python多线程和多进程的实现
一、python多线程
1、python单线程
import time
def say_hello():
print("今天又是美好的一天")
time.sleep(1)
for i in range(5):
say_hello()
2、 python 多线程的第一种实现方式
import threading
import time
def say_hello():
print("今天又是美好的一天")
time.sleep(1)
for i in range(5):
t = threading.Thread(target=say_hello)
t.start() # 启动线程,即让线程开始执行
3、python单线程和python多线程的区别
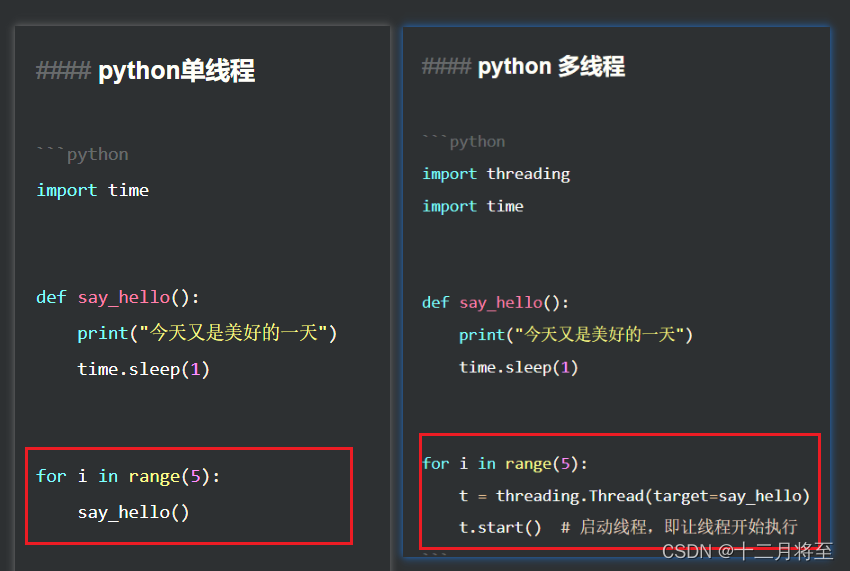
- 查看不同,就可以看出,多线程的创造就是使用了threading.Tread()这个模块,target=say_hello .是内部的参数。target翻译成中文是目标的意思。 say_hello这个函数名就是目标。 把这个函数名传入到target里面,每次调用 t = threading.Thread(target=say_hello),就是创建了一个新的线程。 然后 通过start来启动,这样就实现了多线程。 上面一共循环5次,就是创建了5个线程. 加上主线程,就是6个线程。可以先猜一下上面左右两个程序运行的现象。
- 要注意的一点是,say_hello中的time.sleep,是阻碍当前的线程,即当前循环产生的线程。不能阻碍下一次循环产生的新线程,所以右边的程序,可以很快打印出 ‘今天又是美好的一天’,左边的程序,因为是单线程,所以每隔一秒,打印出今天又是美好的一天。类比一下,单线程是一个人说了5次, 多线程是一个人找了5个人,然后5个人都说了一次。
4、多线程传参 的方式
之前的多线程实现方式,就是把函数名传入到线程模块里(target=),从而会新生成的一个线程来运行。但是一个函数运行,经常是需要给函数传入参数的。这个在线程模块里,是通过args这个参数来传入的,查看源码可以看到注释
注意一下,target 是会被一个run()的方法调用的
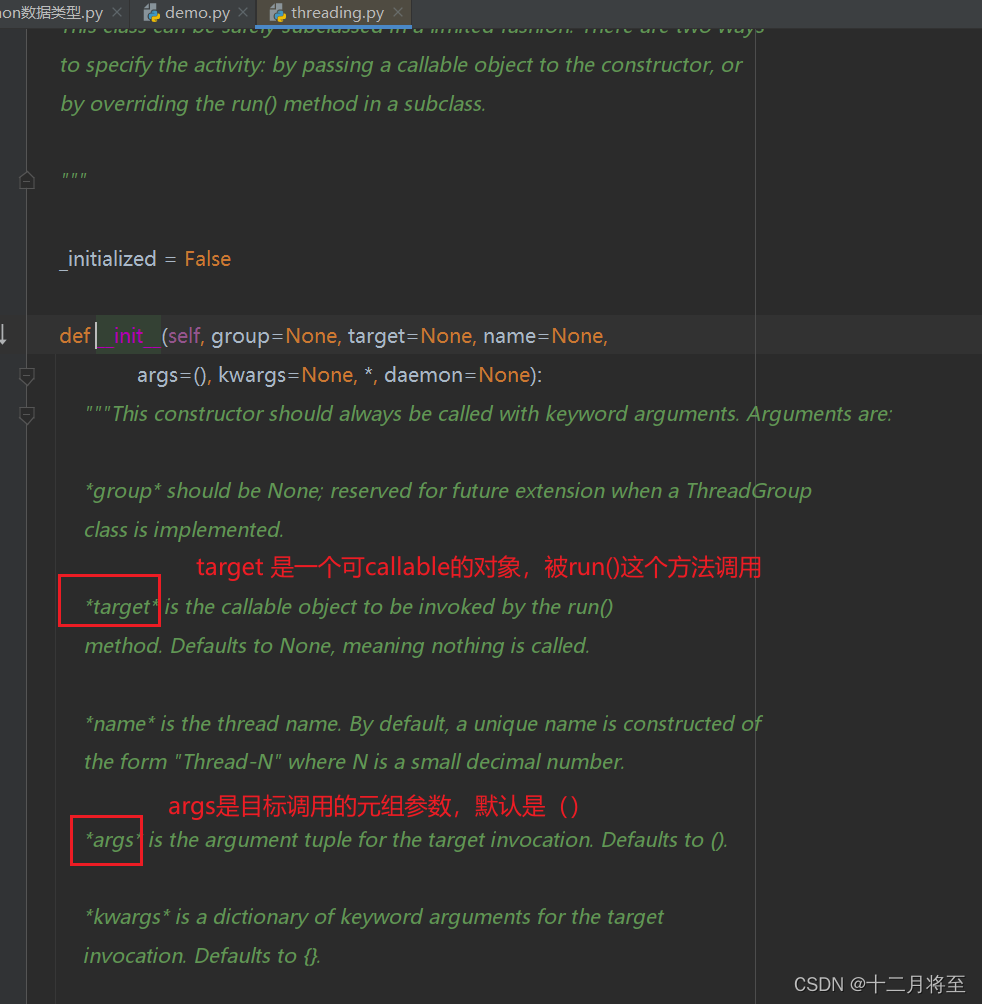
如下面程序展示的,就是把args这个元组里的10传入t1里面的work1函数,20传入t2里面的work2。
from threading import Thread
import time
def work1(nums):
print("----in work1--nums=%d-" % nums)
def work2(nums):
print("----in work2--nums=%d-" % nums)
t1 = Thread(target=work1, args=(10,))
t1.start()
t2 = Thread(target=work2, args=(20,))
t2.start()
如果传如多个参数,就是
