第二部分:员工离职预测
在上期用过bi分析了离职数据集,本期用所学的机器学习算法来试着预测职工离职概率。
点击跳转上一期:离职情况分析①
开发步骤概述
一、导入模块与文件
##引入必要的包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
import seaborn as sns
from sklearn import preprocessing
%matplotlib inline
## 导入文件
df_online=pd.read_csv(r'C:\Users\ADMIN\Desktop\离职预测\machine learning\online.csv')
df_offline=pd.read_csv(r'C:\Users\ADMIN\Desktop\离职预测\machine learning\offline.csv')
## 合并文件&查看
df=pd.concat([df_online,df_offline])
df.head()
共计28211行,19列特征

二、数据清洗
##去重
df.drop_duplicates()
df.info()
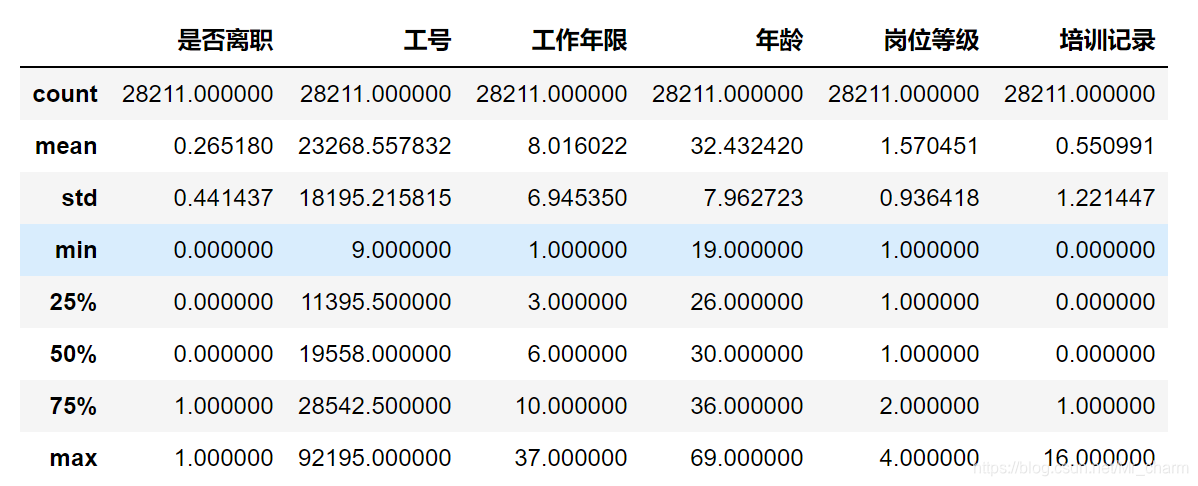
df.describe()
- 其中数据清洗过程过于冗长详细
- 比如工时、工种、年龄缺失,根据岗位类型、部门等等进行填补,
- 比如进公司时间缺失,可以根据年龄和工作年限反推
- 比如年龄等等之类异常值,这次主要想讲述特征工程,故不多赘述这块
三、特征工程
3.1特征构造
- 看看清洗后的数据概况
##重新设置index
df=df.reset_index(drop=True)
df.info()
一共28211条数据,其中数值型有6条,先看看有没有什么异常值。
进一步处理特征

##转换数据类型
df.出生日期=pd.to_datetime(df.出生日期)
df.进公司时间=pd.to_datetime(df.进公司时间)
##删去明显无关的特征
df.drop(['工号','姓名','合同所属地'],axis=1,inplace=True)
##转换类别特征,变成有序类别数值型特征
df.groupby(by='学历').size()
a=[]
for i in df.学历:
if i=='专科':
a.append(1)
elif i=='本科':
a.append(2)
elif i=='研究生':
a.append(3)
else:
a.append(4)
len(a)
df['教育程度']=a
因为进公司时间与工作年限,出生日期与年龄这两对特征本身基本可以互相转换,线性相关性较强,为了简单理解,本次处理先
删去进公司时间、出生日期,以及用教育程度代替学历

df.drop(['进公司时间','出生日期','学历'],axis=1,inplace=True)
得到特征
因为计算机最终都是以识别数值型的数据为基础开始机器学习,红框中还有很多文字性特征后续需要进行独热编码

- 查看正负样本比例
符合真实情况,大概是3/7开
pos_data=df[df.是否离职==1]
neg_data=df[df.是否离职==0]
print('正样本数量:{},所占比例:{}'.format(len(pos_data),len(pos_data)/len(df)))
print('负样本数量:{},所占比例:{}'.format(len(neg_data),len(neg_data)/len(df)))

3.2 特征筛选
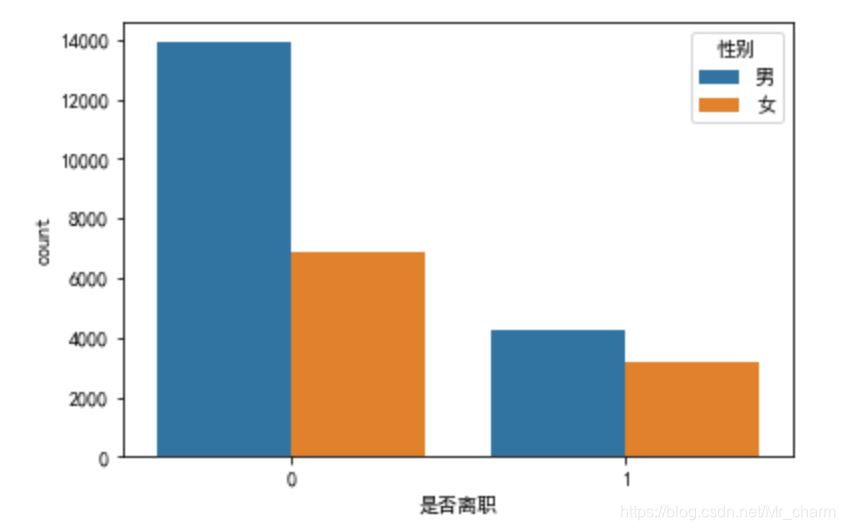
查看离职标签特征与其他维度特征的关系
法一:单个变量之间看
plt.figure
sns.countplot(x='是否离职',data=df,hue='性别') ##hue里面可以替换成学历、岗位等级等等。
箱型图表示
# 单变量关系
p