
最近做了几个实时数据开发需求,也不可避免地在使用Flink的过程中遇到了一些问题,比如数据倾斜导致的反压、interval join、开窗导致的水位线失效等问题,通过思考并解决这些问题,加深了我对Flink原理与机制的理解,因此将这些开发经验分享出来,希望可以帮助到有需要的同学。
下文会介绍3个case案例,每个case都会划分为背景、原因分析和解决方法三部分来进行介绍。

Case1: 数据倾斜
数据倾斜无论是在离线还是实时中都会遇到,其定义是:在并行进行数据处理的时候,按照某些key划分的数据显著多余其他部分,分布不均匀,导致大量数据集中分布到一台或者某几台计算节点上,使得该部分的处理速度远低于平均计算速度,成为整个数据集处理的瓶颈,从而影响整体计算性能。造成数据倾斜的原因有很多种,如group by时的key分布不均匀,空值过多、count distinct等,本文将只介绍group by + count distinct这种情况。
▐ 背景
对实时曝光流,实时统计近24小时创意的曝光UV和PV。且每分钟更新一次数据。通用的方法就是使用hop滑动窗口来进行统计,代码如下:
select
HOP_START(
ts
,interval '1' minute
,interval '24' hour
) as window_start
,HOP_END(
ts
,interval '1' minute
,interval '24' hour
) as window_end
,creative_id
,count(distinct uid) as exp_uv -- 计算曝光UV
,count(uid) as exp_pv --计算曝光PV
from dwd_expos_detail
group by
hop(
ts
,interval '1' minute
,interval '24' hour
) -- 滑动窗口开窗,窗口范围:近24小时,滑动间隔:每1分钟
,creative_id▐ 问题及原因
问题发现
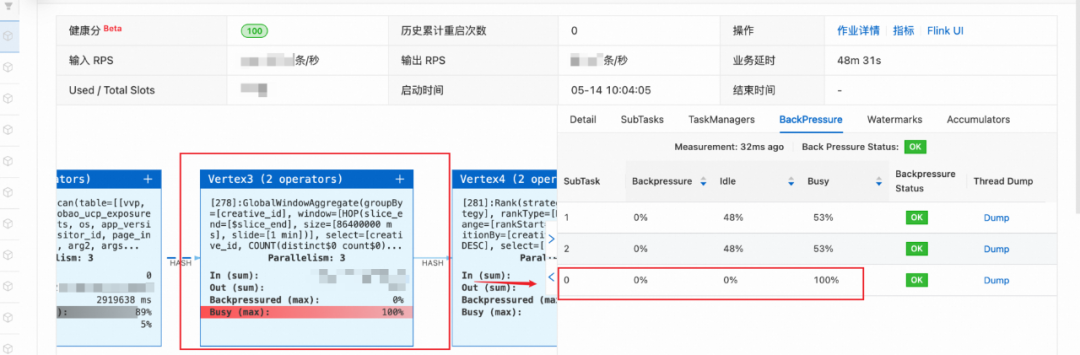
在上述flink程序运行的时候,该窗口聚合算子GlobalWindowAggregate出现长时间busy的情况,导致上游的算子出现反压,整个flink任务长时间延迟。
原因分析
一般面对反压的现象,首先要定位到出现拥堵的算子,在该case中,使用窗口聚合计算每个创意id对应的UV和PV时,出现了计算繁忙拥堵的情况。
针对这种情况,最常想到的就是以下两点原因:
数据量较大,但是设置的并发度过小(此任务中该算子的并发度设置为3)
单个slot的CPU和内存等计算资源不足
点击拥堵算子,并查看BackPressure,可以看到虽然并发度设置为3,但是出现拥堵的只有subtask0这一个并发子任务,因此基本上可以排出上述两种猜想,如果还是不放心,可以设置增加并行度至6,同时提高该算子上的slot的内存和CPU,结果如下:
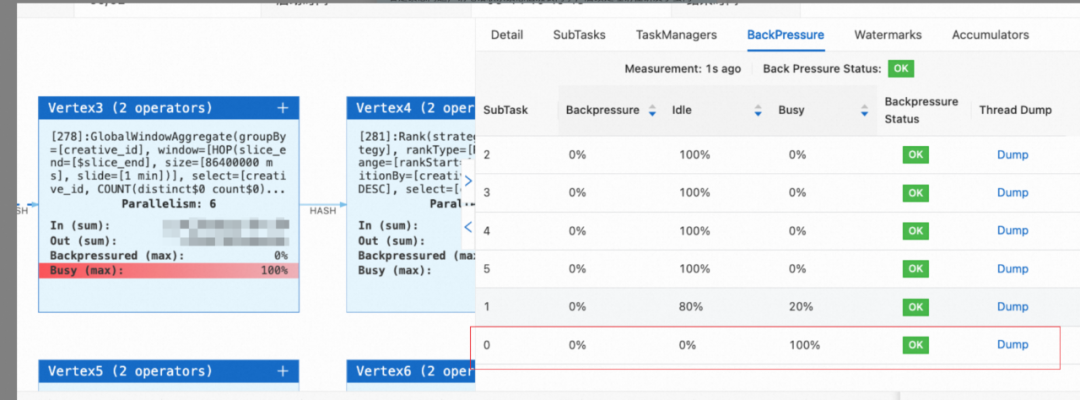
可以看到依然只有subtask0处于计算拥堵的状态,现在可以完全确认是由于group by时的key上的数据分布不均匀导致的数据倾斜问题。
▐ 解决方法
