前言
这篇博客是纪念自己第一次处理水文领域的数据,可能处理方式上有点生疏,甚至有些不当的地方,但实实在在是自己摸索出来的一种方法,后面我会把伪批量化的源码也开源出来,希望能够帮助那些跟我一样在这方面刚入门的小白。
数据介绍
本次实验用到的数据是来自 中国国家级地面气象站基本气象要素日值数据集(V3.0),包含了中国基本气象站、基准气候站、一般气象站在内的主要2474个站点1951年1月至最新本站气压、气温、降水量、蒸发量、相对湿度、风向风速、日照时数和0cm地温要素的日值数据。
因为我主要需要用到的是降水量,所以就选取了降水量的数据集来处理,其他的气象要素数据方法也是类似的,换汤不换药。
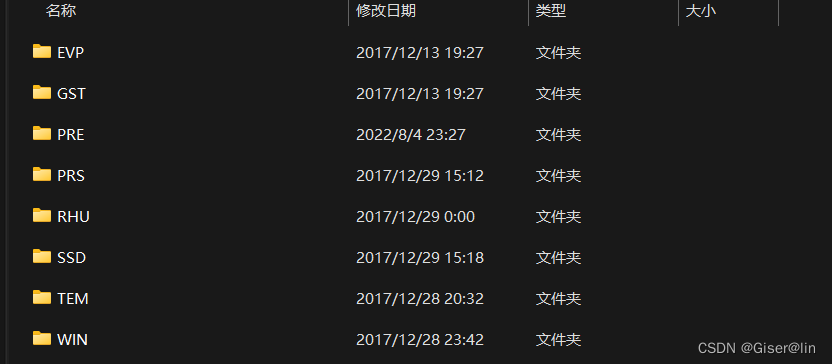
| 1级目录 | 文件名 |
|---|---|
| PRS | SURF_CLI_CHN_MUL_DAY-PRS-10004-YYYYMM.TXT(本站气压) |
| TEM | SURF_CLI_CHN_MUL_DAY-TEM-12001-YYYYMM.TXT(气温) |
| RHU | SURF_CLI_CHN_MUL_DAY-RHU-13003-YYYYMM.TXT(相对湿度) |
| PRE | SURF_CLI_CHN_MUL_DAY-PRE-13011-YYYYMM.TXT(降水) |
| EVP | SURF_CLI_CHN_MUL_DAY-EVP-13240-YYYYMM.TXT(蒸发) |
| WIN | SURF_CLI_CHN_MUL_DAY-WIN-11002-YYYYMM.TXT(风向风速) |
| SSD | SURF_CLI_CHN_MUL_DAY-SSD-14032-YYYYMM.TXT(日照) |
| GST | SURF_CLI_CHN_MUL_DAY-GST-12030-0cm-YYYYMM.TXT(0cm地温) |
处理思路
预处理
- 从数据命名的介绍中,我们可以知道每个TXT文件的命名都包含了类型、年份、月份等信息,如果我们一次性读取所有的TXT(1951~2015年)进来,一方面会增加系统运行的负担,另一方面处理完的分类也是一个问题,所以不如按照文件命名里的时间信息先对文件进行一个预分类,通过建立各个年份的文件夹对不同年份的数据进行存放,这里我准备用一个分类函数来实现这个预处理。
处理过程
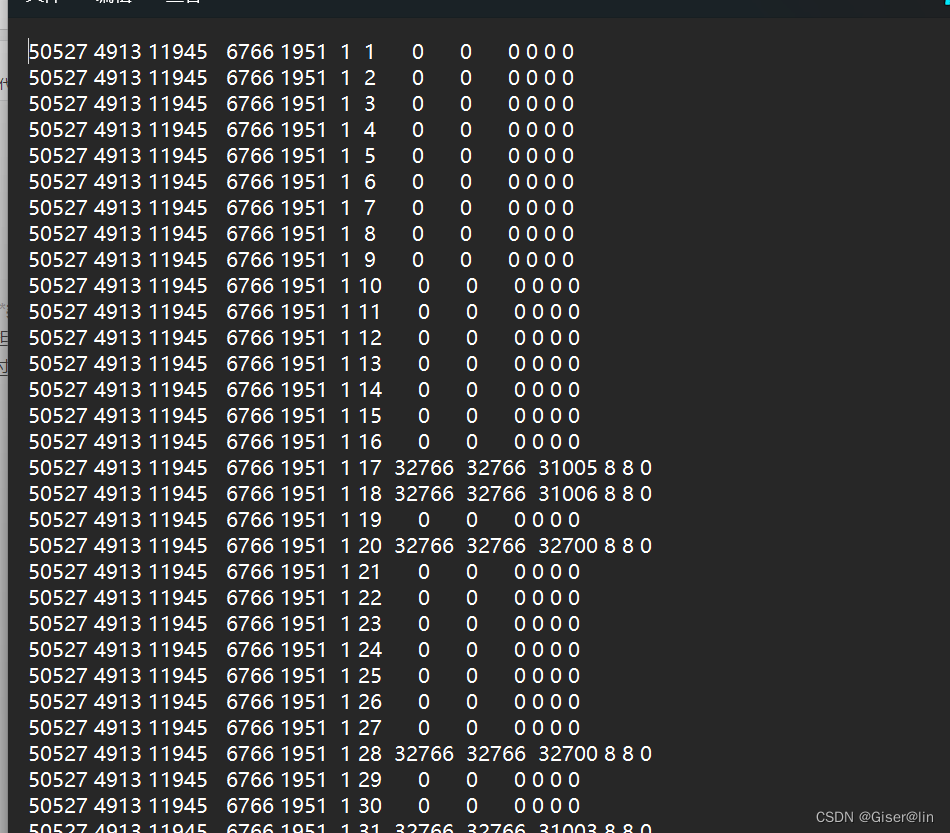
- 从文本数据包含的数据来看,首先我们需要把每一列的含义弄清楚,尤为注意每一列数据的单位。
- 筛选出核心数据列,每个文本数据都包含13列数据,但并非全部列都是我们关心的,例如质量控制码、非核心的统计指标,这些均可以筛选去掉,增加数据的可读性。
- 通过检查每个站点的信息,包括站号、经纬度、高程、日期等信息,发现这些基本信息都很齐全,因此我们可以用这几列来进行分组、聚合等操作,不用担心被缺失值或异常值所困扰,但值得注意的是每一年甚至每个月的站点都会有增加或者减少的现象。
处理后
这里主要指处理完之后数据的存放位置和存放形式。
最后的输出结果有day,month,year三个文件夹,分别存储了处理好的日值、月值、年度累计降水数据。
数据处理
构建分类函数
- 在构建函数之前,导入处理需要的一些库,第一次用python的朋友记得先安装一下~
#导入所需的库
import os #操作系统路径、文件等常用的库
import shutil #能够将文件移动到指定路径下的库
import pandas as pd #科学计算届的老熟人
import numpy as np # pandas的好基友
- 为了实现对数据进行存放,这里起码需要一个参数,即待处理数据所在的路径,因此我在这里构建参数为路径的函数:
def Classify(path):
#设置数据集的路径,告诉python我们要对哪里的数据进行分类,chdir--change dir改变路径的缩写
os.chdir(path)
# getcwd -- get work dir 得到工作路径,就是查看一下当前的工作路径
os.getcwd()
# os.listdir()可以读取路径下的所有数据,并且保存成列表形式
Total_File = os.listdir(path)
# 取出命名中的年份信息 即i[-10:-6],用这个特征来进行分年份存放对应的文件
for i in Total_File:
year = i[-10:-6]
