1 逻辑回归之第一次学习
本文内容主要转自两处:
[1] 逻辑回归从入门到深入(logistic regression)
本文内容从Python 逻辑回归实际使用的角度出发,较为通俗易懂,感谢其作者的分享。
[2] 《百面机器学习》之逻辑回归
注意,下面有核心公式(1)、核心公式(2),笔者认为,理解了这两个公式,也就掌握逻辑回归的基本思想了。
其中(1)是逻辑回归函数(又称为对数几率函数),输出结果是预测X为正例的最大概率。
(2)是用公式(1)预测时的损失函数。
再辅以数值优化算法,例如梯度下降法、牛顿法等,就可以实现,逻辑回归算法进行分类任务的全部过程了。
1.1 引言
最近做一个项目,准备用逻辑回归来把数据压缩到[-1,1],但最后的预测却是和标签类似(或者一样)的预测。也就是说它的predict的结果不是连续的,而是类别,1,2,3,…k。对于predict_proba,这是预测的概率,但概率有很多个,数目为训练集类别(label)的个数。逻辑回归的原理,就是取出最大概率对应的类别。
所以逻辑回归,不是回归,而是分类器,二分类,多分类。
逻辑回归,是一个很有误导性的概念。
这是个人最近的体会,入门的读者请忽略。
1.2 线性回归
先说一下,一般模型的训练和预测过程:
1 训练:通过训练数据来训练模型,也就是通常我们所说的学习过程,即确定模型的参数。
2 预测:训练过后,模型参数确定,有预测数据输入,就会得到一个结果。
常见的线性回归y=wx+b,我们通过训练集来训练出我们的模型,也就是得到我们的模型参数w,b,这样,我们的直线或者超平面(x是多维的)就确定了。接着,对于测试集,来了一个数据x,w,b已经学习出来了,带入y=wx+b,就会得到一个y值,也就是我们的预测值。注意, 它是浮点数。
这里得到的y为什么叫回归呢,因为y不是类别(label)中的一个,它是预测出来的实数(大部分是小数)。
有的同学可能不理解什么是回归?我解释一下:
首先,需要明白二分类,类别/标签/label是二值,{0,1}或{-1,1},总之它的类别数两个。相信你已经知道多分类了,就是类别是多值的,{0,1,2,3,4}等,这是5类。那么回归是什么你呢。回归的取值,就不是像分类这样取整数了,它是小数,浮点数,是连续的,例如(0,1)之间的取值等。
1.3 逻辑回归
前面已经说了,虽然它不是回归,但是名字已经确定了,大家还是这么叫的。
前面的线性回归,我们已经得到y=wx+b。它是实数,y的取值范围可以是(负无穷,正无穷)。现在,我们不想让它的值这么大,所以我们就想把这个值给压缩一下,压缩到[0,1]。什么函数可以干这个事呢?研究人员发现signomid函数就有这个功能。所以,他们就尝试着,用signomid函数搞一搞这个y。
sigmoid的函数如下:
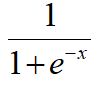
sigmoid的图像如下:
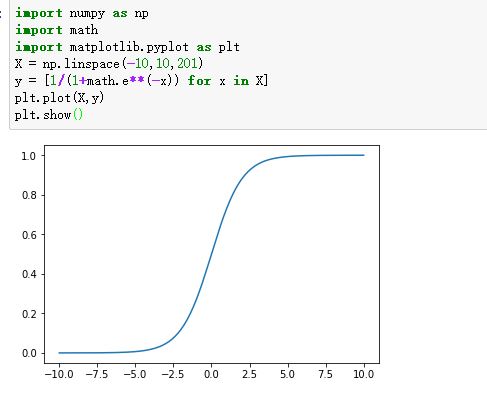
压缩,就是把y=wx+b带入sigmoid(x)。把这个函数的输出,还定义为y,即:
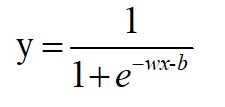
这样,y就是(0,1)的取值。
把这个式子变换一下:
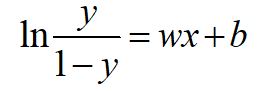
1.4 损失函数
损失函数,通俗讲,就是衡量真实值和预测值之间差距的函数。所以,我们希望这个函数越小越好。在这里,最小损失是0。
以二分类(0,1)为例:
当真值为1,模型的预测输出为1时,损失最好为0,预测为0是,损失尽量大。
同样的,当真值为0,模型的预测输出为0时,损失最好为0,预测为1是,损失尽量大。
所以,我们尽量使损失函数尽量小,越小说明预测的越准确。
这个损失函数为:
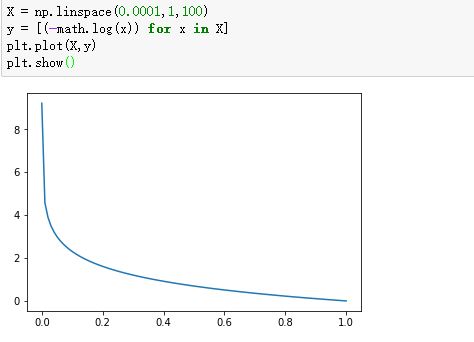
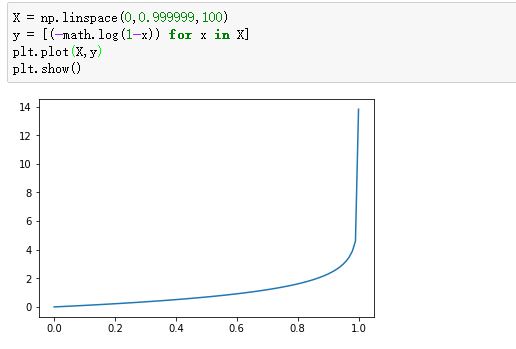
我们看看这个函数的图像:
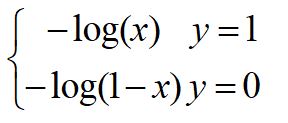
-log(x):
-log(1-x):
所以,我们压缩之后,预测y在0-1之间。我们利用这个损失函数,尽量使这个损失小,就能达到很好的效果。
我们把这两个损失综合起来:
y就是标签,分别取0,1,看看是不是我们前面写的那两个损失函数。
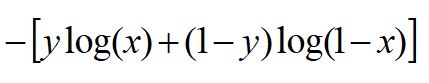
对于m个样本,总的损失:
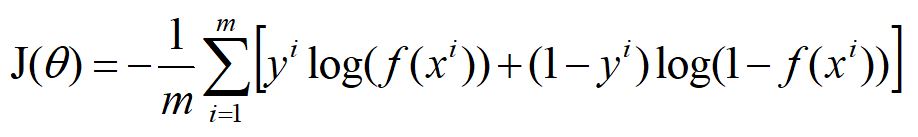
这个式子中,m是样本数,y是标签,取值0或1,i表示第i个样本,f(x)表示预测的输出。
不过,当损失过于小时,也就是模型能拟合全部/绝大部分的数据,就有可能出现过拟合。这种损失最小是经验风险最小,为了不让模型过拟合,我们又引入了其他的东西,来尽量减小过拟合,就是大家所说的结构风险损失。
结构经验风险常用的是正则化,L0,L1,L2正则化。
损失函数的详细推导:
参考书籍:《Python机器学习算法》赵志勇著


1.5 sklearn中的应用
sklearn.linear_model.LogisticRegression(penalty=l2, # 惩罚项,可选l1,l2,对参数约束,减少过拟合风险
dual=False, # 对偶方法(原始问题和对偶问题),用于求解线性多核(liblinear)的L2的惩罚项上。样本数大于特征数时设置False
tol=0.0001, # 迭代停止的条件,小于等于这个值停止迭代,损失迭代到的最小值。
C=1.0, # 正则化系数λ的倒数,越小表示越强的正则化。
fit_intercept=True, # 是否存在截距值,即b
intercept_scaling=1, #
class_weight=None, # 类别的权重,样本类别不平衡时使用,设置balanced会自动调整权重。为了平横样本类别比例,类别样本多的,权重低,类别样本少的,权重高。
random_state=None, # 随机种子
solver=’liblinear’, # 优化算法的参数,包括newton-cg,lbfgs,liblinear,sag,saga,对损失的优化的方法
max_iter=100,# 最大迭代次数,
multi_class=’ovr’,# 多分类方式,有‘ovr','mvm'
verbose=0, # 输出日志,设置为1,会输出训练过程的一些结果
warm_start=False, # 热启动参数,如果设置为True,则下一次训练是以追加树的形式进行(重新使用上一次的调用作为初始化)
n_jobs=1 # 并行数,设置为1,用1个cpu运行,设置-1,用你电脑的所有cpu运行程序
)
1.5.1 solver 各参数详解
损失函数的选择,主要有liblinear(线性分类器库),sag,saga,newton-cg,lbfgs
对于小的数据集,选择‘liblinear’较好;对于大的数据集,选择’sag’或者‘saga’,它们的速度更快
对于对分类问题,只能用sag,saga,newton-cg,lbfgs;对于多项式损失,'liblinear’只限于1对多的问题。
sag,newton-cg,lbfgs,只能用于L2正则化,liblinear,saga还可以用于L1正则化
-
liblinear
liblinear: A Library for Large Linear Classification
liblinear是国立台湾大学林智仁(Chih-Jen Lin)老师团队开发的,他们还开发了libsvm。
liblinear是一个线性分类器,它支持:
L2-regularizedL1-loss Support VectorClassification # L2正则化项,L1损失函数的SVM分类器
L2-regularizedL2-loss Support Vector Classification # L2正则化项,L2损失函数的SVM分类器
L1-regularizedL2-loss Support Vector Classification # L1正则化项,L1损失函数的SVM分类器
L2-regularized Logistic Regression # L2正则逻辑回归
L1-regularized Logistic Regression # L1正则逻辑回归
sklearn参数中的penalty=L2,就是采用上面的L2正则逻辑回归,是对参数矩阵W做了平方。 -
sag
sag :Stochastic Average Gradient(随机平均梯度)
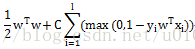
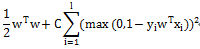
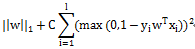
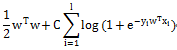
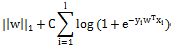
1.6 《百面机器学习-逻辑回归》


2 逻辑回归 之 第二次学习
前一次学习较为啰嗦,这次简单概括一下。
2.1 基础概念
逻辑回归,虽然名字中有“回归”两个字,但不是回归算法,而是分类算法。
应用场景:多用于二分类任务。
逻辑回归的目的:计算出样本是“正例”的概率、是“反例”的概率。结果的阈值为 [0,1]。
公式推导:
(一)首先,用最简单的线性回归计算,样本是某一类别(此处可先计算正例)的概率,可表示为p1:
p(y=1) = c0 + c1x1 + … + cnxn
缺点,这样得到的结果,值域是R。
(二)为了将上式p(y=1)的结果映射到[0,1]中,使用Sigmoid函数。
将p1代入Sigmoid函数,值域是(0,1)。
(三)将(二)中公式变换一下,得到逻辑回归的公式:
(四)逻辑回归的损失函数
公式总结:

2.2 优缺点
- 优点
(1)可解释性强,可以看到各个属性的权重和影响。
(2)不需要事先假设数据的分布。
(3)不仅得到类别,还得到每个类别的概率值,可以帮助实现更精确的决策。 - 缺点
(1)预测精度一般。
(2)对异常值敏感。
2.3 Demo
Python的datasets模块中,有一份乳腺癌数据集,这是一个二分类数据集。
- 共有569个样本,212个为恶性(0),357个为良性(1)。
- 每个样本有30个特征,均为非负实数。
- 30个特征分3类,前10个是相关指标的平均值,中间10个是指标的偏差,最后10个是指标的最差极值。
程序:
import numpy as np
from sklearn import datasets
from sklearn.linear_model import LogisticRegression #逻辑回归类
from sklearn.metrics import confusion_matrix #混淆矩阵类
from sklearn.model_selection import train_test_split
breast_cancer = datasets.load_breast_cancer()
x = breast_cancer.get('data')
y = breast_cancer['target']
X_train,X_test,y_train,y_test = train_test_split(x,y,random_state=42)
# 逻辑回归拟合
log_reg = LogisticRegression()
log_reg.fit(X_train,y_train)
# 测试集效果检验,输出混淆矩阵
y_predict = log_reg.predict(X_test)
print(confusion_matrix(y_test,y_predict))
输出:
[[50 4]
[ 2 87]]
关于混淆矩阵,可参考笔者的另一篇文章:分类器评估方法:准确率和混淆矩阵
LogisticRegression()的参数:
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)
常用的有:
-
penalty:选择正则化方法——可选值有“l1”、“l2”。
penalty参数可选择的值为"l1"和"l2".分别对应L1的正则化和L2的正则化,默认是L2的正则化。
在调参时如果我们主要的目的只是为了解决过拟合,一般penalty选择L2正则化就够了。但是如果选择L2正则化发现还是过拟合,即预测效果差的时候,就可以考虑L1正则化。另外,如果模型的特征非常多,我们希望一些不重要的特征系数归零,从而让模型系数稀疏化的话,也可以使用L1正则化。
penalty参数的选择会影响我们损失函数优化算法的选择。即参数solver的选择,如果是L2正则化,那么4种可选的算法{‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’}都可以选择。但是如果penalty是L1正则化的话,就只能选择‘liblinear’了。这是因为L1正则化的损失函数不是连续可导的,而{‘newton-cg’, ‘lbfgs’,‘sag’}这三种优化算法时都需要损失函数的一阶或者二阶连续导数。而‘liblinear’并没有这个依赖。 -
C:设置正则化强度。
C越小,越容易防止过拟合,正则化(惩罚)强度越高。(注意:C过小,可能导致欠拟合)
默认值是0,即不进行正则化。 -
solver:选择优化算法,比如梯度下降算法,为了使模型参数,快速达到最优解。
a) liblinear:使用了开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数。
b) lbfgs:拟牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
c) newton-cg:也是牛顿法家族的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
d) sag:即随机平均梯度下降,是梯度下降法的变种,和普通梯度下降法的区别是每次迭代仅仅用一部分的样本来计算梯度,适合于样本数据多的时候。SAG是一种线性收敛算法,这个速度远比SGD快
在sklearn的官方文档中,对于solver的使用说明如下:
从上面的描述,大家可能觉得,既然newton-cg, lbfgs和sag这么多限制,如果不是大样本,我们选择liblinear不就行了嘛!错,因为liblinear也有自己的弱点!我们知道,逻辑回归有二元逻辑回归和多元逻辑回归。对于多元逻辑回归常见的有one-vs-rest(OvR)和many-vs-many(MvM)两种。而MvM一般比OvR分类相对准确一些。郁闷的是liblinear只支持OvR,不支持MvM,这样如果我们需要相对精确的多元逻辑回归时,就不能选择liblinear了。也意味着如果我们需要相对精确的多元逻辑回归不能使用L1正则化了。
.
总结而言,liblinear支持L1和L2,只支持OvR做多分类,“lbfgs”, “sag” “newton-cg”只支持L2,支持OvR和MvM做多分类。 -
multi_class:选择分类方式。可选值有:ovr和multinomial。
multi_class参数决定了我们分类方式的选择,有 ovr和multinomial两个值可以选择,默认是 ovr。
ovr即前面提到的one-vs-rest(OvR),而multinomial即前面提到的many-vs-many(MvM)。如果是二元逻辑回归,ovr和multinomial并没有任何区别,区别主要在多元逻辑回归上。
OvR的思想很简单,无论你是多少元逻辑回归,我们都可以看做二元逻辑回归。具体做法是,对于第K类的分类决策,我们把所有第K类的样本作为正例,除了第K类样本以外的所有样本都作为负例,然后在上面做二元逻辑回归,得到第K类的分类模型。其他类的分类模型获得以此类推。
而MvM则相对复杂,这里举MvM的特例one-vs-one(OvO)作讲解。如果模型有T类,我们每次在所有的T类样本里面选择两类样本出来,不妨记为T1类和T2类,把所有的输出为T1和T2的样本放在一起,把T1作为正例,T2作为负例,进行二元逻辑回归,得到模型参数。我们一共需要T(T-1)/2次分类。
从上面的描述可以看出OvR相对简单,但分类效果相对略差(这里指大多数样本分布情况,某些样本分布下OvR可能更好)。而MvM分类相对精确,但是分类速度没有OvR快。
如果选择了ovr,则4种损失函数的优化方法liblinear,newton-cg, lbfgs和sag都可以选择。但是如果选择了multinomial,则只能选择newton-cg, lbfgs和sag了。
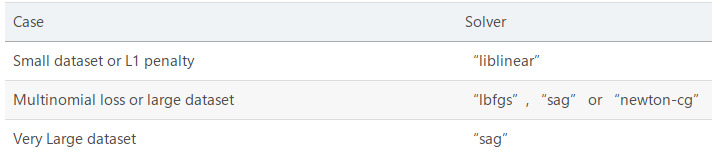
参数选择总结:
- 需要筛选特征
须使用L1正则化:penalty = l1。
因为L1正则化,没有连续导数,所以solver只能使用libnear。
.
不适用的情况:多元逻辑回归时,为了保证精准度,multi_class须选用multinomial,就不能用solver=libnear了,也就不能用L1正则化了。 - 样本量大,eg:10w
须使用梯度下降法优化算法:solver=sg
就只能使用L2正则化了:penalty=l2
.
不适用的情况:
<1> 需要筛选特征:应使用L1正则化。
<2>样本量小:sag每次仅仅使用了部分样本进行梯度迭代,所以当样本量少的时候不要选择它
总结而言,liblinear支持L1和L2,只支持OvR做多分类,“lbfgs”, “sag” “newton-cg”只支持L2,支持OvR和MvM做多分类。
想了解LogisticRegression()参数的其他内容,可以参考:逻辑回归(Logistic Regression)
2.4 总结
逻辑回归是有监督分类算法,应用场景多是二分类任务。
逻辑回归是非线性模型,但本质是线性回归和Sigmoid函数的结合。传统的线性回归可以拟合函数曲线的最佳参数,而Sigmoid函数帮助我们将输出值固定在**[0,1]**。
2.5 逻辑回归用于多分类任务
将Sigmod函数,换为Softmax函数即可。
Softmax函数,或称归一化指数函数。它能将一个K维向量 “压缩”到另一个K维向量 中,使得每一个元素的范围都在 [0,1]之间,并且所有元素的和为1。
该函数的形式通常按下面的式子给出:
其中, j = 1, …, K。

上图参考自:《Python机器学习实战》裔隽 张怿檬 张目清 等 著

3 逻辑回归之第三次学习:手推公式
逻辑回归中的损失函数的解释
后面的多分类公式,可以参考笔者文章常见的损失函数中的对数损失函数。



