通用块层的核心数据结构称为bio描述符,它描述了块设备的io操作。每一个bio结构都包含一个磁盘存储区标识符(存储区中的起始扇区号和扇区数目)和一个或多个描述与IO操作相关的内存区段(bio_vec数组)
bio结构中的字段
/*
* main unit of I/O for the block layer and lower layers (ie drivers and
* stacking drivers)
*/
struct bio {
struct bio *bi_next; /* request queue link 链接到请求队列中的下一个bio*/
struct block_device *bi_bdev; /* 指向块设备描述符的指针 */
unsigned int bi_flags; /* status, command, etc bio的状态标志*/
int bi_error;
unsigned long bi_rw; /* bottom bits READ/WRITE, I/O操作标志(低位是读写位,高位是优先级)
* top bits priority
*/
struct bvec_iter bi_iter;
/* Number of segments in this BIO after
* physical address coalescing is performed.
*/
unsigned int bi_phys_segments; //合并之后bio中物理段的数目
/*
* To keep track of the max segment size, we account for the
* sizes of the first and last mergeable segments in this bio.
*/
unsigned int bi_seg_front_size;
unsigned int bi_seg_back_size;
atomic_t __bi_remaining;
bio_end_io_t *bi_end_io; //bio的I/O操作结束时调用的方法
void *bi_private; //通用块层和块设备驱动程序的I/O完成方法使用的指针
#ifdef CONFIG_BLK_CGROUP
/*
* Optional ioc and css associated with this bio. Put on bio
* release. Read comment on top of bio_associate_current().
*/
struct io_context *bi_ioc;
struct cgroup_subsys_state *bi_css;
#endif
union {
#if defined(CONFIG_BLK_DEV_INTEGRITY)
struct bio_integrity_payload *bi_integrity; /* data integrity */
#endif
};
unsigned short bi_vcnt; /* how many bio_vec's bio的引用计数器*/
/*
* Everything starting with bi_max_vecs will be preserved by bio_reset()
*/
unsigned short bi_max_vecs; /* max bvl_vecs we can hold bio_vec数组中允许的最大段数*/
atomic_t __bi_cnt; /* pin count */
struct bio_vec *bi_io_vec; /* the actual vec list 存放段的数组*/
struct bio_set *bi_pool; //备用的bio内存池
/*
为了避免重复申请少量的bio_vec,使用内联一定数量的bio_vec数组,将它放在bio结构的尾部。
* We can inline a number of vecs at the end of the bio, to avoid
* double allocations for a small number of bio_vecs. This member
* MUST obviously be kept at the very end of the bio.
*/
