0 Summary:
Title: Multi-Behavior Hypergraph-Enhanced Transformer for Sequential Recommendation
conference: KDD 2022
论文链接:https://arxiv.org/pdf/2207.05584.pdf
Abstract:
学习动态用户偏好是序列推荐(sequential recommendations)的重要组成部分,但现有的方法主要集中在具有单一交互类型的项目序列表示上,因此仅限于捕获用户和项目之间的动态异构关系结构(例如,页面查看,添加到收藏夹,购买)
本文设计了一个多行为超图增强型Transformer框架 (Multi Behavior Hypergraph-enhanced Transformer :MBHT)来捕获短期和长期的跨类型行为依赖性。
具体来说:多尺度 Transformer 结合低秩自注意力从细粒度和粗粒度级别联合编码行为感知序列模式。并将全局多行为依赖项引入到超图神经架构中,以捕获分层的长期项目相关性
粒度,可以理解为目标所容纳的逻辑。一个项目模块(或子模块)分得越多,每个模块(或子模块)越小,负责的工作越细,就说粒度越细,否则为粗粒度 。
粒度更细,就能抽象出了更多的模型对应现实逻辑。
粗粒度和细粒度是一个相对的概念
**序列推荐(sequential recommendations):**参考论文《Sequential Recommender Systems: Challenges, Progress and Prospects》
它通过对用户(user)行为序列,比如购买商品(item)的序列(sequence)来建模,学到user 兴趣的变化,从而能够对用户下一个行为进行预测。序列推荐的模型,随着整个CS research领域的发展,也是一直在不断变化。从最开始的Markov chain,到后来的RNN,CNN模型,以及现在流行的transformer。每个时期的序列推荐模型,基本上也是对应着该时期用的比较多的NLP模型。
原文链接:https://blog.csdn.net/paper_reader/article/details/109325928
超图(Hypergraph) 简单来说,我们所熟悉的图而言,它的****一条边*(edge)只能连接两个顶点*(vertice);而超图,人们定义它的一条边(hyperedge)可以和任意个数的顶点连接。下图曲线和直线都属于超图的边,可连接不止两个顶点。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-C4H6lD8d-1661160872248)(C:\Users\杨\AppData\Roaming\Typora\typora-user-images\image-20220819192510694.png)]
