深入理解Kafka系列(八)--Kafka的流式处理
系列文章目录
前言
本系列是我通读《Kafka权威指南》这本书做的笔录和思考。
正文
数据流是一个无边界的数据集的抽象表示。无边界也就是意味着无限和持续增长,现实中可以理解为随着时间的推移,新的数据会不断的加入到这个集合当中。如股票交易、快递的递送啊等等。
一个事件流模型除了以上的无边界的属性外,还有以下属性:
- 事件流是有序的:事件的发生总是有个先后顺序。
- 不可变的数据记录:事件一旦发生,就不能被改变。
- 事件流是可重播的:比如我们曾经用过A手段去处理某个事件M,而现在,可重播的意思就代表着支持我们用新的手段去处理事件M,或者说进行审计。
简单了解过事件流后,就可以了解流式处理了。流式处理是指实时的处理一个或者多个事件流,流式处理是一种编程范式,以下是他的3大特征:
- 请求与响应:这是延迟最小的一种范式,响应时间处于亚毫秒到毫秒之间,并且响应时间非常稳定。但是这种处理模式一般是堵塞的,应用程序向处理系统发出请求,然后等待响应。
- 批处理:这种范式具有高延迟、高吞吐量的特点。数据都是层批次的进行处理,用户会看到相同的结果直到下一批消息处理完毕。
- 流式处理:该范式介于上述两者之间。大部分业务不要求亚毫秒级的响应,也不想批处理这种需要等待一段时间才知道结果,反而大部分业务是一个持续进行的过程,只需要业务报告保持更新,得到持续的响应,则使用流式处理,边接收数据边处理数据。
流式处理的相关概念
1.时间
流式处理系统当中一般包含了如下几个时间概念:
1.事件时间:指所追踪事件的发生时间和记录的创建时间。在Kafka0.10.0或者更高的版本当中,生产者会自动在记录中添加记录的创建时间。举例:商品的出售时间,网站用户访问页面的时间。
2.日志追加时间:指的是事件保存到broker的时间。在Kafka0.10.0或者更高的版本当中,如果启动了自动添加时间戳的功能,那么broker会在接受这些记录的时候自动添加时间戳。
3.处理时间:指应用程序在收到事件之后要对其进行处理的时间。
2.状态
事件和事件之间的信息被称为状态。一般状态会被保存到应用程序里的本地变量当中,例如:用散列表保存移动计时器。,流式处理包含了以下几种类型的状态:
1.本地状态或者内部状态:这种状态只能被单个应用程序实例访问,他们一般使用内嵌在应用程序里面的数据库进行维护和管理。本地状态的优势在于他的速度很快,劣势在于他受到内存大小的限制。因此,流式处理的很多设计模式都将数据拆分到多个子流。
2.外部状态:这种状态使用外部的数据存储来维护,一般使用NoSql系统。优势在于:没有大小限制并且可以被应用程序的多个实例访问。劣势在于:引入外部系统会增加复杂性和延迟性。也就引入了如何维护内部和外部状态一致性的问题。
3.流和表的二元性
首先,表的记录是可变更的。我们将表与流进行对比的时候,可以这么想,流包含了变更,流中的每个事件就是一个变更。而表包含了当前的状态,是多个变更造成的结果。所以流和表可以看作为同一个硬币的两面。
1.表转化为流:需要捕捉到表上面所发生的的变更。比如增删改操作,对于数据库表而言有个很好的例子也就是CDC增量,Kafka连接器会把这些变更发送到Kafka,用于后续的流处理。
2.流转化为表:需要“应用”流里面所包含的所有变更。首先在内存中、内部状态存储或者外部数据库中创建一张表,然后从头到尾遍历流里的所有时间,逐个地改变状态,完成这个过程后,得到一张表,代表某个时间点的状态。
4.时间窗口
大部分针对流的操作都是基于时间窗口的,比如两个流的合并啊、移动平均数啊等等。针对时间窗口,我们首先要知道这么几个问题:
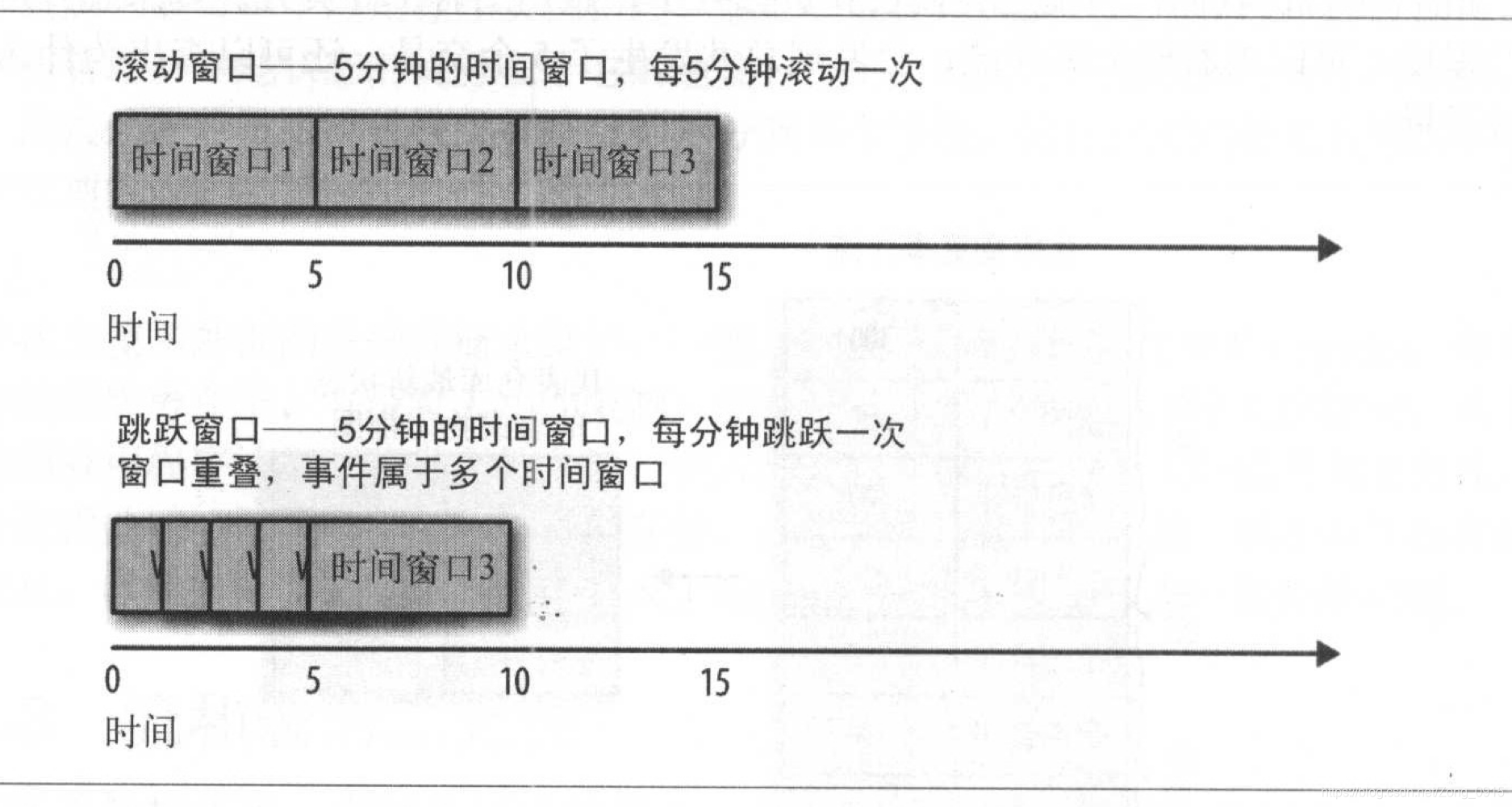
1.窗口的大小:窗口越小,就能越快的发现变更。窗口越大,变更越平滑,但是延迟越严重。
2.窗口的频率:如果移动间隔与窗口大小相等,这种情况被称为滚动窗口,如果窗口随着每一条记录移动,这种情况叫做移动窗口。
3.窗口的可更新时间多长:即定义一个时间段,在这个时间段内,事件会被添加到与他们对应的时间片段中。
滚动窗口和跳跃窗口的区别:
流式处理的设计模式
这里主要讲流式处理在不同的场景或者模型下,如何处理,也就是流式处理框架用怎样的设计模式去解决对应的业务。
单个事件处理
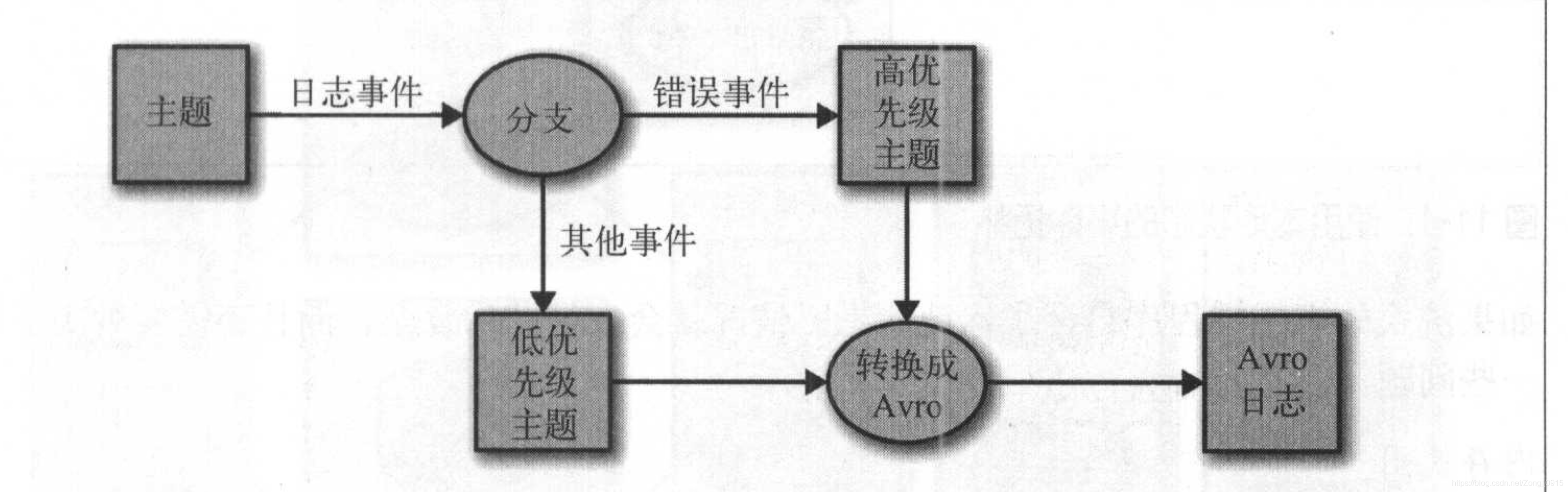
处理单个事件是流式处理当中最基本的模式,这个模式也叫做map或filter模式,因为他经常被用作过滤无用的事件或者用于转换事件。
在这种模式下,应用程序读取流中的事件,修改他们,然后把事件生成到另外的流上。例如:一个应用程序从一个流当中读取日志消息,然后把ERROR级别的消息写到高优先级的流中,把其他消息写到低优先级的流中。
如图:
这类应用程序不需要再程序内部维护状态,因为每个事件都是独立处理的。
使用本地状态
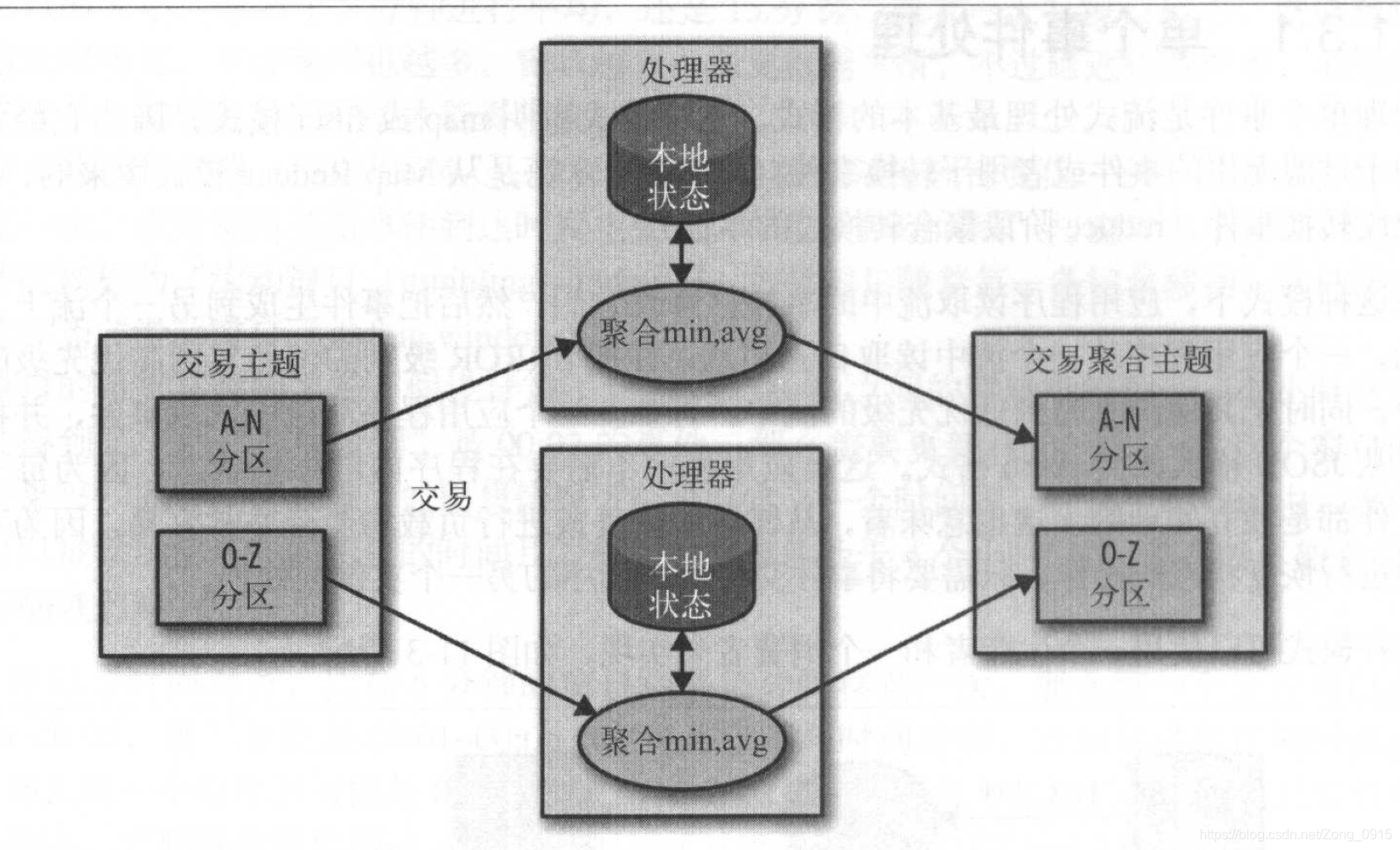
大部分流式处理应用程序关心的是如何聚合信息,特别是基于时间窗口进行聚合。这些操作的实现,需要维护流的状态,可以通过本地状态来实现。
例如:基于各个股票的代码进行聚合。使用Kafka分区器来确保具有相同股票代码的事件总是被写入相同的分区
但是流式处理如果包含了本地状态,情况就会变得非常复杂,还需要解决其他的一些问题,如下:
- 内存使用:应用实例必须要有可用的内存空间来保存本地状态。
- 持久化:确保应用程序关闭的时候不会丢失状态,并且在应用程序重启或者切换到另外一个领用的时候可以恢复状态。
- 再均衡:有些时候,分区会被重新分配给不同的消费者(Kafka的特性),那么这种情况下,失去分区的实例必须把最后的状态保存起来,同时获得分区的实例必须知道如何恢复正确的状态
多阶段处理和重分区
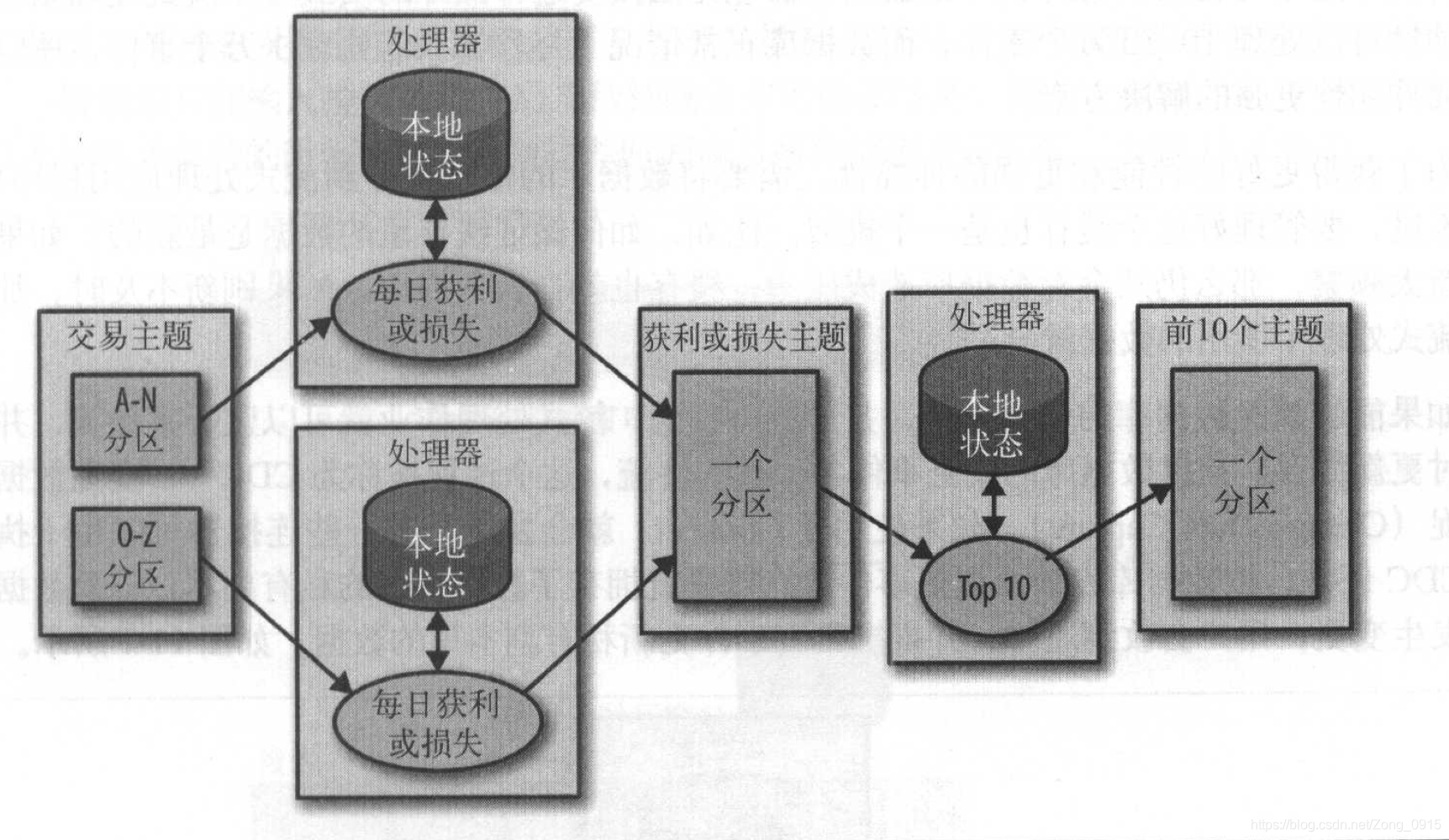
有些时候,可能需要对某一个结果产生一个筛选,获得一个经过精拣的最终结果。比如:我们需要获得每天发布的前10支股票,那么我们需要做一个两阶段解决方案,即多阶段处理
一阶段:计算每只股票当天的涨跌,这个可以在每个实例上进行。
二阶段:将结果写入到一个包含单个分区的新主题上,另一个单独的实例读取该分区,找出当天的Top10股票。
步骤图如下:
再举个例子:MapReduce代码当中,可能需要很多个reduce步骤,每个reduce步骤的应用需要被隔离开来,但是大多数流式处理框架可以将多个步骤放在一个应用里面,框架会负责调配每一步需要运行哪一个应用实例。
使用外部查找—流和表的连接
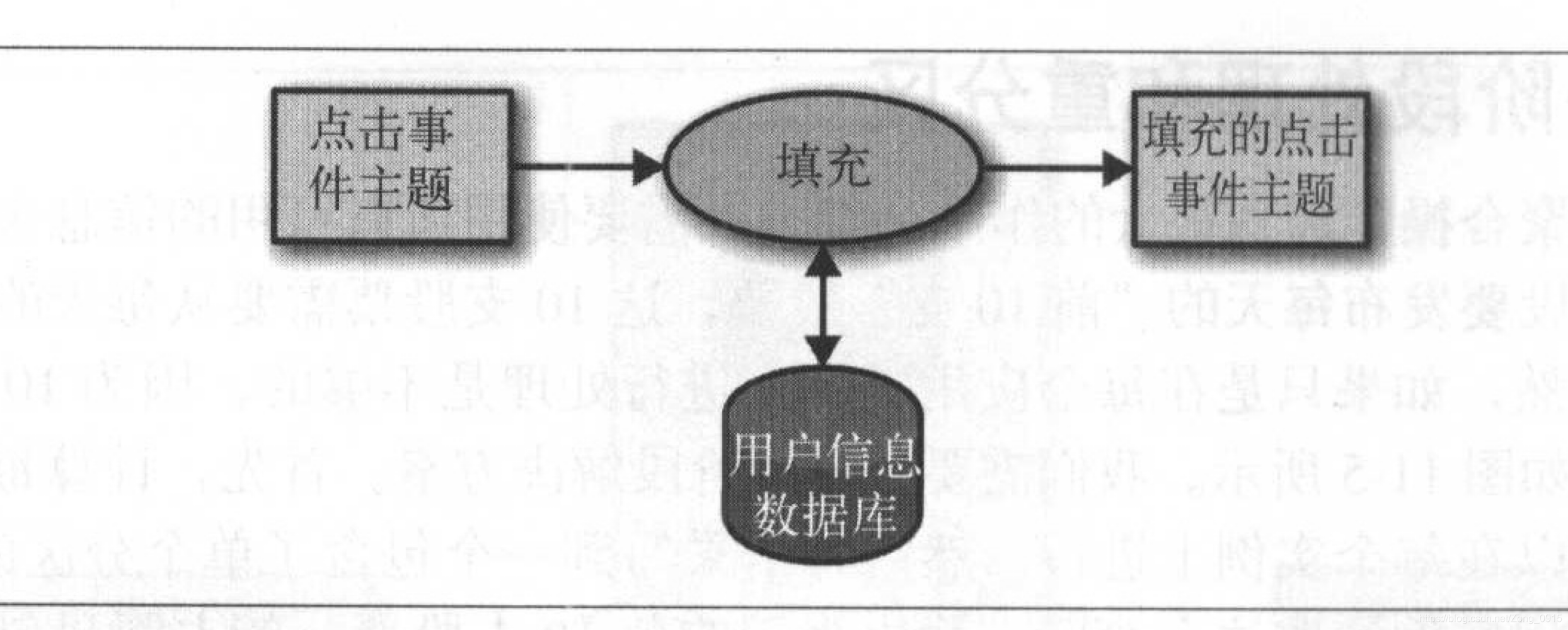
有些时候,流式处理需要将外部数据和流集成在一起,比如使用保存在外部数据库里的规则来验证事务。这种情况可以这样做:
- 对于事件流的每一个点击事件,从用户信息表里查找相关的用户信息。
- 然后把其中需要的信息抽取出来并将其插入到点击事件当中。
- 然后把整合过的新事件发布到另外的主题上。
这种方式会产生一些严重的问题:
- 外部查找带来严重的延迟。
- 外部数据存储无法接受这种额外的负载(Kafka的处理量非常巨大,远大于数据库的处理量)
解决方案:
为了获得更好的性能和更强的伸缩性,需要将数据库的信息缓存到流式处理应用程序中。
问题:如何保证缓存中的数据是最新的?如果刷新太过于频繁,数据库压力太大,刷新不及时,那么流中的数据又会过时,那怎么办?
答:1.如果说能够捕捉数据库的变更事件,并形成事件流,流式处理作业就可以监听事件流,并及时更新缓存。那么捕捉数据库的变更事件并形成事件流的这个过程也就是我们都听过的:CDC—(Change Data Capture)。
2.Kafka中的Connect连接器,有一些可以执行CDC任务,把数据库表转成变更事件流,那这样的话,一旦数据库发生变更,用户就会收到通知。
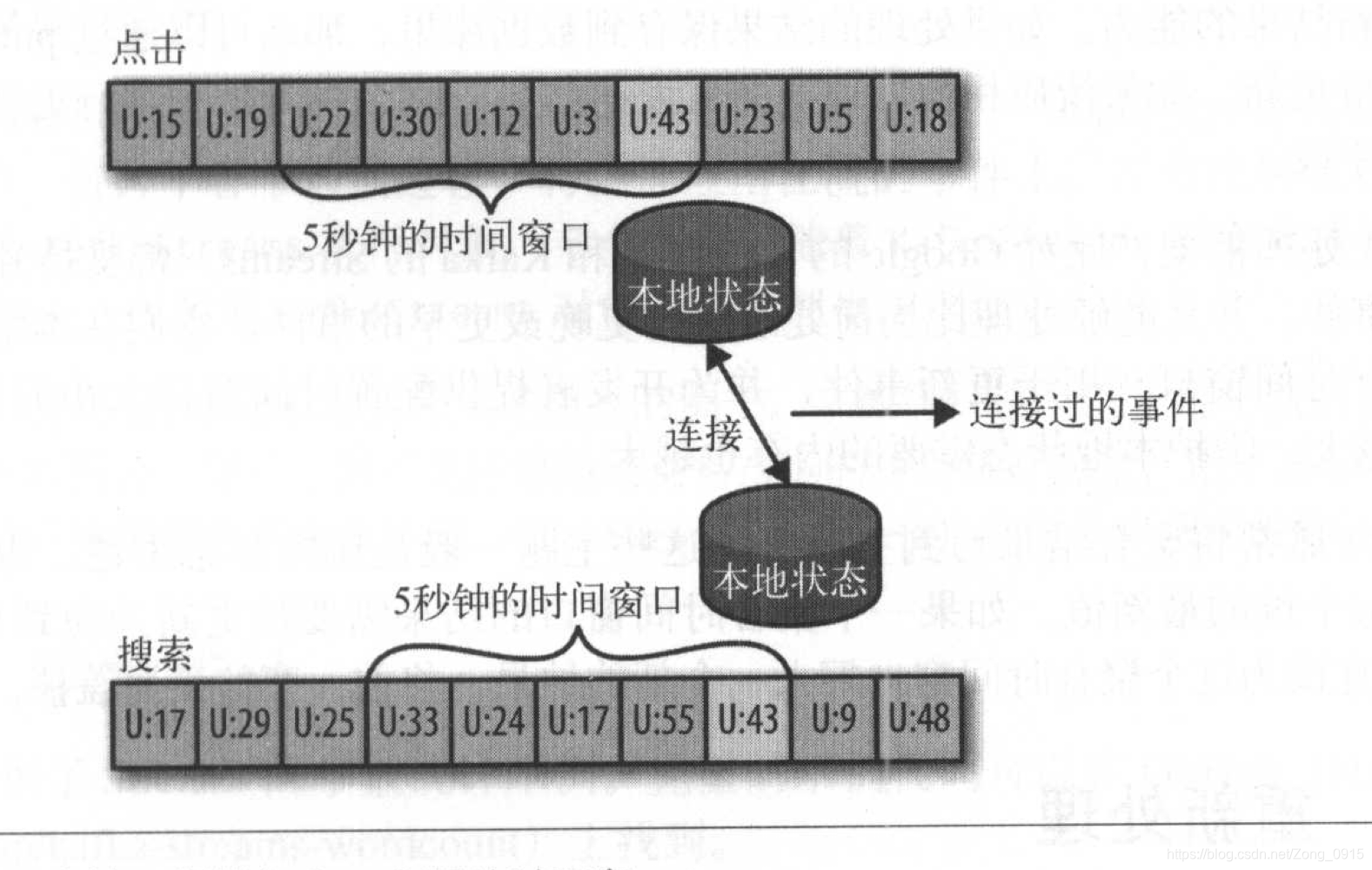
流与流的连接
流和流的连接也叫做基于时间窗口的连接,也就是将两个流里面具有相同键和发生在相同时间窗口内的事件匹配起来。 例如:有一个由网站用户输入的搜索事件流和一个由用户对搜索结果进行点击的事件流,那么我们对用户的搜索和用户对搜索结果的点击进行匹配,就可以知道哪一个搜索的热度更高。
这种情况下,我们一般都需要基于搜索关键词来进行匹配,且每个关键词只能和一定时间窗口内的事件进行匹配,因为一般用户在输入搜索关键词后的几秒钟内会点击搜索结果。
所以对于这种流与流的连接,我们都需要为每一个流维护一个时间窗口,并对这些时间窗口事件进行结果匹配。
乱序的事件
不管是流式处理还是传统的ETL系统,处理乱序事件都是一个挑战。在现实生活中,如:一个移动设备断开wifi几个小时,再重新连接的时候需要将几个小时间积累的事件一起发送出去。
如果要让流式处理应用程序处理好这些场景,需要做到以下几点:
- 识别乱序的事件:应用程序需要检查事件的事件,并将其与当前时间进行比较(时间戳)。
- 规定一个时间段用于重排乱序的事件:比如3个小时以内的事件是允许重排的。
- 具有在一定时间段内重排乱序事件的能力。
- 具备更新结果的能力。
一些流式处理框架如Google的Dataflow和Kafka的Streams,都支持独立于处理时间发生的事件,并且能够处理比当前处理时间更早或者更晚的事件。他们在本地状态里维护了多个聚合时间窗口,用于更新事件,并为开发者提供配置时间窗口大小的能力。
重新处理
最后一个模式为重新处理事件,该模式有两个处理情况。
- 我们对流式处理应用进行改进,使用新版本应用处理同一个事件流,生成新的结果,并比较两种版本的结果,然后在某个时间点将客户端切换到新的结果流上。
对于这种情况,Kafka将事件流长时间的保存在可伸缩的数据存储里。
如果要使用两个版本的流式处理应用来生成结果,需要满足以下三个条件:
1.将新版本的应用作为一个新的消费者群组。
2.让他从输入主题的第一个偏移量开始读取数据。
3.检查结果流,在新版本的处理作业赶上进度的时候,将客户端应用程序切换到新的结果流上。
- 先用的流式处理应用出现了缺陷,在修复完缺陷后,重新处理事件流并重新计算结果。
这种情况要求我们重置应用,让应用回到输入流的起始位置开始处理,同时重置本地状态(这样两个版本应用的处理结果就不会混淆),同时需要清理之前的输出流。
这两种情况,我推荐第一种。
- 首先,第一种可以让新老版本的处理结果进行比较。
- 其次,第二种情况需要清理输入输出流,并且重置状态,简而言之就是需要把老版本的数据or缓存进行清空,即存在数据丢失的情况。
- 那么第一种情况更加安全,多个版本之间还可以来回切换,也不会再清理过程中引入错误。
Streams示例
字数统计
1.pom文件
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.12</artifactId>
<version>0.11.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>0.11.0.0</version>
</dependency>
2.示例程序
package kafka;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.KeyValue;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KStreamBuilder;
import java.util.Arrays;
import java.util.Properties;
import java.util.regex.Pattern;
public class WordCountExample {
public static void main(String[] args) throws InterruptedException {
Properties properties = new Properties();
// 1.每个Streams应用程序必须要有一个应用ID
properties.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordCount");
// 2.Streams从Kafka上读取数据,并将结果写到Kafka主题上
properties.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.237.130:9092");
// 3.读写数据时的序列化和反序列化器
properties.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
properties.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
// 4.创建一个KStreamBuilder对象,并且定义一个流,指向输入主题
KStreamBuilder builder = new KStreamBuilder();
KStream<String, String> source = builder.stream("wordcount-input");
final Pattern pattern = Pattern.compile("\\W+");
// 5.从主题上读取的每一个事件就是一行文字,用正则表达式将他拆分为一系列的单词,然后将每个单词作为事件的键
KStream<Object, String> counts = source.flatMapValues(value ->
Arrays.asList(pattern.split(value.toLowerCase())))
.map((key, value) -> new KeyValue<Object, Object>(value, value))
// 6.过滤掉the单词
.filter((key, value) -> (!value.equals("the")))
// 7.根据键进行groupBy操作,这样得到了一个不重复的单词集合
.groupByKey()
// 8.计算每个集合里面的事件数,计算结果为Long型,转成String
.count("CountStore").mapValues(value -> Long.toString(value))
.toStream();
// 9.最终将结果写回Kafka
counts.to("wordcount-output");
KafkaStreams streams = new KafkaStreams(builder, properties);
// 10.启动程序
streams.start();
Thread.sleep(5000L);
streams.close();
}
}
3.具体步骤:
- 创建输入主题:wordcount-input
./bin/kafka-topics.sh --zookeeper 192.168.237.130:2181 --topic wordcount-input --partitions 1 --replication-factor 1 --create
- 向输入主题中输入数据:
./bin/kafka-console-producer.sh --broker-list 192.168.237.130:9092 --topic wordcount-input

- 启动代码(一次性的)
- 消费者获取主题:wordcount-output
./bin/kafka-console-consumer.sh --topic wordcount-output --from-beginning --bootstrap-server 192.168.237.130:9092 --property print.key=true
结果:可以看出各个单词的统计数已经出来了,并且过滤掉了the单词
这个事例主要是演示了如何实现单事件处理模式(在事件上使用了map和filter),然后通过group by操作对数据进行重新分区,并为统计记录个数维护了一个简单的本地状态。

Streams的架构概览
每个流式应用程序至少会实现和执行一个拓扑(DAG,有向无环图),是一个操作和变换的集合,每个事件从输入到输出都会经过他,拿上面的字数统计例子来说,他的DAG图如下:
拓扑是由处理器来组成的,这些处理器是拓扑图中的节点(椭圆节点)
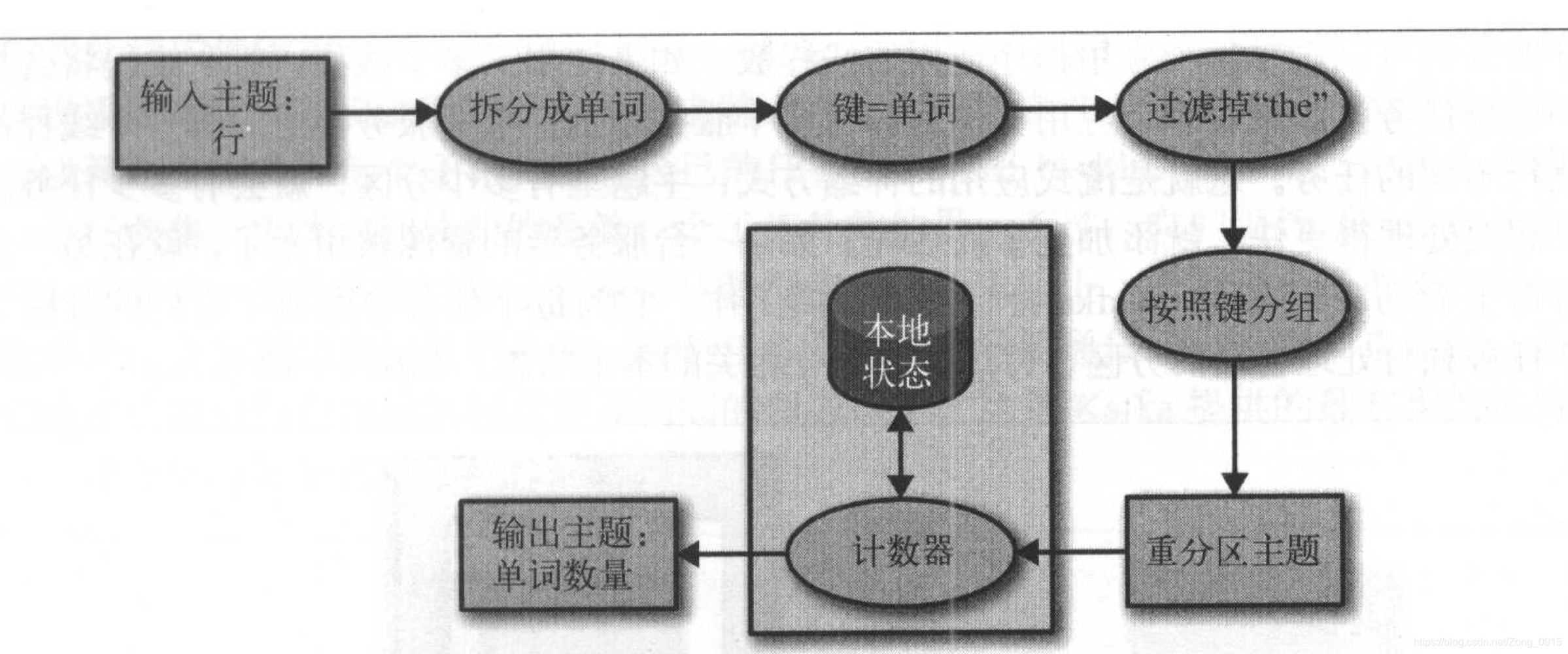
- 大部分处理器都实现了一个数据操作:过滤、映射、聚合等。
- 数据源处理器从主题上读取数据,并传给其他组件。
- 数据池处理器从上一个处理器接收数据,并将他们生成到主题上。
- 拓扑总是从一个或者多个数据源处理器开始,并以一个或者多个数据池处理器结束。
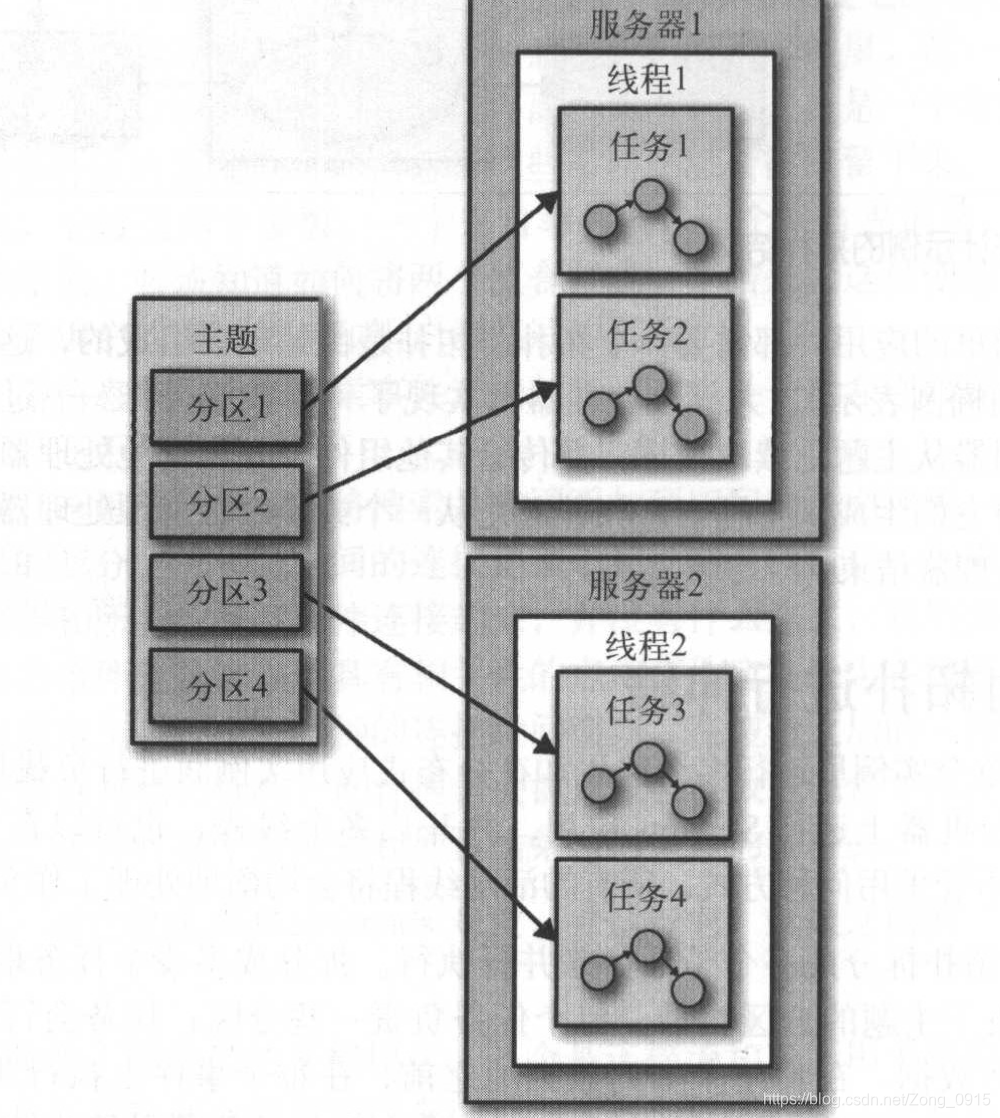
对拓扑进行伸缩
其实上面的一个拓扑流程可以看做为一个任务。那么Streams引擎可能会将拓扑拆分成多个子任务来并行运行,至于拆分为多少个取决于Streams引擎以及主题的分区数量。
- 任务是Streams引擎最基本的并行单元。
- 每个人物负责一些分区,任务会订阅这些分区,并从分区当中读取事件数据。
- 在任务将结果写到数据池之前,这些处理步骤会在每个事件上执行。
如图:运行相同拓扑的两个任务—每个读取主题的一个分区。
当然,除了任务的拆分,开发人员还可以选择每个应用程序使用的线程数。如果使用了多个线程,每个线程会执行一部分任务,如果有多个应用实例运行在多个服务器上,每个服务器上的每一个线程都会执行不同的任务。Kafka会自动的协调工作,为每个任务分配属于他们的分区,每个任务独自处理自己的分区,并维护与聚合操作相关的本地状态。
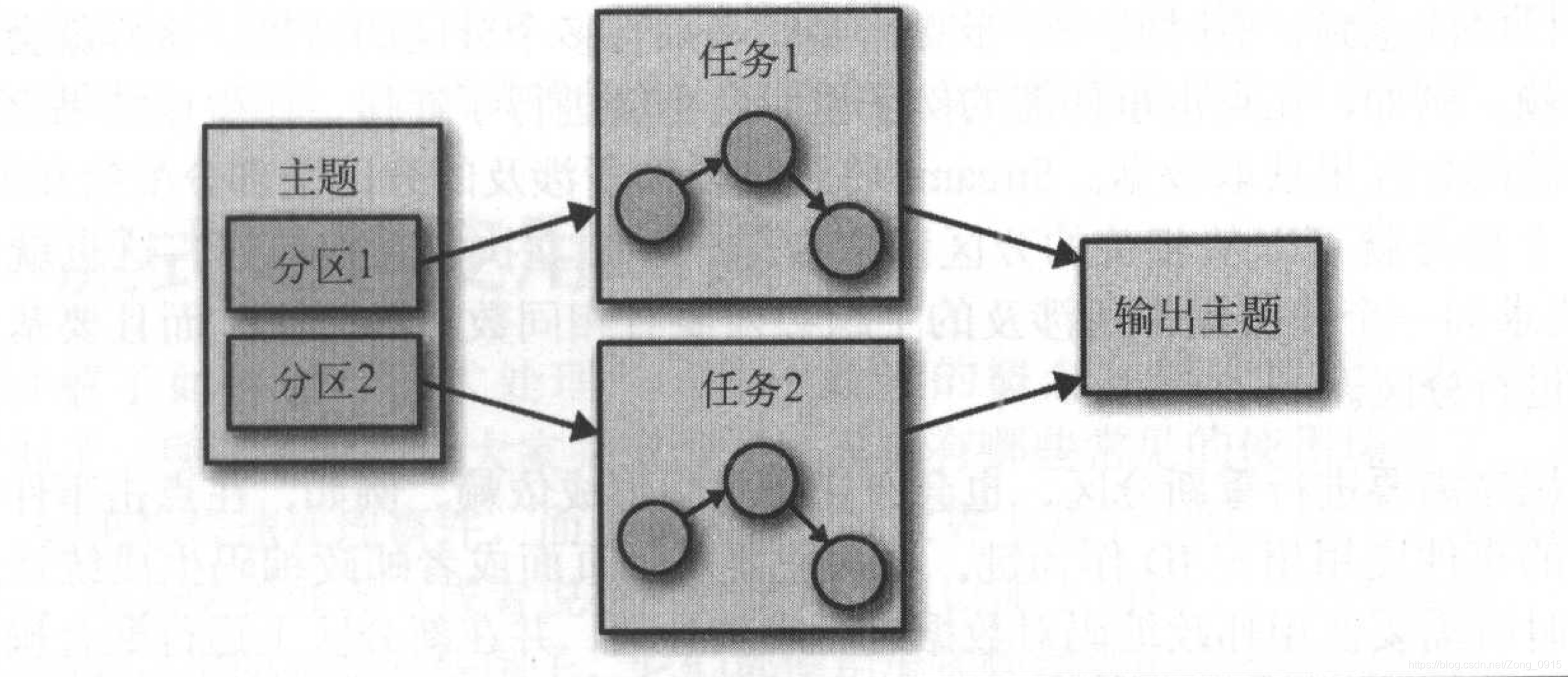
如图:处理任务可以运行在多个线程和多个服务器上。
总结
本文大概讲了这么几个点:
- 流式处理的相关概念和不同场景下的设计模式。
- 一个简单的Kafka Streams的字数统计Demo。
- 相关的拓扑图及其伸缩性。