Pre-Trained Image Processing Transformer
1.四个问题
要解决什么问题
低视觉任务(去燥、超分辨率、去雨、去模糊等):图像处理
探索一种用于图像处理任务的通用预训练方法
用什么方法解决
基于Transformer架构,通过大规模数据集,开发了一个用于图像处理的预训练模型,即图像处理转换器(IPT),以端到端的方式进行学习。
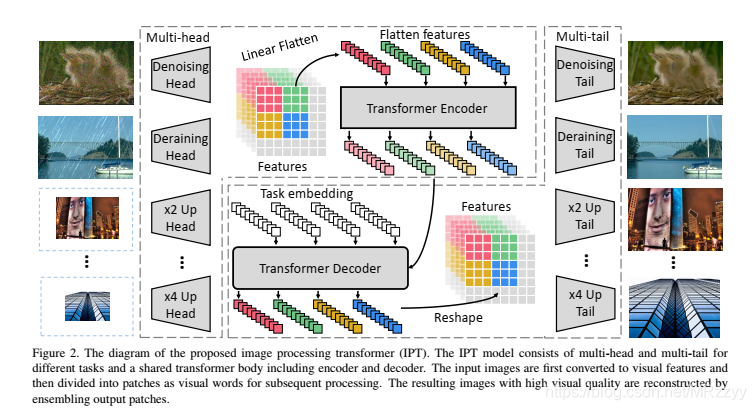
整个模型分为3个部分:a.从损坏图像中提取特征的头部;b.用于恢复属于数据中心丢失信息的编码器-解码器转换器;c.用于将特征恢复为图像的尾部
将ImageNet数据集中的图像进行处理,模拟复杂的自然界,生成损坏的图像进行模型的训练
效果如何
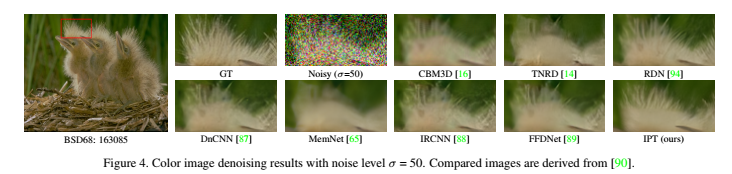
在ImageNet数据集中,与SOTA相比,在去噪和去雨中都取得最优结果。在BSD68和Urban100数据集上,也取得最优结果,同时胜过CNN方法。
还存在什么问题
Transformer架构需要大规模的数据集来进行训练。
合成各种损坏的图像,但是自然图像的复杂度更高,故无法合成所有图像进行训练。(泛化能力)
论文简介
摘要随着现代硬件的计算能力强劲增长,在大规模数据集上学习的预训练深度学习模型(例如 BERT、GPT-3)已显示出其优于传统方法的有效性。 大的进步主要归功于transformer及其变体架构的表示能力。 在本文中,我们研究了低级计算机视觉任务(例如,去噪、超分辨率和去雨)并开发了一种新的预训练模型,即图像处理转换器(IPT)。 为了最大限度地挖掘transformer的能力,我们提出利用众所周知的ImageNet基准来生成大量损坏的图像对。 IPT 模型在这些具有多头和多尾的图像上进行训练。 此外,引入对比学习以很好地适应不同的图像处理任务。 因此,预训练的模型可以在微调后有效地用于所需的任务。 仅使用一个预训练模型,IPT 在各种低级基准测试中都优于当前最先进的方法。 代码可在 https://github.com/huawei-noah/Pretrained-IPT 和 https:// gitee.com/ mindspore/ mindspore/ tree/master/model_zoo/research/cv/IPT上获得。
网络结构
实验结果
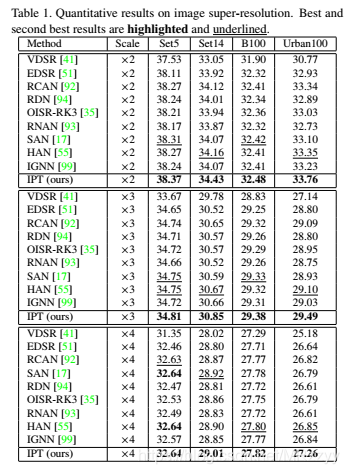
表1:超分辨率定量结果
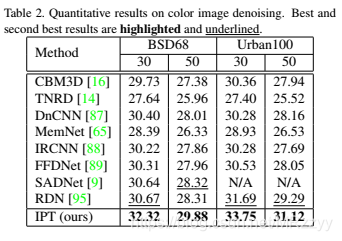
表2:去噪定量结果
表3:去雨定量结果
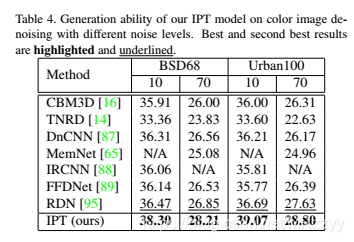
表4:对不同噪声水平的彩色图像去噪的生成能力。
实验效果展示: