导读:Paddle Lite高性能推理引擎支持FPGA作为其底层加速硬件,其支持的模型可以很简单的部署到FPGA计算卡上,利用Paddle Lite上层框架的优化能力,加上FPGA底层超强的计算能力,在精度损失很小的情况下,模型运行速度可以得到很大的提升。本文通过Paddle Lite高性能推理引擎在百度EdgeBoard计算卡上部署蔬菜识别模型,达到了实时高效识别蔬菜品类的效果。
1. 基于飞桨开源深度学习平台的AI解决方案
作为飞桨开源深度学习平台的重要组成部分,Paddle Lite和EasyEdge通过有机组合,可以快速实现基于FPGA的嵌入式AI解决方案,具有高性能、高通用、低成本、易开发等四大优点,适用于开发验证、产品集成、科研教学、项目落地等应用方向,以及安防监控、工业质检、医疗诊断、农作物生长监控、无人驾驶、无人零售等应用场景。
2. 真实案例:蔬菜种类识别
针对真实的业务需求:蔬菜种类识别,本文进行了完整的案例实现。简便起见,我们采用了百度AI Studio的公开蔬菜识别模型,为了进一步提高识别速度和效率,采用的是int8量化训练的模型,量化的优点包括低内存带宽、低功耗、低计算资源占用以及低模型存储需求等。这里,硬件我们采用EdgeBoard来实现
图1 EdgeBoard计算卡
2.1. 量化训练原理
量化是将浮点数量化成定点数,以最大绝对值量化(max-abs)为例,量化公式如下:
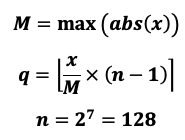
前向计算量化过程如下:
a. 输入和权重被量化为8-bit整数
b. 在8-bit整数上执行矩阵乘法或卷积
c. 对矩阵乘法或者卷积操作的输出结果进行反量化,输出为32-bit浮点数
d. 在32-bit浮点型数据上执行偏置加法操作

图2 量化训练前向过程(左为量化过程,右为等价工作流)
为了充分的利用GPU提供的加速支持,上述的前向计算流可以等价为图2右的工作流:
对应反向传播计算过程:

图3 量化计算反向传播过程
2.2. 模型训练
本文采用的模型是Resnet50模型,它引入了新的残差结构,解决了随着网络加深,准确率下降的问题,在分类问题上表现良好,可以通过以下步骤进行模型训练:
a. 打开百度AI Studio官网https://aistudio.baidu.com/
b. 点击顶部菜单:项目->公开项目, 搜索 “EdgeBoard-Resnet50”,点击打开。
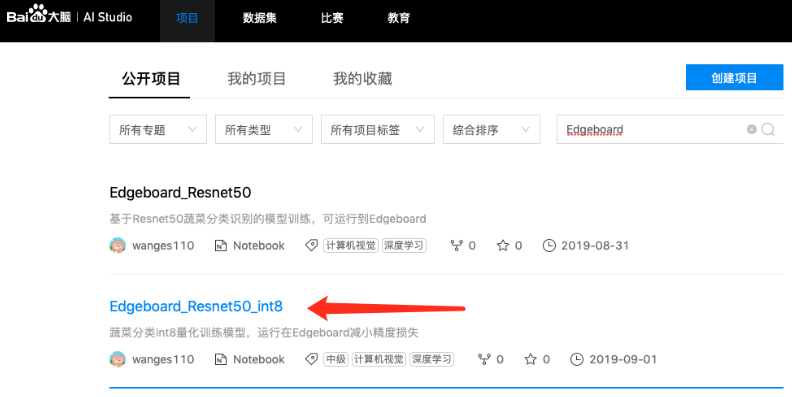
c. 加载训练数据和float模型,量化训练8bit模型