#将当前文件夹路径与对应年份相黏贴,构成每个年份文件夹的完整路径
year_Path = path+'\\'+year
#检查当前文件下有没有对应年份的文件夹,若没有的话即创建
if not os.path.exists(year_Path):
os.mkdir(year_Path)
#如果已经存在对应年份的文件夹,则根据文件的年份信息进行分类
if(year == year_Path[-4:]):
# shutil.move(源文件,指定路径):递归移动一个文件
shutil.move(i,year_Path)
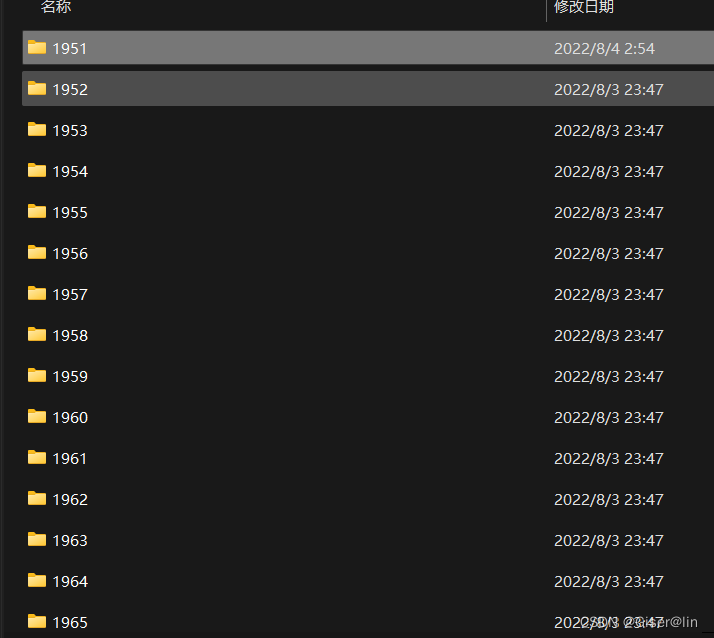
- 运行完上面的代码之后,你会发现原本统一存放的文本数据变成了下面这个样子,这样就证明创建并分类成功了,但需要注意的地方是,上面的代码
os.mkdir(year_Path)是在文件夹不存在的情况下才会创建,如果已经存在了相应的文件夹,再次运行的时候就会报错提示你已经有该文件了。
后面的话当然是读取指定年份下文件夹里的数据啦,事不宜迟,直接开搞!
构建核心处理函数
- 为了尽可能地方便后面进行批量化操作,我们可以设置一个参数year,通过改变这个year来读取不同年份的文件夹,当然,还需要包含读取路径和最后文件的保存路径这两个必要的参数啦~毕竟路径这东西因人而异嘛
def ChinaDayPRE(path,year,out):
"""
path:读取的文件夹路径
year:需要处理的年份
out:需要保存的文件路径
"""
os.chdir(out)
if not os.path.exists('day'):
os.mkdir('day')
if not os.path.exists('month'):
os.mkdir('month')
if not os.path.exists('year'):
os.mkdir('year')
- 其次,在每个年份的文件夹里,我们可以看出这里有十二个文本文件,每个文件对应不同的月份。参考了一些博主的处理方法后,我觉得用pandas库将每个月的数据都读取成DataFrame格式,并用一个列表存储这十二个月份的数据框,事不宜迟,来看看怎么实现!