struct bio_vec bi_inline_vecs[0]; /*一般一个bio就一个段,bi_inline_vecs就
可满足,省去了再为bi_io_vec分配空间*/
};
bio中的每个段是由一个bio_vec数据结构描述的,bio_vec数据结构如下
//bio段就是描述所要读或写的数据在内存中位置
struct bio_vec{
struct page* bv_page //指向段在页框描述符的指针
unsigned int bv_len //段的字节长度
unsigned int bv_offset //页框中数据的偏移量
}
bio中的bi_io_vec字段指向bio_vec数组的第一个元素,bi_vcnt则说明了数组当前元素的个数,而bi_max_vecs则限定了数组的长度。
下面两幅图可以很好的说明bio与bio_vec的关系
在通用块层启动一次新的IO操作时,会调用bio_alloc函数分配一个新的bio结构,bio是由slab分配器分配的。内核同时也为bio_vec结构分配内存池。
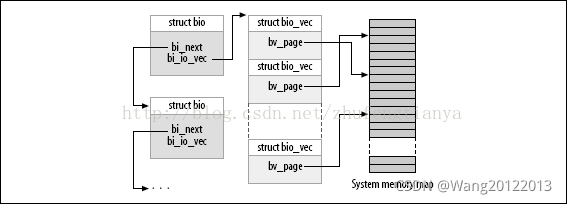
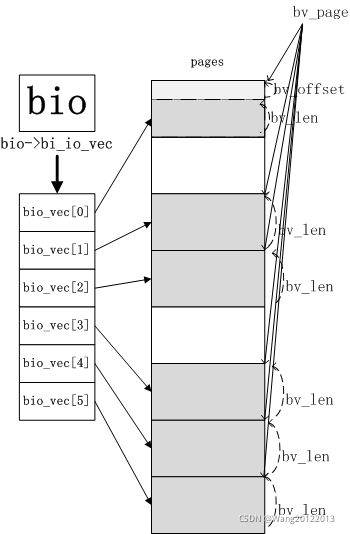
参考:https://blog.csdn.net/zhufengtianya/article/details/42145985?utm_source=copy
bio与bio段的关系
一个bio可能有很多个bio段,这些bio段可能在内存上不连续(位于不同的页),但他们在磁盘上对应的位置是连续的。一般上层构建bio的时候都是只有一个bio段,可以参考_submit_bh函数。
在块io操作期间bio的内容一直保持更新,例如,块设备驱动在一次分散聚集DMA操作中不能一次完成全部数据的传送,那么bio的bi_idx就会更新来指向待传送的第一个段。
bio,request,request_queue的学习
bio:代表了一个io请求
request:一个request中包含了一个或多个bio,为什么要有request这个结构呢?它存在的目的就是为了进行io的调度。通过request这个辅助结构,我们来给bio进行某种调度方法的排序,从而最大化地提高磁盘访问速度。
request_queue:每个磁盘对应一个request_queue.该队列挂的就是request请求。
具体如下图:(有颜色方框头表示数据结构的名字)
请求到达block层后,通过generic_make_request这个入口函数,在通过调用一系列相关的函数(具体参见我另一篇博客)把bio变成了request。具体的做法如下:如果几个bio要读写的区域是连续的,即积攒成一个request(一个request上挂多个连续的bio,就是我们通常说的“合并bio请求”),如果一个bio跟其他的bio都连不上,那它就自己创建一个新的request,把自己挂在这个request下。当然,合并bio的个数也是有限的,这个可以通过配置文件配置。
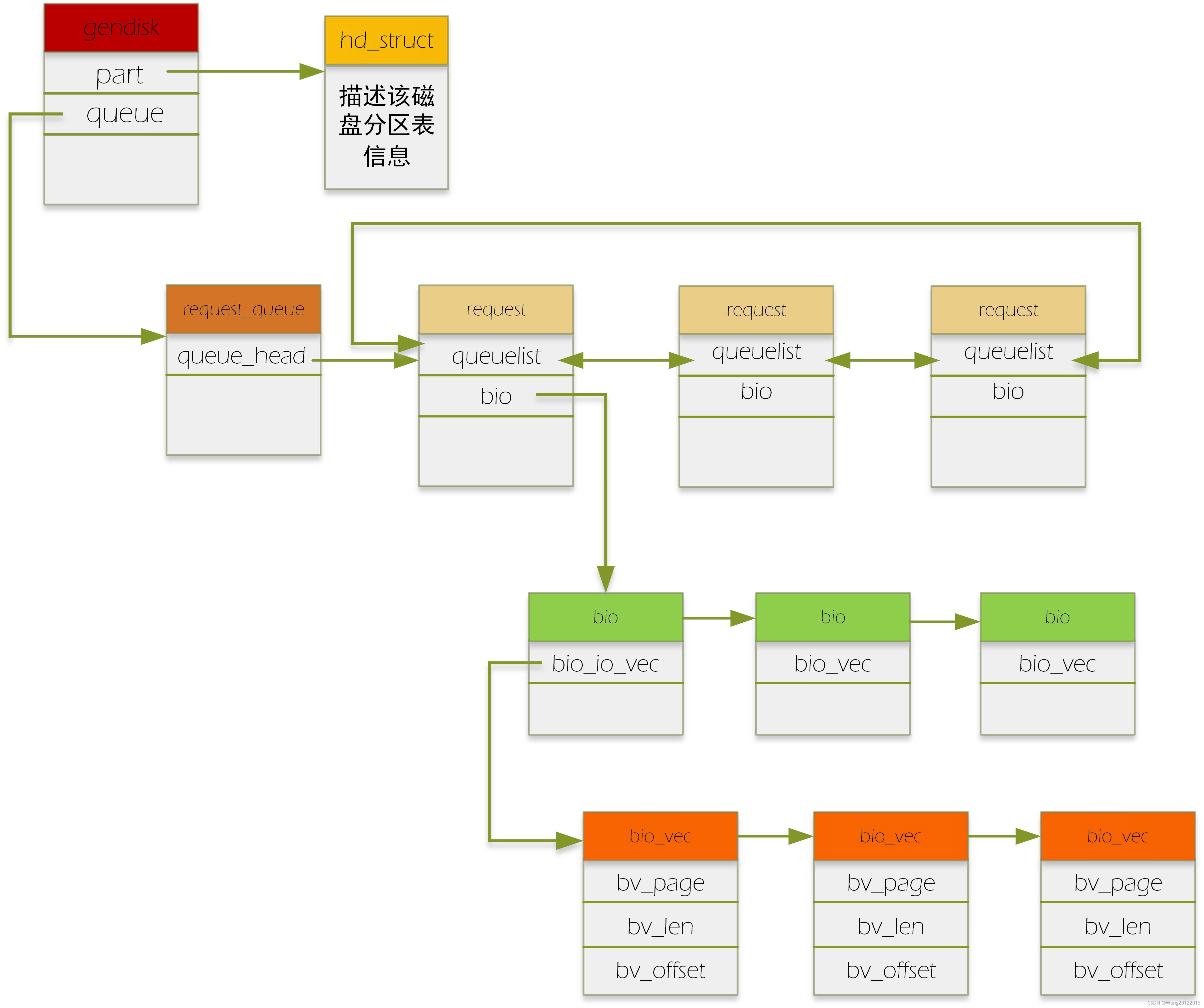
对于上段补充一点:上层的一次请求可能跨越了多个扇区,形成不连续的扇区段,那么该请求构造的每个bio对应着一个连续的扇区段。故一个请求可以构造出多个bio。
合并后的request放入每个设备对应的request_queue中。之后设备驱动调用peek_request从request_queue中取出request,进行下一步处理。
这里要注意的是,在实现设备驱动时,厂家可以直接从request_queue中拿出排队好的request,也可以实现自己的bio排队方法,即实现自己的make_request_fn方法,即直接拿文件系统传来的bio来自己进行排队,按需设计,想怎么排就怎么排,像ramdisk,还有很多SSD设备的firmware就是自己排。(这里就和我另一篇博客,说到为什么generic_make_request要设计成一层递归调用联系起来)。
网上有个问答也是我的疑惑:这里我写一遍,加强记忆
bio结构中有bio_vec数组结构,该结构的的数组可以指向不同的page单元,那为什么不在bio这一级就做了bio合并工作,即把多个bio合并成一个bio,何必加入一个request这么麻烦?
答:每个bio有自己的end_bio回调,一旦一个bio结束,就会对自己进行收尾工作,如果合并了,或许有些bio会耽误,灵活性差。