在机器学习的广阔天地里,算法可谓是核心中的核心。机器学习算法大致能分为监督学习、无监督学习以及强化学习这几大类别。不同类别的算法各有千秋,适用于各种各样的场景。今天,咱们就来深入聊聊监督学习和无监督学习中的一些常见算法。
监督学习算法
线性回归(Linear Regression)
线性回归主要用于回归任务,目标是预测连续的数值。它的原理是探寻输入特征与目标值之间的线性关系,进而得出一个连续的输出结果。比如说在预测房价、股票价格这类实际场景中,线性回归就大有用武之地。它的目标是找到一个形如 y=w1x1+w2x2+⋯+wnxn+b 的最佳线性方程。这里面,y 代表预测值,也就是我们的目标值;x1,x2,⋯,xn 是输入特征;w1,w2,⋯,wn 是需要学习的权重,也就是模型的参数;b 则是偏置项。
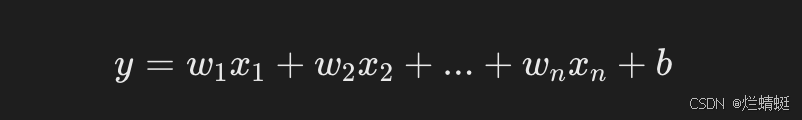
下面咱们用 sklearn 库来做个简单的房价预测示例。
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
import pandas as pd
# 假设我们有一个简单的房价数据集
data = {
'面积': [50, 60, 80, 100, 120],
'房价': [150, 180, 240, 300, 350]
}
df = pd.DataFrame(data)
# 特征和标签
X = df[['面积']]
y = df['房价']
# 数据分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
print(f"预测的房价: {y_pred}")行这段代码,得到的输出结果是:预测的房价: [180.8411215] 。
逻辑回归(Logistic Regression)
逻辑回归虽然名字里有 “回归” 二字,但它实际上是用于二分类任务的算法。它的工作方式是学习输入特征与类别之间的关系,以此来预测类别标签。在垃圾邮件分类、疾病诊断(判断是否患病)等场景中,逻辑回归经常被使用。逻辑回归的输出是一个概率值,表示样本属于某一类别的概率,通常会借助 Sigmoid 函数来实现。
下面通过代码看看如何用逻辑回归进行二分类任务。
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 只取前两类做二分类任务
X = X[y != 2]
y = y[y != 2]
# 数据分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练逻辑回归模型
model = LogisticRegression()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型
print(f"分类准确率: {accuracy_score(y_test, y_pred):.2f}")运行后,输出结果为:分类准确率: 1.00 。
支持向量机(SVM)
支持向量机是一种常用的分类算法,它的核心思路是构造一个超平面,通过最大化类别之间的间隔,让分类误差达到最小。在文本分类、人脸识别等领域,支持向量机都有着出色的表现。
下面我们用它来完成鸢尾花的分类任务。
from sklearn.svm import SVC
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 数据分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 训练 SVM 模型
model = SVC(kernel='linear')
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型
print(f"SVM 分类准确率: {accuracy_score(y_test, y_pred):.2f}")最终输出结果为:SVM 分类准确率: 1.00 。
决策树(Decision Tree)
决策树是基于树结构来进行决策的,既可以用于分类,也能用于回归。它通过一系列的 “判断条件”,逐步确定一个样本所属的类别。在客户分类、信用评分等场景中,决策树能发挥很大的作用。
下面我们用决策树进行分类任务。
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 数据分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 训练决策树模型
model = DecisionTreeClassifier(random_state=42)
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型
print(f"决策树分类准确率: {accuracy_score(y_test, y_pred):.2f}")输出结果为:决策树分类准确率: 1.00 。
无监督学习算法
K - means 聚类(K - means Clustering)
K - means 是一种基于中心点的聚类算法。它的工作方式是不断调整簇的中心点,让每个簇内的数据点尽可能靠近簇中心。在客户分群、市场分析、图像压缩等场景中,经常能看到它的身影。
下面我们用 K - means 来进行客户分群。
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
# 生成一个简单的二维数据集
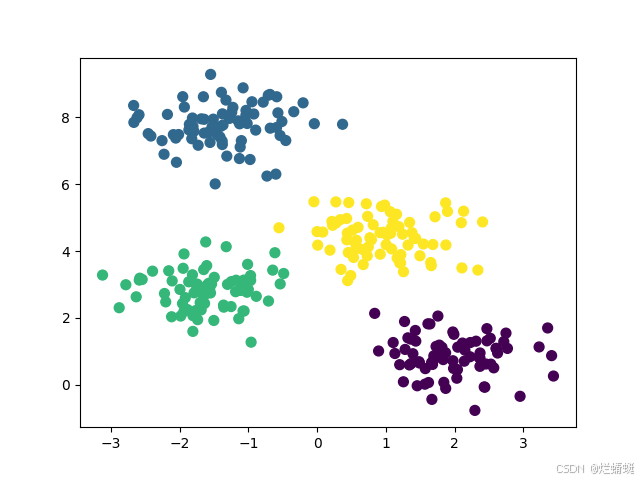
X, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
# 训练 K - means 模型
model = KMeans(n_clusters=4)
model.fit(X)
# 预测聚类结果
y_kmeans = model.predict(X)
# 可视化聚类结果
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap='viridis')
plt.show()运行代码后,会生成一个可视化聚类结果的图。
主成分分析(PCA)
PCA 是一种降维技术,它通过线性变换,把数据转换到新的坐标系中,让大部分方差集中在前几个主成分上。在图像降维、特征选择、数据可视化等方面,PCA 有着广泛的应用。
下面我们用 PCA 来降维并可视化高维数据。
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 降维到 2 维
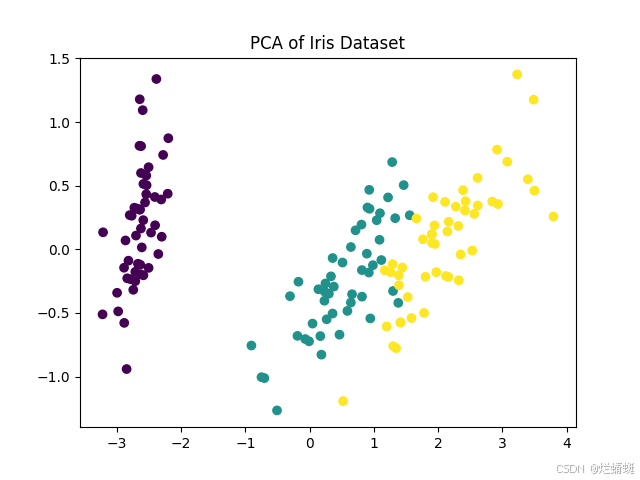
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
# 可视化结果
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y, cmap='viridis')
plt.title('PCA of Iris Dataset')
plt.show()运行代码后,会得到一个展示 PCA 处理鸢尾花数据集结果的可视化图。
在实际应用中,我们要根据数据的特征,比如数据有没有标签、数据的维度等,来挑选最合适的机器学习算法,这样才能让算法发挥出最大的效能。希望今天介绍的这些算法能给大家在机器学习的学习和实践中带来帮助。