开启PartialFinal解决count distinct中的热点问题
-
实现:flink中提供了针对count distinct的自动打散和两阶段聚合,即PartialFinal优化。实现方法:在作业运维中增加如下参数设置:
table.optimizer.distinct-agg.split.enabled: true限制:这个参数适用于普通的GroupAggregate算子,对于WindowAggregate算子目前只适用于新的Window TVF(窗口表值函数),老的一套Tumble/Hop/Cumulate window是不支持的。
由于我们的代码中并没有使用到窗口表值函数,而是直接在group中使用了hop窗口,因此该方法不适用。
人工对不均匀的key进行打散并实现两阶段聚合
思路:增加按Distinct Key取模的打散层
实现:
第一阶段:对distinct的字段uid取hash值,并除以1024取模作为group by的key。此时的group by分组由于引入了user_id,因此分组变得均匀。
select
HOP_START(
ts
,interval '1' minute
,interval '24' hour
) as window_start
,HOP_END(
ts
,interval '1' minute
,interval '24' hour
) as window_end
,creative_id
,count(distinct uid) as exp_uv
,count(uid) as exp_pv
from dwd_expos_detail
group by
hop(
ts
,interval '1' minute
,interval '24' hour
)
,creative_id
,MOD(HASH_CODE(uid), 1024)-
第二阶段:对上述结果,再根据creative_id字段进行分组,并将UV和PV的值求和
select
window_start
,window_end
,creative_id
,sum(exp_uv) as exp_uv
,sum(exp_pv) as exp_pv
from (
select
HOP_START(
ts
,interval '1' minute
,interval '24' hour
) as window_start
,HOP_END(
ts
,interval '1' minute
,interval '24' hour
) as window_end
,creative_id
,count(distinct uid) as exp_uv
,count(uid) as exp_pv
from dwd_expos_detail
group by
hop(
ts
,interval '1' minute
,interval '24' hour
)
,creative_id
,MOD(HASH_CODE(uid), 1024)
)
group by
window_start
,window_end
,creative_id
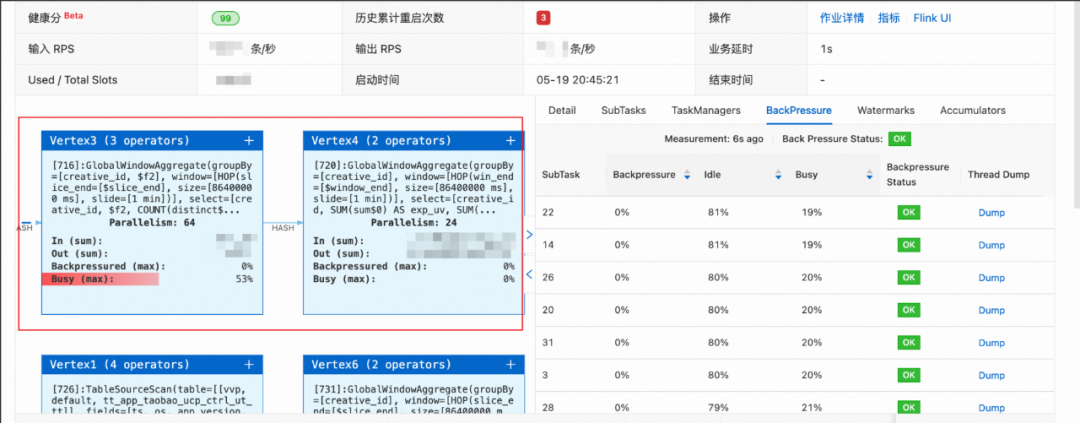
;效果:在拓扑图中可以看到原窗口聚合算子被分为两个独立的聚合算子,同时每个subtask的繁忙程度也都接近,不再出现不均匀的情况。
Case2: 水位线失效▐ 背景
需要先对两条实时流进行双流join,然后再对join后的结果使用hop滑动窗口,计算每个创意的汇总指标。
▐ 问题及原因
问题发现
开窗后长时间无数据产生。
原因分析
水位线对于窗口函数的实现起到了决定性的作用,它决定了窗口的触发时机,Window聚合目前支持Event Time和Processing Time两种时间属性定义窗口。最常用的就是在源表的event_time字段上定义水位线,系统会根据数据的Event Time生成的Watermark来进行关窗。只有当Watermark大于关窗时间,才会触发窗口的结束,窗口结束才会输出结果。如果一直没有触发窗口结束的数据流入Flink,则该窗口就无法输出数据。
限制:数据经过GroupBy、双流JOIN或OVER窗口节点后,会导致Watermark属性丢失,无法再使用Event Time进行开窗。
由于我们在代码中首先使用了interval join来处理点击流和交易流,然后在对生成的数据进行开窗,导致水位线丢失,窗口函数无法被触发。
▐ 解决方法
思路1: 既然双流join之后的时间字段丢失了水位线属性,可以考虑再给join之后的结果再加上一个processing time的时间字段,然后使用该字段进行开窗。
缺点:该字段无法真正体现数据的时间属性,只是机器处理该条数据的时间戳,因此会导致窗口聚合时的结果不准确,不推荐使用。
思路2: 新建tt流
要开窗就必须有水位线,而水位线往往会在上述提及的聚合或者双流join加工中丢失,因此考虑新建一个flink任务专门用来进行双流join,过滤出符合条件的用户交易明细流,并写入到tt,然后再消费该tt,并对tt流中的event_time字段定义watermark水位线,并直接将数据用于hop滑动窗口。
实现:
步骤1:新建flink任务,通过interval join筛选出近六个小时内有过点击记录的用户交易明细,并sink到tt
insert into sink_dwd_pop_pay_detail_ri
select
p1.uid
,p1.order_id
,p1.order_amount
,p1.ts
,p2.creative_id
from (
select
uid
,order_amount
,order_id
,ts
from dwd_trade_detail
) p1
join dwd_clk_uv_detail p2
on p2.ts between p1.ts - interval '6' hour and p1.ts
and p1.uid = p2.uid
;-
步骤2: 消费该加工后的交易流,并直接进行滑动窗口聚合
select
HOP_START(
ts
,INTERVAL '1' minute
,INTERVAL '24' hour
) as window_start
,HOP_END(
ts
,INTERVAL '1' minute
,INTERVAL '24' hour
) as window_end
,creative_id
,sum(order_amount) as total_gmv
,count(distinct uid) as cnt_order_uv
,round(
sum(order_amount) / count(distinct uid) / 1.0
,2
) as gmv_per_uv
from source_dwd_pop_pay_detail_ri
GROUP BY
HOP(
ts
,INTERVAL '1' minute
,INTERVAL '24' hour
)
,creative_id
;Case3: group by失效▐ 背景
目的:对于实时流,需要给素材打上是否通过的标签。
打标逻辑:如果素材id同时出现在lastValidPlanInfo和validPlanInfo的两个数组字段中,则认为该素材通过(is_filtered=0),如果素材id只出现在lastValidPlanInfo数组字段中,则认为该素材未通过(is_filtered= 1)。
sink表类型:odps/sls,不支持回撤和主键更新机制。
上述逻辑的实现sql如下:
SELECT
`user_id`
,trace_id
,`timestamp`
,material_id
,min(is_filtered)) as is_filtered -- 最后group by聚合,每个素材得到唯一的标签
FROM (
SELECT
`user_id`
,trace_id
,`timestamp`
,material_id
,1 as is_filtered -- lastValidPlanInfo字段中出现的素材都打上1的被过滤标签
FROM dwd_log_parsing
,lateral table(string_split(lastValidPlanInfo, ';')) as t1(material_id)
WHERE lastValidPlanInfo IS NOT NULL
UNION ALL
SELECT
`user_id`
,trace_id
,`timestamp`
,material_id
,0 as is_filtered -- validPlanInfo字段中出现的素材都打上0的被过滤标签
FROM dwd_log_parsing
,lateral table(string_split(validPlanInfo, ';')) as t2(material_id)
WHERE validPlanInfo IS NOT NULL
)
GROUP BY
`user_id`
,trace_id
,`timestamp`
,material_id▐ 问题及原因
问题发现
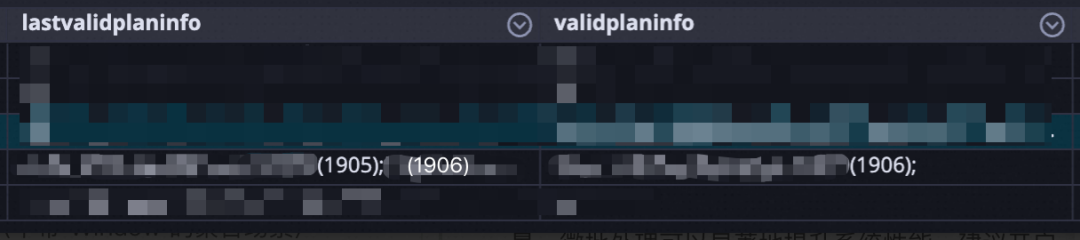
原始数据样例:根据下图可以发现1905和1906两个素材id出现在lastValidPlanInfo中,只有1906这个id出现在validPlanInfo字段中,说明1905被过滤掉了,1906通过了。
期望的计算结果应该是:
material_id | is_filtered |
1905 | 1 |
1906 | 0 |
但是最终写入到odps的结果如下图,可以发现material_id为1906出现了两条结果,且不一致,所以我们不禁产生了一个疑问:是fink中的group by失效了吗?