d. CPU评估量化训练模型效果

3. 模型的部署与测试
3.1. Paddle Lite支持FPGA硬件原理
Paddle Lite完整支持从Mobile到Server多种硬件,这主要得益于对不同硬件的统一抽象,不同的硬件提供统一的接口给上层框架,形成了硬件的可插拔,极大方便了底层硬件的扩展与支持。FPGA作为Paddle Lite的Backends之一,将自身硬件相关的kernel、驱动及内核进行了包装并向Paddle Lite提供了统一的op调用接口,使得Paddle Lite能很方便的集成FPGA的计算能力。同时通过Paddle Lite上层框架对模型的优化能力,包括各种op融合、计算剪枝、存储复用、量化融合的优化pass,以及kernel的最优调度、混合部署等功能,进一步实现了模型加速。整体结构原理如图所示。
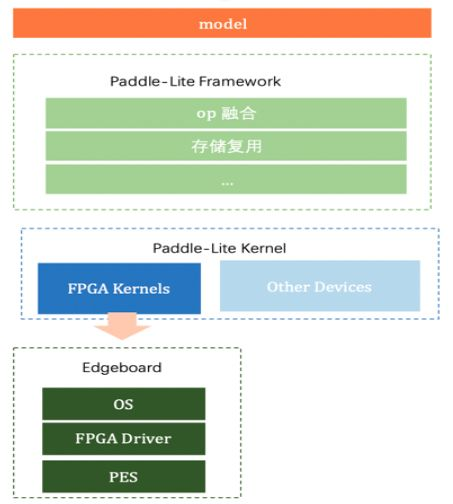
图4 Paddle Lite支持EdgeBoard原理
3.2. Paddle Lite库编译
3.2.1. 拉取Paddle Lite库
git clone https://github.com/PaddlePaddle/Paddle Lite.git
3.2.2.编译Paddle Lite FPGA库
可以使用Paddle Lite使用的docker
cd Paddle Lite && ./lite/tools/build_FPGA.sh
编译完成时build_FPGA/lite/inference_lite_lib.armlinux.armv8.FPGA/cxx里包含了所需的头文件文件夹include和库文件夹lib,lib下静态库libpaddle_api_full_bundled.a是我们所需的Paddle Lite静态库文件
3.3. EdgeBoard模型部署
利用Paddle Lite在EdgeBoard上进行模型部署很简单,只需将include下头文件包含到调用Paddle Lite的代码文件中,将静态库文件与工程文件联编成可执行程序,即可运行。其中调用Paddle Lite的步骤如下:
3.3.1. 包含头文件
#include "paddle_api.h"
#include "paddle_use_kernels.h"
#include "paddle_use_ops.h"
#include "paddle_use_passes.h"
using namespace paddle::lite_api;
3.3.2. 设置配置参数
std::vector<Place> valid_places({Place{TARGET(kFPGA), PRECISION(kFP16), DATALAYOUT(kNHWC)},
Place{TARGET(kHost), PRECISION(kFloat), DATALAYOUT(kNCHW)}});
std::string model_dir = j["model"];
std::string model_file = model_dir + "/model";
std::string params_file = model_dir + "/params";
// 1. Set CxxConfig
CxxConfig config;
config.set_model_dir(model_dir);
config.set_model_file(model_file);
config.set_param_file(params_file);
config.set_preferred_place(Place{TARGET(kFPGA), PRECISION(kFP16), DATALAYOUT(kNHWC)});
config.set_valid_places(valid_places);
3.3.3. 创建预测器
// 2. Create PaddlePredictor by CxxConfig
predictor = CreatePaddlePredictor<CxxConfig>(config);
3.3.4. 设置输入数据
std::unique_ptr<Tensor> input_tensor(std::move(predictor->GetInput(0)));
input_tensor->Resize(shape_t({1, 3, 224, 224}));
auto* input = input_tensor->mutable_data<float>();
read_image(value, input);
3.3.5. 开始预测
// 4. Run predictor
for (int i = 0;i < 2; i++) {
predictor->Run();
}
3.3.6. 获取运行结果
// 5. Get output
std::unique_ptr<const Tensor> output_tensor;
std::move(predictor->GetOutput(0)));
3.4. 应用测试
将EdgeBoard计算卡与摄像头相连,可以测试我们的蔬菜识别模型的效果与运行速度,整个测试结果如下:
3.4.1. 检测结果测试
随便选取若干张图片,测试结果如下:

图5 EdgeBoard后台模型运行过程
再把图片可视化的效果看一下:


图6 EdgeBoard运行效果
3.4.2. 运行性能测试
对比ARM端芯片,EdgeBoard的性能有4-14倍提升,如下图所示:

图7 EdgeBoard对比ARM芯片,其他芯片数据均来测于Paddle Lite beta1版本 armv8+4线程,纵轴单位为ms
对比主流边缘及端类芯片,EdgeBoard也有不错的表现:
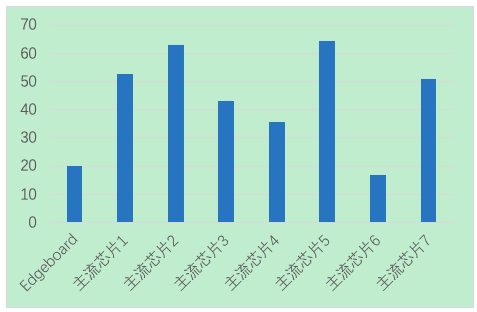
图8 与同类主流芯片性能比较,纵轴单位为ms
4. 总结
本文利用Paddle Lite推理引擎在EdgeBoard计算卡上部署Resnet50 int8量化蔬菜识别模型,实现了边缘端智能识别蔬菜品类的功能,可用于多种场景。整个应用借助Paddle Lite的上层框架优化能力与FPGA的底层计算加速能力,每秒可识别50帧,真正实现实时高效的蔬菜识别。
本案例具有极高的拓展性,由于Paddle Lite可以和飞桨PaddlePaddle模型无缝对接,加上EdgeBoard计算卡的软件可持续迭代、op持续更新等特点,在模型支持上的数量上和速度上均会有很大优势,如本文所用模型也可以更换成Inception等常用的分类模型或检测模型。