# 读取某个年份的文件夹进行单年份数据处理
file_Path = path +'\\'+str(year)
l = os.listdir(file_Path)
# 设置一个列表来存放当前年份的十二个月份数据
Day_list = []
for y in range(len(l)):
file = file_Path+'\\'+l[y]
#将数据添加进列表中
col = ['站号','纬度','经度','测量海拔','年','月','日','20-8时降水量','8-20降水量',
'20-20累计降水量','20-8时降水量控制码','8-20时降水量控制码','20-20时累计降水量控制码']
Day_list.append(pd.read_csv(file,sep='\s+',names= col))
- 通过上面的函数就将十二个月份的数据框存在了Day_list的列表中,后面就是对每个月份中的数据进行数据清洗,这里先不要着急格式转换、列筛选等,因为从帮助文档里面我们可以知道,每份表里都有质量控制的列,并且也有每一列的含义,这个务必先弄清楚。从下面的资料可以知道,我们只需要筛选出质量控制码为0的行即可。我相信可疑或者未进行过质量控制的数据你用着也不放心😂
| 质量控制码 | 含义 |
|---|---|
| 0 | 数据正确 |
| 1 | 数据可疑 |
| 8 | 数据缺失或无观测任务 |
| 9 | 未进行质量控制 |
根据描述文件的介绍,数据里的第10列为累计降水量,第13列为质量控制码,因此我们可以针对第十三列进行筛选,针对第十列来进行累积计算
# 根据第十三列的质量控制码,筛选出正确的数据,索引从0开始
for i in range(len(year_list)):
year_list[i] = year_list[i][year_list[i]['20-20时累计降水量控制码'].isin([0])]
# 检查累计降水量该列是否全为正确数据
for i in range(len(year_list)):
if year_list[i]['20-20时累计降水量控制码'].max() == 0:
flag = True
print(flag)
- 筛选出正确的数据后,我们就可以大胆地进行异常值处理和格式转换等操作了。下面进行异常值处理和经纬度的处理,这里面有两个需要注意的地方,一个是32766表示数据缺失,我们可以用-999来标识;另一个是原始数据的经纬度单位为度、分,即4539表示45°39′的意思,而我们一般需要将它转成度的形式,即45°+39/60 = 45.65°,这里我看的一些博客里并没有注意到这点。
异常值处理
| 代码 | 含义 |
|---|---|
| 32700 | 表示降水"微量" |
| 32XXX | XXX 为纯雾露霜 |
| 31XXX | XXX 为雨和雪的总量 |
| 30XXX | XXX 为雪量(仅包括雨夹雪,雪暴) |
经纬度处理
| 序号 | 中文名 | 数据类型 | 单位 |
|---|---|---|---|
| 1 | 区站号 | Number(5) | |
| 2 | 纬度 | Number(5) | (度、分) |
| 3 | 经度 | Number(6) | (度、分) |
| 4 | 观测场拔海高度 | Number(7) | 0.1米 |
# 异常值和经纬度处理
# 备份一份数据,保存异常值处理之前的list
Day_process = Day_list
# 写一个度分秒转换的函数
def dfToDu(data):
D = data.astype(int)
F = (data - D)*100/60
F = round(F,2)
data = D+F
return data
for i in range(len(Day_process)):
Day_process[i].loc[Day_process[i]['20-20累计降水量'] == 32766,'20-20累计降水量'] = -999
Day_process[i].loc[Day_process[i]['20-20累计降水量'] == 32700,'20-20累计降水量'] = 0
Day_process[i].loc[(Day_process[i]['20-20累计降水量'] >= 30000) & (Day_process[i]['20-20累计降水量'] < 31000),'20-20累计降水量']= Day_process[i]['20-20累计降水量']-30000
Day_process[i].loc[(Day_process[i]['20-20累计降水量'] >= 31000) & (Day_process[i]['20-20累计降水量'] < 32000),'20-20累计降水量'] = Day_process[i]['20-20累计降水量']-31000
Day_process[i].loc[(Day_process[i]['20-20累计降水量'] >= 32000) & (Day_process[i]['20-20累计降水量'] < 33000),'20-20累计降水量'] = Day_process[i]['20-20累计降水量']-32000
Day_process[i]['20-20累计降水量'] = Day_process[i]['20-20累计降水量']*0.1
#经纬度处理
# 经纬度除以100后,小数前两位是度,可以用i取整的方法提取出来,小数后两位是分,可以乘回100得到正常的值
Day_process[i]['经度'] = Day_process[i]['经度']*0.01
Day_process[i]['纬度'] = Day_process[i]['纬度']*0.01
#对经纬度进行单位转换
Day_process[i]['经度'] = dfToDu(Day_process[i]['经度'])
Day_process[i]['纬度'] = dfToDu(Day_process[i]['纬度'])
- 上文提到并非所有的列都有重要的价值,因此下一步我们就要筛选出核心的列并进行导出。
# 去除一些冗余的列,保留站点的信息和累计降水量
daily = Day_process[0][['站号','纬度','经度','测量海拔','年','月','日','20-20累计降水量']]
for i in range(1,12):
daily = pd.concat([daily,Day_process[i][['站号','纬度','经度','测量海拔','年','月','日','20-20累计降水量']]],join='inner',axis = 0)
#导出路径设置
OutDaily = out+'/day/'+str(year)+'_day.csv'
# 日值降水量数据
daily.to_csv(OutDaily,encoding='gbk',index = False)
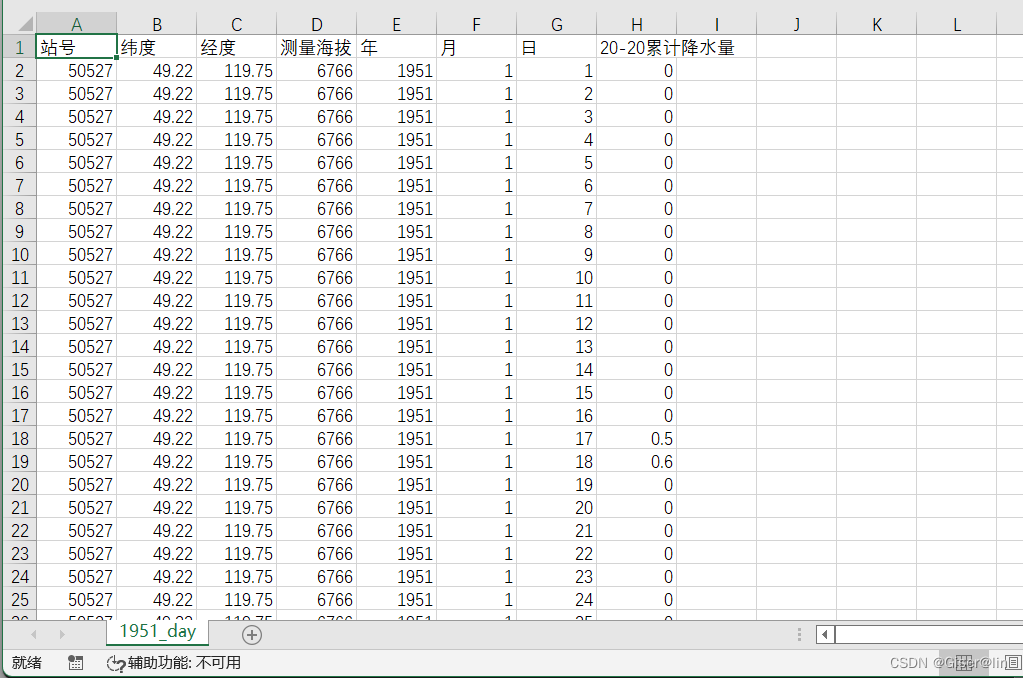
让我们来看看处理完的日值数据!
