在自然语言处理中的性能得到了显著提升。
语音识别领域的进展
- 性能提升:自2010年代以来,CNN在语音识别领域的突破性发展显著提升了语音识别技术的性能。
- 模型复杂性和计算资源:为了获得更好的识别效果,CNN模型通常较为复杂,需要大量的计算资源和存储空间。
- 数据需求:CNN在语音识别中需要大量的标注数据进行训练,而语音数据的标注成本较高,这在一定程度上限制了其应用。
- 特征提取:CNN通过将卷积层和池化层堆叠起来以获取更高级别的特征,从而提高语音识别的准确性。
面临的挑战
- 数据量要求:无论是自然语言处理还是语音识别,CNN都需要大量的标注数据进行训练,而这些数据的获取成本较高。
- 模型复杂性:为了达到更好的识别效果,CNN模型通常较为复杂,需要大量的计算资源和存储空间。
- 训练时间:人工神经网络在语音识别中存在训练时间较长的问题。
- 过拟合:在处理复杂数据时,CNN可能会出现过拟合现象,影响模型的泛化能力。
CNN在自然语言处理和语音识别领域都取得了显著的进展,但同时也面临着数据量大、模型复杂、训练时间长等挑战。