检索增强生成(RAG)为大语言模型(LLMs)提供了从数据源检索的信息,以此为基础生成回答。简而言之,RAG结合了搜索技术和大语言模型的提示功能,即模型根据搜索算法找到的信息作为上下文来回答查询问题。无论是查询还是检索的上下文,都会被整合到发给大语言模型的提示中。
- 向量Embedding:相当于数据的坐标,向量分数越高,代表坐标位置越接近,匹配的数据越相似
- 向量数据库EmbeddingStore:支持20多种实现,包括内存、redis、mongo、es等
向量模型简单使用
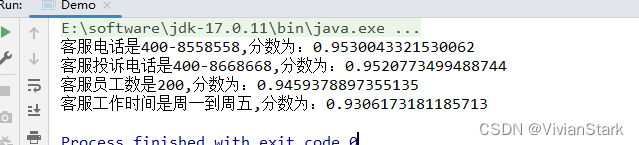
从执行结果看似乎分数差别不大,但是要注意小数点后位数很多,也就是这个分数精度是比较高的,所以两个分数还是有一定距离的。
public static void main(String[] args) throws Exception {
// openAi的向量模型
OpenAiEmbeddingModel embeddingModel = OpenAiEmbeddingModel.builder()
.baseUrl(OPEN_AI_BASE_URL)
.apiKey(OPEN_AI_API_KEY)
.build();
// InMemoryEmbeddingStore向量存储(内存存储)
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
TextSegment textSegment1 = TextSegment.textSegment("客服电话是400-8558558");
TextSegment textSegment2 = TextSegment.textSegment("客服工作时间是周一到周五");
TextSegment textSegment3 = TextSegment.textSegment("客服投诉电话是400-8668668");
TextSegment textSegment4 = TextSegment.textSegment("客服员工数是200");
// 生成向量数据
Response<Embedding> embed1 = embeddingModel.embed(textSegment1);
Response<Embedding> embed2 = embeddingModel.embed(textSegment2);
Response<Embedding> embed3 = embeddingModel.embed(textSegment3);
Response<Embedding> embed4 = embeddingModel.embed(textSegment4);
// 存储向量
embeddingStore.add(embed1.content(), textSegment1);
embeddingStore.add(embed2.content(), textSegment2);
embeddingStore.add(embed3.content(), textSegment3);
embeddingStore.add(embed4.content(), textSegment4);
// 生成向量
Response<Embedding> embed = embeddingModel.embed("客服电话多少");
//查询
List<EmbeddingMatch<TextSegment>> result = embeddingStore.findRelevant(embed.content(), 4);
for (EmbeddingMatch<TextSegment> embeddingMatch : result) {
System.out.println(embeddingMatch.embedded().text() + ",分数为:" + embeddingMatch.score());
}
}
RAG场景使用
模型一个人工智能助手,根据问答模板内容,回答客户问题。
// 定义一个智能助手,用来回答问题
public interface AiAgent {
// 用来回答问题
String answer(String question);
// 利用AiServices创建一个AiAgent的代理对象
static AiAgent create(ContentRetriever contentRetriever) {
// 创建模型
ChatLanguageModel model = OpenAiChatModel.builder().apiKey(OPEN_AI_API_KEY).baseUrl(OPEN_AI_BASE_URL).build();
// 敏感词检测模型
ModerationModel moderationModel = OpenAiModerationModel.builder().baseUrl(OPEN_AI_BASE_URL).apiKey(OPEN_AI_API_KEY).build();
// 指定模型,创建并返回代理对象
return AiServices.builder(AiAgent.class)
.chatLanguageModel(model) // 大模型
.chatMemory(MessageWindowChatMemory.withMaxMessages(10)) // 对话内存
.contentRetriever(contentRetriever) // 内容检索条件
.tools(new ToolUtil()) // 工具
.moderationModel(moderationModel)
.build();
}
}
// 文本分割器
public class CustomerServiceDocumentSplitter implements DocumentSplitter {
@Override
public List<TextSegment> split(Document document) {
List<TextSegment> segments = new ArrayList<>();
String[] parts = document.text().split("\\s*\\R\\s*\\R\\s*");
for (String part : parts) {
segments.add(TextSegment.from(part));
}
return segments;
}
}
// 使用
public static void main(String[] args) {
// 导入文本数据
Document document = getDocument();
DocumentSplitter splitter = new CustomerServiceDocumentSplitter();
// 对数据进行切分
List<TextSegment> segments = splitter.split(document);
// 定义向量模型
EmbeddingModel embeddingModel = OpenAiEmbeddingModel.builder()
.apiKey(OPEN_AI_API_KEY)
.baseUrl(OPEN_AI_BASE_URL)
.build();
// 根据向量模型获取向量数据
List<Embedding> embeddings = embeddingModel.embedAll(segments).content();
// 向量数据存储到InMemoryEmbeddingStore内存中
EmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
embeddingStore.addAll(embeddings, segments);
// 组装ContentRetriever 用于查询
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(3) // 最相似的3个结果
.minScore(0.9) // 只找相似度在0.9以上的内容
.build();
// 创建
AiAgent aiAgent = AiAgent.create(contentRetriever);
// 使用
String result = aiAgent.answer("今天的余额提现,最晚哪天能到账?给我具体的日期");
System.out.println(result);
}
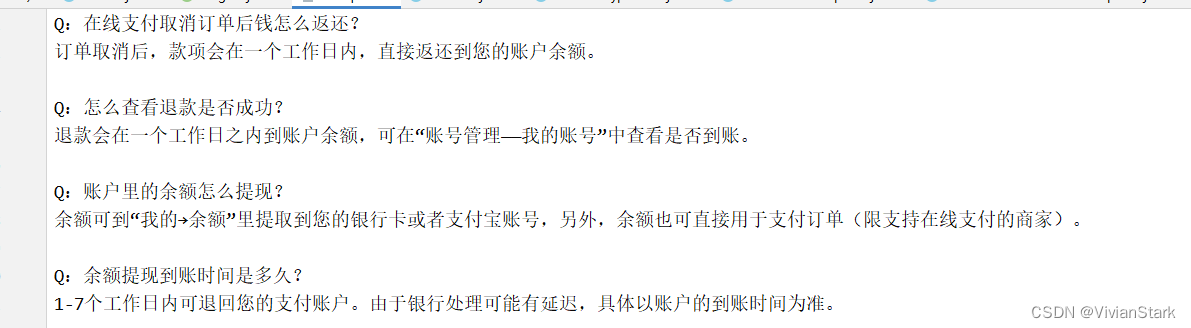
问答模版
执行结果