数据的再加工(月度、年度)
其实正常而言经过上述的处理已经得到一份干净的数据了,但科研人除了需要用到日值的数据,还有可能需要用到月度、年度的累计降水数据,因此我们可以稍微再做一点加工,用日值数据进行分组和聚合操作,得到对应的加工数据。
# 处理成月累计数据
month_data = daily.groupby(['站号','月']).agg({'20-20累计降水量':np.sum,'年':np.mean,'测量海拔':np.mean,'纬度':np.mean,'经度':np.mean})
#导出月度累计数据
OutMonth = out+'/month/'+str(year)+'_month.csv'
month_data.to_csv(OutMonth,encoding='gbk')
#年度数据合成
year_data=month_data.groupby(['站号']).agg({'20-20累计降水量':np.sum,'年':np.mean,'测量海拔':np.mean,'纬度':np.mean,'经度':np.mean})
#导出年度数据
OutYear = out + '/year/'+str(year)+'_year.csv'
year_data.to_csv(OutYear,encoding='gbk')
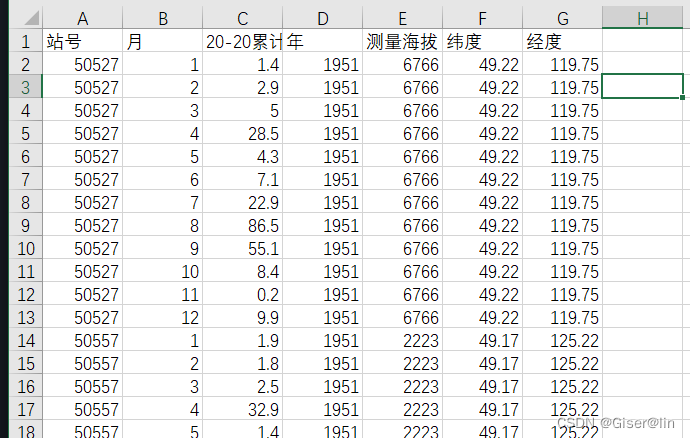
处理成果
处理完之后,我们可以看到指定路径下多了三个文件夹,分别存储日值、月度和年度的数据。
完整代码
# 导入所需的库
import os
import shutil
import pandas as pd
import numpy as np
def Classify(path):
#设置当前的工作路径
os.chdir(path)
os.getcwd()
Total_File = os.listdir(path)
# 取出命名中的年份信息 即i[-10:-6],用这个特征来进行分年份存放对应的文件
for i in Total_File:
year = i[-10:-6]
#将当前文件夹路径与对应年份相黏贴,构成每个年份文件夹的完整路径
year_Path = path+'\\'+year
#检查当前文件下有没有对应年份的文件夹,若没有的话即创建
if not os.path.exists(year_Path):
os.mkdir(year_Path)
#如果已经存在对应年份的文件夹,则根据文件的年份信息进行分类
if(year == year_Path[-4:]):
# shutil.move(源文件,指定路径):递归移动一个文件
shutil.move(i,year_Path)
def ChinaDayPRE(path,year,out):
"""
path:读取的文件夹路径
year:需要处理的年份
out:需要保存的文件路径
"""
os.chdir(out)
if not os.path.exists('day'):
os.mkdir('day')
if not os.path.exists('month'):
os.mkdir('month')
if not os.path.exists('year'):
os.mkdir('year')
# 读取某个年份的文件夹进行单年份数据处理
file_Path = path +'\\'+str(year)
l = os.listdir(file_Path)
# 设置一个列表来存放当前年份的十二个月份数据
Day_list = []
for y in range(len(l)):
file = file_Path+'\\'+l[y]
#将数据添加进列表中
col = ['站号','纬度','经度','测量海拔','年','月','日','20-8时降水量','8-20降水量',
'20-20累计降水量','20-8时降水量控制码','8-20时降水量控制码','20-20时累计降水量控制码']
Day_list.append(pd.read_csv(file,sep='\s+',names= col))
# 根据第十一列的质量控制码,筛选出正确的数据,索引从0开始
for i in range(len(Day_list)):
Day_list[i] = Day_list[i][Day_list[i]['20-20时累计降水量控制码'].isin([0])]
# 检查累计降水量该列是否全为正确数据
for i in range(len(Day_list)):
if Day_list[i]['20-20时累计降水量控制码'].max() == 0:
flag = True
# print(flag)
# 异常值和经纬度处理
# 备份一份数据,保存异常值处理之前的list
Day_process = Day_list
# 写一个转换函数
def dfToDu(data):
D = data.astype(int)
F = (data - D)*100/60
F = round(F,2)
data = D+F
return data
for i in range(len(Day_process)):
Day_process[i].loc[Day_process[i]['20-20累计降水量'] == 32766,'20-20累计降水量'] = -999
Day_process[i].loc[Day_process[i]['20-20累计降水量'] == 32700,'20-20累计降水量'] = 0
Day_process[i].loc[(Day_process[i]['20-20累计降水量'] >= 30000) & (Day_process[i]['20-20累计降水量'] < 31000),'20-20累计降水量']= Day_process[i]['20-20累计降水量']-30000
Day_process[i].loc[(Day_process[i]['20-20累计降水量'] >= 31000) & (Day_process[i]['20-20累计降水量'] < 32000),'20-20累计降水量'] = Day_process[i]['20-20累计降水量']-31000
Day_process[i].loc[(Day_process[i]['20-20累计降水量'] >= 32000) & (Day_process[i]['20-20累计降水量'] < 33000),'20-20累计降水量'] = Day_process[i]['20-20累计降水量']-32000
Day_process[i]['20-20累计降水量'] = Day_process[i]['20-20累计降水量']*0.1
#经纬度处理
# 经纬度除以100后,小数前两位是度,可以用i取整的方法提取出来,小数后两位是分,可以乘回100得到正常的值
Day_process[i]['经度'] = Day_process[i]['经度']*0.01
Day_process[i]['纬度'] = Day_process[i]['纬度']*0.01
Day_process[i]['经度'] = dfToDu(Day_process[i]['经度'])
Day_process[i]['纬度'] = dfToDu(Day_process[i]['纬度'])
# 去除一些冗余的列,保留站点的信息和累计降水量
daily = Day_process[0][['站号','纬度','经度','测量海拔','年','月','日','20-20累计降水量']]
for i in range(1,12):
daily = pd.concat([daily,Day_process[i][['站号','纬度','经度','测量海拔','年','月','日','20-20累计降水量']]],join='inner',axis = 0)
# 日值降水量数据
OutDaily = out+'/day/'+str(year)+'_day.csv'
daily.to_csv(OutDaily,encoding='gbk',index = False)
# 处理成月累计数据
month_data = daily.groupby(['站号','月']).agg({'20-20累计降水量':np.sum,'年':np.mean,'测量海拔':np.mean,'纬度':np.mean,'经度':np.mean})
#导出月度累计数据
OutMonth = out+'/month/'+str(year)+'_month.csv'
month_data.to_csv(OutMonth,encoding='gbk')
#年度数据合成
year_data=month_data.groupby(['站号']).agg({'20-20累计降水量':np.sum,'年':np.mean,'测量海拔':np.mean,'纬度':np.mean,'经度':np.mean})
#导出年度数据
OutYear = out + '/year/'+str(year)+'_year.csv'
year_data.to_csv(OutYear,encoding='gbk')
#修改为数据集的文件夹
path = r'D:\New Desktop\SURF_CLI_CHN_MUL_DAY_V3.0\SURF_CLI_CHN_MUL_DAY_V3.0\datasets\PRE'
#修改输出的文件路径
outpath = 'D:/New Desktop'
#先对未处理的数据进行分类
Classify(path)
#分类后对所有年份进行批量处理
for year in range(1951,2016):
ChinaDayPRE(path,year,outpath)
print('Successful!')
总结
- 从处理难度来看,处理起来不是很费劲,主要原因是数据的质量较高,缺失数据的数量较少,其次每种特征值都有详细的说明。
- 从处理方式来看,上述的分类-再分年份处理并非是唯一解,其实也可以统一处理再分类,哪种效率更高目前还不知道。另外,除了按照年份进行分类,还可以处理成每个站点一份表格,这样对于观测一个站点的长时间序列降水变化而言会更为方便。
- 从方法的可拓展性上来看,有些地方例如列名、异常值的列数都是被写死的,虽然针对降水量这份数据而言是方便的,但其他类型的数据估计会有不同,这样看拓展性会大打折扣。