文章目录
Spark和MapReduce场景应用和区别
一、引言
在大数据处理领域,MapReduce和Spark是两个非常重要的框架。MapReduce是Hadoop生态系统的核心组件,而Spark则是一个更为现代的、支持内存计算的框架。它们都旨在简化大规模数据集的处理,但在设计理念、性能和应用场景上存在显著差异。本文将深入探讨这两种技术的应用场景和主要区别,并提供代码示例以便更好地理解它们的工作方式。
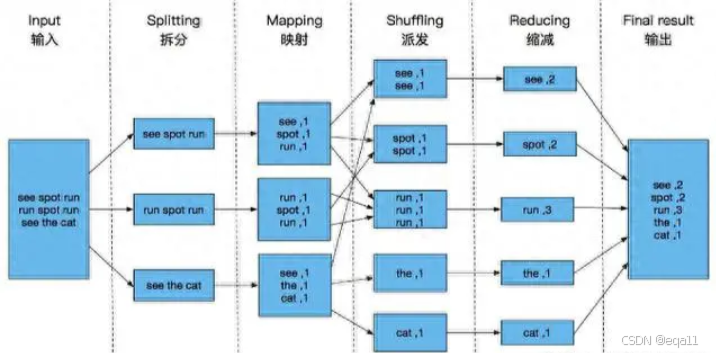
二、MapReduce和Spark的应用场景
1. MapReduce的应用场景
MapReduce主要适用于批量数据处理,如大规模数据的ETL任务、批量报表生成。它适合于不需要频繁迭代的大数据计算任务,因为每次MapReduce作业都需要从磁盘读取数据并将结果写回磁盘,这导致了较高的延迟。
2. Spark的应用场景

Spark适用于需要多次迭代计算的任务,如机器学习算法的训练。通过Spark Streaming可以处理实时数据流,Spark SQL支持即席查询(ad-hoc query),适用于数据分析和探索。此外,Spark也适用于需要复杂数据处理的场景,如图计算和机器学习。
三、MapReduce和Spark的区别
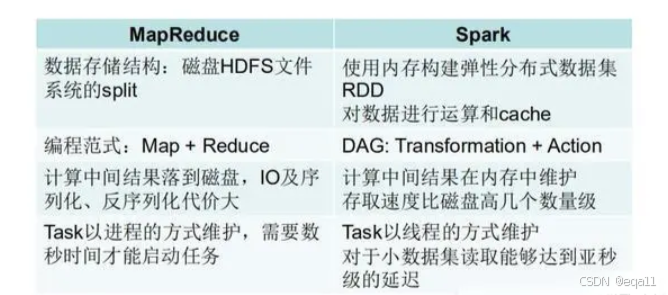
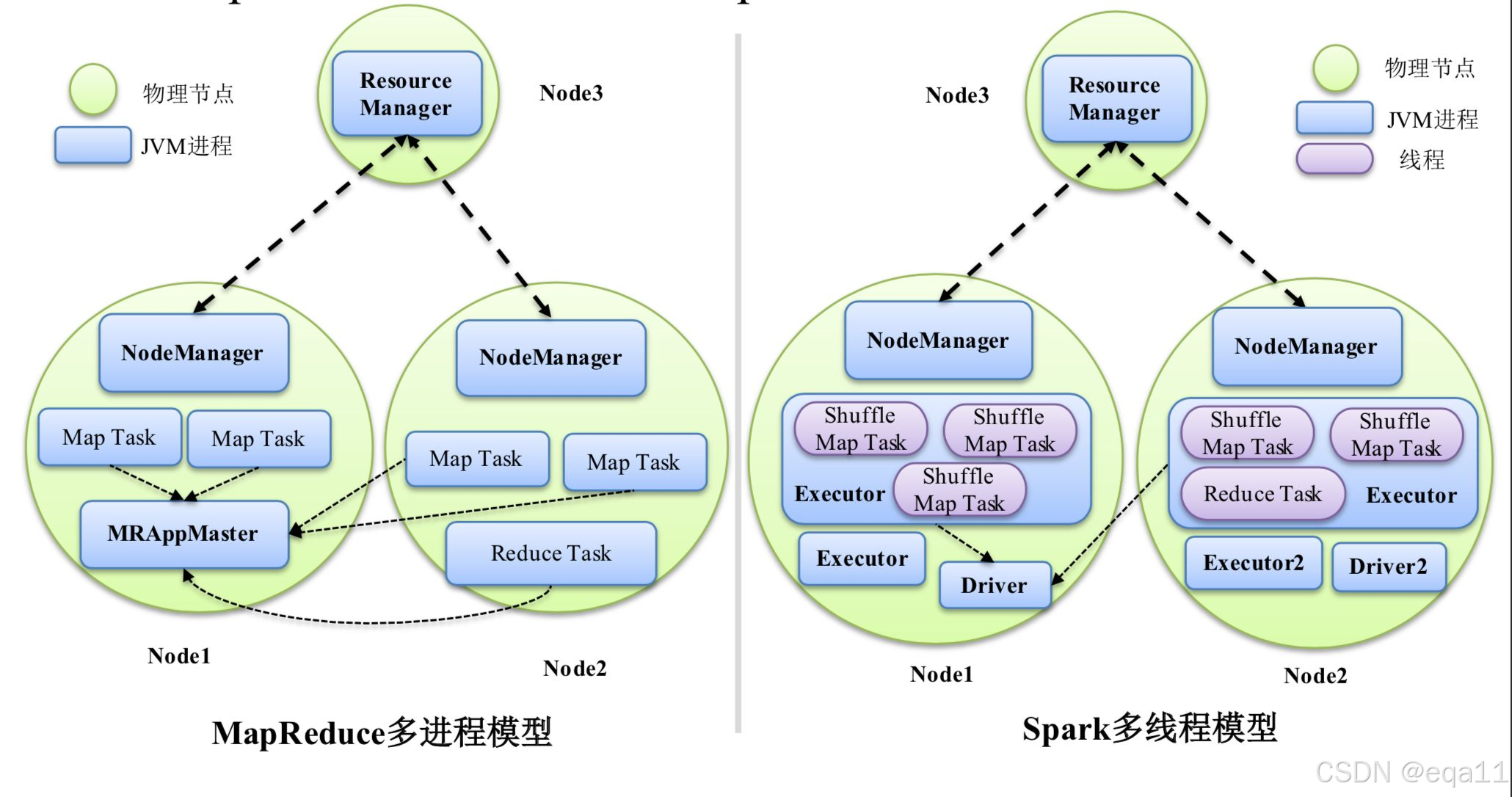
1. 内存使用和性能
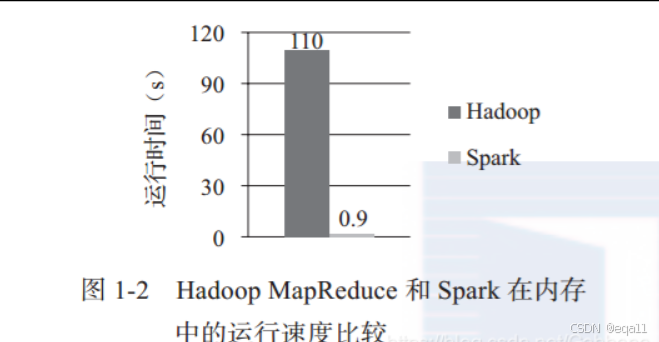
MapReduce将中间数据写入磁盘,而Spark将中间数据存储在内存中,这使得Spark在某些情况下比MapReduce更快,尤其是对于迭代计算和交互式查询等需要多次读写数据的场景。Spark利用内存计算,对于需要多次迭代的数据处理任务,如机器学习和图计算,性能远超MapReduce。
2. 编程模型和易用性