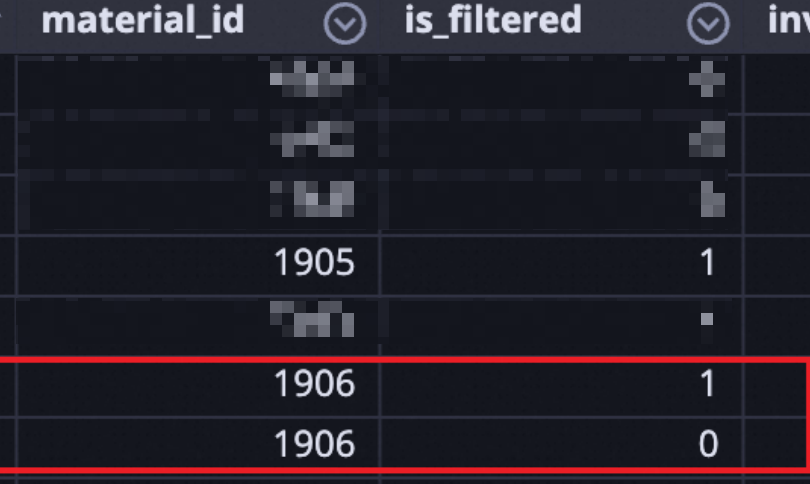
原因分析
由于odps sink表不支持回撤和upsert主键更新机制,因此对于每一条源表的流数据,只要进入到operator算子并产生结果,就会直接将该条结果写入到odps。
union all和lateral table的使用都会把一条流数据拆分为多条流数据。上述代码中首先使用到了lateral table将lastValidPlanInfo和validPlanInfo数组字段中的material_id数字拆分为多条material_id,然后再使用union all+group by实现过滤打标功能,这些操作早已经将原tt流中的一条流数据拆分成了多条。
综合上述两点,
针对1906的素材id,由于lateral table的使用,使得其和1905成为了两条独立的流数据;
由于union all的使用,又将其拆分为is_filtered =1的一条流数据(union all的前半部分),和is_filtered=0的一条流数据(union all的后半部分);
由于flink一次只能处理一条流数据,因此如果先处理了素材1906的is_filtered=1的流数据,经过group by和min(is_filtered)操作,将is_filtered= 1的结果先写入到odps,然后再处理is_filtered=1的流数据,经过group by和min(is_filtered)操作,状态更新is_filtered的最小值变更为0,又将该条结果写入到odps。
由于odps不支持回撤和主键更新,因此会存在两条素材1906的数据,且结果不一致。
▐ 解决方法
思路:既然lateral table和union all的使用,会把一条流数据变为多条,并引发了后续的多次写入的问题。因此我们考虑让这些衍生出的多条流数据可以一次性进入到group by中参与聚合计算,最终只输出1条结果。
实现:mini-batch微批处理
table.exec.mini-batch.enabled: true
table.exec.mini-batch.allow-latency: 1s概念:mini-batch是缓存一定的数据后再触发处理,以减少对State的访问,从而提升吞吐并减少数据的输出量。微批处理通过增加延迟换取高吞吐,如果您有超低延迟的要求,不建议开启微批处理。通常对于聚合场景,微批处理可以显著地提升系统性能,建议开启。
效果:上述问题得到解决,odps表只输出每个用户的每次请求的每个素材id只有1条数据输出。

总结
FlinkSQL的开发是最方便高效的实时数据需求的实现途径,但是它和离线的ODPS SQL开发在底层的机制和原理上还是有很大的区别,根本的区别就在于流和批的处理。如果按照我们已经习惯的离线思维来写FlinkSQL,就可能会出现一些“离奇”的结果,但是遇到问题并不可怕,要始终相信根本不存在任何“离奇”,所有的问题都是可以追溯到原因的,而在这个探索的过程中,也可以学习到许多知识,所以让我们遇到更多的问题,积累更多的经验,熟练地应用Flink。

参考资料
窗口:
https://help.aliyun.com/zh/flink/developer-reference/overview-4?spm=a2c4g.11186623.0.i33
高性能优化:
https://help.aliyun.com/zh/flink/user-guide/optimize-flink-sql

团队介绍
淘天业务技术用户运营平台技术团队是一支懂用户,技术驱动的年轻队伍,以用户为中心,通过技术创新提升用户全生命周期体验,持续为用户创造价值。
团队立足体系化打造业界领先的用户增长基础设施,以媒体外投平台、ABTest平台、用户运营平台为代表的基础设施赋能阿里集团用户增长,日均处理数据量千亿规模、调用QPS千万级。
¤ 拓展阅读 ¤