from threading import Thread
import time
def work1(num1, num2):
print("----in work1--num1=%d,num2=%d-" % (num1, num2))
def work2(num1, num2, num3):
print("----in work1--num1=%d,num2=%d,num3=%d-" % (num1, num2, num3))
t1 = Thread(target=work1, args=(11, 22))
t1.start()
t2 = Thread(target=work2, args=(33, 44, 55))
t2.start()
之前都是args逐个分配,顺序给到num1和num2,但是如果指定给num2这个值给22,这种怎么操作呢,如下所示。参数有三个,专门给num2这个值给22,m给100,就要用到字典的方式,key是给的变量的名字,value是给的变量的值
from threading import Thread
def work1(num1, num2, m):
print("----in work1--num1=%d,num2=%d,m=%d-" % (num1, num2, m))
def work2(num1, num2, num3, n):
print("----in work1--num1=%d,num2=%d,num3=%d,n=%d-" % (num1, num2, num3, n))
t1 = Thread(target=work1, args=(11,), kwargs={"m": 100, "num2": 22})
t1.start()
t2 = Thread(target=work2, args=(33, 44, 55), kwargs={"n": 200})
t2.start()
总结:在使用Thread创建线程的时候,args是传递一个元组,元组中的数据个数与target指定的函数形参个数、顺序一直,kwargs是一个字典 里面的key当做形参中的变量名字,value是给这个形参传递的数值,先用args的赋值顺序的,后用字典赋值,不用考虑到顺序。
5、多线程实现的第二种方式
上面的实现方式是使用threading.Thread()创建一个对象,并且在使用target来指定一个函数,作为线程要执行的代码。
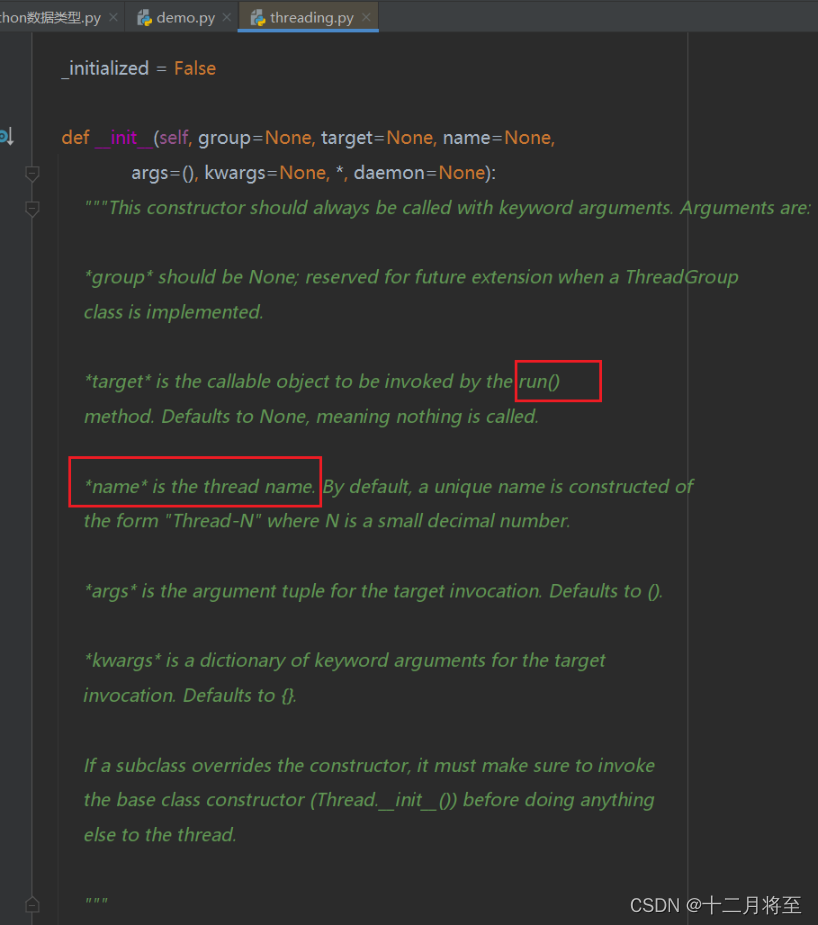
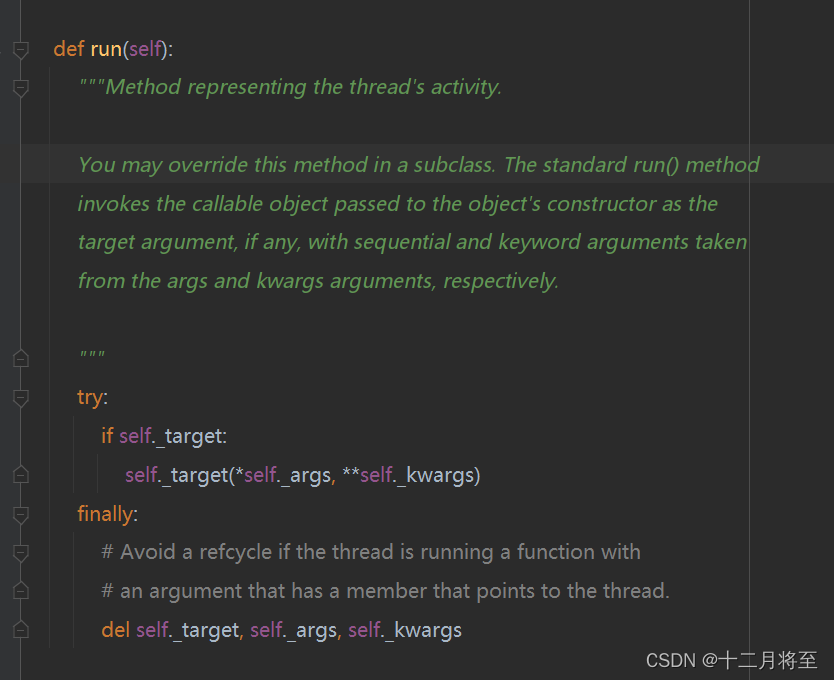
可以看出,target保存的目标函数,是通过run()这个方法实现的,另一种实现方式,就是通过继承thread这个模块,然后重写run()这个方法。name也就是线程的名字。
封装性更好的一种创建线程的方式是:
import threading
import time
class MyThread(threading.Thread):
def run(self):
for i in range(3):
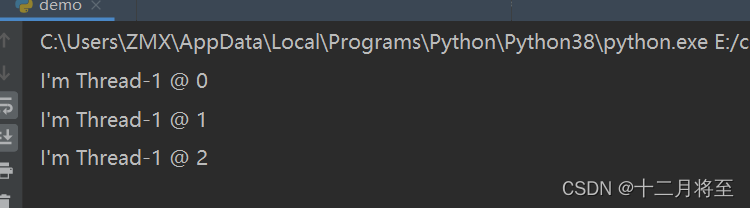
msg = "I'm "+ self.name + ' @ '+str(i) # name属性中保存的是当前线程的名字
print(msg)
time.sleep(1)
if __name__ == '__main__':
t = MyThread()
t.start()
当线程启动时,它会执行run方法。
run方法里有一个循环,循环三次。
在每次循环中,它创建一个消息字符串msg,该字符串包含当前线程的名字(通过self.name获取)和循环的当前迭代次数i。
然后,它打印这条消息。
接着,线程暂停(休眠)1秒。
在if name == ‘main’:部分,代码创建了MyThread类的一个实例 t,并调用start方法启动这个线程。一旦线程启动,它就会执行run方法中的代码。
所以,当你运行这段代码时,你会看到如下输出(线程名字可能会有所不同,因为它是由Python自动分配的):
总结下通用实现的步骤
1、 定义一个新的类,继承Thread类
2、 在这个类中实现run方法
3、在run方法中写如要执行的代码
4、当使用这个类创建一个对象后,调用对象的start方法就可以让这个线程执行,且会自动执行run方法的代码
结论:
1、 每个线程默认有一个名字,尽管上面的例子中没有指定线程对象的name,但是python会自动为线程指定一个名字。
2、当线程的run()方法结束时表示该线程结束
3、既然run方法是个示例方法,那么也就意味着可以调用本类中的其它实例方法,从而能够编写出较为复杂的功能
二、python多进程
1、多进程实现的方法一
线程是threading.Thread(target=函数名) 这种实现多线程,
进程是通过multiprocessing.Process(target=函数名) 来实现多进程
- 如下面程序
from multiprocessing import Process
import time
def test():
"""子进程单独执行的代码"""
while True:
print('---test---')
time.sleep(1)
if __name__ == '__main__':
p=Process(target=test)
p.start()
# 主进程单独执行的代码
while True:
print('---main---')
time.sleep(1)
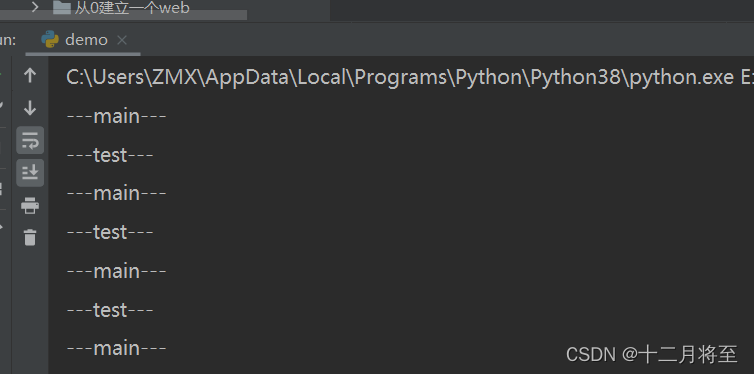
当运行这段代码时,你会看到—test—和—main—交替打印出来,每个消息之间间隔1秒。这是因为子进程和主进程是并发执行的,它们会几乎同时打印出各自的消息。
需要注意的是,由于并发执行的特性,你有时可能会看到—test—和—main—的打印顺序不是完全交替的,但这并不影响两个进程各自的行为。
另外,由于这两个进程都是无限循环,所以这个程序将一直运行下去,除非你手动停止它。在实际应用中,你可能需要添加一些条件来优雅地终止这些进程。
小结:
- 1、 通过额外创建一个进程,可以实现多任务
2、使用进程实现多任务的流程:
3、创建一个Process对象,且在创建时通过target指定一个函数的引用
4、当调用start时,会真正的创建一个子进程
常用进程的方法
start():启动子进程实例(创建子进程)
is_alive():判断子进程是否还在活着
join([timeout]):是否等待子进程执行结束,或等待多少秒
terminate():不管任务是否完成,立即终止子进程用
2、多进程实现的方法二
1、参考多线程的类实现
import threading
class Task(threading.Thread):
def run(self):
"""子线程要执行的代码"""
pass
t = Task()
t.start()
2、多进程通过类实现如下
也是类继承 Process后,重写run ,然后通过start方法来调用
from multiprocessing import Process
import time
class MyNewProcess(Process):
def run(self):
while True:
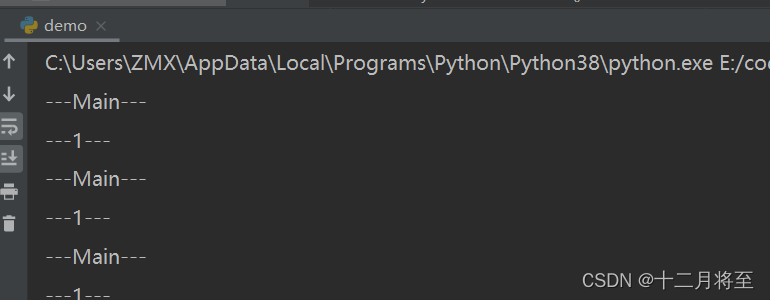
print('---1---')
time.sleep(1)
if __name__=='__main__':
p = MyNewProcess()
# 调用p.start()方法,p会先去父类中寻找start(),然后在Process的start方法中调用run方法
p.start()
while True:
print('---Main---')
time.sleep(1)
3、 多进程实现小结:
1、创建多进程的流程
- 自定义一个类,继承Process类
- 实现run方法
- 通过自定义的类,创建实例对象
- 调用实例对象的start方法
2、对比
- 自定义继承Process类的方式比 直接创建Process对象 要稍微复杂一些,但是可以用来实现更多较为复杂逻辑的功能
3、建议
- 如果想快速的实现一个进程,功能较为简单的话,可以直接创建Process的实例对象
- 如果想实现一个功能较为完整、逻辑较为复杂的进程,可以自定义继承Process类 来实现
3、多进程传递参数
和多线程的实现一样,也是通过
Process(target=run_proc, args=(‘test’,18), kwargs={“m”:20})这种,用 args(元组)和kwargs(字典)来实现的。
如下
from multiprocessing import Process
import os
from time import sleep
def run_proc(name, age, **kwargs):
for i in range(10):
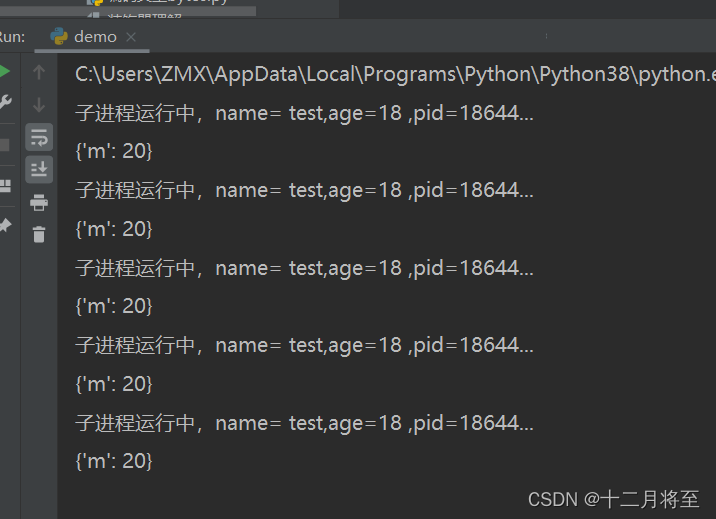
print('子进程运行中,name= %s,age=%d ,pid=%d...' % (name, age, os.getpid()))
print(kwargs)
sleep(0.2)