MapReduce使用Java编程接口,而Spark支持多种编程语言接口,包括Java、Scala、Python和R,使得开发者可以使用自己熟悉的语言进行开发。Spark提供了更高级的API,支持Scala、Java、Python和R等多种语言,使得编写和调试代码更加容易。
3. 实时计算支持
Spark提供了实时流处理功能,可以对数据进行实时处理和分析,而MapReduce主要用于离线批处理。
四、使用示例
1. MapReduce代码示例
以下是一个简单的MapReduce程序,用于计算文本文件中的单词频率:
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
String[] tokens = value.toString().split("\\s+");
for (String token : tokens) {
word.set(token);
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
2. Spark代码示例
以下是一个简单的Spark程序,同样用于计算文本文件中的单词频率:
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("WordCount").setMaster("local[*]")
val sc = new SparkContext(conf)
val textFile = sc.textFile(args(0))
val counts = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
counts.saveAsTextFile(args(1))
sc.stop()
}
}
五、总结
MapReduce和Spark都是强大的大数据处理工具,但它们在设计理念和性能上有所不同。MapReduce适合于大规模的批量数据处理,而Spark则因其内存计算特性和丰富的数据处理操作,更适合于需要快速迭代和实时处理的场景。选择合适的工具需要根据具体的业务需求和数据特点来决定。
版权声明:本博客内容为原创,转载请保留原文链接及作者信息。
参考文章: