一 : 学习目标
- 认识多线程
- 掌握多线程程序的编写
- 掌握多线程的状态
- 掌握什么是线程不安全及解决思路
- 掌握synchronized、volatile关键字
二 : 初识线程
2.1 线程概念
线程(thread)是操作系统能够进行运算调度的最小单位.它被包含在进程之中,是进程中的实际运作单位.一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务.
在计算机中 , 为了充分利用CPU的多核资源 , 我们引入了并发编程 . 使用多进程这种编程模型 , 完全可以做到并发编程 , 且能够使CPU多核被充分利用 .但有些场景下 , 需要频繁地创建/销毁进程 , 此时就比较低效 .
例如我们写一个服务器程序 , 需要在同一时间给多个客户端提供服务 , 此时就需要用到并发编程了 . 典型做法是给每个客户端分配一个进程 , 提供一对一的服务 . 但是创建/销毁进程 , 本身就是一个比较低效的操作 . 需要经过多个步骤 :
1.创建PCB ;
2.分配系统资源 ;
3.把PCB加入到内核的双向链表中 .
其中 , 分配系统资源需要在系统内核资源管理模块 , 进行一次遍历操作 .
为了提高这个场景下的效率 , 就引入了"线程" (线程又叫"轻量级进程") .
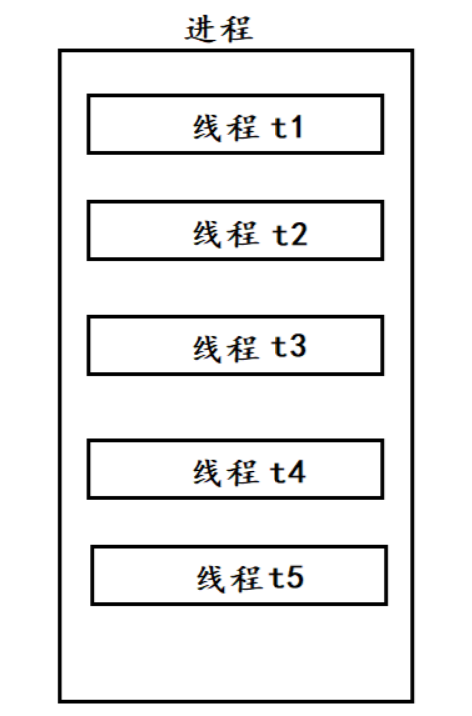
进程是线程的容器 . 一个进程里,通常包含多个线程 .
每个线程其实也有自己的PCB,一个进程里可能就对应多个PCB .
同一个进程里的多个线程之间 , 共用同一份系统资源 . 这就意味着 , 创建新线程 , 不需要重新给他分配系统资源 , 只需要复用之前的即可 . 因此 , 创建线程只需要 :
1.创建PCB ;
2.把PCB加入到内核的双向链表中 .

2.2 进程和线程之间的区别
Q : 进程和线程之间的区别 ?
A :
- 进程是包含线程的 , 线程是在进程内部的 ;
- 每个进程有独立的虚拟地址空间(进程之间的资源是独立的) , 也有自己独立的文件描述符表 ; 同一个进程的多个线程之间 , 则共用这一份虚拟地址空间和文件描述符表 .
- 进程是操作系统中资源分配的基本单位 , 线程是操作系统中调度执行的基本单位 .
- 多个进程同时执行的时候 , 如果一个进程挂了 , 一般不会影响的别的进程 . 同一个进程内的多个线程之间 , 如果一个线程挂了 , 很可能会把整个进程带走 , 其他同进程中的线程也就没了 .
2.3 Java的线程和操作系统线程的关系
线程是操作系统中的概念 . 操作系统内核实现了线程这样的机制, 并且对用户层提供了一些 API 供用户使用(例如 Linux 的 pthread 库).
Java 标准库中 Thread 类可以视为是对操作系统提供的 API 进行了进一步的抽象和封装 .
Thread实例是java中对于线程的表示,实际上想要真正跑起来,还需要操作系统里面的线程!创建好Thread,此时系统里面还没有线程 .直到调用start方法,操作系统才真的创建了线程,并进行执行 .
操作系统创建线程的步骤:
1.创建PCB;
2.把PCB加入到链表里~
2.4 线程优点
1.线程的优点
- 创建一个新线程的代价要比创建一个新进程小的多;
- 与进程之间的切换相比 , 线程之间的切换需要操作系统做的工作要少得多;
- 线程占用的资源要比进程少得多;
- 能够充分利用多处理器的可并行数量;
- 在等待慢速I/O操作结束的同时 , 程序可以执行其他的计算任务;
- 计算密集型应用,为能在多处理器上运行 , 将计算分解到多个线程中实现;
- I/O密集型应用,为了提高性能,将I/O操作重叠 , 线程可以同时等待不同的I/O操作.

2.实例1
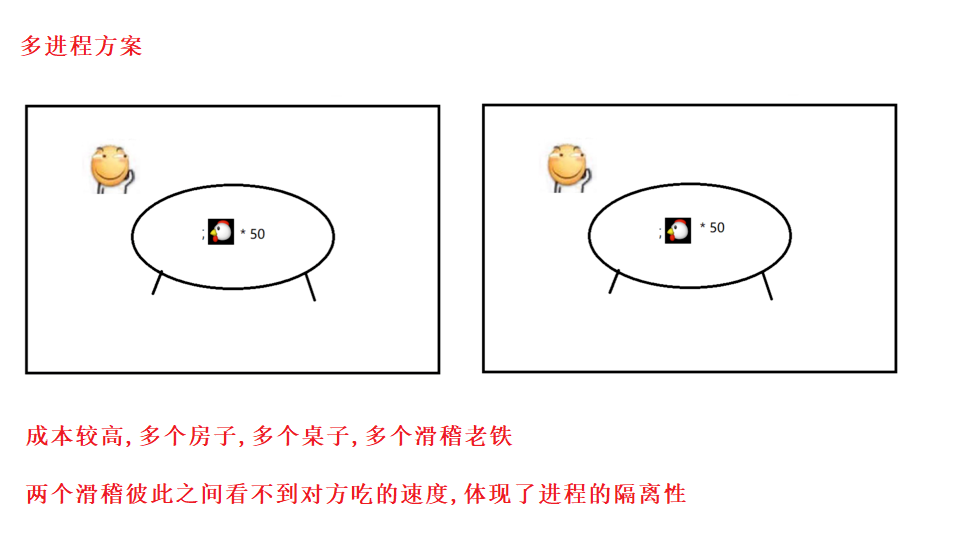
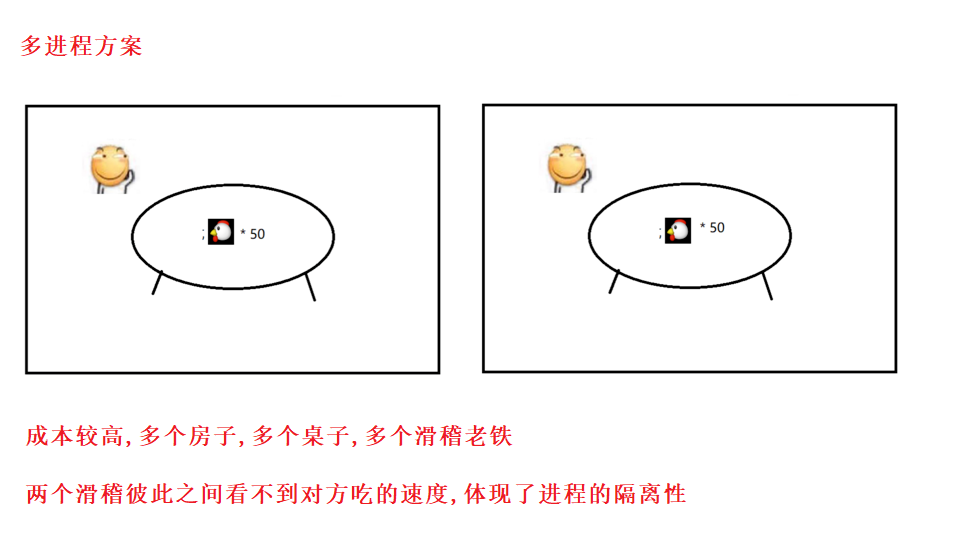
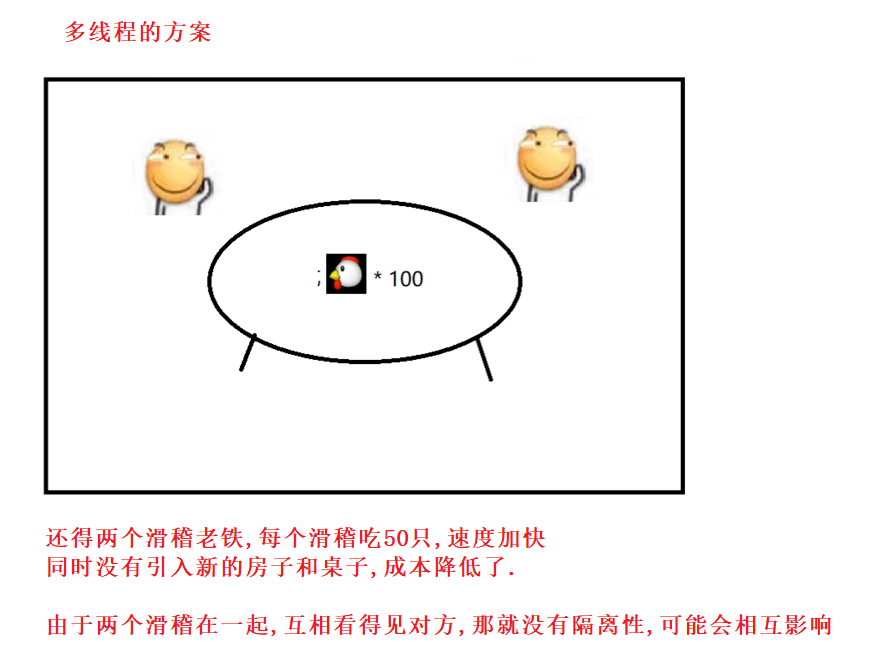
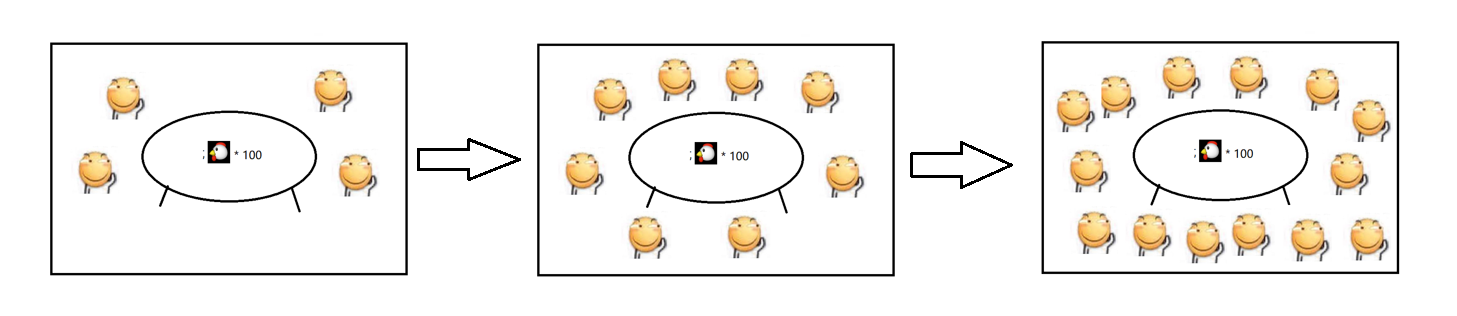

此时还涉及线程安全问题 .

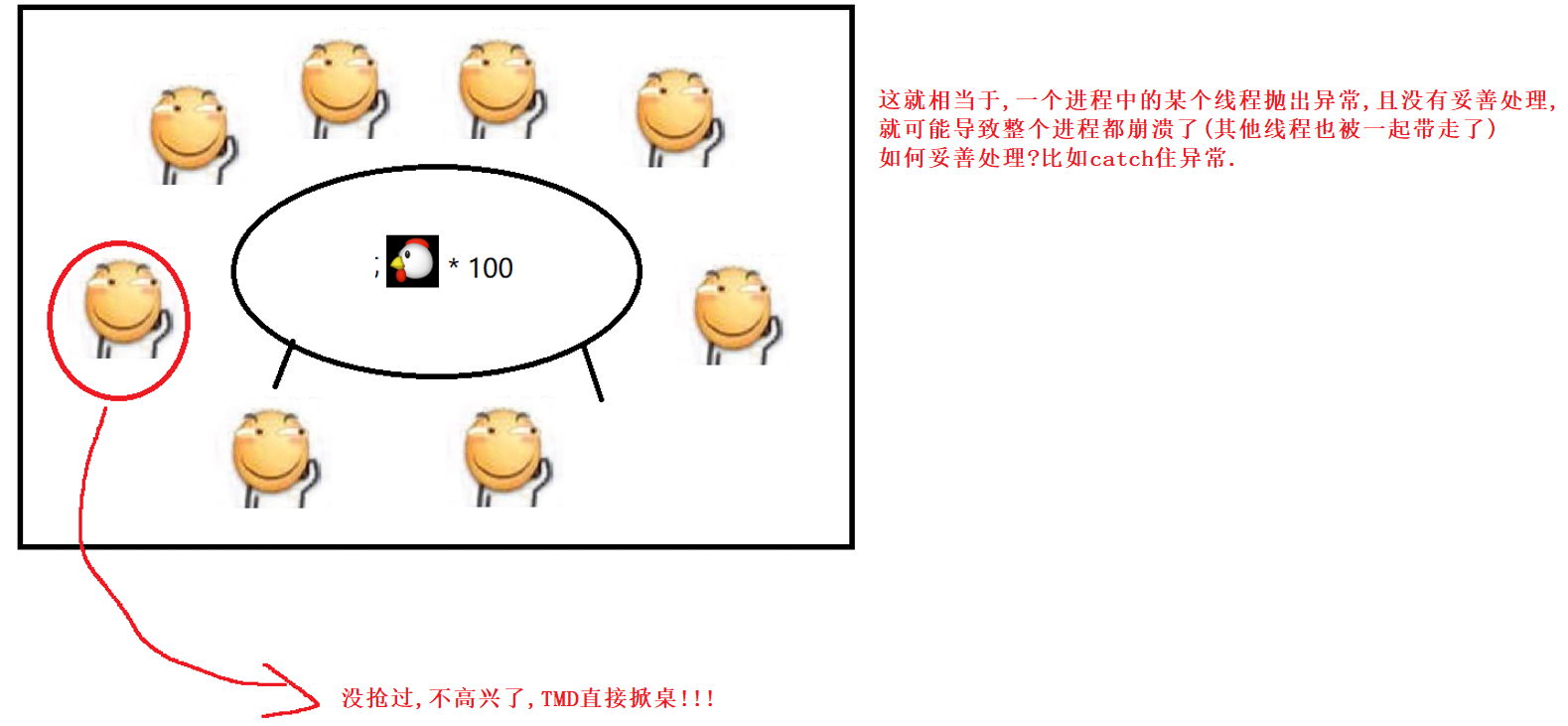

3.实例2
(建议了解本文三 , 四两节内容后回看这部分示例)
能够更充分的利用CPU的多核资源.
package Thread;
public class Demo6 {
// 1. 单个线程, 串行的, 完成 20 亿次自增.
// 2. 两个线程, 并发的, 完成 20 亿次自增.
private static final long COUNT = 20_0000_0000;
private static void serial() {
// 需要把方法执行的时间给记录下来.
// 记录当前的毫秒级时间戳.
long beg = System.currentTimeMillis();
int a = 0;
for (long i = 0; i < COUNT; i++) {
a++;
}
a = 0;
for (long i = 0; i < COUNT; i++) {
a++;
}
long end = System.currentTimeMillis();
System.out.println("单线程消耗的时间: " + (end - beg) + " ms");
}
private static void concurrency() {
long beg = System.currentTimeMillis();
Thread t1 = new Thread(() -> {
int a = 0;
for (long i = 0; i < COUNT; i++) {
a++;
}
});
Thread t2 = new Thread(() -> {
int a = 0;
for (long i = 0; i < COUNT; i++) {
a++;
}
});
t1.start();
t2.start();
try {
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println("并发执行的时间: " + (end - beg) + " ms");
}
public static void main(String[] args) {
serial();
concurrency();
}
}
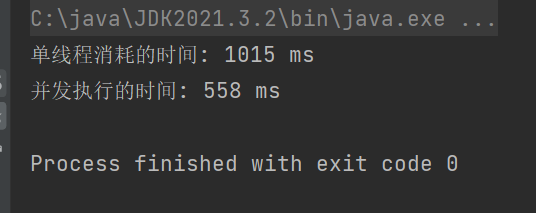

分析 :


4.join用法
线程之间的执行顺序是完全随机的,看系统的调度!join就是一种确定线程执行顺序的辅助手段!!通过joni可以控制两个线程的结束顺序!!!!但是线程的开始执行顺序是无法确定的!!!

示例一 : t2线程等待t1线程结束 , main线程等待t2线程结束 .
package Thread;
public class Demo11 {
private static Thread t1 = null;
private static Thread t2 = null;
public static void main(String[] args) throws InterruptedException {
System.out.println("main begin");
t1 = new Thread(()->{
System.out.println("t1 begin");
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("t1 end");
});
t1.start();
t2 = new Thread(()->{
System.out.println("t2 begin");
try {
t1.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("t2 end");
});
t2.start();
t2.join();
System.out.println("main end");
}
}
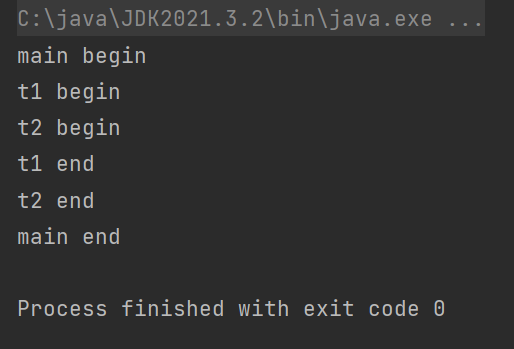
示例二 : main线程运行t1 和1t2 , t1和t2随机调度 .
package Thread;
//控制main线运行t1,t1执行完再执行t2
public class Demo12 {
public static void main(String[] args) throws InterruptedException {
System.out.println("main begin");
Thread t1 = new Thread(()->{
System.out.println("t1 begin");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("t1 end");
});
t1.start();
Thread t2 = new Thread(()->{
System.out.println("t2 begin");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("t2 end");
});
t2.start();
t1.join();
t2.join();
System.out.println("main end");
}
}

join还有一个带参数的版本 :
未来开发实际程序的时候 , 像这样的等待操作,一般都不会使用死等的方式 . 死等的方式有风险!!万一代码出了bug 没控制好,死等就容易让服务器"卡死”,无法继续工作.因为一个小问题就影响到全局 .
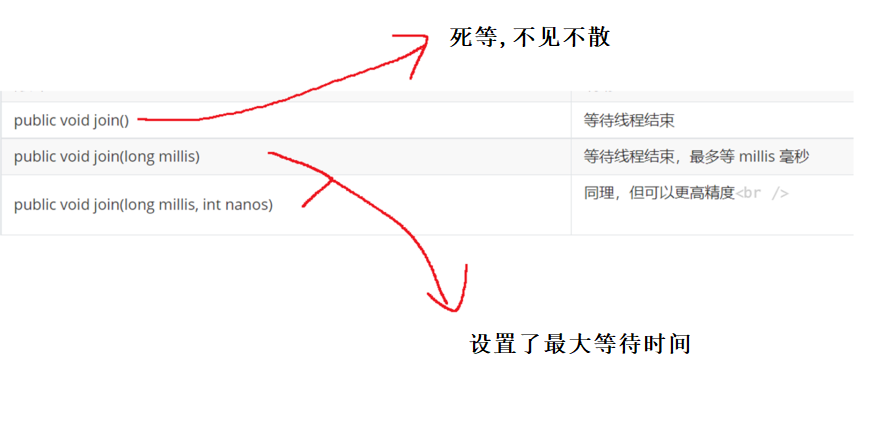
更多的是要等待的时候预期好最多等多久 , 如果时间到了还没有等来,就要做出一些措施!!
总结join的行为 :
- 如果被等待的线程还没执行完,就阻塞等待;
- 如果被等待的线程已经执行完了,就直接返回 .
2.5 多线程的应用场景

比如排核酸时候 , 排队的过程就是等待 , 类似于等待IO结束 , 此时同学们就打开青年大学习 , 顺便学一手 , 学习新思想 , 争做新青年 !!!


三 :第一个多线程程序

package Thread;
class MyThread1 extends Thread {
@Override
public void run() {
while (true) {
System.out.println("hello thread!");
}
}
}
public class Demo0 {
public static void main(String[] args) {
Thread t = new MyThread1(); //向上转型的写法
t.start();
while(true){
System.out.println("hello main!");
}
}
}
四 : 创建线程的五种方法
4.1 方法一
创建一个类继承Thread,重写run方法.这种写法,线程和任务内容是绑定在一起的.
package Thread;
class MyThread extends Thread {
@Override
public void run() {
while (true) {
System.out.println("hello thread!");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Demo1 {
public static void main(String[] args) {
// 创建一个线程
// Java 中创建线程, 离不开一个关键的类, Thread
// 一种比较朴素的创建线程的方式, 是写一个子类, 继承 Thread, 重写其中的 run 方法.
Thread t = new MyThread();
t.start();
while(true){
System.out.println("hello Thread!");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
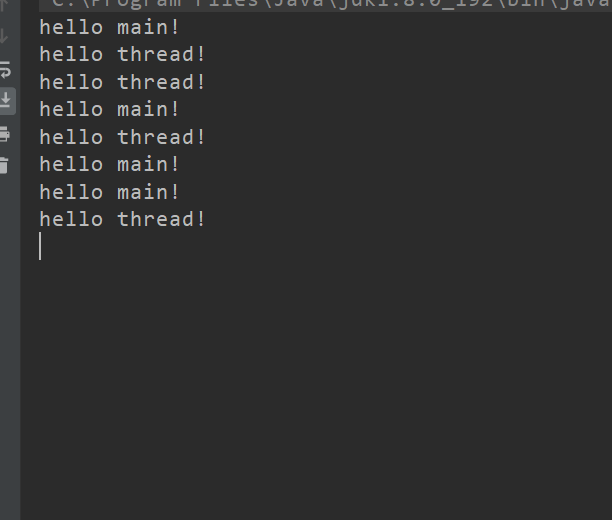

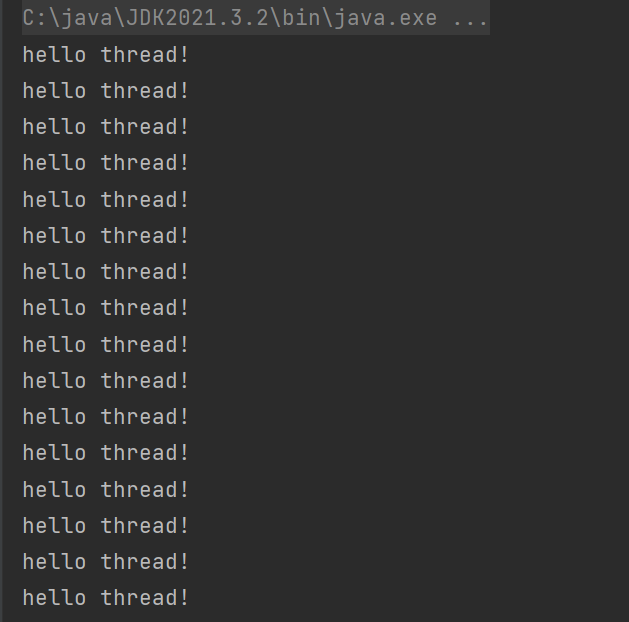
关于打印顺序 : 默认情况下,多个线程的执行顺序是随机的,是“无序”的,是随机调度的!
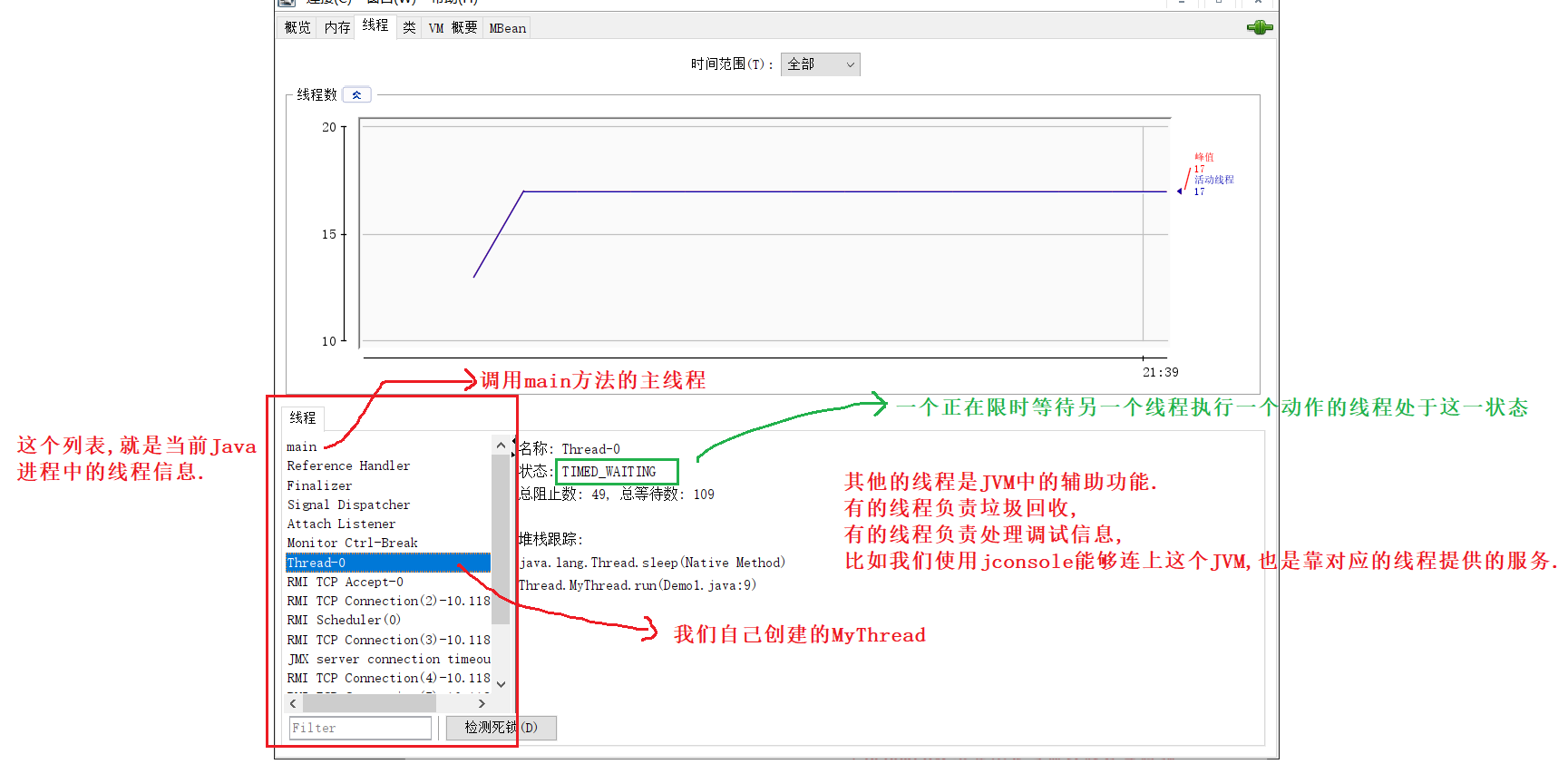
如何查看当前进程里的线程 ?
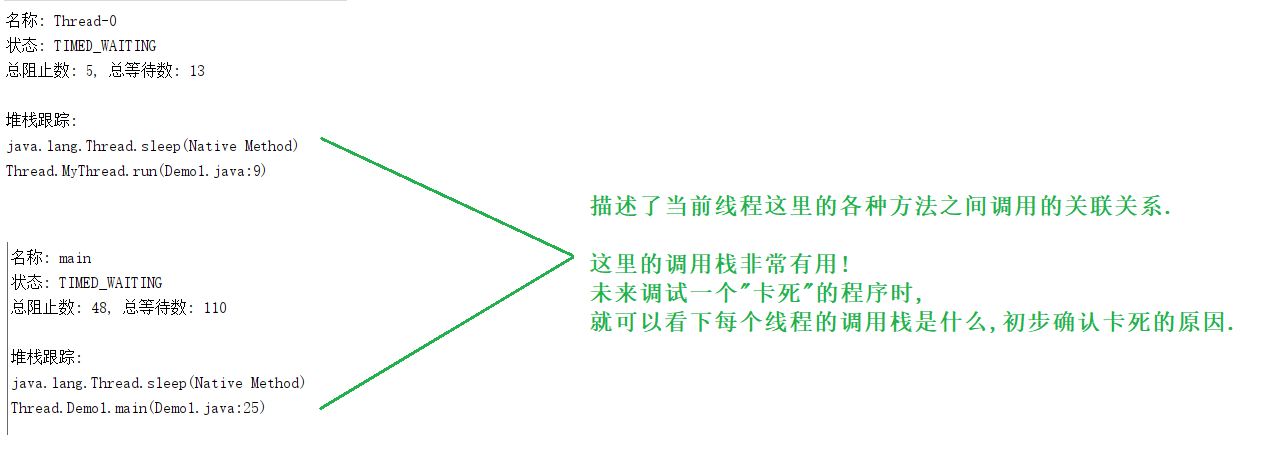
关于sleep()方法
为什么要捕获InterruptedException异常 ?
sleep(1000)就是要休眠1000ms , 但在休眠过程中 , 可能有一些意外 , 把这个线程提前唤醒了 , 此时就会触发这个终端异常 !
run和start的区别 ?
package Thread;
class MyThread extends Thread {
@Override
public void run() {
while (true) {
System.out.println("hello thread!");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Demo1 {
public static void main(String[] args) {
Thread t = new MyThread(); //向上转型的写法
//t.start();
t.run();
while(true){
System.out.println("hello main!");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
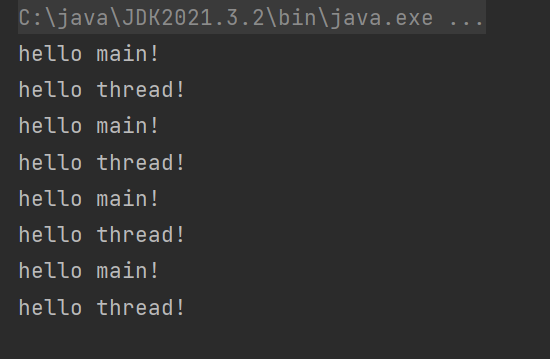
这时候没有打印hello main了 . 这说明 , run方法和start方法是有本质区别的 :
简单说,直接调用run方法,没有创建新的线程,而只是在之前的线程中,执行了run里面的内容.
使用start方法,则是创建新的线程,新的线程里面会调用run,新线程和旧线程之间是并发执行的关系.
详细总结 :

4.2 方法二
创建一个类,实现Runnable接口,重写run.
package Thread;
class MyRunnable implements Runnable{
@Override
public void run() {
while (true){
System.out.println("hello thread!");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Demo2 {
public static void main(String[] args) {
//创建线程
Runnable runnable = new MyRunnable();
Thread t = new Thread(runnable);
t.start();
while (true) {
System.out.println("hello main!");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}

代码要求 : “高内聚,低耦合” .

4.3 方法三
仍使用继承Thread类,但是不再显式继承,而是使用"匿名内部类" .
package Thread;
public class Demo3 {
public static void main(String[] args) {
Thread t = new Thread(){
@Override
public void run(){
while(true){
System.out.println("hello thread!");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
t.start();
while(true){
System.out.println("hello main!");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
4.4 方法四
Runnable接口 + 匿名内部类
package Thread;
public class Demo4 {
public static void main(String[] args) {
Thread t = new Thread(new Runnable() {
@Override
public void run() {
while (true){
System.out.println("hello thread!");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
t.start();
while(true){
System.out.println("hello main!");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
4.5 方法五
使用lambda表达式定义任务(推荐做法)
package Thread;
public class Demo5 {
public static void main(String[] args) {
Thread t = new Thread(() ->{
while(true){
System.out.println("hello thread!");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
while(true){
System.out.println("hello main!");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
lambda表达式的结构:
( )→{ } ,在{ }中写该线程需要执行的内容 .
五 : Thread
5.1 Thread的构造方法
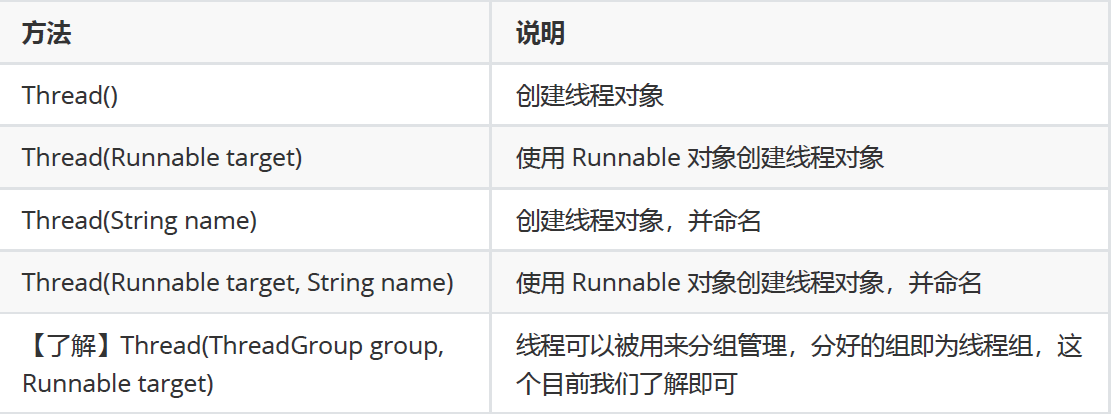
Thread t1 = new Thread();
Thread t2 = new Thread(new MyRunnable());
Thread t3 = new Thread("这是我的名字");
Thread t4 = new Thread(new MyRunnable(), "这是我的名字");
线程在操作系统内是没有名字的,只有一个身份标识 . 但是在java中,为了让程序员调试的时候方便理解这个线程是谁,就在操作系统里给对应的Thread对象加了名字 , 这个Thread对象和内核中的线程是一一对应的 .
这个名字对程序的执行没有任何影响,且多个线程可以有同样的名字,但这显然不利于调试 .
5.2 Thread的常见属性
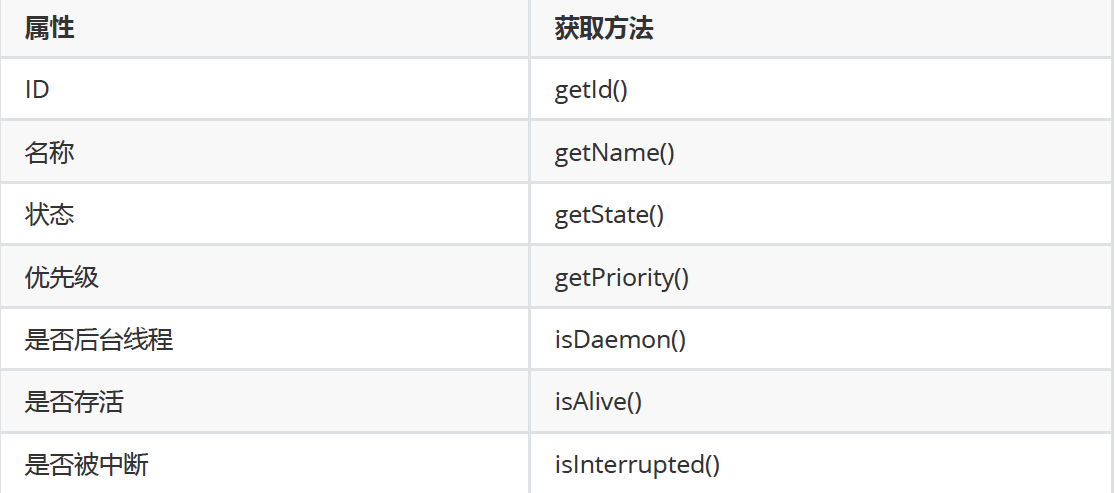


5.2.1 常见属性代码示例
package Thread;
public class Demo8 {
public static void main(String[] args) {
Thread t = new Thread(()->{
while (true){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},"我的线程");
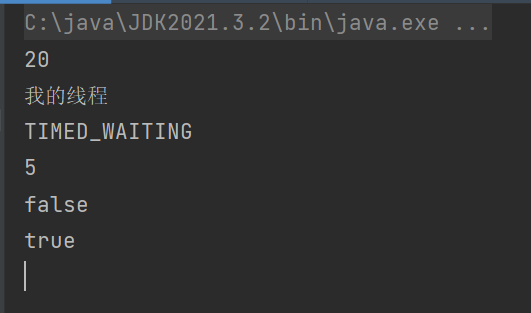
t.start();
System.out.println(t.getId());
System.out.println(t.getName());
System.out.println(t.getState());
System.out.println(t.getPriority());
System.out.println(t.isDaemon());
System.out.println(t.isAlive());
}
}
5.2.2 用一个boolean变量控制线程结束
package Thread;
//用一个布尔变量表示线程是否要结束
//这个变量是一个成员变量,不是局部变量
public class Demo9 {
private static boolean isQuit = false;
public static void main(String[] args) throws InterruptedException {
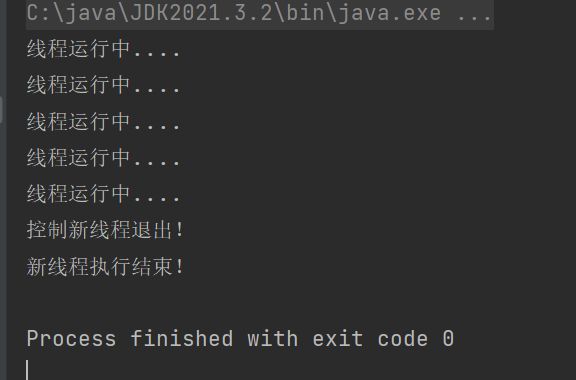
Thread t = new Thread(()->{
while(!isQuit){
System.out.println("线程运行中....");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("新线程执行结束!");
});
t.start();
Thread.sleep(5000);
System.out.println("控制新线程退出!");
isQuit = true;
}
}
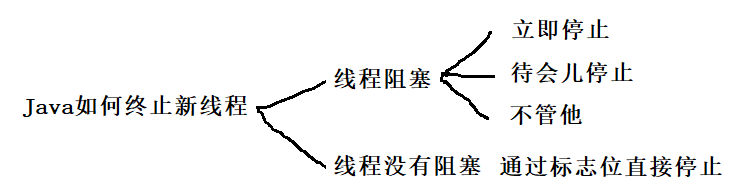
5.2.3 interrupt()方法
设置线程中断有专门的函数 , 即interrupt()方法 , 其作用是让线程尽快把入口方法执行结束 .
入口方法 : 指程序运行的起点 , 即main方法 .
package Thread;
public class Demo10 {
public static void main(String[] args) throws InterruptedException {
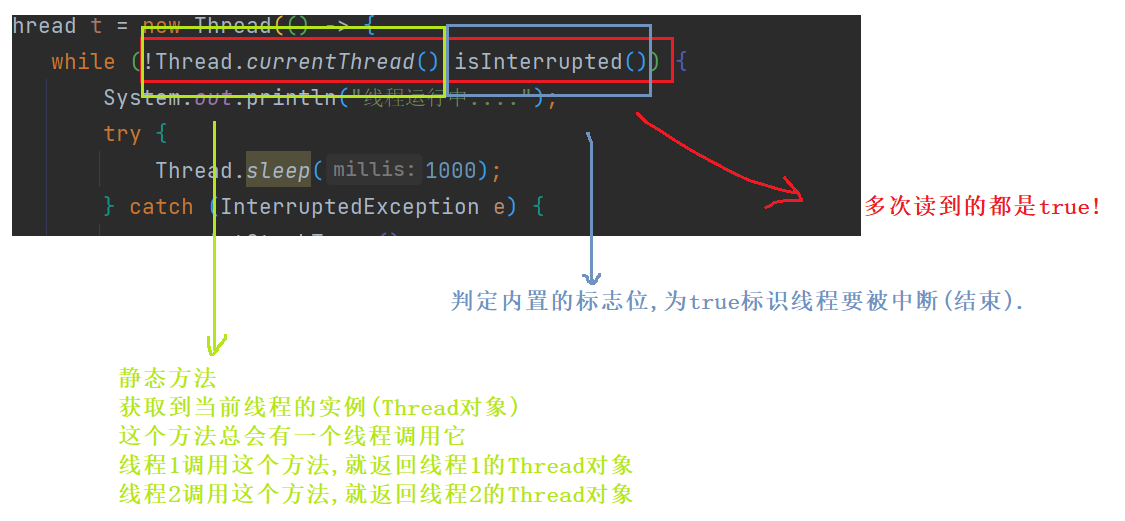
Thread t = new Thread(() -> {
while (!Thread.currentThread().isInterrupted()) {
System.out.println("线程运行中....");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
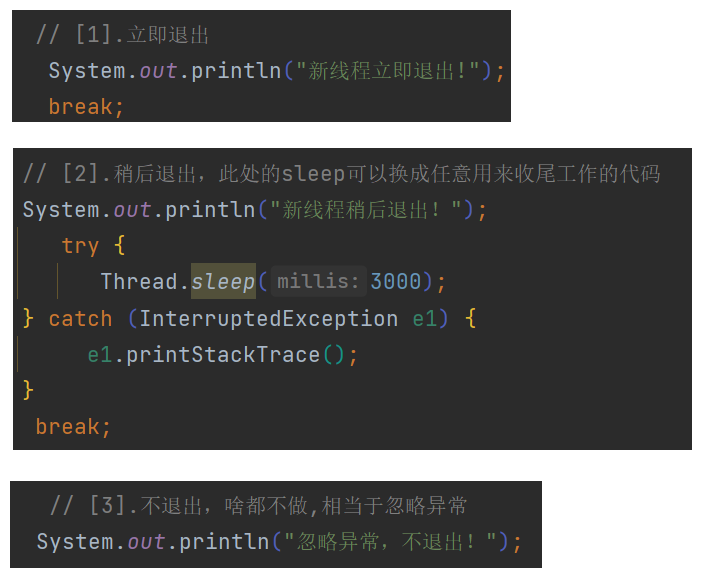
// [1].立即退出
// System.out.println("新线程立即退出!");
// break;
// [2].稍后退出,此处的sleep可以换成任意用来收尾工作的代码
//System.out.println("新线程稍后退出!");
// try {
// Thread.sleep(3000);
//} catch (InterruptedException e1) {
// e1.printStackTrace();
//}
// break;
// [3].不退出,啥都不做,相当于忽略异常
//System.out.println("忽略异常,不退出!");
}
}
});
t.start();
Thread.sleep(5000);
System.out.println("控制新线程退出!");
t.interrupt();
}
}
总结 :
一定要注意,是让线程内部产生阻塞的方法抛出异常,不是interrupt自己抛出异常!!!!!
5.2.4 守护线程
1.守护线程的作用and使用场景
用来让其(这里暂称之为子线程)随着调用它的主线程(这里暂称之为main方法)的结束而结束,不管该线程任务是否圆满完成,只要调用它的主线程结束了,它(子线程)就跟随着结束。
使用场景:
1、当且仅当你希望调用它的线程(可能是主线程或其他线程)结束而结束,不在意子线程的任务是否圆满完成时,此时可以使用守护线程。
2、当你希望在调用它的线程结束时,被调用的子线程继续运行的时候,就不需要设置守护线程。
2.举例
给员工设置了守护线程,就意味着只要老板(主线程)“休假”(工作完成,没事可做了),员工(子线程)也跟着休假不用上班,无论员工手头的活干完没有;
没给员工设置守护线程,就意味着,即使老板“休假”了,员工依然要在后台继续完成他可能永远都完不成的工作!

3.代码示例
package Thread;
import java.util.concurrent.TimeUnit;
public class Demo13 {
/**
* 类描述:了解守护线程的用法呵呵
* 守护线程作用:为了确保调用它的主方法结束的同时子线程也一并结束(并不一定是进入死亡,有可能仅仅进入了等待),就需要设置为守护线程。
* 否则,可能会产生主线程结束后,子线程依然在继续运行
* thread1.setDaemon(true) -> 开启守护线程[默认是false]
*/
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(() -> {
while (true) {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("----我是子线程,每隔一秒打印一次,就是玩儿-----");
}
});
//thread.setDaemon(true);//true 确保主方法结束时候,子线程随之结束(默认是false)
thread.start();
try {
TimeUnit.SECONDS.sleep(3);//让主线程休息一会儿,给子线程充足的执行时间,否则可能造成因主线程执行速度过快,主线程结束了子线程还没来得及执行
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("主线程已结束");
//只有new(新创建)和terminated(死亡)状态的线程下的isAlive()返回值才是false
//其他waiting、blocked、runable、running状态下,isAlive()返回值都是true
System.out.println("子线程状态:"+thread.getState());
System.out.println("是否依然存活:"+thread.isAlive());
System.out.println("是否是守护线程:"+thread.isDaemon());
}
}

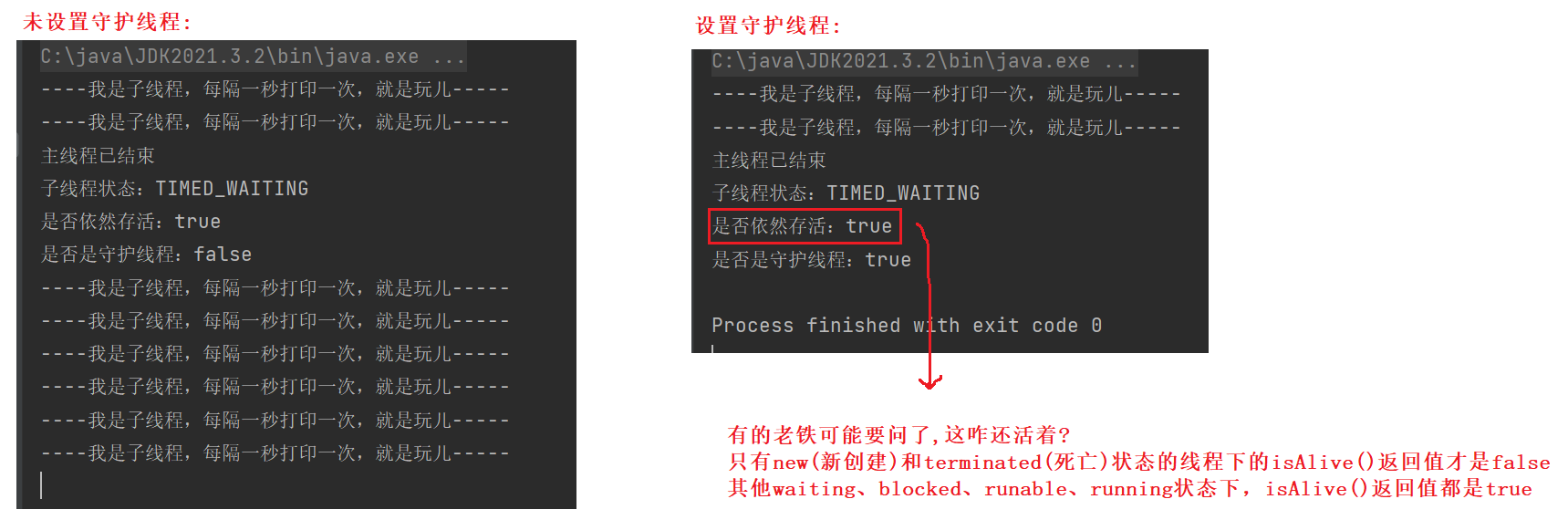
- 子线程休息的状态可能是TIMED_WAITING、RUNNING、BLOCKED三种状态,具体进入哪种状态是由jvm来决定的 .
- 设置守护线程后,线程随着主线程运行结束后,不是每次都会进入wait等待队列(包含:BLOCKED、TIMED_WAITING),有时候也会直接进入runnable就绪队列 . 等待(wait)队列就是阻塞(blocked)队列,没有被CPU直接执行的权利,只有在runnable就绪队列就绪队列才会有被CPU执行的权利(貌似在说我准备好了,CPU你来执行我吧).

4.守护线程可能存在的问题
设置守护线程为true后,子线程(内部有短时间难以干完的活)可能会因主线程的结束而进入等待(大部分情况下,子线程活如果干完了,会直接进入terminated死亡状态),可能会直接导致子线程自己的活儿没干完,而被暂停!(有时候它的活可能永远干不完,不能休息进入waiting,本例的for死循环就是这个意思).
简而言之:被设置守护的子线程,如果子线程内部是简单的工作,不会造成影响,直接会随着主线程的结束而彻底结束,如果子线程内部是死循环,子线程会随着主线程的结束而暂停,进入等待队列或者就绪队列,但是有可能剩余的工作就无法再继续 .
当然也有一种可能性,我就是不想让他死循环了,就想在主线程结束时直接带走子线程,这时候自然就用到“守护线程”了!
5.守护线程到底是不是一个线程?
Q : 守护线程是线程吗? A : 就看守护线程是否会开启一个新的线程.
package Thread;
import java.util.concurrent.TimeUnit;
public class Demo15 {
public static void printThread(int num,ThreadGroup threadGroup) {
Thread[] threads = new Thread[num];
threadGroup.enumerate(threads);
for (Thread t:threads){
System.out.println("线程"+t.getId()+" "+t.getName());
}
}
public static void main(String[] args) throws InterruptedException {
ThreadGroup threadGroup = Thread.currentThread().getThreadGroup();
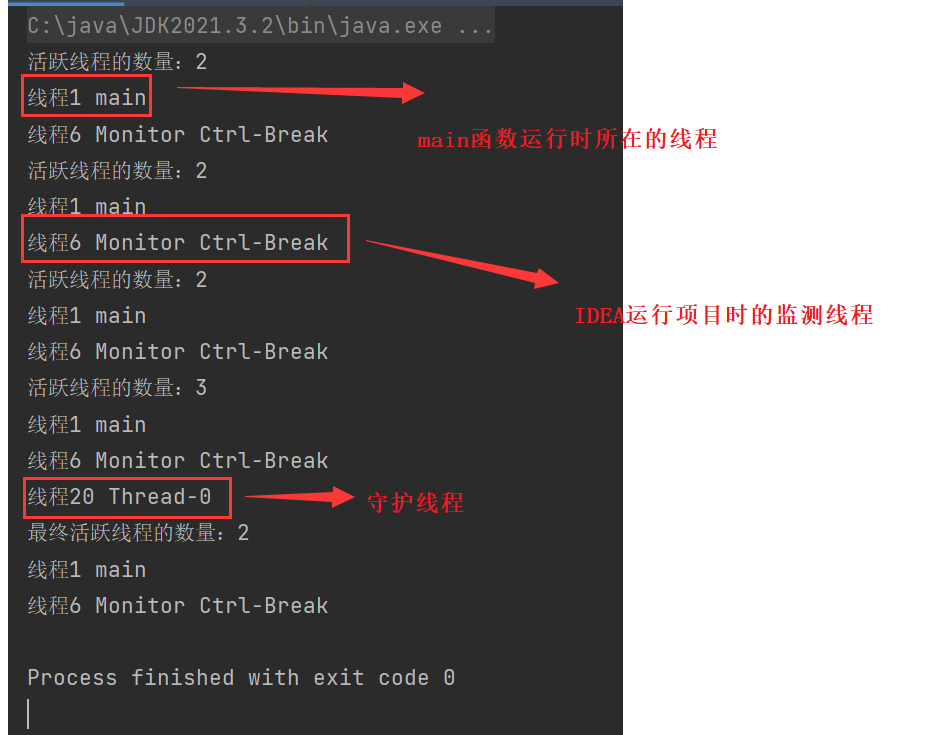
System.out.println("活跃线程的数量:" + Thread.activeCount()); //此时打印的2
//打印线程
printThread(Thread.activeCount(),threadGroup);
Thread thread = new Thread();
System.out.println("活跃线程的数量:" + Thread.activeCount()); //因为new的线程没有start,所以活跃的线程仍然是2
printThread(Thread.activeCount(),threadGroup);
thread.setDaemon(true);//该参数设置为true或false,并不影响活跃线程的数量,它仅影响主线程退出时,子线程是否跟随停止运行(进入等待或就绪队列)
System.out.println("活跃线程的数量:" + Thread.activeCount()); //因为new的线程没有start,所以活跃的线程仍然是2
printThread(Thread.activeCount(),threadGroup);
thread.start();
System.out.println("活跃线程的数量:" + Thread.activeCount()); //因为new的线程已start,所以活跃的线程变为3
printThread(Thread.activeCount(),threadGroup);
Thread.sleep(5 * 1000);//给足子线程充足的执行时间
System.out.println("最终活跃线程的数量:" + Thread.activeCount());
printThread(Thread.activeCount(),threadGroup);
}
}
5.2.5 获取当前线程的引用
为了对线程进行操作,就需要获取到线程的引用 !!! 对线程的操作,就包括线程等待,线程中断,获取各种线程的属性… 如果是继承Thread,然后重写run方法,可以直接在run中使用this获取到线程的实例;但如果是Runnable或lambda,this就不行了(this就不是指向Thread实例).
更通用的办法,是Thread.currentThread()——哪个线程来调用这个方法,得到的结果就是哪个线程的实例 .

public class ThreadDemo {
public static void main(String[] args) {
Thread thread = Thread.currentThread();
System.out.println(thread.getName());
}
}
5.2.6 休眠当前线程sleep
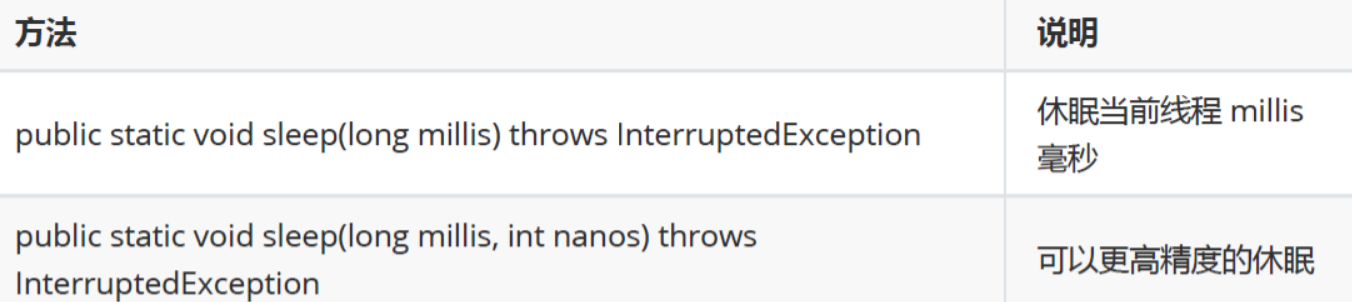
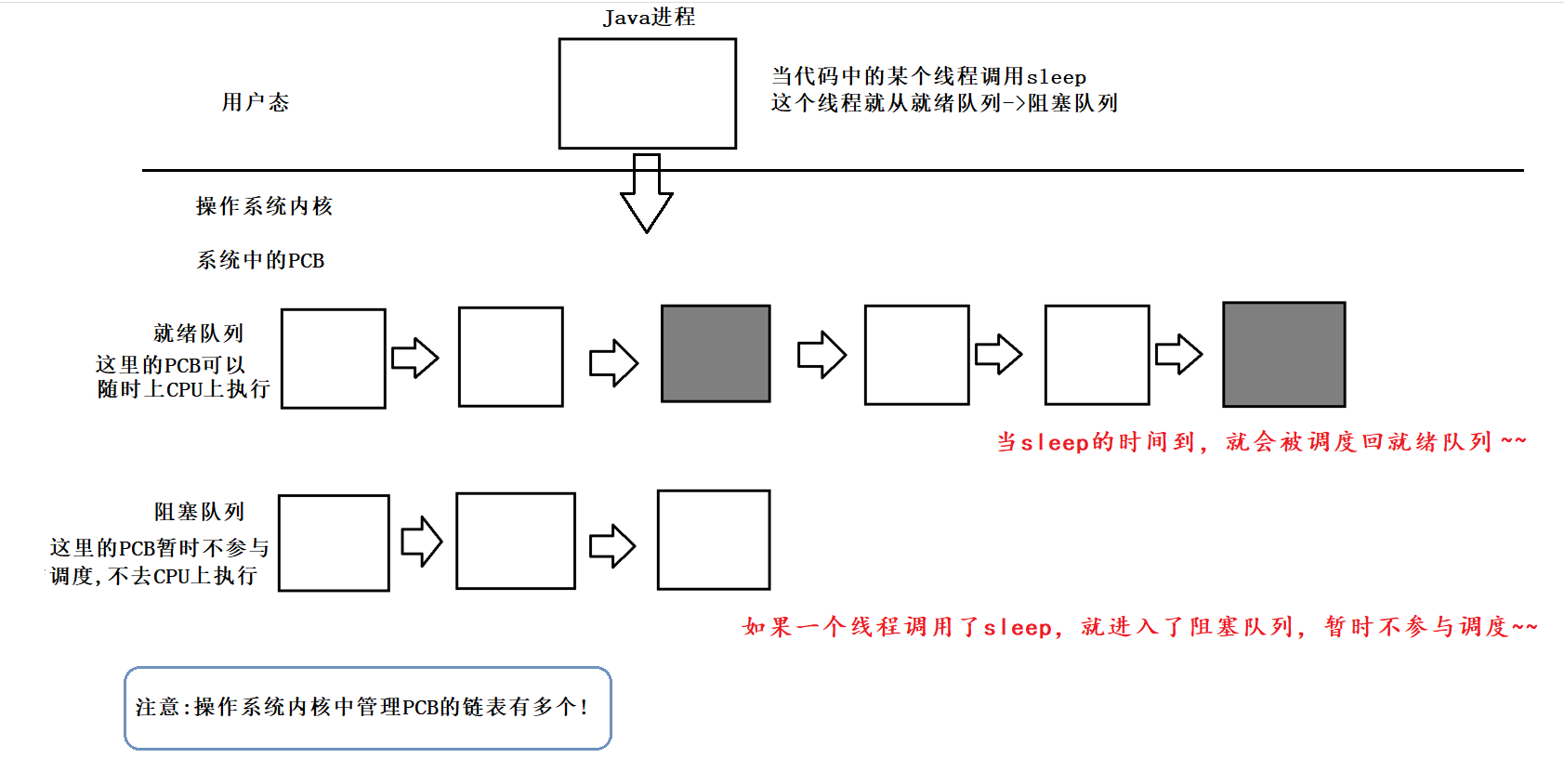
休息一下 , 回忆回忆 :



六 :线程的状态
6.1 观察线程的状态
线程的状态是一个枚举类型 Thread.State
package Threading;
public class Test2 {
public static void main(String[] args) {
for (Thread.State state : Thread.State.values()) {
System.out.println(state);
}
}
}

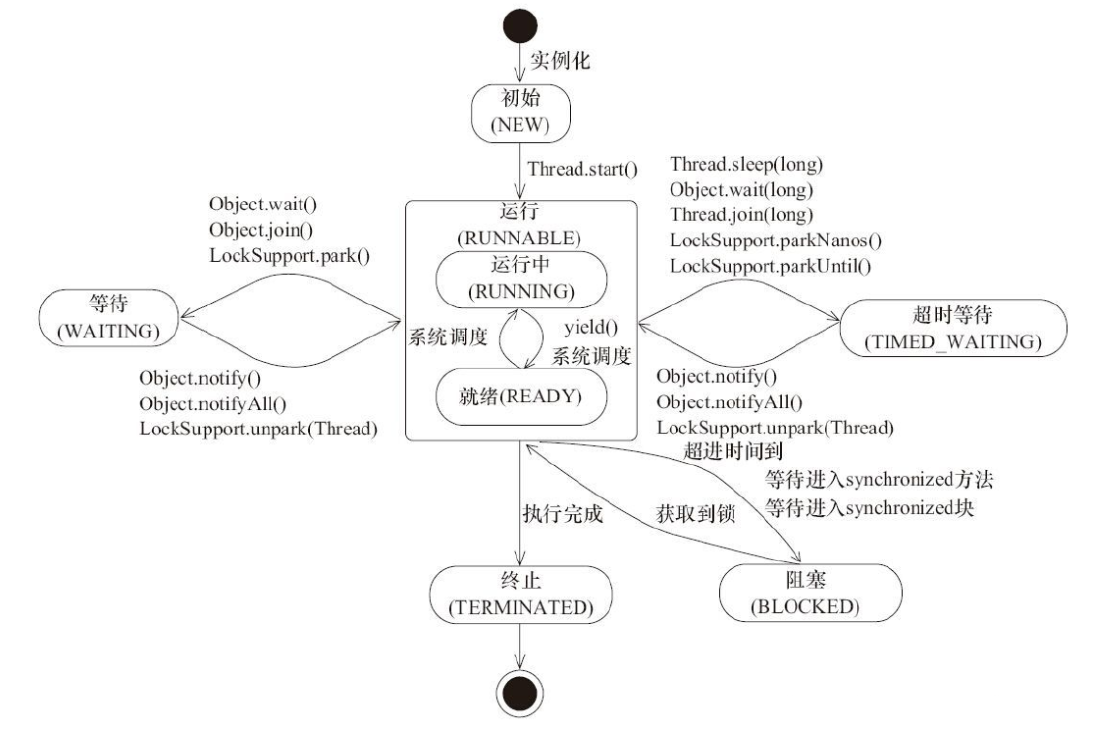
6.2 线程状态及其转移的意义
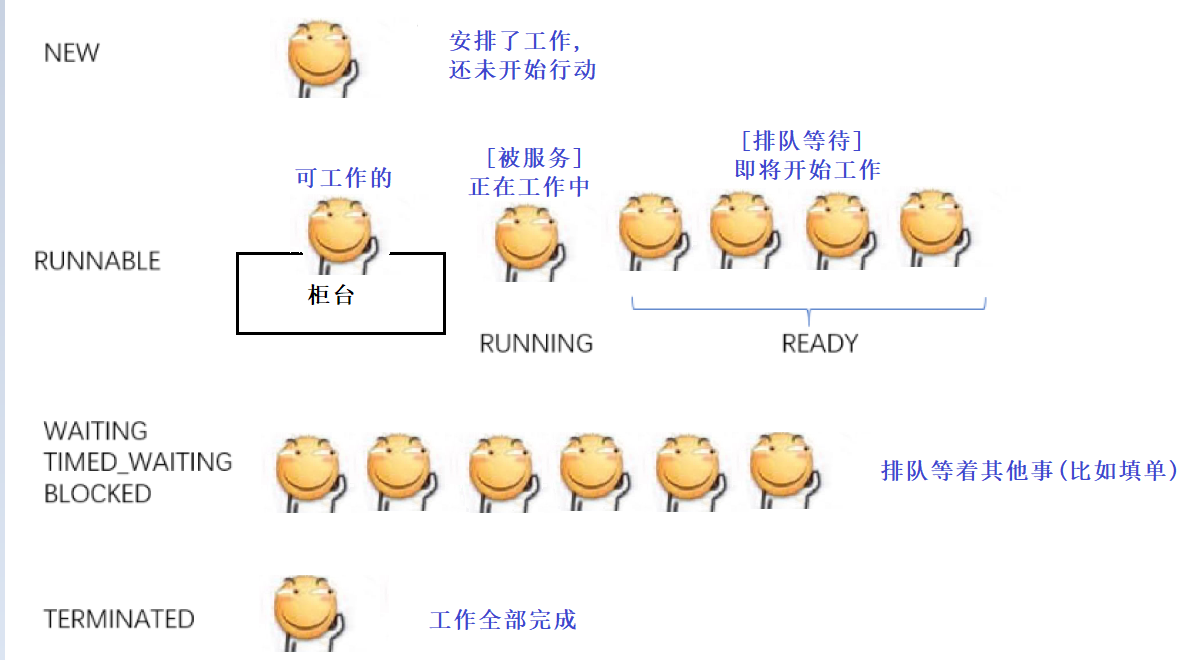
操作系统内核是不区分进程线程的 , 只认PCB , 只不过有些PCB之间有关联关系(共用一组虚拟地址空间和文件描述符表) .
画一个简易版的线程状态转移图 :
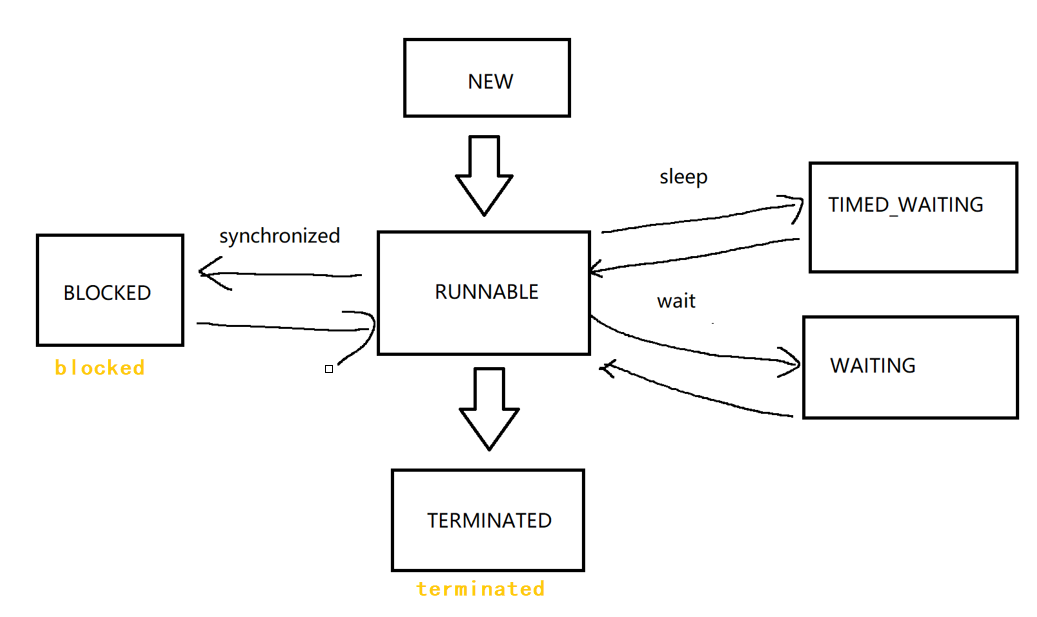
主干道是NEW→RUNNABLE→TERMINATED
在RUNNABLE会根据特定代码进入支线任务 ! 这些支线任务都是阻塞状态!这三种阻塞状态,进入的方式不一样,同时阻塞的时间也不同,被唤醒的方式也不同!
6.3 观察线程的状态和转移
package Thread;
public class Demo16 {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
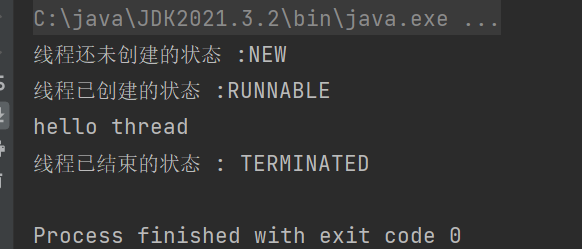
//在start之前获取,获取到的是线程还未创建的状态
System.out.println("线程还未创建的状态 :" + t.getState()); //NEW
t.start();
System.out.println("线程已创建的状态 :" + t.getState()); //RUNNABLE
t.join();
//在join之后获取,获取到的是线程已经结束后的状态
System.out.println("线程已结束的状态 : "+ t.getState()); //TERMINATED
}
}
package Thread;
public class Demo17 {
public static void main(String[] args) {
Thread t = new Thread(()->{
System.out.println("hello thread");
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
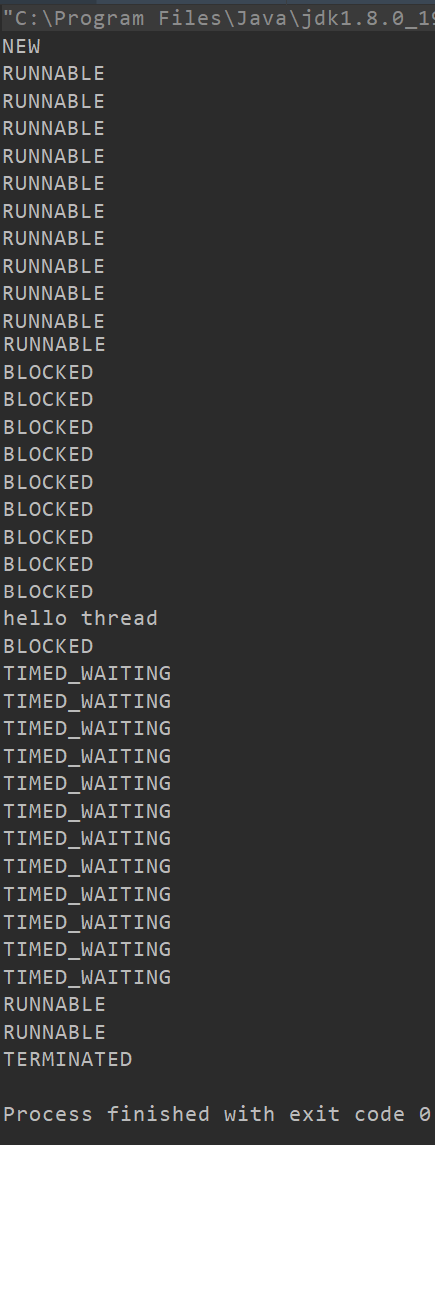
//在start之前获取,获取到的是线程还未创建的状态
System.out.println(t.getState()); //NEW
t.start();
//线程开始工作了,只要线程还存活,就打印其状态
while(t.isAlive()){
System.out.println(t.getState());
}
System.out.println(t.getState());
}
}
BLOCKED 表示等待获取锁, WAITING 和 TIMED_WAITING 表示等待其他线程发来通知 . TIMED_WAITING 线程在等待唤醒,但设置了时限; WAITING 线程在无限等待唤醒 ; 上述结果充分体现了线程调度的随机性 !
package Thread;
public class Demo18 {
public static void main(String[] args) {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
while(true){
System.out.println("张三");
Thread.yield();
}
}
},"t1");
t1.start();
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
while(true){
System.out.println("李四");
//Thread.yield();
}
}
},"t2");
t2.start();
}
}
实验结果分析 :
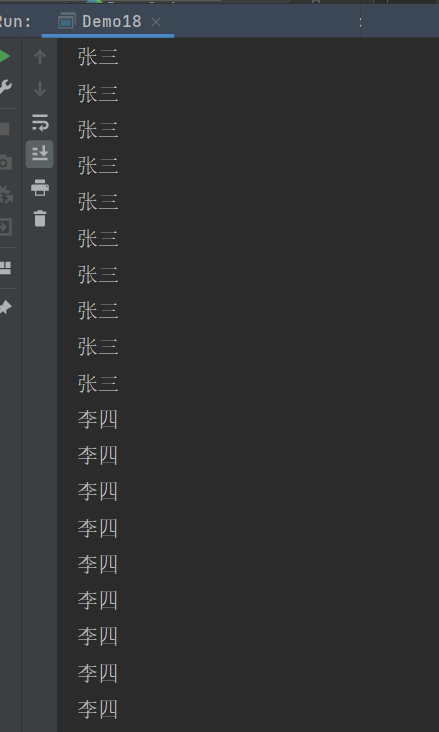
- 不使用yeild时 , 张三李四大概五五开 ;
- 使用yield时 , 张三的数量远远小于李四了 .
yield()大公无私 , 让出CPU , 短暂地放弃CPU , 排到就绪队伍的后面位置 , 仍然在就绪队列里 , 没进阻塞队列 . 也就是说 , yield不改变线程的状态 , 但是会重新去排队 .
sleep(0)表示马上进入阻塞队列 , 又马上回来 , 效果和yield()类似 ; 像C/C++里没有yield操作 , 就可以使用slee(0)凑合一下 .
七 : 多线程带来的风险
7.1 线程安全罪魁祸首—调度器随机调度
线程安全是多线程编程中最重要,也是最困难的问题!
线程安全问题的万恶之源,正是调度器随机调度/抢占式执行这个过程!
典型例子 : 两个线程对同一个变量进行并发地自增 !
package Thread;
import java.util.Comparator;
//创建两个线程,对同一个变量进行并发自增,每个线程自增5w次,预期自增10w次
class Counter{
public int count;
public void increase(){
count++;
}
}
public class Demo19 {
public static void main(String[] args) {
Counter counter = new Counter();
Thread t1 = new Thread(()->{
for (int i = 0; i < 50000; i++) {
counter.increase();
}
});
Thread t2 = new Thread(()->{
for (int i = 0; i < 50000; i++) {
counter.increase();
}
});
t1.start();
t2.start();
try {
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("count: "+counter.count);
}
}
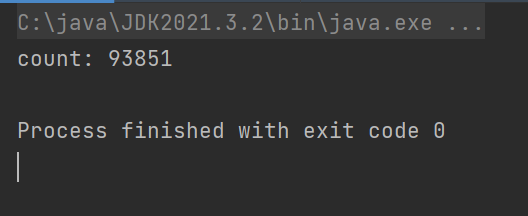
上述bug是如何出现的 ?
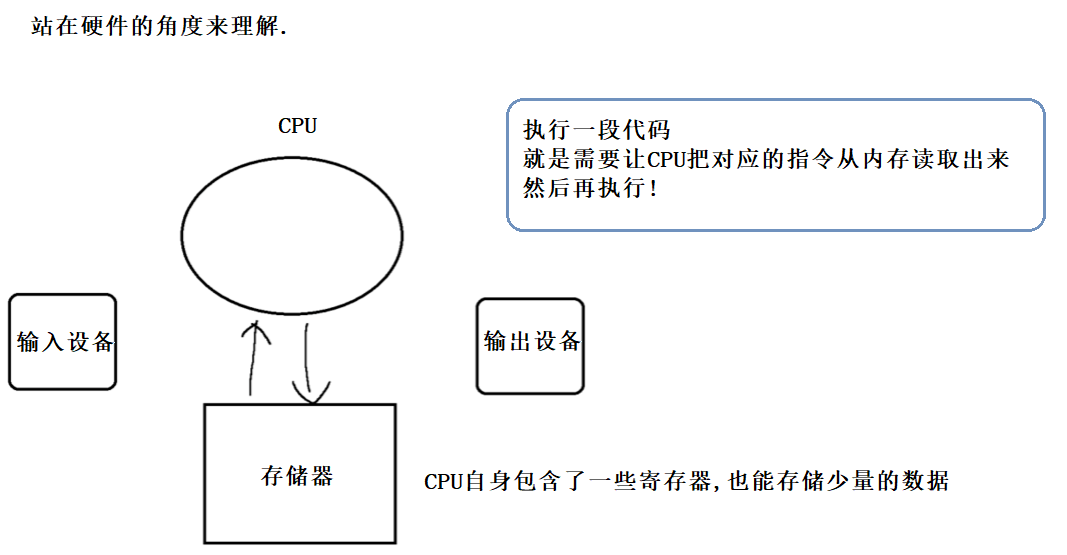
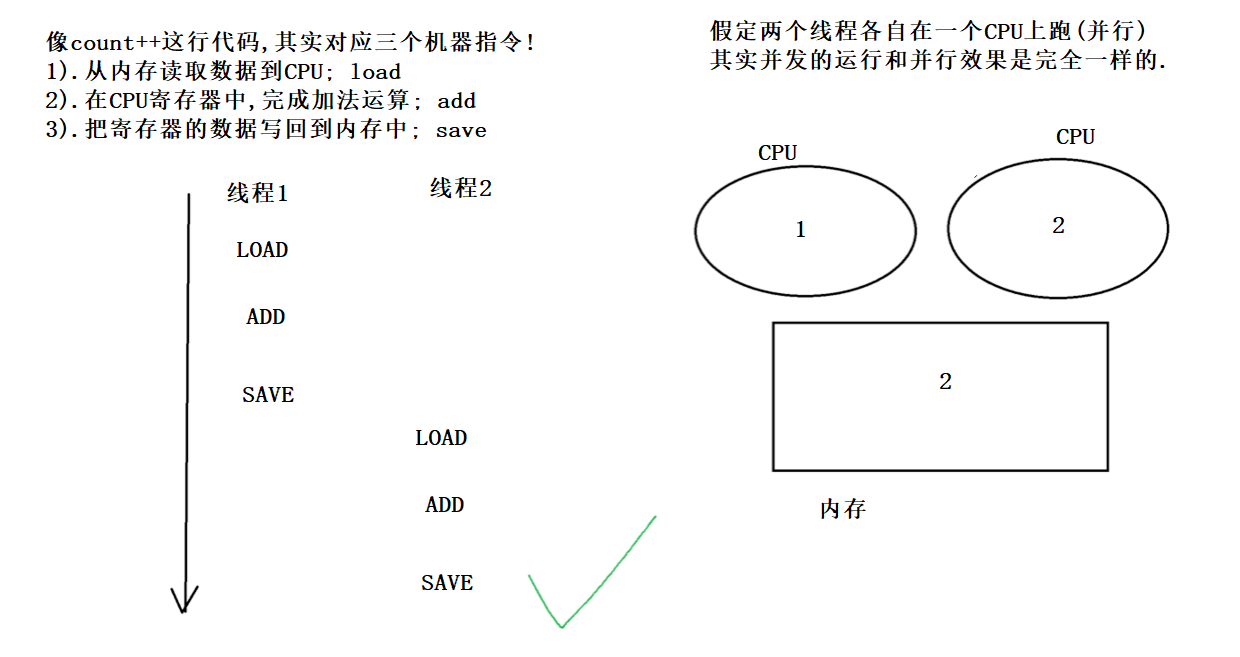
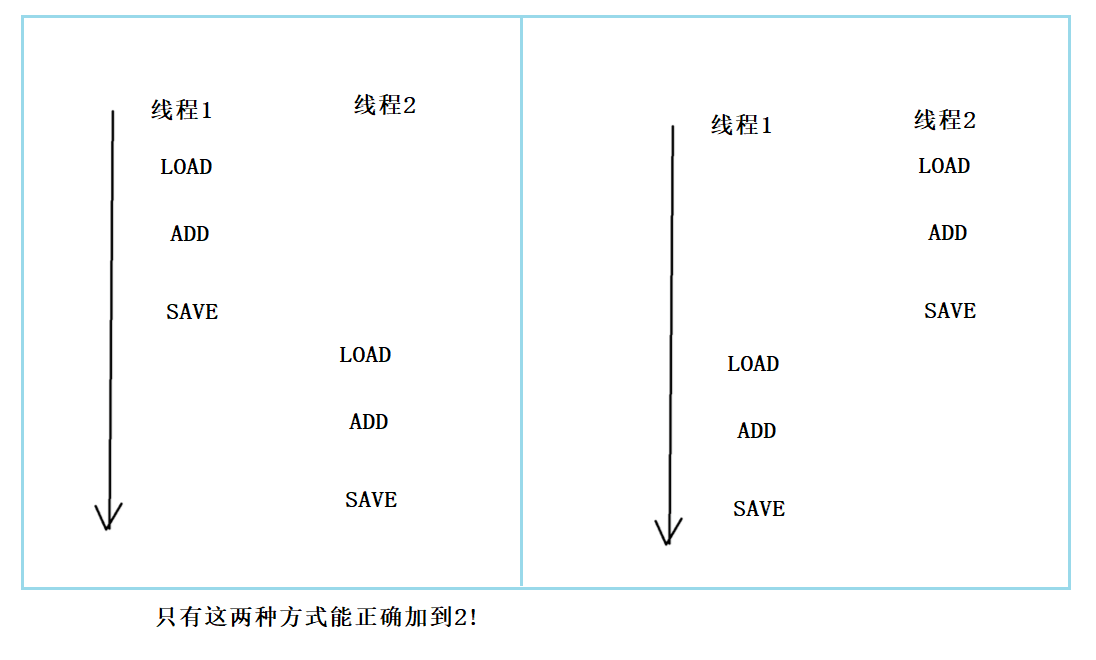
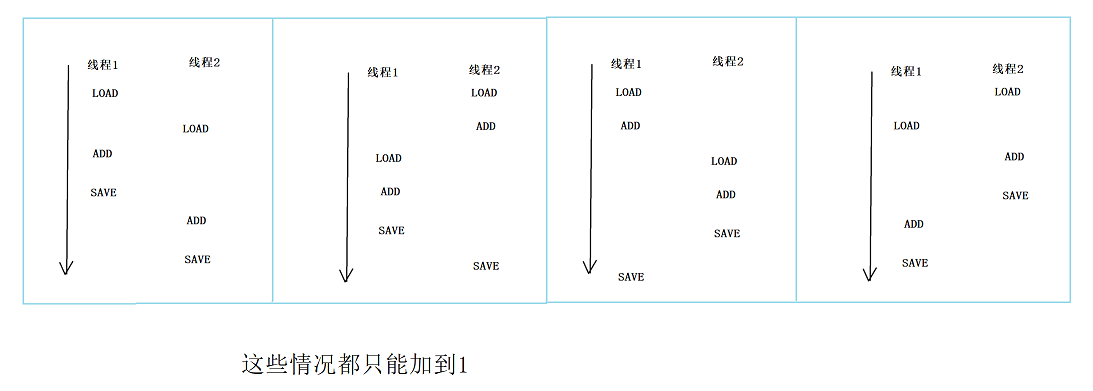
像上述这些情况 , 明明我们在程序里自增了2次 , 但实际上内存中的值只加了1次 . 这是典型的由于线程不安全导致的BUG !
注意 : 操作系统内核的调度器随机调度线程 , 严格意义上说并不是数学上的"随机" , 而是在内部有一套逻辑/算法 , 来支持这一调度过程的 !
7.2 原子性
原子性. 原子性是指一个操作是不可中断的,要么全部执行成功要么全部执行失败,有着"同生共死"的感觉.
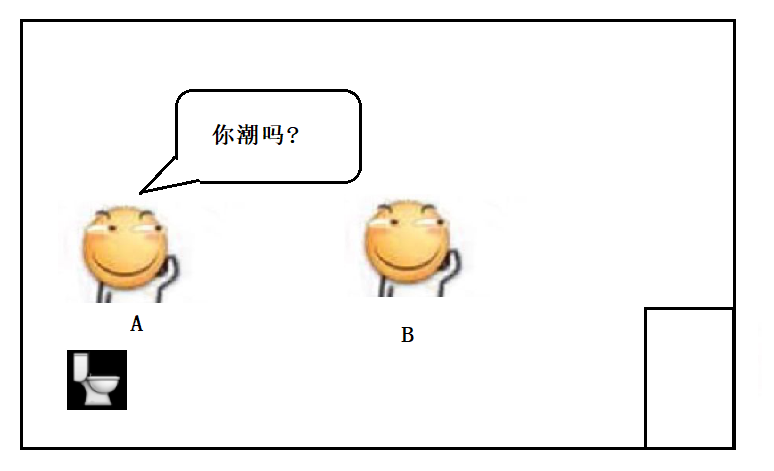
什么是原子性呢 ? 我们把一段代码想象成一间厕所,每个线程就是要进入这间厕所的人。如果没有任何机制保证,A进入厕所之后,还没有出来;B 是不是也可以进入厕所,打断 A 在厕所里的活动。这个就是不具备原子性的。这好吗 ? 这不好 .
那我们应该如何解决这个问题呢?是不是只要给厕所加一把锁,A 进去就把门锁上,其他人是不是就进不来了。这样就保证了这段代码的原子性了。
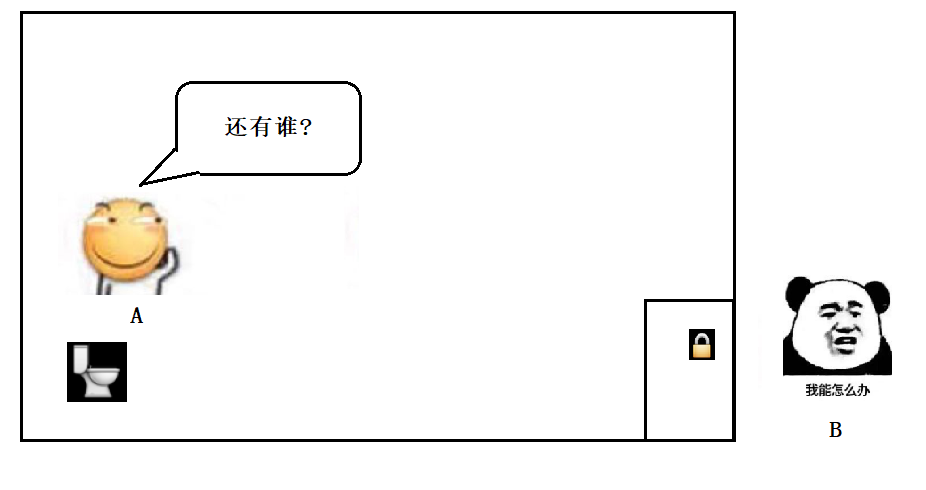
有时也把这个现象叫做同步互斥,表示操作是互相排斥的 .
一条 java 语句不一定是原子的,也不一定只是一条指令
比如刚才我们看到的count++,其实是由三步操作组成的:
1.从内存把数据读到 CPU
2.进行数据更新
3.把数据写回到 CPU
如果不保证原子性 , 当一个线程正在对一个变量操作时 , 中途其他线程插入进来了 , 如果这个操作被打断了 , 结果就可能是错误的。当然 , 这点也和线程的抢占式调度密切相关. 如果线程不是 “抢占” 的, 就算没有原子性, 也问题不大.
7.3 可见性
可见性指, 一个线程对共享变量值的修改,能够及时地被其他线程看到.
Java 内存模型 (JMM): Java虚拟机规范中定义了Java内存模型.
目的是屏蔽掉各种硬件和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到一致的并发效果 .
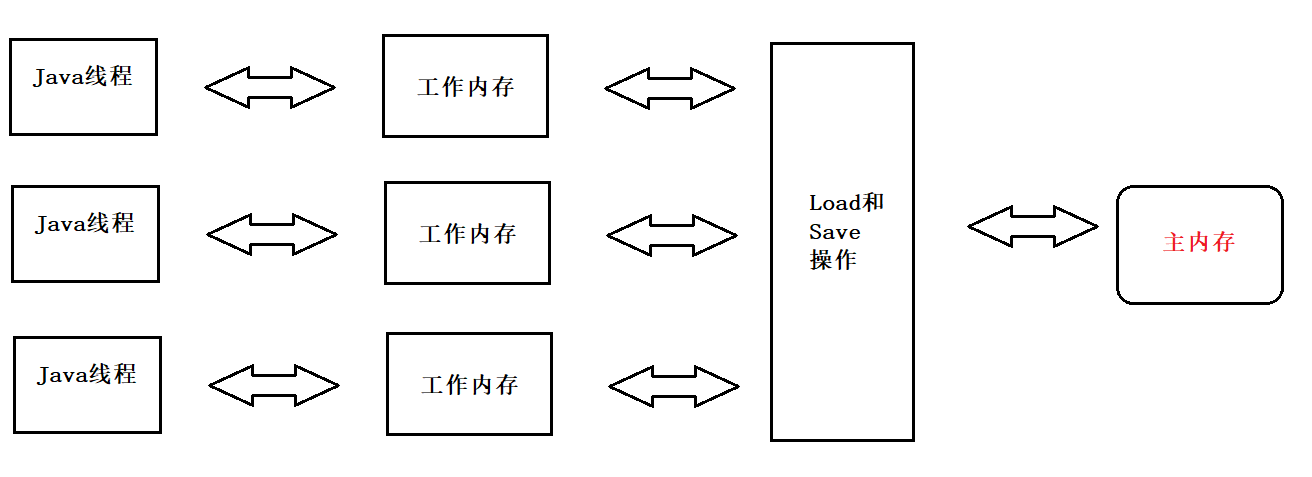
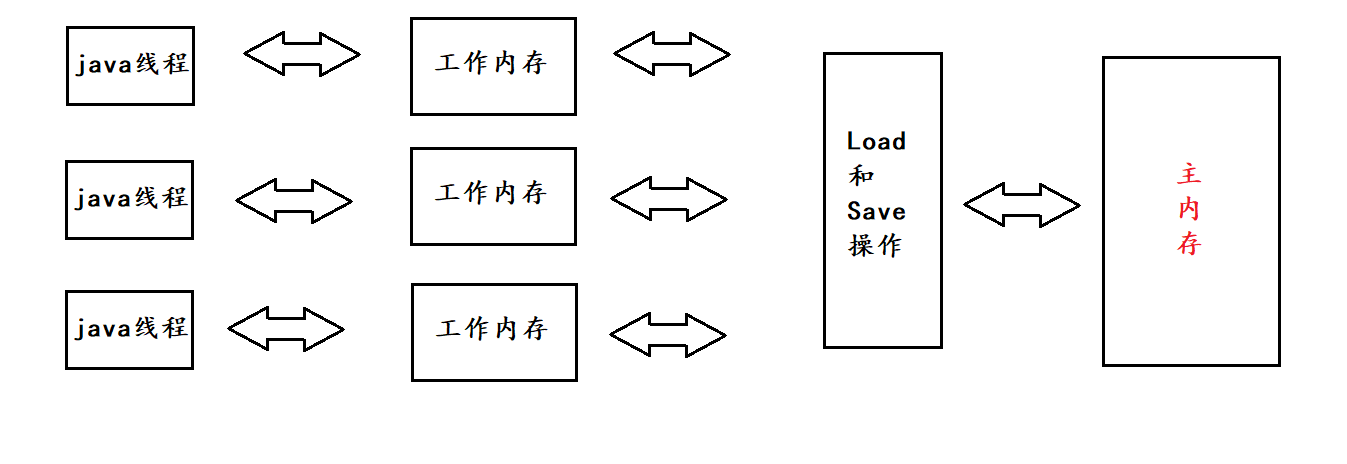
线程之间的共享变量存在于主内存 (Main Memory).
每一个线程都有自己的 “工作内存” (Working Memory) .
当线程要读取一个共享变量的时候, 会先把变量从主内存拷贝到工作内存, 再从工作内存读取数据.
当线程要修改一个共享变量的时候, 也会先修改工作内存中的副本, 再同步回主内存.
由于每个线程有自己的工作内存, 这些工作内存中的内容相当于同一个共享变量的 “副本”. 此时修改线程1 的工作内存中的值, 线程2 的工作内存不一定会及时变化 .
此时就出现了两个发人省醒的问题 :
- 为什么要搞这么多块内存呢 ?
- 为什么要这么麻烦的拷贝来拷贝去呢 ?

- 为啥整这么多内存?
实际并没有这么多 “内存”. 这只是 Java 规范中的一个术语, 是属于 “抽象” 的叫法 . 所谓的 “主内存” 才是真正硬件角度的 “内存” ; 而所谓的 “工作内存” , 则是指 CPU 的寄存器和高速缓存 .
- 为啥要拷贝来拷贝去 ?
因为 CPU 访问自身寄存器的速度以及高速缓存的速度 , 远远超过访问内存的速度(快了 3 - 4 个数量级, 也就是几千倍, 上万倍).
比如某个代码中要连续 10 次读取某个变量的值, 如果 10 次都从内存读, 速度是很慢的. 但是如果只是第一次从内存读, 读到的结果缓存到 CPU 的某个寄存器中, 那么后 9 次读数据就不必直接访问内存了. 效率就大大提高了.
那么现在又出现一个问题 , 既然访问寄存器速度这么快, 还要内存干啥??
答案就是一个字: 贵 !