if __name__=='__main__':
p = Process(target=run_proc, args=('test',18), kwargs={"m":20})
p.start()
sleep(1) # 1秒中之后,立即结束子进程
p.terminate() # 作用是尝试终止子进程。注意,这并不一定意味着子进程会立即停止。它只是发送一个终止信号给子进程,子进程需要在适当的时候响应这个信号
p.join()
子进程要执行的代码是run_proc这个函数:
-
1、 run_proc 这个函数是子进程要执行的代码。
-
2、 它接受三个参数:name、age和**kwargs。其中name和age是位置参数,**kwargs是关键字参数,允许传递任意数量的关键字参数。
-
3、在函数内部,它有一个循环,循环10次。每次循环中,它打印当前子进程的名称、年龄和进程ID,以及所有传入的关键字参数。
-
4、然后,它让子进程休眠0.2秒。
主进程要执行的代码里,主程序的入口是这样的
-
1、使用Process类创建一个子进程对象p。
-
2、target=run_proc:指定子进程要执行的函数。
-
3、args=(‘test’, 18):传递给run_proc函数的位置参数。依次传给name 和age
-
4、kwargs={“m”: 20}:传递给run_proc函数的关键字参数。
-
5、p.start():启动子进程。
-
6、sleep(1):主进程休眠1秒。
-
7、p.terminate():尝试终止子进程。注意,这并不一定意味着子进程会立即停止。它只是发送一个终止信号给子进程,子进程需要在适当的时候响应这个信号。
-
8、p.join():主进程等待子进程结束。这里需要注意的是,即使调用了p.terminate(),p.join()仍然会等待子进程真正结束,因为p.terminate()不是一下子结束子进程。
三、python多进程 和多线程之间的注意点
1、多线程之间共享全局变量,多进程之间不共享全局变量
- 多线程之间是共享的
import threading
import time
nums = []
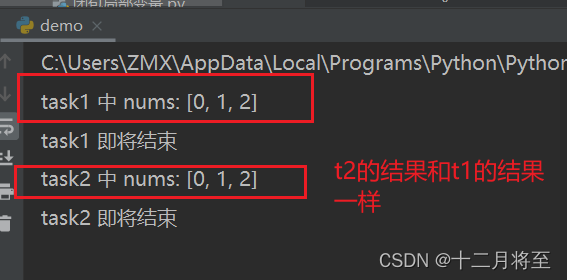
def task1():
for i in range(3):
nums.append(i)
print("task1 中 nums:", nums)
print("task1 即将结束")
def task2():
print("task2 中 nums:", nums)
print("task2 即将结束")
t1 = threading.Thread(target=task1)
t2 = threading.Thread(target=task2)
t1.start()
time.sleep(2)
t2.start()
2、多进程之间变量是不共享的
from multiprocessing import Process
import os
import time
nums = [11, 22]
def work1():
"""子进程要执行的代码"""
