京东商城的页面不是静态页面,其评论信息存放于json文件中,由ajax控制,所以我们在浏览器上看到的网页源代码和用Python爬下来的是不一样的,所以我们真正要爬取的是评论数据所存放的json文件。
首先打开一个京东商品的评论页面,按F12。然后点击network之后再刷新一次页面,会显示如下信息。
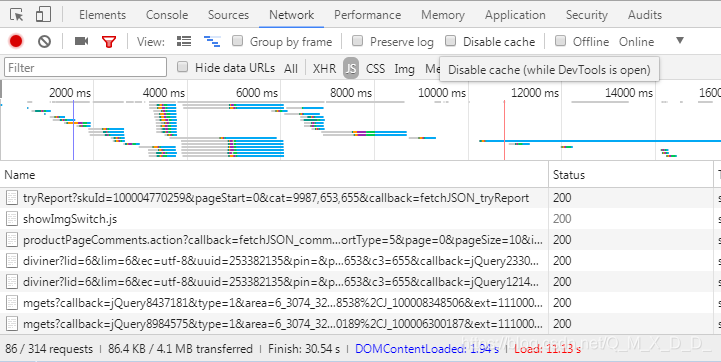
在所有的json文件中找到那个存放评论的文件:
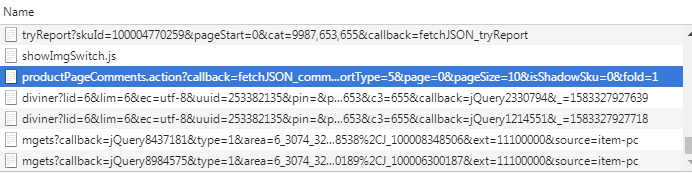
观察其URL,其中有一个参数是page=0,大概这个参数表示第几页评论,那么我们就可以通过修改page参数来获取其他所有页的评论,分析完之后开始编写程序。
首先创造Request对象,然后使用urlopen函数将该文件爬取下来,通过Python中的json库来解析改文件,最后保存到文件中。代码如下:
import urllib.request
import json
import time
import xlwt
#======》爬取评论信息《=======#
end_page = int(input('请输入爬取的结束页码:'))
for i in range(0,end_page+1):
print('第%s页开始爬取------'%(i+1))
url = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100004770259&score=0&sortType=5&page={}&pageSize=10&isShadowSku=0&fold=1 '
url = url.format(i)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36',
'Referer': 'https://item.jd.com/100004770259.html'
}
request = urllib.request.Request(url=url,headers=headers)
content = urllib.request.urlopen(request).read().decode('gbk')
content = content.strip('fetchJSON_comment98vv385();')
obj = json.loads(content)
comments = obj['comments']
fp = open('京东.txt','a',encoding='utf8')
for comment in comments:
#评论时间
creationTime = comment['creationTime']
#评论人
nickname = comment['nickname']
#评论内容
contents = comment['content']
item = {
'评论时间': creationTime,
'用户': nickname,
'评论内容': contents,
}
string = str(item)
fp.write(string + '\n')
print('第%s页完成----------'%(i+1))
time.sleep(4)
fp.close()
更新
这个程序比较低效,在新的博客中我实现了一个功能更加强大的程序:Python爬取京东商品评论(二)、Python爬取京东商品评论(三)