当然 , 快和慢都是相对的 , CPU访问寄存器的速度远远快于内存 , 但是内存的访问速度又远远快于硬盘 . 一般情况下, 访问速度越快 , 价格也最贵 !
7.4 代码顺序性
比如有这样一段代码 :
- 到二仙桥买炊饼 ;
- 到成华大道买瓜;
- 到二仙桥买电瓶车 .
如果是在单线程情况下,JVM、CPU指令集会对其进行优化,比如,按 1->3->2的方式执行,这样的话 , 可以少跑一次二仙桥 .
编译器对于指令重排序的前提是 “保持逻辑不发生变化” . 这一点在单线程环境下比较容易判断, 但是在多线程环境下就没那么容易了, 多线程的代码执行复杂程度更高, 编译器很难在编译阶段对代码的执行效果进行预测, 因此激进的重排序很容易导致优化后的逻辑和之前不等价 !
7.5 总结


总结线程安全五大问题:
1.系统随机调度/抢占式执行——万恶之源,无能为力 ;
2.多个线程同时修改一个变量——部分规避 ;
3.修改操作不是原子的——加锁可以改善 synchronized ;
4.内存可见性——由于编译器/JVM/操作系统误判,非正常优化了 ;
5.指令重排序——使用volatile可以防止编译器进行指令重排序 .
八 : 解决线程不安全问题
8.1 synchronized
8.1.1 synchronized 的特性
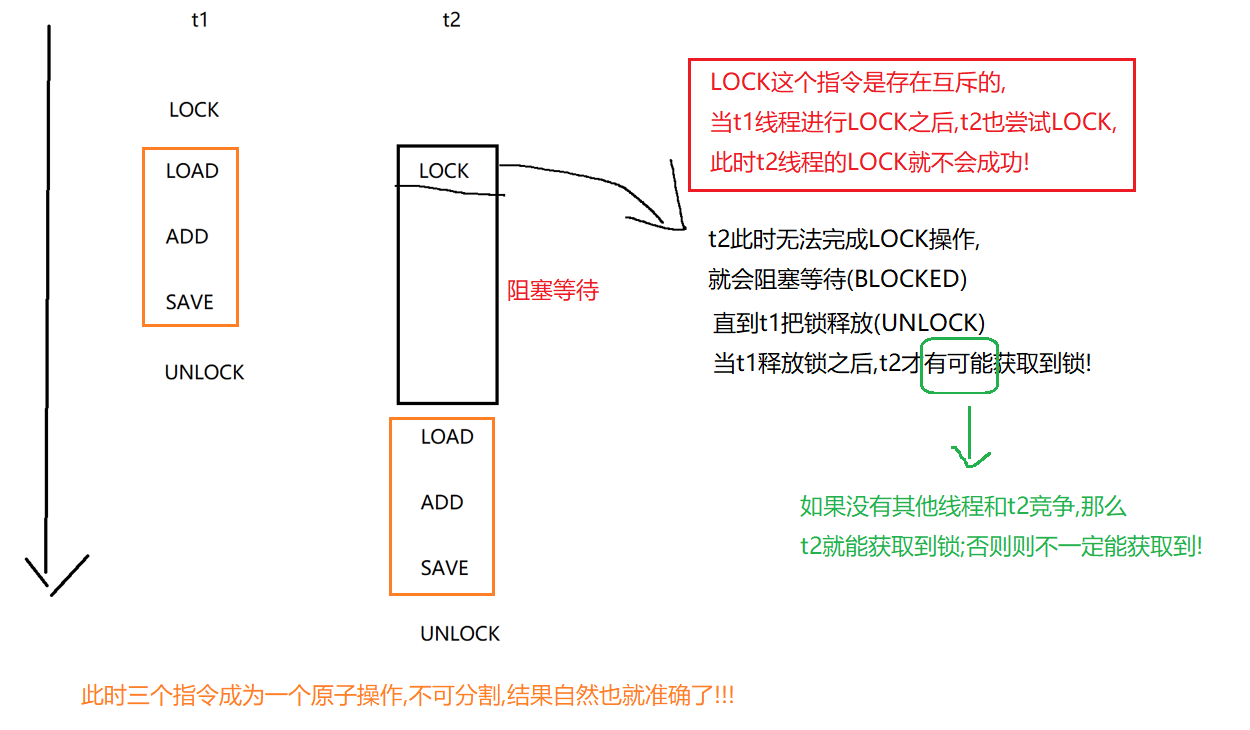
1. 互斥性
synchronized 会起到互斥效果, 某个线程执行到某个对象的 synchronized 中时, 其他线程如果也执行到同一个对象 , synchronized 就会阻塞等待.
进入 synchronized 修饰的代码块, 相当于 加锁
退出 synchronized 修饰的代码块, 相当于 解锁
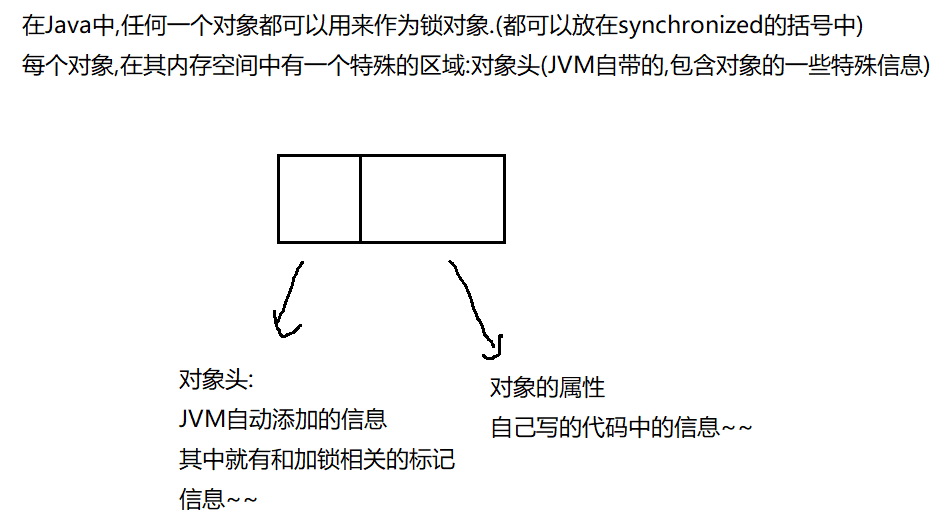
synchronized用的锁是存在Java对象头里的 .
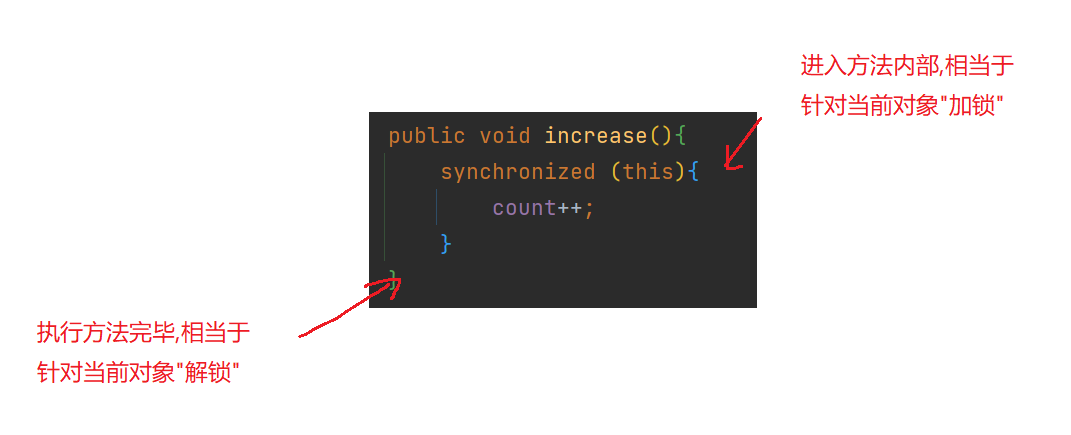
可以粗略理解成, 每个对象在内存中存储的时候, 都存有一块内存表示当前的 “锁定” 状态(类似于厕所的 “有人/无人”).
如果当前是 “无人” 状态, 那么就可以使用, 使用时需要设为 “有人” 状态.
如果当前是 “有人” 状态, 那么其他人无法使用, 只能排队 .
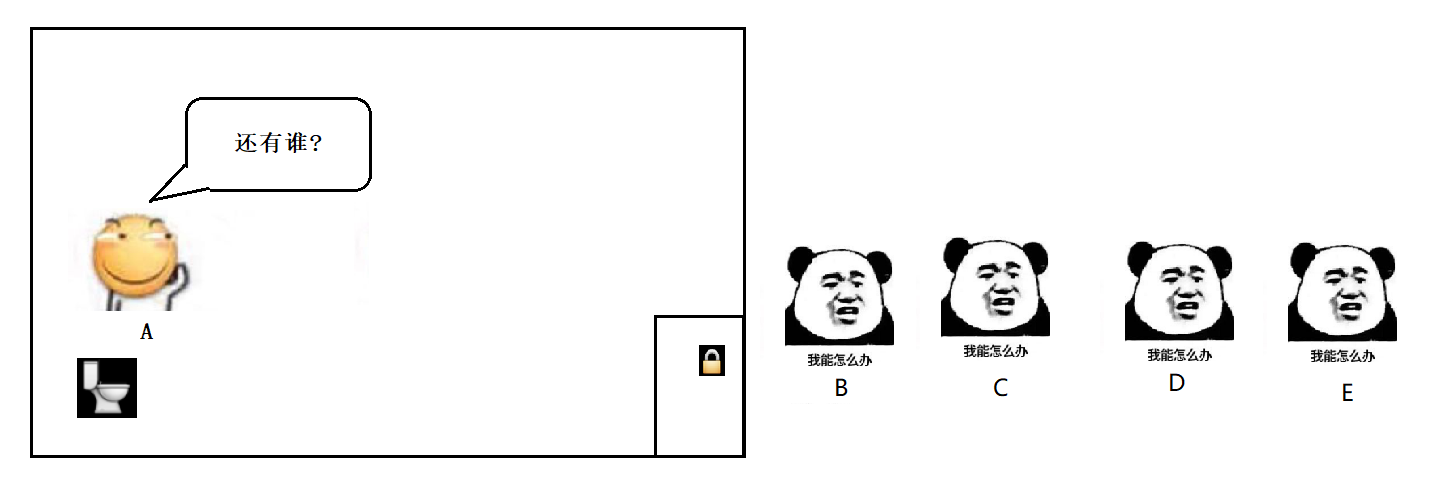
理解阻塞等待 : 针对每一把锁 , 操作系统内部维护了一个等待队列 , 当这个锁被某个线程占有的时候, 其他线程尝试进行加锁, 就加不上了, 就会阻塞等待, 一直等到之前的线程解锁之后, 由操作系统唤醒一个新的线程, 再来获取到这个锁.
注意 :
- 上一个线程解锁之后, 下一个线程并不是立即就能获取到锁. 而是要靠操作系统来 “唤醒”. 这也就是操作系统线程调度的一部分工作.
- 假设有 A B C 三个线程, 线程 A 先获取到锁, 然后 B 尝试获取锁, 然后 C 再尝试获取锁, 此时 B和 C 都在阻塞队列中排队等待. 但是当 A 释放锁之后, 虽然 B 比 C 先来的, 但是 B 不一定就能获取到锁, 而是和 C 重新竞争, 并不遵守先来后到的规则 .
synchronized的底层是使用操作系统的mutex lock实现的 .
2. 刷新内存
synchronized 的工作过程:
- 获得互斥锁
- 从主内存拷贝变量的最新副本到工作的内存
- 执行代码
- 将更改后的共享变量的值刷新到主内存
- 释放互斥锁
所以 synchronized 也能保证内存可见性 .
3. 可重入
synchronized 同步块对同一条线程来说是可重入的,不会出现自己把自己锁死的问题 .
什么是可重入 ? 提到可重入,首先要有前提条件:内核环境(内核中常有中断异步发生)或者多进程、多线程,总之是异步环境下 . 可重入:很简单,就是可以重新再进入 . 就是在运行某个函数或者代码时因为某个原因(中断或者抢占资源问题)而中止函数或代码的运行,等到问题解决后,重新进入该函数或者代码继续运行 , 其结果不会受到影响(和没有被打断时,运行结果一样). 那么这个函数或者代码就称为可重入的 , 即"可以重新再进入" .
什么是把自己锁死 ? 就是一个线程没有释放锁, 然后又尝试再次加锁 .
按照之前对于锁的设定, 第二次加锁的时候, 就会阻塞等待. 直到第一次的锁被释放, 才能获取到第二个锁 . 但是释放第一个锁也是由该线程来完成, 结果这个线程已经躺平了, 啥都不想干了, 也就无法进行解锁操作. 这时候就会死锁 .
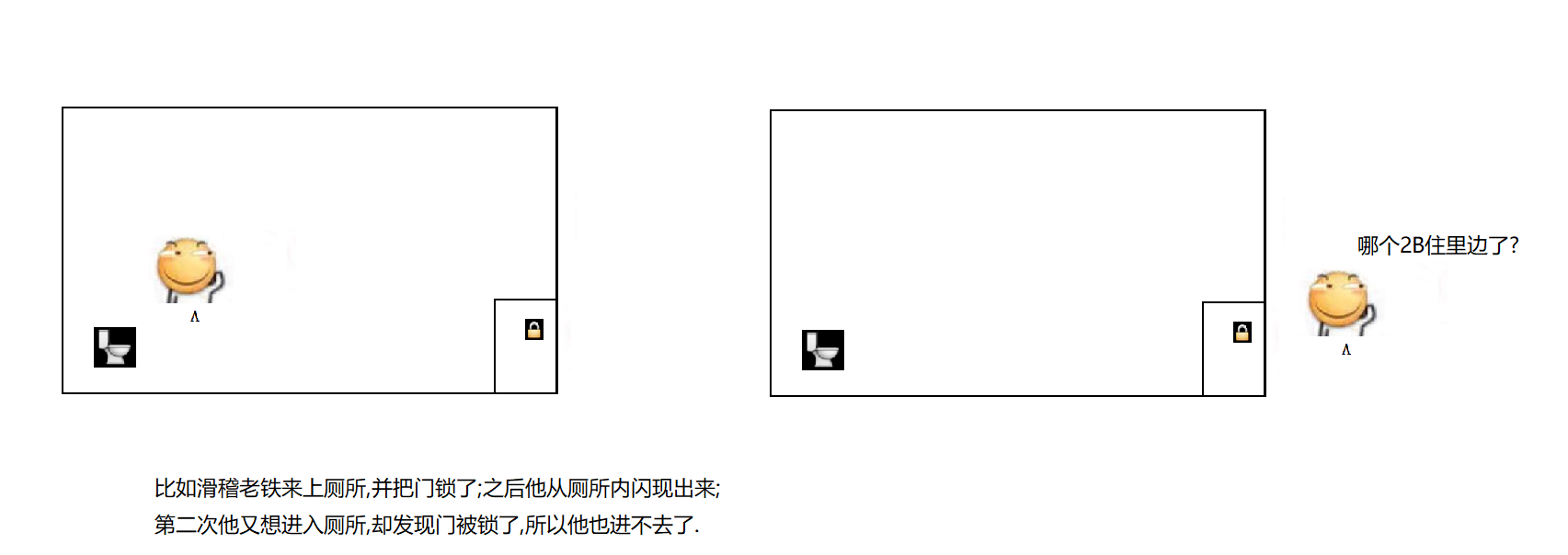
这样的锁称为 不可重入锁.
Java 中的 synchronized 是 可重入锁, 因此没有上面的问题.
8.1.2 synchronized代码演示
1. 解决两个线程加问题
package Thread;
import java.util.Comparator;
//创建两个线程,对同一个变量进行并发自增,每个线程自增5w次,预期自增10w次
class Counter{
public int count;
public void increase(){
synchronized (this){
count++;
}
}
}
public class Demo19 {
public static void main(String[] args) {
Counter counter = new Counter();
Thread t1 = new Thread(()->{
for (int i = 0; i < 50000; i++) {
counter.increase();
}
});
Thread t2 = new Thread(()->{
for (int i = 0; i < 50000; i++) {
counter.increase();
}
});
t1.start();
t2.start();
try {
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("count: "+counter.count);
}
}
运行结果 :
在这个示例中 , t1和t2都调用了counter对象 , 其实是在针对counter对象进行加锁 . 那么 , 都有哪些对象可以用来加锁呢 ?
2. synchronized修饰的内容

3. Java标准库中的线程安全类
因为加锁涉及到一些线程的阻塞等待和线程的调度 , 所以会牺牲很大的运行速度,其性能自然就不高了 .

Q : 类锁和对象锁有什么区别呢 ?
A : 没啥区别 ! 类对象加锁和普通对象加锁没有任何区别 , synchronized里面写啥对象 , 对于synchronized本身来说都是一样的 ! synchronized只是往这个对象里设置对象头的状态 .
硬说有区别 , 类对象只有唯一一个实例 , 所有的使用这个类对象的synchronized之间都有互斥关系 ; 普通的对象加锁 , 则可能有多个实例 .同时注意 , 线程和对象也没关系 , 不存在"某个对象内的线程"这种说法 ! 线程和对象是各自独立的关系 !
本质 : 同一个对象会产生互斥竞争 , 不同的对象不产生竞争 !
针对其本质 , 下面是一个代码示例 :
package Thread;
public class Demo20 {
public static Object locker1 = new Object();
public static Object locker2 = new Object();
public static void main(String[] args) {
Thread t1 = new Thread(()->{
synchronized (locker1){
System.out.println("t1 start");
try {
Thread.sleep(1000); //让t1线程执行一段时间
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("t1 end");
}
});
t1.start();
Thread t2 = new Thread(()->{
synchronized (locker1){
System.out.println("t2 start");
try {
Thread.sleep(1000); //让t1线程执行一段时间
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("t2 end");
}
});
t2.start();
}
}
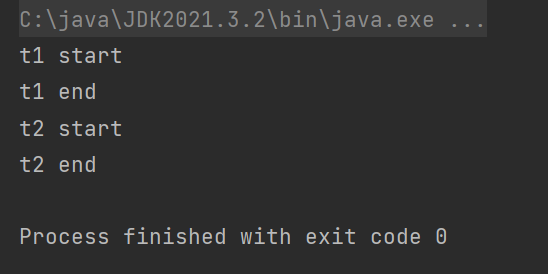
此时加的是同一把锁,t1执行完end之后 , t2才开始执行 .
package Thread;
public class Demo20 {
public static Object locker1 = new Object();
public static Object locker2 = new Object();
public static void main(String[] args) {
Thread t1 = new Thread(()->{
synchronized (locker1){
System.out.println("t1 start");
try {
Thread.sleep(1000); //让t1线程执行一段时间
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("t1 end");
}
});
t1.start();
Thread t2 = new Thread(()->{
synchronized (locker2){
System.out.println("t2 start");
try {
Thread.sleep(1000); //让t1线程执行一段时间
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("t2 end");
}
});
t2.start();
}
}
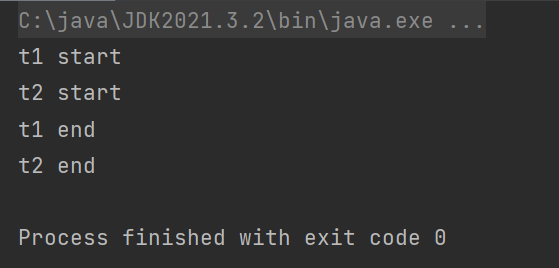
此时加的是不同的锁 , 在两个synchronized之间没有产生竞争 .
注意 :

8.2 volatile
8.2.1 volatile的作用
volatile关键字的作用主要有如下两个:
-
保证内存可见性:基于屏障指令实现,即当一个线程修改一个共享变量时,另外一个线程能读到这个修改的值。
-
保证有序性:禁止指令重排序。编译时 JVM 编译器遵循内存屏障的约束,运行时靠屏障指令组织指令顺序。
volatile解决的是一个内存读,一个内存写的问题。

概念辨析:
- 工作内存:不是真正的内存,其实就是CPU的寄存器(还可能加上CPU缓存);
- 主内存:真正的内存!
8.2.2使用volatile关键字
代码示例
在这个代码中用到了静态内部类,这是因为一开始,我想在Demo21中创建一个类Counter,但是失败了;这是因为在同一个包下,已经有了Counter这个类。而解决方案就是使用静态内部类!
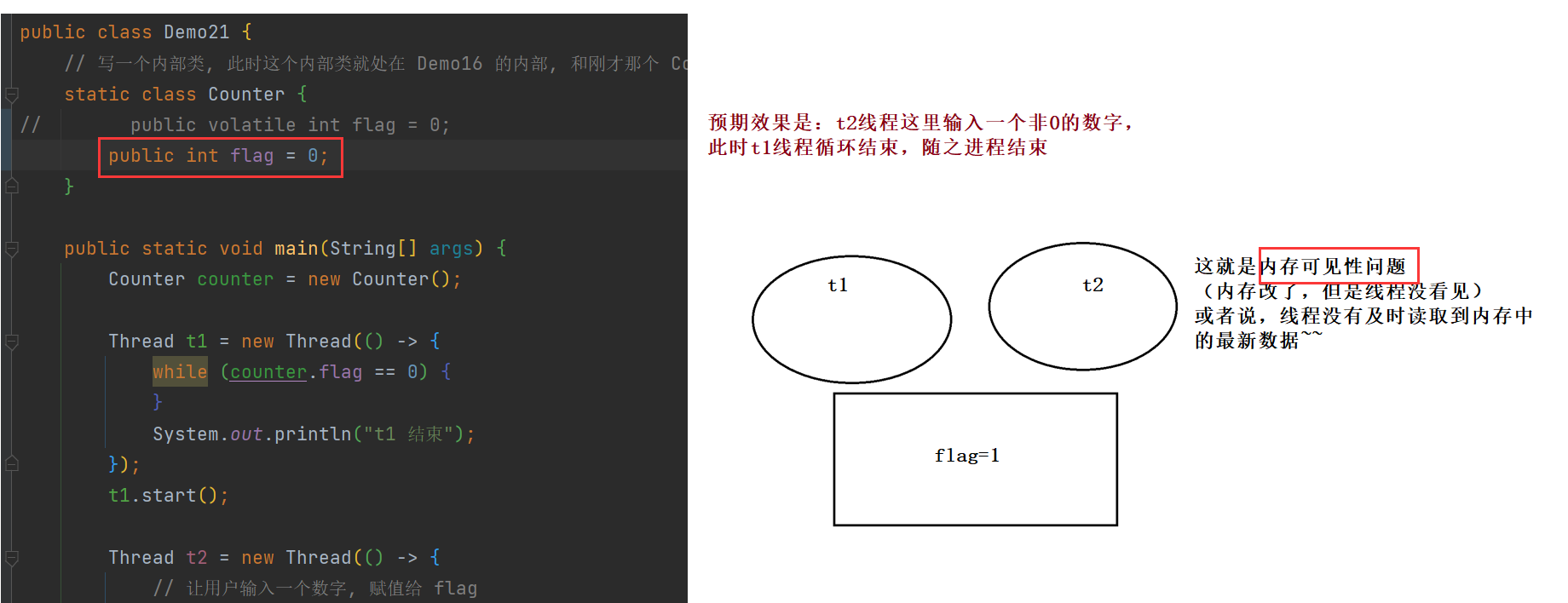
在这个代码中,创建两个线程 t1 和 t2。t1 中包含一个循环, 这个循环以 flag == 0 为循环条件;t2 中从键盘读入一个整数, 并把这个整数赋值给 flag。预期当用户输入非 0 的值的时候, t1 线程结束。
package Thread;
import java.util.Scanner;
public class Demo21 {
// 写一个内部类, 此时这个内部类就处在 Demo16 的内部, 和刚才那个 Counter 不是一个作用域了~~
static class Counter {
public int flag = 0;
}
public static void main(String[] args) {
Counter counter = new Counter();
Thread t1 = new Thread(() -> {
while (counter.flag == 0) {
// 执行循环, 但是此处循环啥都不做~~
}
System.out.println("t1 结束");
});
t1.start();
Thread t2 = new Thread(() -> {
// 让用户输入一个数字, 赋值给 flag
Scanner scanner = new Scanner(System.in);
System.out.println("请输入一个整数: ");
counter.flag = scanner.nextInt();
});
t2.start();
}
}
运行结果:
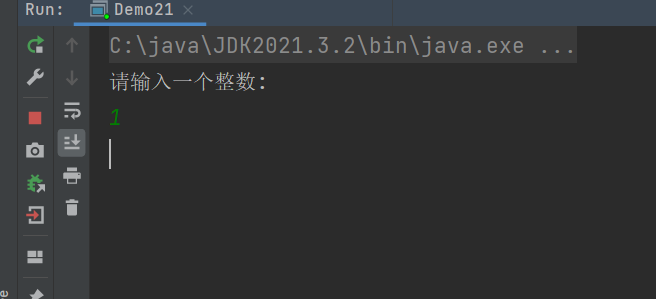
这似乎与我们的预期不否。这是因为:

优化操作一:使用volatile关键字
package Thread;
import java.util.Scanner;
public class Demo21 {
// 写一个内部类, 此时这个内部类就处在 Demo16 的内部, 和刚才那个 Counter 不是一个作用域了~~
static class Counter {
public volatile int flag = 0;
}
public static void main(String[] args) {
Counter counter = new Counter();
Thread t1 = new Thread(() -> {
while (counter.flag == 0) {
}
System.out.println("t1 结束");
});
t1.start();
Thread t2 = new Thread(() -> {
// 让用户输入一个数字, 赋值给 flag
Scanner scanner = new Scanner(System.in);
System.out.println("请输入一个整数: ");
counter.flag = scanner.nextInt();
});
t2.start();
}
}
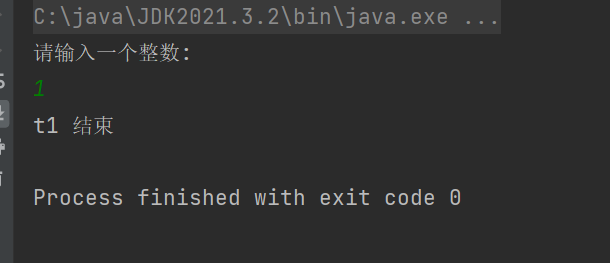
volatile操作相当于显式地禁止了编译器进行优化,JVM在读取变量时,因为内存屏障的存在,就知道要每次重新读取这个内存的内容,而不是草率地进行优化。频繁读取内存,虽然速度变慢了,但是数据计算的正确性得到了保证!
注意:volatile 和 synchronized 有着本质的区别 . synchronized 能够保证原子性 , volatile 保证的是内存可见性 .
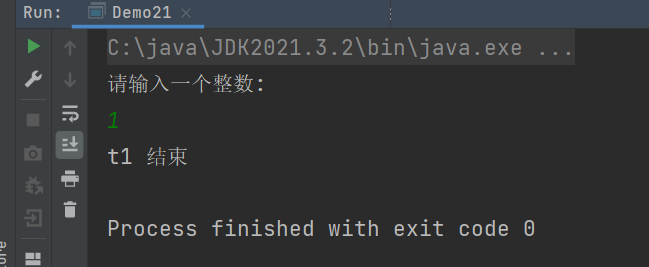
优化操作二:加sleep
package Thread;
import java.util.Scanner;
public class Demo21 {
// 写一个内部类, 此时这个内部类就处在 Demo16 的内部, 和刚才那个 Counter 不是一个作用域了~~
static class Counter {
// public volatile int flag = 0;
public int flag = 0;
}
public static void main(String[] args) {
Counter counter = new Counter();
Thread t1 = new Thread(() -> {
while (counter.flag == 0) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("t1 结束");
});
t1.start();
Thread t2 = new Thread(() -> {
// 让用户输入一个数字, 赋值给 flag
Scanner scanner = new Scanner(System.in);
System.out.println("请输入一个整数: ");
counter.flag = scanner.nextInt();
});
t2.start();
}
}

九:wait和notify
9.1 综述

由于线程之间是抢占式执行的, 因此线程之间执行的先后顺序难以预知 .
但是实际开发中有时候我们希望合理的协调多个线程之间执行的先后顺序 .
球场上的每个运动员都是独立的 “执行流” , 可以认为是一个 “线程”.

而完成一个具体的进攻得分动作, 则需要多个运动员相互配合, 按照一定的顺序执行一定的动作, 线程1 先 “传球” , 线程2 才能 “扣篮”.
完成这个协调工作, 主要涉及到以下方法:
1.wait() / wait(long timeout): 让当前线程进入等待状态;
2.notify() / notifyAll(): 唤醒在当前对象上等待的线程。
注意: wait, notify, notifyAll 都是 Object 类的方法.
9.2 wait
作用:
- 使当前执行代码的线程进入等待(把线程放到等待队列中);
- 释放当前的锁;
- 满足一定条件时被唤醒,重新尝试获取这个锁。
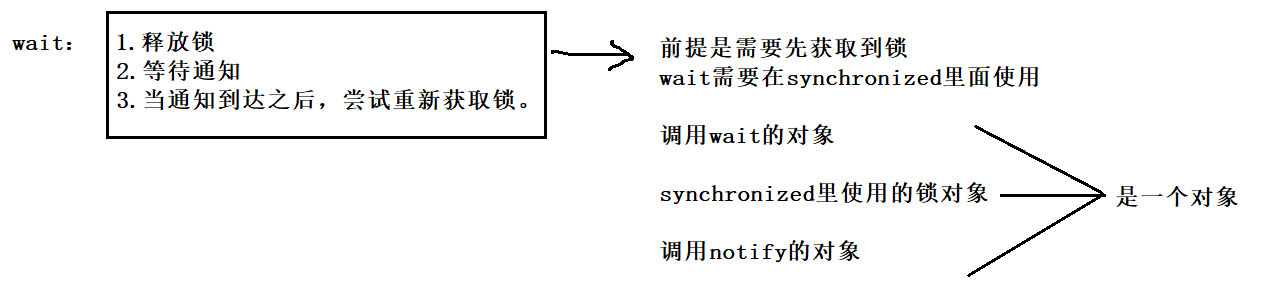
wait结束等待的条件:
- 其他线程调用该对象的notify方法;
- wait等待的时间超时(wait方法提供有一个带有timeout的版本的,可以指定等待时间)
- 其他线程调用该等待线程的interrupted方法,导致wait抛出InterruptedException异常。
代码示例:
package Thread;
public class Demo22 {
public static void main(String[] args) throws InterruptedException {
Object object = new Object();
synchronized (object){
System.out.println("wait 之前");
object.wait();
System.out.println("wait 之后");
}
}
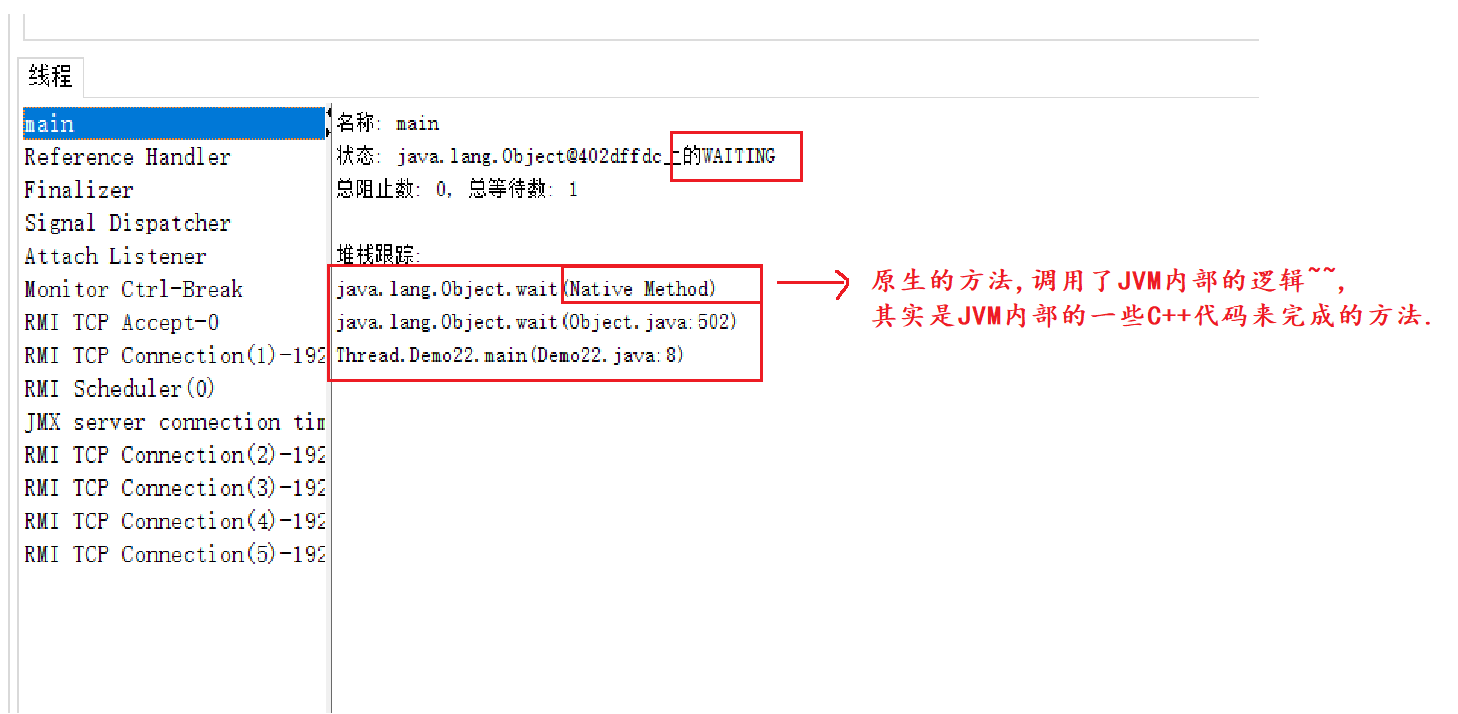
}
运行结果:
执行到object.wait()之后,会一直等待下去。
9.3 notify
notify方法是唤醒等待的线程.
方法notify()也要在同步方法或同步块中调用,该方法是用来通知那些可能等待该对象的对象锁的其它线程,对其发出通知notify,并使它们重新获取该对象的对象锁。
如果有多个线程等待,则有线程调度器随机挑选出一个呈 wait 状态的线程。(并没有 “先来后到”) . 在notify()方法后,当前线程不会马上释放该对象锁,要等到执行notify()方法的线程将程序执行完,也就是退出同步代码块之后才会释放对象锁。
notify这个东西在调用的时候,会尝试进行通知,如果当前对象没有在其他线程里wait,则不会有副作用~~
diamante示例:使用notify唤醒线程。
package Thread;
import java.util.Scanner;
//创建两个线程,一个线程调用wait,一个线程调用notify
public class Demo23 {
public static Object locker = new Object();
public static void main(String[] args) {
//创建一个用于等待的线程
Thread waitTask = new Thread(()->{
synchronized (locker){
System.out.println("wait 开始");
try {
locker.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("wait 结束");
}
});
waitTask.start();
//创建一个用于通知/唤醒的线程
Thread notifyTask = new Thread(()->{
Scanner scanner = new Scanner(System.in);
System.out.println("输入任意内容,开始通知:");
//next会阻塞,直到用户真正输入内容以后
scanner.next();
synchronized (locker){
System.out.println("notify 开始");
locker.notify();
System.out.println("notify 结束");
}
});
notifyTask.start();
}
}
使用场景 : 线程1需要先计算一个结果 , 线程2来使用这个结果~~线程2就可以wait , 线程1计算完结果之后 , notify , 唤醒线程2 .
wait和notify机制 , 还可以有效避免线程饿死.
线程饿死:有些情况下,调度器可能分配的不均匀 , 导致有些线程反复占用CPU,有些线程始终捞不着CPU .
举例说明 :
我们针对这种场景进行分析:

线程之间在系统里的调度是随机的!
一种可能的情况是 , 滑稽老哥一进来 , 发现我去 , 没钱了 ; 我出来 , 然后以迅雷不及掩耳之势又进来 , 其他滑稽(线程)根本就没有机会进入ATM取钱(占用CPU) .
一种更加可能的情况是 , 滑稽老哥1进来 , 发现我去 , 没钱了 , 我走 ; 滑稽老哥2进来 , 发现我去 , 没钱了 , 我走 ; 滑稽老哥3进来 , 发现我去 , 没钱了 , 我走 ; 这时候滑稽老哥1又进来了 , 他三隔这儿循环呢 , 那滑稽老哥4就只能问君能有几多愁 , 恰似一群太监逛青楼了 ! 滑稽老哥4(线程)根本就没有机会进入ATM取钱(占用CPU) .


解决问题的方法是:让前三个取钱的滑稽,拿到锁之后,判定当下的任务是否可以进行;如果能进行就干活,不能进行,就wait。wait来等待合适的实际再继续执行/参与锁竞争!
如果wait的是对象A,notify的是对象B,则没什么用,无法唤醒,实例如下:
package Thread;
import java.util.Scanner;
//如果我是等待locker1,通知locker2,那么没任何影响.
public class Demo24 {
public static Object locker1 = new Object();
public static Object locker2 = new Object();
public static void main(String[] args) {
//创建一个用于等待的线程
Thread waitTask = new Thread(()->{
synchronized (locker1){
System.out.println("wait 开始");
try {
locker1.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("wait 结束");
}
});
waitTask.start();
//创建一个用于通知/唤醒的线程
Thread notifyTask = new Thread(()->{
Scanner scanner = new Scanner(System.in);
System.out.println("输入任意内容,开始通知:");
//next会阻塞,直到用户真正输入内容以后
scanner.next();
synchronized (locker2){
System.out.println("notify 开始");
locker2.notify();
System.out.println("notify 结束");
}
});
notifyTask.start();
}
}
线程2已经通知完了,但线程1还没结束 , 这就是因为wait和notify是针对不同对象的 .
当有多个线程等待时 , 使用notify是一次唤醒一个(从若干个里面随机挑一个)。
9.4 notifyAll
notifyAll则是唤醒所有(再由这些线程去竞争锁)!!!!

举例说明:


9.5 wait和sleep的对比
其实理论上 wait 和 sleep 完全是没有可比性的,因为一个是用于线程之间的通信的,一个是让线程阻塞一段时间,唯一的相同点就是都可以让线程放弃执行一段时间 .
wait和sleep都会让线程进入阻塞 ,阻塞的原因和目的不同 , 进入的状态也不同 , 被唤醒的条件也不同 .
实际开发中很少会使用sleep , 目的是为了"放权" , 暂时让出当前CPU的使用权.
总结:
1.wait 需要搭配 synchronized 使用 , sleep 不需要 .
2.wait 是 Object 的方法 , sleep 是 Thread 的静态方法 .
十:多线程案例
10.1单例模式
单例模式和多例模式是校招中重点考察的两种设计模式。
什么是设计模式?
设计模式好比象棋中的 “棋谱”. 红方当头炮, 黑方马来跳. 针对红方的一些走法, 黑方应招的时候有一些固定的套路. 按照套路来走局势就不会吃亏.
软件开发中也有很多常见的 “问题场景”. 针对这些问题场景, 大佬们总结出了一些固定的套路. 按照这个套路来实现代码, 也不会吃亏.
1.目的 : 有些对象 , 在一个程序中应该只有唯一的一个实例,就可以使用单例模式~~
2.在单例模式下,对象的实例化被限制了,只能创建一个!!!

具体实现:
10.1.1 饿汉模式
类加载的同时, 创建实例 .
天然线程安全,使用静态成员表示实例(唯一性),让构造方法为私有,(堵住了new创建新实例的口子)。
package Thread;
//饿汉模式
class Singleton{
private static Singleton instance = new Singleton();
public static Singleton getInstance(){
return instance;
}
//构造方法设为私有,显式防止其他的类new
private Singleton(){
}
}
public class Demo25 {
public static void main(String[] args) {
Singleton instance = Singleton.getInstance();
Singleton instance2 = Singleton.getInstance();
System.out.println(instance == instance2);
}
}
运行结果:
说明 : 是单例模式的最基本的实现 , instance和instance2是同一个对象 .
10.1.2 懒汉模式
package Thread;
import java.awt.image.VolatileImage;
//懒汉模式
class SingletonLazy{
volatile private static SingletonLazy instance = null;
public static SingletonLazy getInstance(){
if(instance == null){
synchronized (SingletonLazy.class){
if(instance == null){
instance = new SingletonLazy();
}
}
}
return instance;
}
private SingletonLazy(){
}
}
public class Demo26 {
public static void main(String[] args) {
SingletonLazy instance = SingletonLazy.getInstance();
}
}

上面这个代码还是比较复杂,其实是有一个发展过程的。我们先看第一版,单线程下的懒汉模式:
class Singleton {
private static Singleton instance = null;
private Singleton() {}
public static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
这段代码很简单,如果没有实例化,那么就在调用getInstance时进行实例化。
上面的懒汉模式的实现是线程不安全的.
线程安全问题发生在首次创建实例时. 如果在多个线程中同时调用 getInstance 方法, 就可能导致创建出多个实例.
一旦实例已经创建好了, 后面再多线程环境调用 getInstance 就不再有线程安全问题了(不再修改instance 了) 。
加上 synchronized 可以改善这里的线程安全问题.。
class Singleton {
private static Singleton instance = null;
private Singleton() {}
public synchronized static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
懒汉模式【多线程版】
以下代码在加锁的基础上, 做出了进一步改动 :
- 使用双重 if 判定, 降低锁竞争的频率 .
- 给 instance 加上了 volatile .
class Singleton {
private static volatile Singleton instance = null;
private Singleton() {}
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}

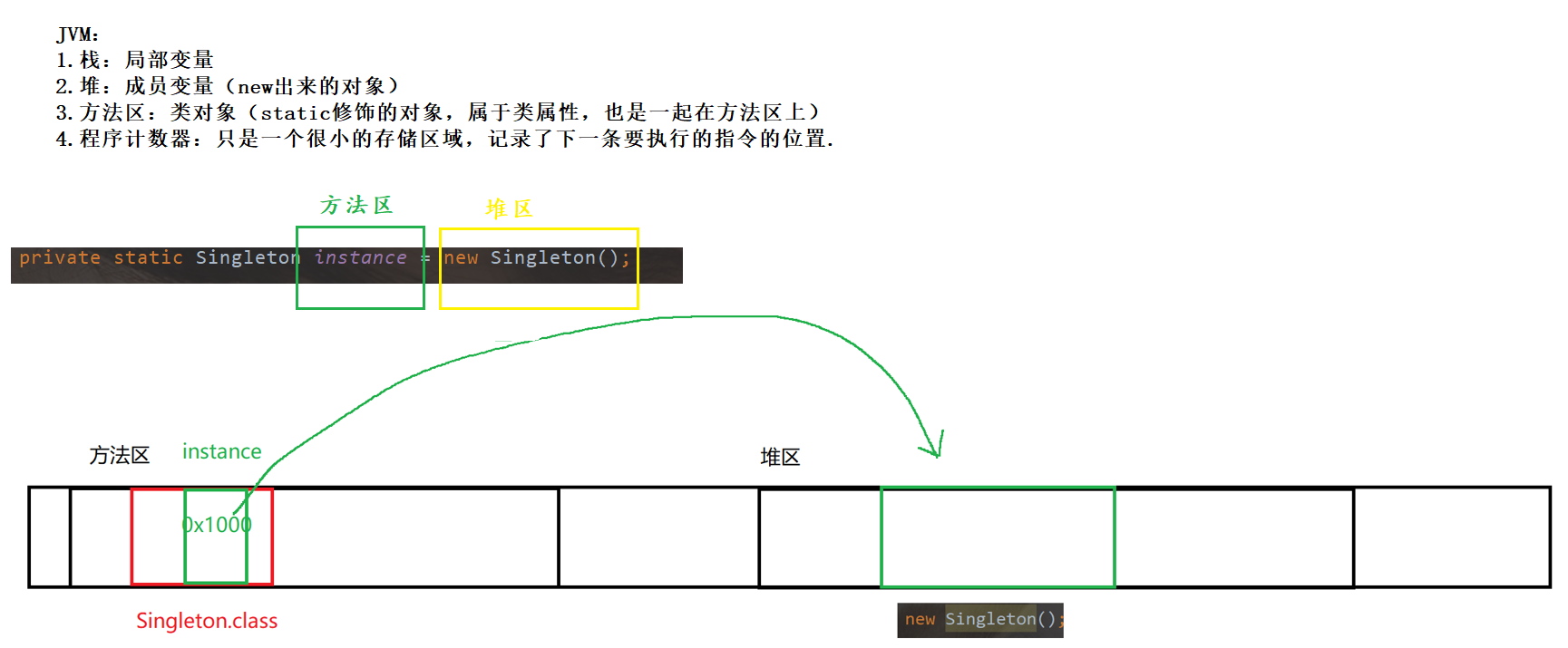
理解这里代码的关键是,不要用单线程的思维来解决多线程的问题!
- 有三个线程, 开始执行 getInstance , 通过外层的 if (instance == null) 知道了实例还没有创建的消息. 于是开始竞争同一把锁.
2) 其中线程1 率先获取到锁, 此时线程1 通过里层的 if (instance == null) 进一步确认实例是否已经创建. 如果没创建, 就把这个实例创建出来.
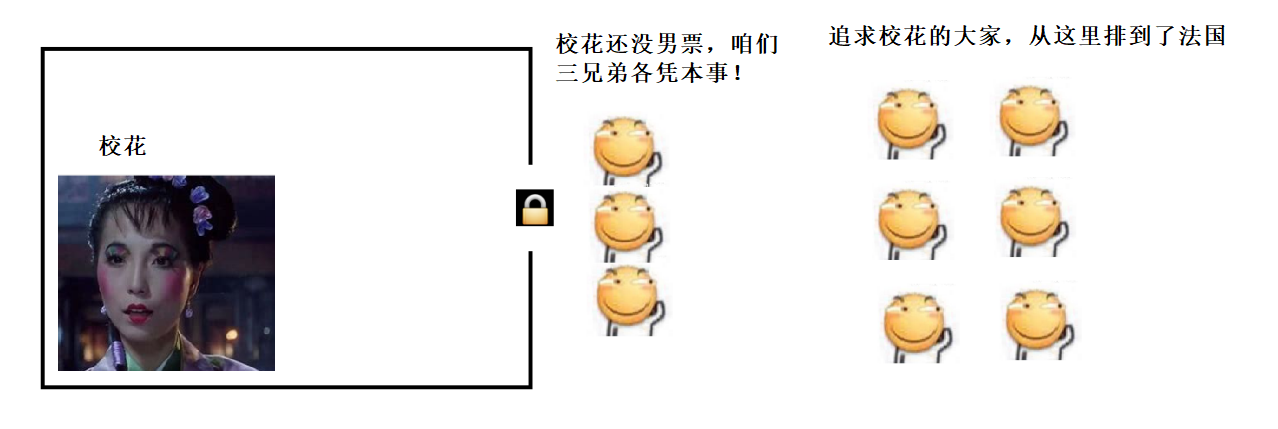
3) 当线程1 释放锁之后, 线程2 和 线程3 也拿到锁, 也通过里层的 if (instance == null) 来确认实例是否已经创建, 发现实例已经创建出来了, 就不再创建了.
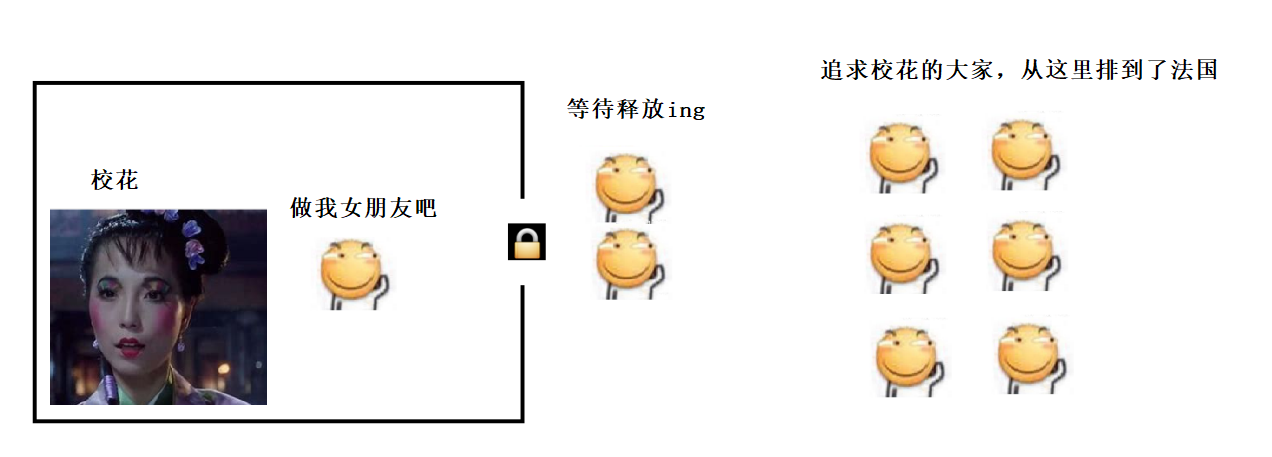
4) 后续的线程, 不必加锁, 直接就通过外层 if (instance == null) 就知道实例已经创建了, 从而不再尝试获取锁了. 降低了开销.
单例对象在哪里呢?
关于volatile,我们还有一点说法:

最终总结 :


10.2阻塞式模式

阻塞队列最重要的应用→生产者消费者模型!
生产者消费者模式就是通过一个容器来解决生产者和消费者的强耦合问题。
生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取.
现在是2023年春节联欢晚会的小品现场,请举例说明春晚小品最后一幕是什么,并说明为什么是包饺子。现在是大年初一,家家户户都要包饺子,此时有两种包法:
- 每个人都分别自己擀皮,自己包;
- 一个人擀面皮,其余人负责包。
一般情况下,一家只有一个擀面杖吧。如果使用第一种方式,效率比较低,多个线程都在抢占同一个资源(擀面杖);如果使用第二种方式,擀皮的人一直使用擀面杖,不存在资源抢占的问题。擀饺子皮的人不关心包饺子的人是谁(能包就行, 无论是手工包, 借助工具, 还是机器包), 包饺子的人也不关心擀饺子皮的人是谁(有饺子皮就行, 无论是用擀面杖擀的, 还是拿罐头瓶擀, 还是直接从超市买的).
阻塞队列有什么优势呢?
可以做到更好的解耦合。
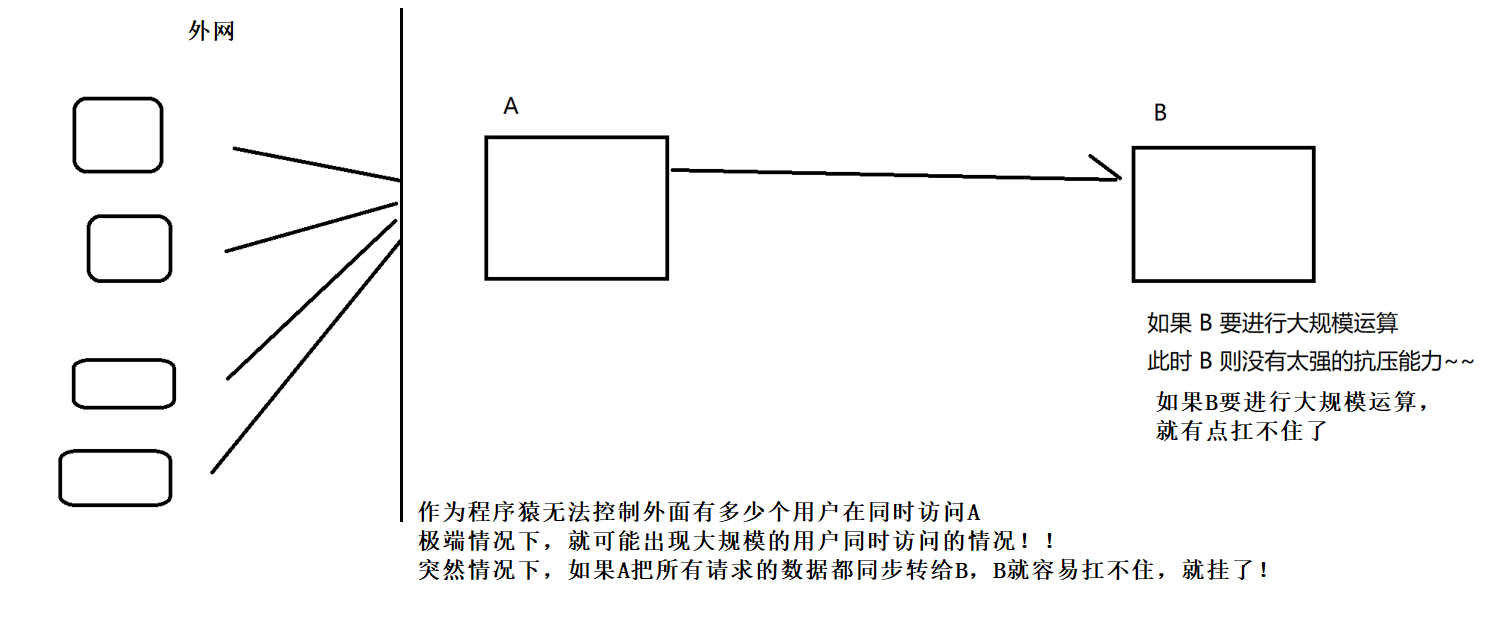
一种耦合度比较高的情形:
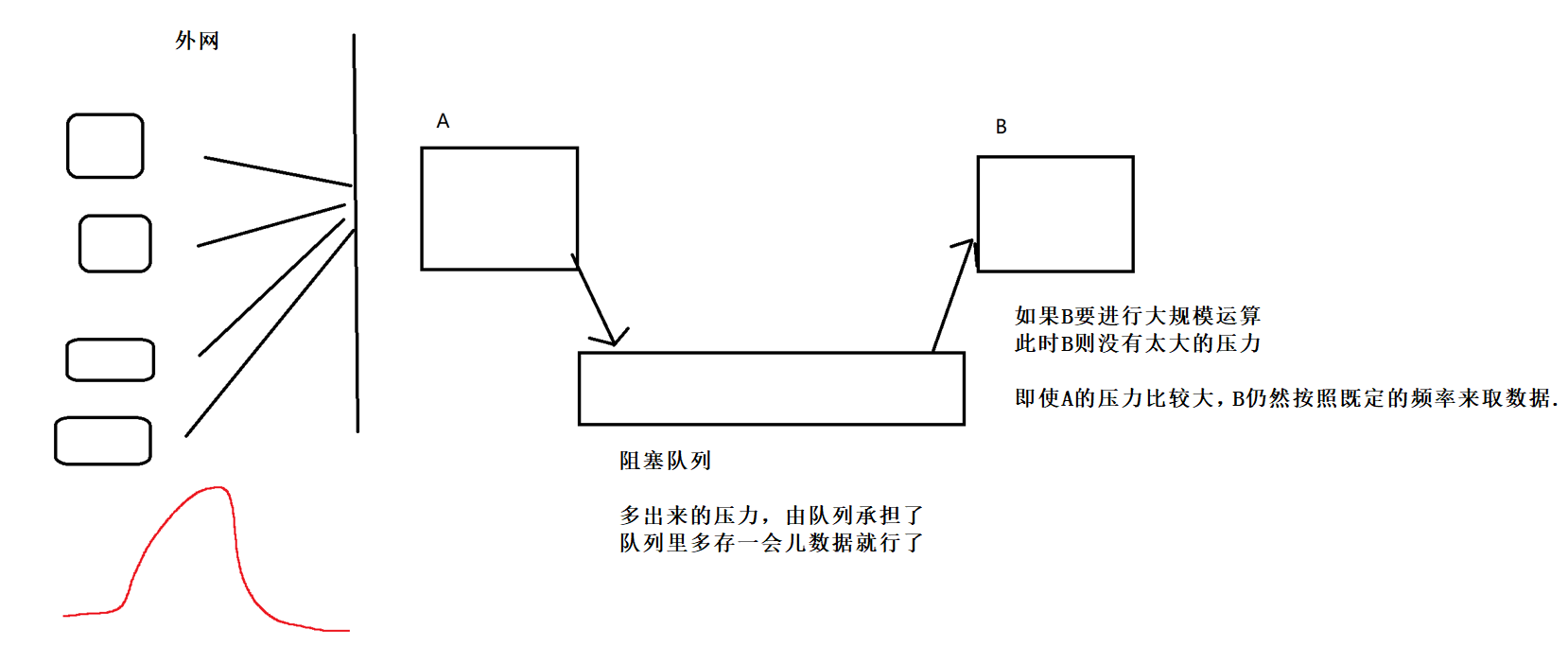
低耦合的情形是:
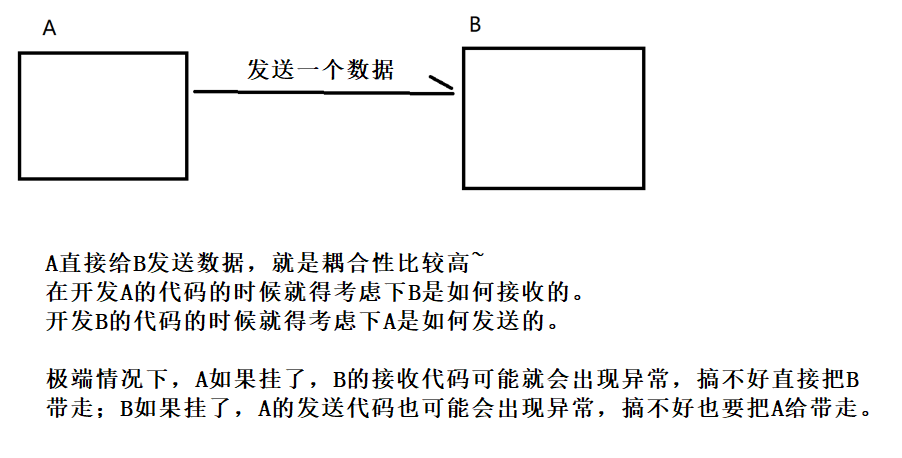
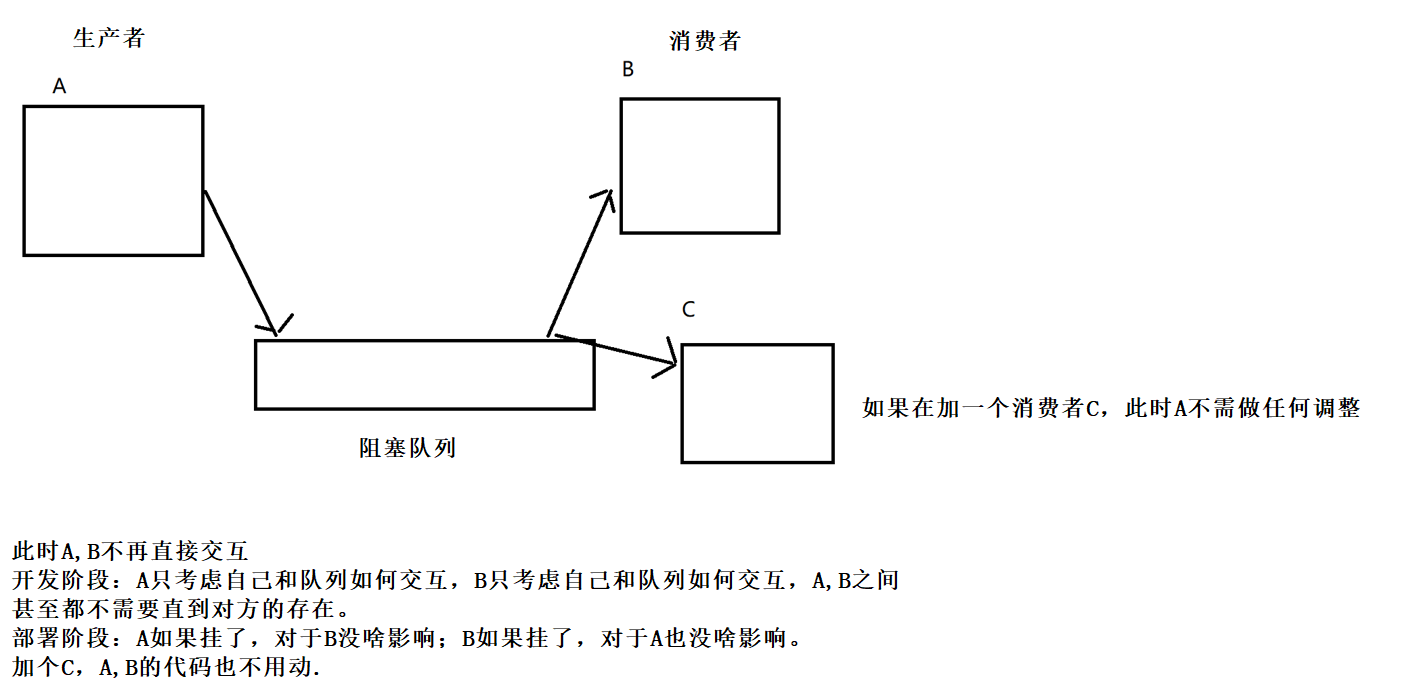
补充 : 什么是高内聚?
写一个功能的时候 , 尽量让这个功能的代码能够集中放置 , 不要"东一块 , 西一块"! 类似于"归类".
"削峰填谷",提高整个系统的抗风险能力
代码示例:


package Thread;
import java.util.concurrent.BlockingDeque;
import java.util.concurrent.LinkedBlockingDeque;
//阻塞队列的实现
public class Demo27 {
public static void main(String[] args) {
BlockingDeque<Integer> queue = new LinkedBlockingDeque<>();
//消费者模型
Thread customer = new Thread(()->{
while(true){
try {
int value = queue.take();
System.out.println("消费元素"+value);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
customer.start();
//生产者模型
Thread producer = new Thread(()->{
int n = 0;
while(true){
try {
System.out.println("生产元素" + n);
queue.put(n);
n++;
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
producer.start();
}
}
运行结果:
此时生产元素和消费元素交替出现 , 没什么规律.

package Thread;
import java.util.concurrent.BlockingDeque;
import java.util.concurrent.LinkedBlockingDeque;
//阻塞队列的实现
//生产速度较慢,所以生产一个,马上被消费
public class Demo27 {
public static void main(String[] args) {
BlockingDeque<Integer> queue = new LinkedBlockingDeque<>();
//消费者模型
Thread customer = new Thread(()->{
while(true){
try {
int value = queue.take();
System.out.println("消费元素"+value);
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
customer.start();
//生产者模型
Thread producer = new Thread(()->{
int n = 0;
while(true){
try {
System.out.println("生产元素" + n);
queue.put(n);
n++;
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
producer.start();
}
}
package Thread;
import java.util.concurrent.BlockingDeque;
import java.util.concurrent.LinkedBlockingDeque;
//阻塞队列的实现
//生产速度较快,消费速度较慢
public class Demo27 {
public static void main(String[] args) {
BlockingDeque<Integer> queue = new LinkedBlockingDeque<>();
//消费者模型
Thread customer = new Thread(()->{
while(true){
try {
int value = queue.take();
System.out.println("消费元素"+value);
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
customer.start();
//生产者模型
Thread producer = new Thread(()->{
int n = 0;
while(true){
try {
System.out.println("生产元素" + n);
queue.put(n);
n++;
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
producer.start();
}
}
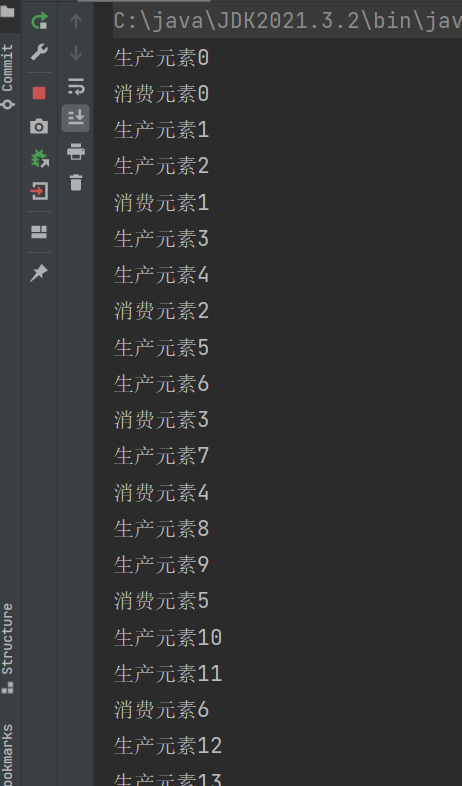
模拟实现阻塞队列:
package Thread;
/**
* 自己模拟实现一个阻塞队列
* 基于数组的方式来实现队列
* 提供两个核心方法:
* 1.put入队列
* 2.take出队列
*/
class MyBlockingQueue{
//假定最大元素是1000个
private int[] items = new int[1000];
//队首位置
private int head = 0;
//队尾位置
private int tail = 0;
//队列中元素的个数
volatile private int size = 0;
//入队列
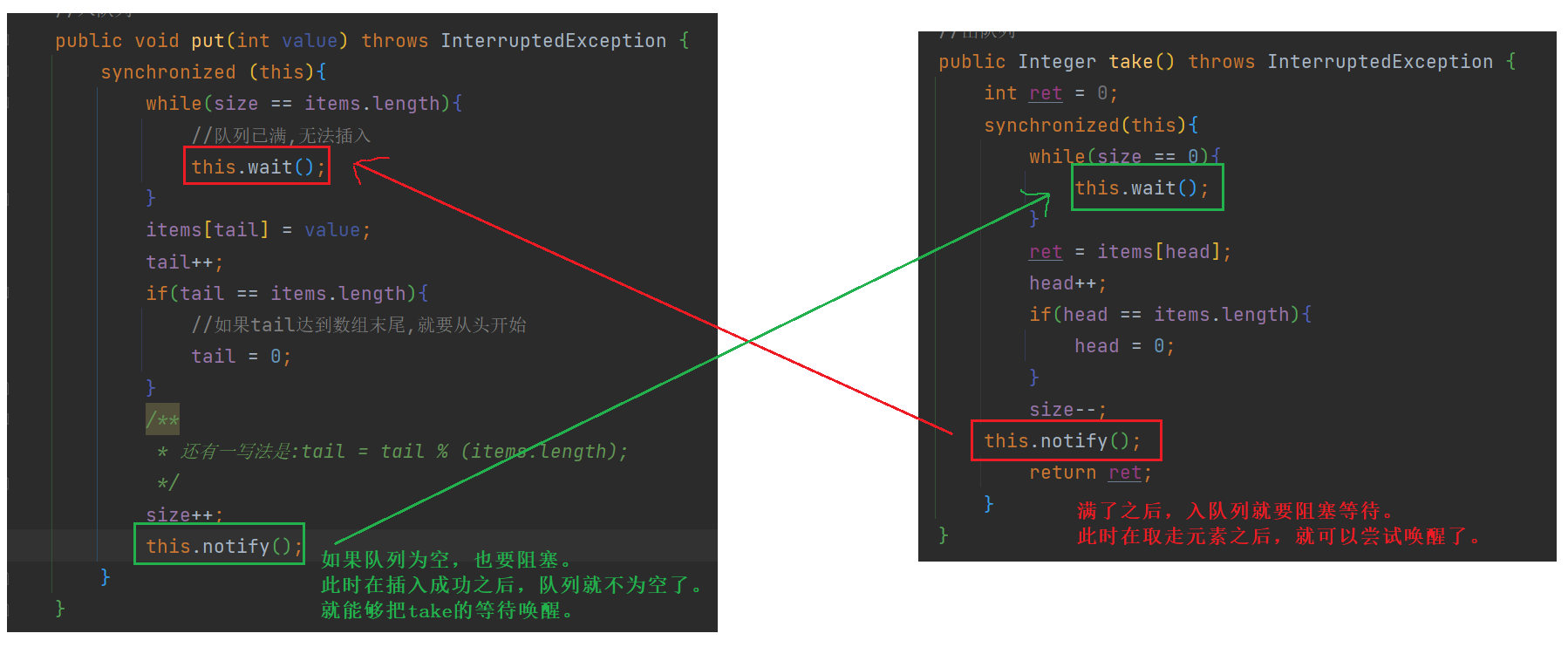
public void put(int value) throws InterruptedException {
synchronized (this){
while(size == items.length){
//队列已满,无法插入
this.wait();
}
items[tail] = value;
tail++;
if(tail == items.length){
//如果tail达到数组末尾,就要从头开始
tail = 0;
}
/**
* 还有一写法是:tail = tail % (items.length);
*/
size++;
this.notify();
}
}
//出队列
public Integer take() throws InterruptedException {
int ret = 0;
synchronized(this){
while(size == 0){
this.wait();
}
ret = items[head];
head++;
if(head == items.length){
head = 0;
}
size--;
this.notify();
return ret;
}
}
}
public class Demo28 {
public static void main(String[] args) {
MyBlockingQueue queue = new MyBlockingQueue();
Thread customer = new Thread(()->{
while(true){
int value = 0;
try {
value = queue.take();
System.out.println("消费元素"+value);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
customer.start();
Thread producer = new Thread(()->{
int value = 0;
while(true){
try {
queue.put(value);
System.out.println("生产元素" + value);
value++;
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
producer.start();
}
}
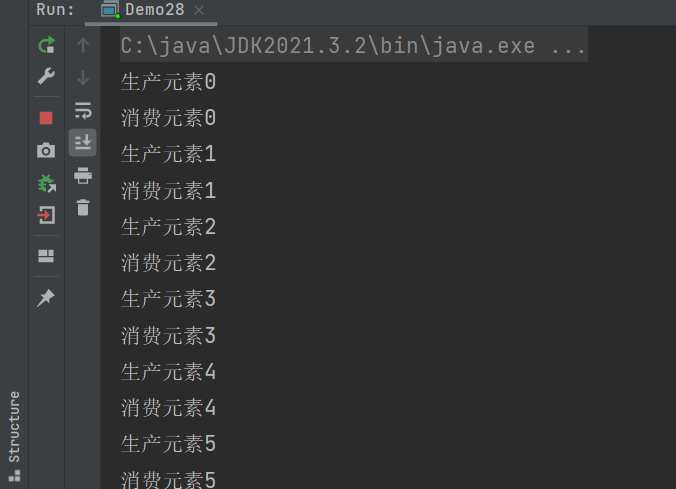
运行结果:
程序分析:


10.3 定时器
package Thread;
import java.util.Timer;
import java.util.TimerTask;
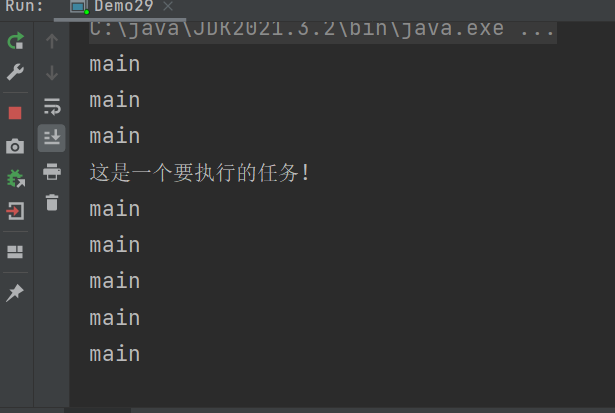
public class Demo29 {
public static void main(String[] args) throws InterruptedException {
//java.util里的一个组件
Timer timer = new Timer();
//schedule_是安排一个任务,3000ms之后再执行
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.println("这是一个要执行的任务!");
}
},3000);
while(true){
System.out.println("main");
Thread.sleep(1000);
}
}
}
Q : 定时器执行完之后线程为什么没有结束呢 ?
A : 实现定时器 , 背后涉及到多线程 ! Timer里面有线程 , 这个线程的运行阻止了进程的退出 !
Q : 为什么不用sleep呢 ?
A : 使用sleep是把当前线程给阻塞了 , sleep的时间里 , 你啥都干不了 , 只能干等。但是使用定时器 , 之前的线程该干啥干啥 !
模拟实现定时器:
Timer 其实可以往里面加入很多很多的任务的。Timer内部要组织很多的任务,Timer里的每个任务都要通过一定的方式来描述出来(自己定义一个TimerTask)。
还需要有一个线程,通过这个线程来扫描定时器内部的任务,执行其中时间到了的任务。虽然当前这里的任务有很多,但是它们的执行顺序是一定的:按照时间顺序先后,来执行。
使用优先级队列可以非常高效的找到当前时间最小的任务,此处可以使用优先级队列来组织这些任务!
package Thread;
import java.util.PriorityQueue;
import java.util.concurrent.PriorityBlockingQueue;
//通过这个类来描述一个任务
class MyTask implements Comparable<MyTask>{
//任务的内容
private Runnable command;
//任务的时间
private long time;
//提供构造方法
public MyTask(Runnable command,long after){
this.command = command;
//此处记录的时间是一个绝对的时间戳,不是"多长时间之后可以执行"
this.time = System.currentTimeMillis() + after;
}
//执行任务的方法,直接在内部调用Runnable的run即可
public void run(){
command.run();
}
public long getTime() {
return time;
}
@Override
public int compareTo(MyTask o) {
return (int)(this.time - o.time);
}
}
//自己创建定时器类
class MyTimer{
//用于阻塞等待的锁对象
private Object locker = new Object();
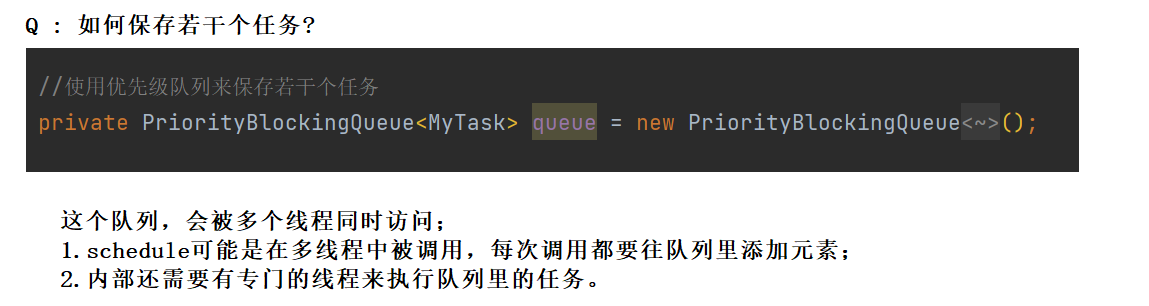
//使用优先级队列来保存若干个任务
private PriorityBlockingQueue<MyTask> queue = new PriorityBlockingQueue<MyTask>();
//command : 要执行的任务是什么
//after : 多长时间之后来执行这个任务
public void schedule(Runnable command,long after){
MyTask mytask = new MyTask(command,after);
synchronized (locker){
queue.put(mytask);
locker.notify();
}
}
//构造方法
public MyTimer(){
//在这里启动一个线程
Thread t = new Thread(()->{
while(true){
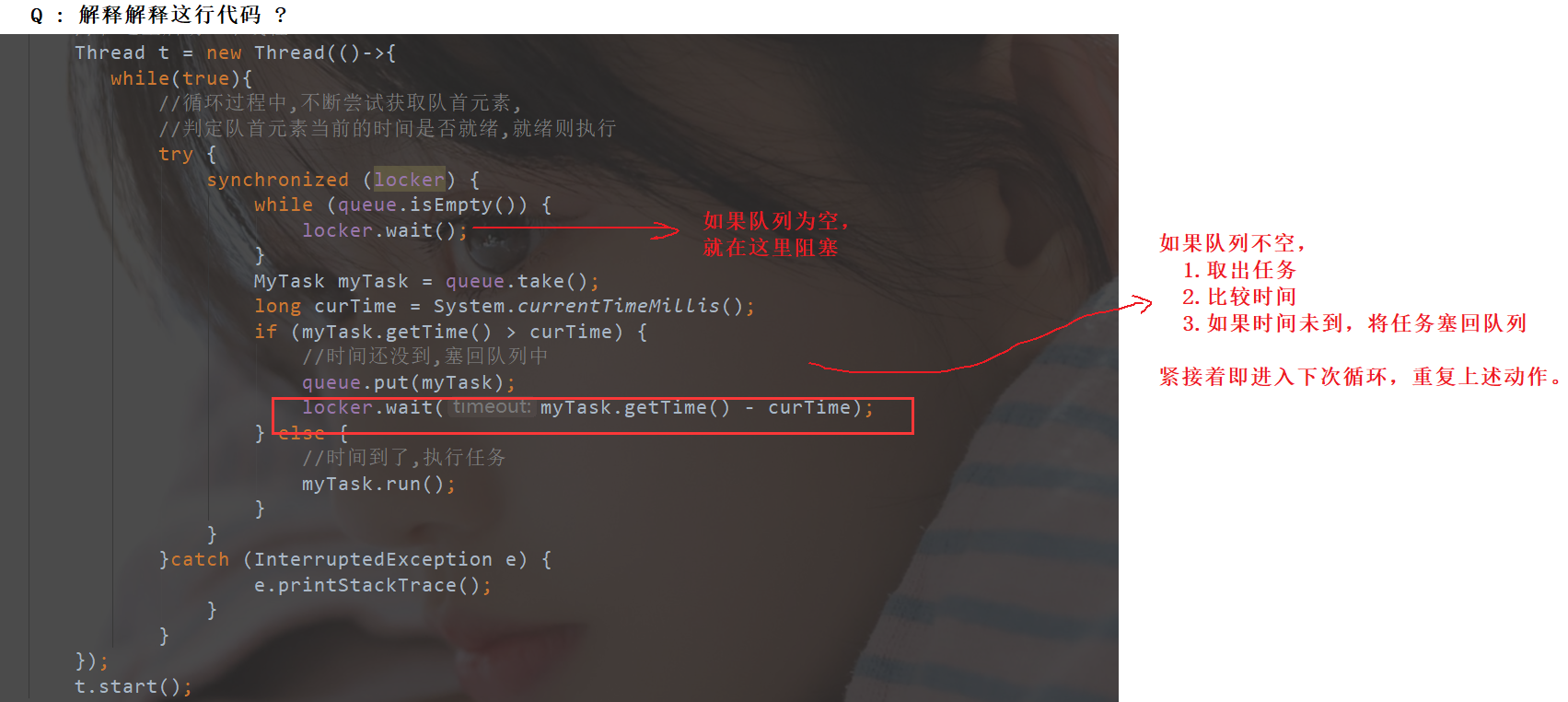
//循环过程中,不断尝试获取队首元素,
//判定队首元素当前的时间是否就绪,就绪则执行
try {
synchronized (locker) {
while (queue.isEmpty()) {
locker.wait();
}
MyTask myTask = queue.take();
long curTime = System.currentTimeMillis();
if (myTask.getTime() > curTime) {
//时间还没到,塞回队列中
queue.put(myTask);
locker.wait(myTask.getTime() - curTime);
} else {
//时间到了,执行任务
myTask.run();
}
}
}catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
}
}
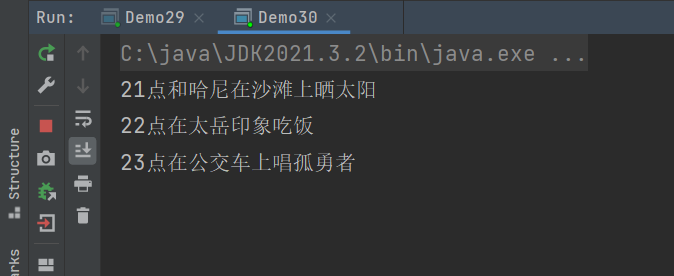
public class Demo30 {
public static void main(String[] args) {
MyTimer myTimer = new MyTimer();
myTimer.schedule(new Runnable() {
@Override
public void run() {
System.out.println("23点在公交车上唱孤勇者");
}
},6000);
myTimer.schedule(new Runnable() {
@Override
public void run() {
System.out.println("21点和哈尼在沙滩上晒太阳");
}
},2000);
myTimer.schedule(new Runnable() {
@Override
public void run() {
System.out.println("22点在太岳印象吃饭");
}
},4000);
}
}
运行结果:
程序分析:
10.4 线程池
10.4.1 什么是线程池 ?
咱们先来说说 , 为什么要有线程池 . 进程本身已经能做到并发编程了 , 为啥还要有线程 ?
进程太重量了 . 创建和销毁成本都比较高(需要申请释放资源).
线程就是针对上述问题的优化 . (共用一组系统资源) . 虽然如此 , 但频繁创建释放线程 , 线程也有点扛不住了 . 线程池就应运而生了.
线程池解决问题的思路,就是把线程创建好之后,放到池子里。
需要使用线程,就直接从池子里取,而不是通过系统来创建。
当线程用完了,也是还到池子里,而不是通过系统来销毁。
从池子里取,是纯用户态的操作;而通过系统来创建,涉及到内核态的操作。通常认为,牵扯到内核态的操作,比纯用户态的操作更加低效!
10.4.2 标准库中的线程池
Java中创建线程的方式共有以下7种:
public class Thread {
public static void main(String[] args) {
// 1. 用来处理大量短时间工作任务的线程池,如果池中没有可用的线程将创建新的线程,如果线程空闲60秒将收回并移出缓存
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
// 2. 创建一个操作无界队列且固定大小线程池
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(3);
// 3. 创建一个操作无界队列且只有一个工作线程的线程池
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
// 4. 创建一个单线程执行器,可以在给定时间后执行或定期执行。
ScheduledExecutorService singleThreadScheduledExecutor = Executors.newSingleThreadScheduledExecutor();
// 5. 创建一个指定大小的线程池,可以在给定时间后执行或定期执行。
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(3);
// 6. 创建一个指定大小(不传入参数,为当前机器CPU核心数)的线程池,并行地处理任务,不保证处理顺序
Executors.newWorkStealingPool();
// 7. 自定义线程池
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(3,
10,
10000,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
}
创建一个操作无界队列且固定大小线程池:
1.使用 Executors.newFixedThreadPool(10) 能创建出固定包含 10 个线程的线程池.
2.返回值类型为 ExecutorService
3.通过 ExecutorService.submit 可以注册一个任务到线程池中 .
package Thread;
import java.util.concurrent.Executor;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
//标准库里的线程池
public class Demo31 {
public static void main(String[] args) {
ExecutorService threadPool = Executors.newFixedThreadPool(10);
for (int i = 0; i < 100; i++) {
threadPool.submit(new Runnable() {
@Override
public void run() {
System.out.println("hello");
}
});
}
}
}

什么是“工厂方法”?
通常情况下 , 创建对象 , 是借助new , 调用构造方法来实现的.
但是C++/java里的构造方法有诸多限制 , 在很多时候不方便使用 . 因此就要给构造方法再包装一层 , 外面起到包装作用的方法就是工厂方法!
这都嘛意思?举个栗子:
Q : 创建了10个线程 , 打印输出了100个hello , 怎么办到的 ?

就像餐馆10个洗碗工洗100个盘子一样 . 10个人同时在洗 , 谁洗完一个 , 就再洗下一个.
Q : 假如9个任务 , 是不是只有9个洗碗工在工作了 ?
A : 未必 ! 可能是8个 , 也可能是1个线程在工作…但在更大的数量级下 , 各个线程之间的工作还是比较均衡的…
自定义线程池:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {}
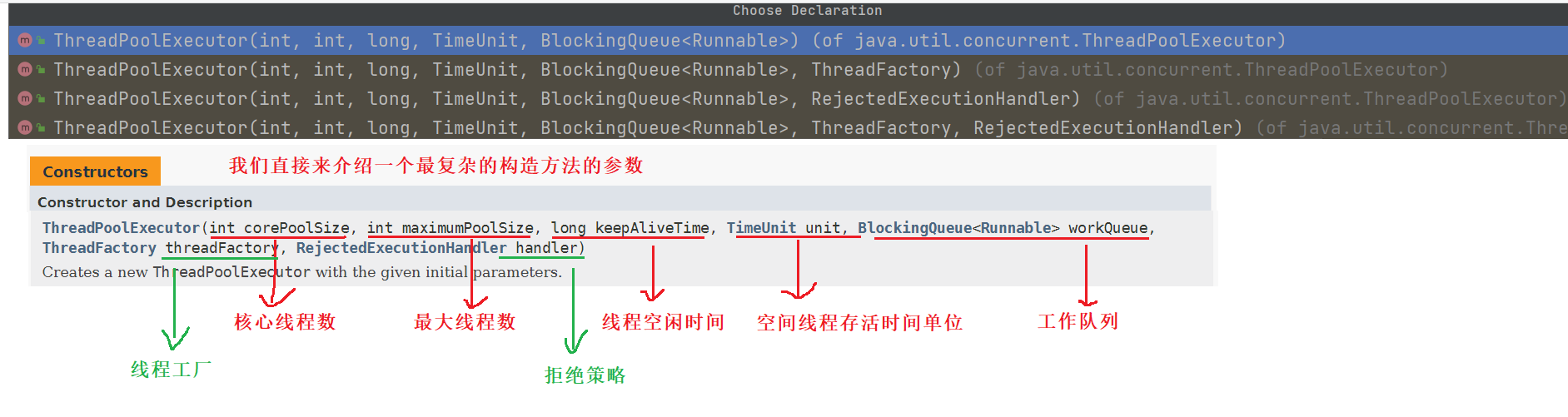
参数讲解:
一、corePoolSize 线程池核心线程大小
线程池中会维护一个最小的线程数量,即使这些线程处理空闲状态,他们也不会 被销毁,除非设置了allowCoreThreadTimeOut。这里的最小线程数量即是corePoolSize。
二、maximumPoolSize 线程池最大线程数量
一个任务被提交到线程池后,首先会缓存到工作队列(后面会介绍)中,如果工作队列满了,则会创建一个新线程,然后从工作队列中的取出一个任务交由新线程来处理,而将刚提交的任务放入工作队列。线程池不会无限制的去创建新线程,它会有一个最大线程数量的限制,这个数量即由maximunPoolSize来指定。
三、keepAliveTime 空闲线程存活时间
一个线程如果处于空闲状态,并且当前的线程数量大于corePoolSize,那么在指定时间后,这个空闲线程会被销毁,这里的指定时间由keepAliveTime来设定
四、unit 空间线程存活时间单位
keepAliveTime的计量单位
五、workQueue 工作队列
新任务被提交后,会先进入到此工作队列中,任务调度时再从队列中取出任务。JDK中提供了四种工作队列:
①ArrayBlockingQueue
基于数组的有界阻塞队列,按FIFO排序。新任务进来后,会放到该队列的队尾,有界的数组可以防止资源耗尽问题。当线程池中线程数量达到corePoolSize后,再有新任务进来,则会将任务放入该队列的队尾,等待被调度。如果队列已经是满的,则创建一个新线程,如果线程数量已经达到maxPoolSize,则会执行拒绝策略。
②LinkedBlockingQuene
基于链表的无界阻塞队列(其实最大容量为Interger.MAX),按照FIFO排序。由于该队列的近似无界性,当线程池中线程数量达到corePoolSize后,再有新任务进来,会一直存入该队列,而不会去创建新线程直到maxPoolSize,因此使用该工作队列时,参数maxPoolSize其实是不起作用的。
③SynchronousQuene
一个不缓存任务的阻塞队列,生产者放入一个任务必须等到消费者取出这个任务。也就是说新任务进来时,不会缓存,而是直接被调度执行该任务,如果没有可用线程,则创建新线程,如果线程数量达到maxPoolSize,则执行拒绝策略。
④PriorityBlockingQueue
具有优先级的无界阻塞队列,优先级通过参数Comparator实现。
六、threadFactory 线程工厂
创建一个新线程时使用的工厂,可以用来设定线程名、是否为daemon线程等等。
七、handler 拒绝策略
当工作队列中的任务已到达最大限制,并且线程池中的线程数量也达到最大限制,这时如果有新任务提交进来,该如何处理呢。这里的拒绝策略,就是解决这个问题的,jdk中提供了4种拒绝策略:
①CallerRunsPolicy
该策略下,在调用者线程中直接执行被拒绝任务的run方法,除非线程池已经shutdown,则直接抛弃任务。
②AbortPolicy
该策略下,直接丢弃任务,并抛出RejectedExecutionException异常。
③DiscardPolicy
该策略下,直接丢弃任务,什么都不做
④DiscardOldestPolicy
该策略下,抛弃进入队列最早的那个任务,然后尝试把这次拒绝的任务放入队列。
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
/**
* 使用ThreadPoolExecutor创建一个忽略最新任务的线程池,创建规则:
* 1.核心线程数为5
* 2.最大线程数为10
* 3.任务队列为100
* 4.拒绝策略为忽略最新任务
*/
public class Test68 {
public static void main(String[] args) throws InterruptedException {
// 创建线程池
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(5, // 核心线程数
10, // 最大线程数
3, // 线程空闲时长
TimeUnit.SECONDS, // 线程空闲时长的时间单位
new LinkedBlockingQueue<>(100), // 任务队列
new ThreadPoolExecutor.DiscardPolicy()); // 拒绝策略为忽略最新任务
// 测试执行
for (int i = 0; i < 2000; i++) {
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "已执行.");
},"thread-" + (i + 1)).start();
}
}
}
10.4.3 模拟实现线程池
package Thread;
import java.util.concurrent.BlockingDeque;
import java.util.concurrent.LinkedBlockingDeque;
//自己实现线程池类
//简单起见,固定10个线程的线程池
class MyThreadPool{
//搞一个"任务队列",把当前线程池要完成的任务都放到这个队列中
//再由线程池内部的工作线程负责完成他们
private BlockingDeque<Runnable> queue = new LinkedBlockingDeque<>();
//核心方法:往线程池里插入任务
public void submit(Runnable runnable){
try {
queue.put(runnable);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//通过构造方法,设定线程池里有几个线程
public MyThreadPool(int n){
for (int i = 0; i < n; i++) {
Thread t = new Thread(()->{
while(!Thread.currentThread().isInterrupted()){
Runnable runnable = null;
try {
runnable = queue.take();
runnable.run();
} catch (InterruptedException e) {
e.printStackTrace();
break;
}
}
});
t.start();
}
}
}
public class Demo32 {
public static void main(String[] args) {
MyThreadPool myThreadPool = new MyThreadPool(10);
for (int i = 0; i < 100; i++) {
myThreadPool.submit(new Runnable() {
@Override
public void run() {
System.out.println("hello");
}
});
}
}
}
程序分析:
由于可以一次插入多个任务 , 需要把当前尚未执行的任务都保存起来 →使用阻塞队列 !
线程池和字符串常量池 , 有什么区别和联系呢?
线程池和字符串常量池都是概念!!(广义的概念)
Java里面JVM中实现了字符串常量池.我们在自己写的Java业务代码中,也能实现自己版本的字符串常量池.
Python解释器里面也实现了字符串常量池,咱们自己写的 Python 业务代码中,也能实现自己版本的字符串常量池.
在Java标准库中提供了线程池的实现,我们自己也可以写自己版本的实现.
Python标准库里也有线程池的实现,咱们也可以自己实现自己的版本…
10.4.4 线程池的优点
- 降低资源消耗:减少线程的创建和销毁带来的性能开销。
- 提高响应速度:当任务来时可以直接使用,不用等待线程创建
- 可管理性: 进行统一的分配,监控,避免大量的线程间因互相抢占系统资源导致的阻塞现象。
多线程初阶部分的内容到此结束!