print("111111in process1 pid=%d ,nums=%s" % (os.getpid(), nums))
for i in range(3):
nums.append(i)
time.sleep(1)
print("222222in process1 pid=%d ,nums=%s" % (os.getpid(), nums))
def work2():
"""子进程要执行的代码"""
print("333333in process2 pid=%d ,nums=%s" % (os.getpid(), nums))
if __name__ == '__main__':
p1 = Process(target=work1)
p1.start()
time.sleep(2)
p2 = Process(target=work2)
p2.start()
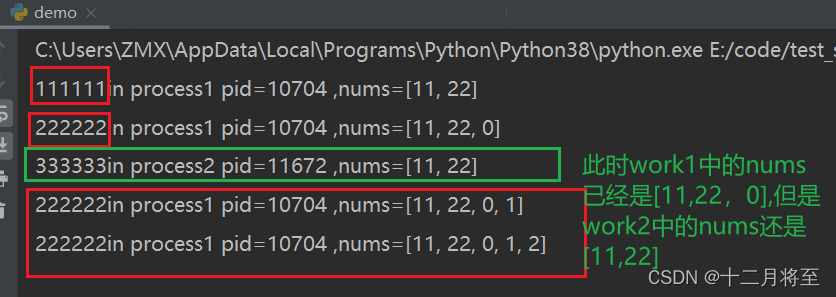
3、多进程之间变量是不共享的,但是如果我们需要共享的话,就需要进程间通信(IPC)
-
例如之前学习的网络编程udp、tcp,其实就是一种实现多进程间数据共享的方式,只是它通过套接字(socket)实现了不同电脑上的进程间通信
-
如果在一台电脑上不同进程间通信,就可以用其它的方式实现(知道即可,不需要深入研究,研究操作系统时才需要深入研究它们):
- 文件(一个进程写入到文件,一个进程从文件中读取)
- 共享内存
- 管道
1、 python 中常用的两种传递进程数据的方式
- 1、multiprocessing模块的Queue实现多进程之间的数据传递
- 2、multiprocessing模块提供的Pool方法里的Queu实现多进程之间的数据传递
2、使用multiprocessing模块的Queue实现多进程之间的数据传递
from multiprocessing import Queue
q = Queue(3) # 初始化一个Queue对象,最多可接收三条put消息
q.put("消息1")
q.put("消息2")
print(q.full()) # False
q.put("消息3")
print(q.full()) # True
# 因为消息列队已满,所以会导致下面的try都会抛出异常,
# 第一个try会等待2秒后再抛出异常
# 第二个Try会立刻抛出异常
try:
q.put("消息4", True, 2)
except:
print("消息列队已满,现有消息数量:%s" % q.qsize())
try:
q.put_nowait("消息4")
except:
print("消息列队已满,现有消息数量:%s" % q.qsize())
# 推荐的方式,先判断消息列队是否已满,再写入
if not q.full():
q.put_nowait("消息4")
# 读取消息时,先判断消息列队是否为空,再读取
if not q.empty():
for i in range(q.qsize()):
print(q.get_nowait())
