一、决策树
决策树的原理
决策树(Decision Tree),它是一种以树形数据结构来展示决策规则和分类结果的模型,作为一种归纳学习算法,其重点是将看似无序、杂乱的已知数据,通过某种技术手段将它们转化成可以预测未知数据的树状模型,每一条从根结点(对最终分类结果贡献最大的属性)到叶子结点(最终分类结果)的路径都代表一条决策的规则。
原理如图:
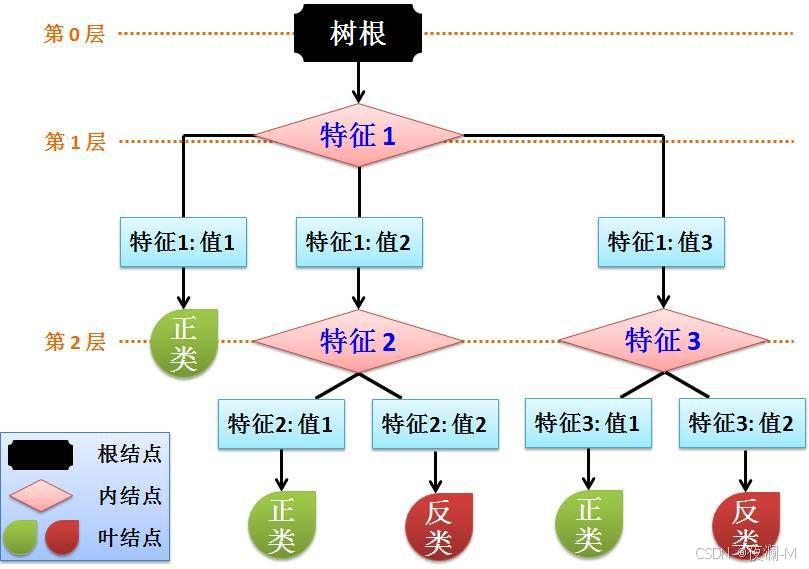
决策树的实现:
- 特征选择:根据某个评价指标(如信息增益、基尼指数等),选择最佳的特征作为当前节点的划分特征。(即哪个特征带来最多的信息变化幅度,就选择哪一个特征来分类)
- 划分数据集:根据选择的特征,将数据集划分成多个子集,每个子集对应一个分支。对于离散特征,可以根据特征值的不同进行划分;对于连续特征,可以选择一个阈值进行划分。
- 递归构建子树:对每个子集递归地构建子树,直到所有子集被正确分类或满足终止条件。常见的终止条件有:达到最大深度、样本数量小于阈值、节点中的样本属于同一类别等。
- 避免过拟合:对决策树进行剪枝处理。剪枝可以分为前剪枝和后剪枝: 前剪枝是在构建树的过程中进行剪枝,通过设定一个阈值,信息熵减小的数量小于这个值则停止创建分支;后剪枝则是在决策树构建完成后,对节点检查其信息熵的增益来判断是否进行剪枝。还可以通过控制决策树的最大深度(max_depth)
决策树的优点:
- 决策树易于理解和实现,人们在在学习过程中不需要使用者了解很多的背景知识,这同时是它的能够直接体现数据的特点,只要通过解释后都有能力去理解决策树所表达的意义
- 对于决策树,数据的准备往往是简单或者是不必要的,而且能够同时处理数据型和常规型属性,在相对短的时间内能够对大型数据源做出可行且效果良好的结果
- 易于通过静态测试来对模型进行评测,可以测定模型可信度;如果给定一个观察的模型,那么根据所产生的决策树很容易推出相应的逻辑表达式
决策树的缺点:
- 对连续性的字段比较难预测
- 对有时间顺序的数据,需要很多预处理的工作
- 当类别太多时,错误可能就会增加的比较快
- 一般的算法分类的时候,只是根据一个字段来分类
二、随机森林
随机森林的原理
将多个决策树结合在一起,每次数据集是随机有放回的选出,同时随机选出部分特征作为输入,所以该算法被称为随机森林算法。可以看到随机森林算法是以决策树为估计器的Bagging算法。算法的具体步骤为:假设有一个大小为 N 的训练数据集,每次从该数据集中有放回的取选出大小为 M 的子数据集,一共选 K 次,根据这 K 个子数据集,训练学习出 K 个模型。当要预测的时候,使用这 K 个模型进行预测,再通过取平均值或者多数分类的方式,得到最后的预测结果。
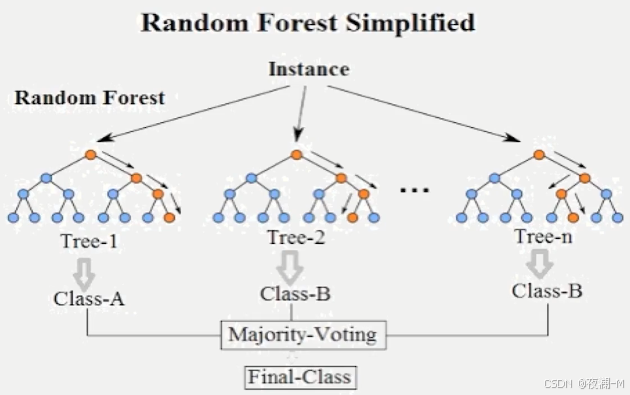
使用Bagging算法能降低过拟合的情况,从而带来了更好的性能。单个决策树对训练集的噪声非常敏感,但通过Bagging算法降低了训练出的多颗决策树之间关联性,有效缓解了上述问题。
随机森林的优点:
- 对于很多种资料,它可以产生高准确度的分类器
- 它可以处理大量的输入变数
- 它可以在决定类别时,评估变数的重要性
- 在建造森林时,它可以在内部对于一般化后的误差产生不偏差的估计
- 它包含一个好方法可以估计遗失的资料,并且,如果有很大一部分的资料遗失,仍可以维持准确度
- 对于不平衡的分类资料集来说,它可以平衡误差
-
学习过程是很快速的
随机森林的缺点:
- 牺牲了决策树的可解释性
- 在某些噪音较大的分类或回归问题上会过拟合
- 在多个分类变量的问题中,随机森林可能无法提高基学习器的准确性
总结:
总之,决策树和随机森林都是基于树结构的机器学习算法,具有可解释性和特征选择的能力。随机森林是多个决策树的集成模型,引入了随机性并通过投票或平均来得出最终预测结果,可以有效降低噪声干扰,提高模型的准确性与稳定性,但是增加了计算量。