from multiprocessing import Process
import os
import time
from multiprocessing import Queue
nums = [11, 22]
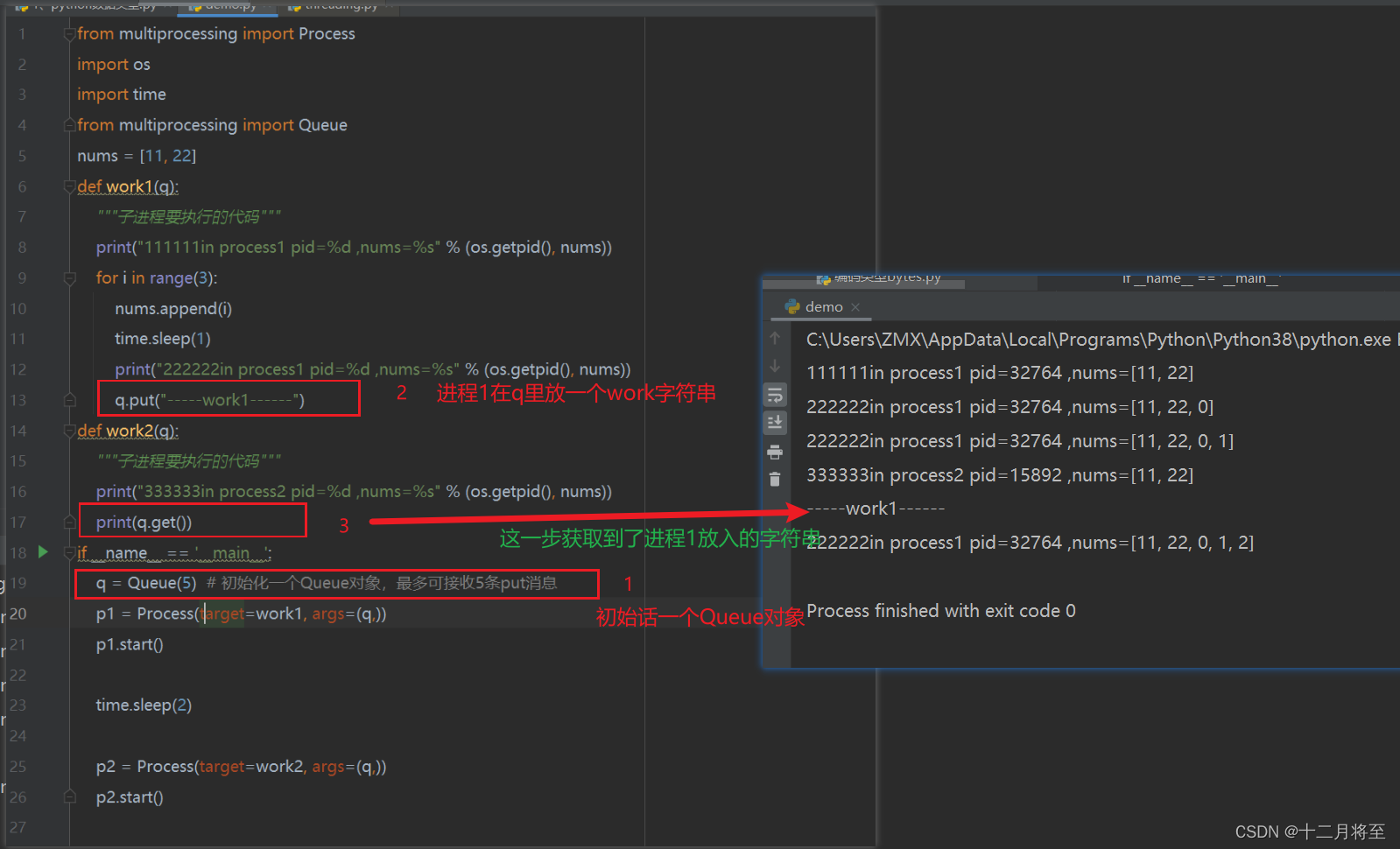
def work1(q):
"""子进程要执行的代码"""
print("111111in process1 pid=%d ,nums=%s" % (os.getpid(), nums))
for i in range(3):
nums.append(i)
time.sleep(1)
print("222222in process1 pid=%d ,nums=%s" % (os.getpid(), nums))
q.put("-----work1------")
def work2(q):
"""子进程要执行的代码"""
print("333333in process2 pid=%d ,nums=%s" % (os.getpid(), nums))
print(q.get())
if __name__ == '__main__':
q = Queue(5) # 初始化一个Queue对象,最多可接收5条put消息
p1 = Process(target=work1, args=(q,))
p1.start()
time.sleep(2)
p2 = Process(target=work2, args=(q,))
p2.start()
3、使用multiprocessing模块的pool方法里的Queue来传输数据–参考下文,先介绍pool线程池
4、使用pool方法创建进程池
- 当需要创建的子进程数量不多时,可以直接利用multiprocessing中的Process动态成生多个进程,但如果是上百甚至上千个目标,手动的去创建进程的工作量巨大,此时就可以用到multiprocessing模块提供的Pool方法。
- 初始化Pool时,可以指定一个最大进程数,当有新的请求提交到Pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到指定的最大值,那么该请求就会等待,直到池中有进程结束,才会用之前的进程来执行新的任务
这个要在linux环境下运行
from multiprocessing import Pool
import time
'''
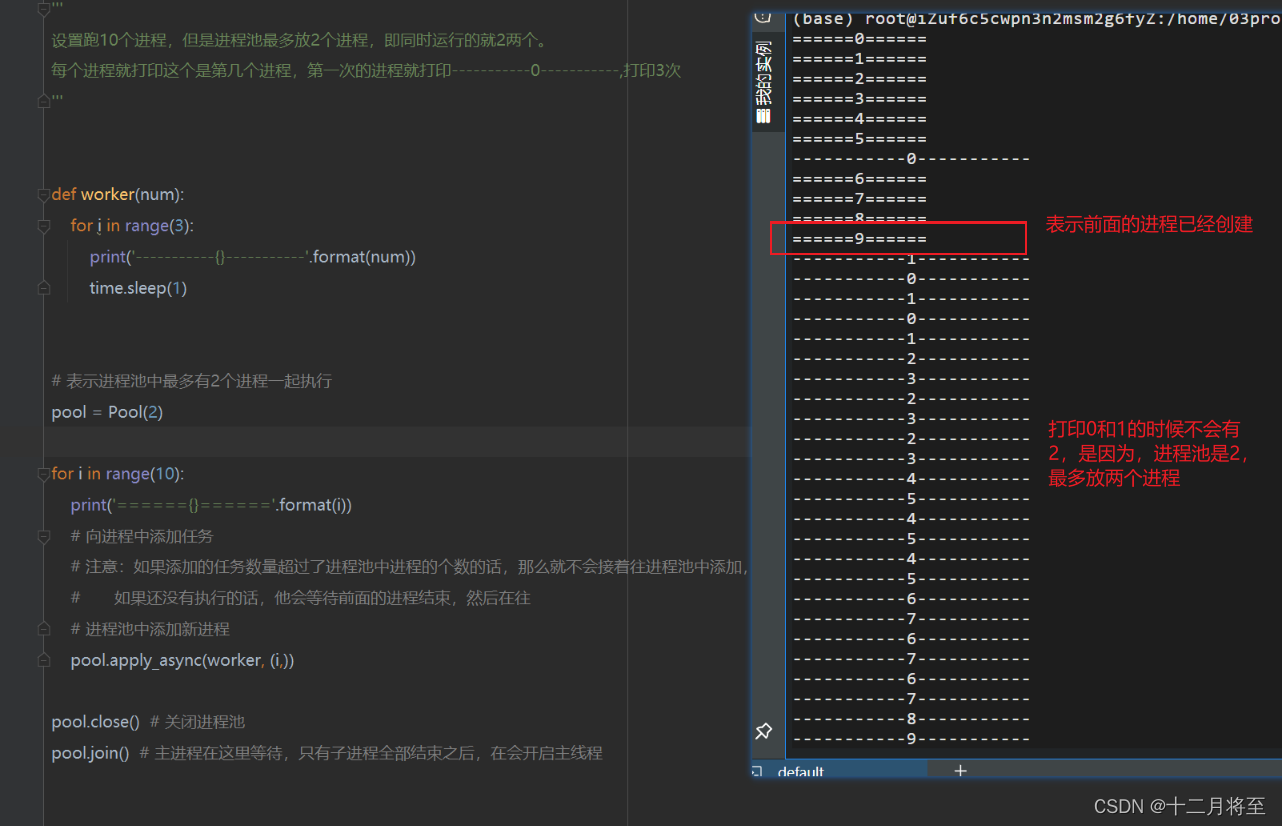
设置跑10个进程,但是进程池最多放2个进程,即同时运行的就2两个。
每个进程就打印这个是第几个进程,第一次的进程就打印-----------0-----------,打印3次
'''
def worker(num):
for i in range(3):
print('-----------{}-----------'.format(num))
time.sleep(1)
# 表示进程池中最多有2个进程一起执行
pool = Pool(2)
for i in range(10):
print('======{}======'.format(i))
# 向进程中添加任务
# 注意:如果添加的任务数量超过了进程池中进程的个数的话,那么就不会接着往进程池中添加,
# 如果还没有执行的话,他会等待前面的进程结束,然后在往
# 进程池中添加新进程
pool.apply_async(worker, (i,))
pool.close() # 关闭进程池
pool.join() # 主进程在这里等待,只有子进程全部结束之后,在会开启主线程
小结:
- apply_async(func[, args[, kwds]]) :使用非阻塞方式调用func(并行执行,堵塞方式必须等待上一个进程退出才能执行下一个进程),args为传递给func的参数列表,kwds为传递给func的关键字参数列表;
- close():关闭Pool,使其不再接受新的任务;
- terminate():不管任务是否完成,立即终止;
- join():主进程阻塞,等待子进程的退出, 必须在close或terminate之后使用;
5、pool进程池中使用Queue
-
之前是使用multiprocessing模块的Queue实现多进程之间的数据传递
-
如果要使用Pool创建进程,就需要使用multiprocessing.Manager()中的Queue(),而不是multiprocessing.Queue(),否则会得到一条如下的错误信息:
- RuntimeError: Queue objects should only be shared between processes through inheritance.
# -*- coding:utf-8 -*-
# 修改import中的Queue为Manager
from multiprocessing import Manager, Pool
import os, time
def reader(q):
print("reader启动(%s),父进程为(%s)" % (os.getpid(), os.getppid()))
for i in range(q.qsize()):
print("reader从Queue获取到消息:%s" % q.get(True))
def writer(q):
print("writer启动(%s),父进程为(%s)" % (os.getpid(), os.getppid()))
for i in "itcast":
q.put(i)
if __name__ == "__main__":
print("(%s) start" % os.getpid())
q = Manager().Queue() # 使用Manager中的Queue
po = Pool()
po.apply_async(writer, (q,))
time.sleep(1) # 先让上面的任务向Queue存入数据,然后再让下面的任务开始从中取数据
po.apply_async(reader, (q,))
po.close()
po.join()
print("(%s) End" % os.getpid())