**低秩(Low-rank):**从物理意义上讲,矩阵的秩度量的就是矩阵的行列之间的相关性。
可以理解为如果矩阵之间相关性很强,那么其便可以投影到更低维的线性子空间,将可以使用更少的向量表示(手动求秩的流程)那么就可以说其是低秩的。
那么如果矩阵表达的是结构性信息,例如本文中的用户-商品推荐表,矩阵各行之间存在这一定的相关性,那这个矩阵一般就是低秩的。
提供了一种协同过滤的思路,假设用户行为矩阵具有低秩的特性,那么是否可以根据这一特性预测其行为
文章目录
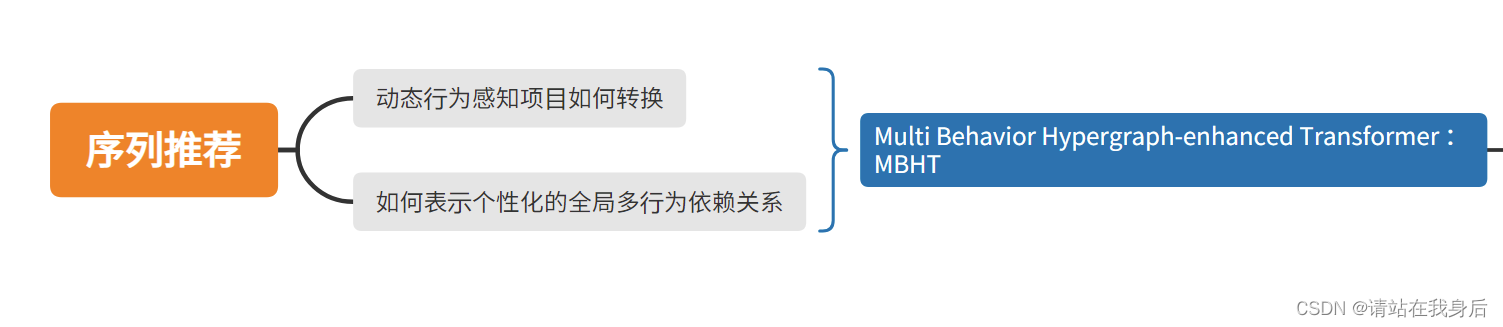
1.简介
序列推荐旨在根据用户过去的行为序列预测未来用户的交互项目,虽然已经有很多研究,但大多数都只有单一类型交互,没有考虑多类型的用户-项目关系。
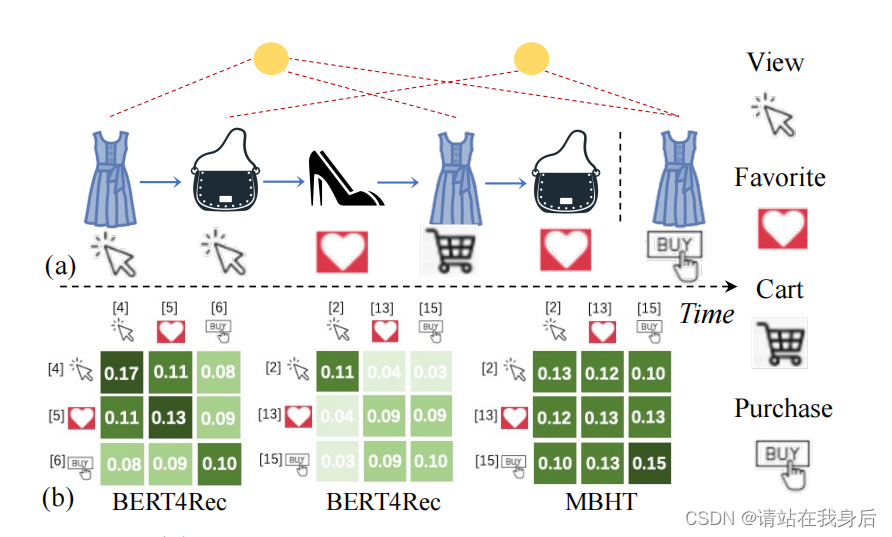
a:使用多行为动态的顺序推荐示例。
b:通过BERT4Rec和本文的MBHT学习到的行为感知的依赖权重:
可以看出本方法可以给好的展现多行为依赖
需要解决的问题
**动态行为感知项目转换:**如何明确捕获动态行为感知项目转换动态多阶关系学习范式多尺度时间动态仍然是一个问题。(存在不同的周期性行为:每日每周每月)(越南在不同类型的物品:日用品季节性服装)因此需要通过细粒度到粗粒度的时间级别显式的捕获行为感知项目转换的多尺度序列效应
**个性化的全局多行为依赖关系:**随着时间的推移,不同类型行为的隐式依赖因用户而异。例如,由于个性化和多样化的用户交互偏好,有些人会想要将产品添加到他们喜欢的列表中。其他人可能更喜欢生成他们最喜欢的商品列表,其中包含他们很可能购买的产品。也就是说,对于不同的用户,不同的行为对他们的兴趣有不同的时间感知依赖性。此外,逐项的(item-wise)多行为依赖关系超越了两两关系,可能表现出三元或事件高阶。因此,设计的模型需要使用动态多阶关系学习范式对不同用户的多行为依赖进行量身定制的建模。
注意力机制可以分为四类:基于输入项的柔性注意力(Item-wise Soft Attention)、基于输入项的硬性注意力(Item-wise Hard Attention)、基于位置的柔性注意力(Location-wise Soft Attention)、基于位置的硬性注意力(Location-wise Hard Attention)。
2 问题界定
Behavior-aware交互序列:
用户
u
i
∈
U
存在
b
e
h
a
v
i
o
r
−
a
w
a
r
e
交互序列
S
i
=
[
(
𝑣
𝑖
,
1
,
𝑏
𝑖
,
1
)
,
.
.
.
,
(
𝑣
𝑖
,
𝑗
,
𝑏
𝑖
,
𝑗
)
,
.
.
.
,
(
𝑣
𝑖
,
𝐽
,
𝑏
𝑖
,
𝐽
)
]
定义
b
i
,
j
表示
S
i
中
u
i
和第
j
个项目
v
j
之间交互的类型(查看,收藏等)
用户u_i \in U \\存在behavior-aware交互序列S_i =[(𝑣_{𝑖,1}, 𝑏_{𝑖,1}), ..., (𝑣_{𝑖,𝑗}, 𝑏_{𝑖,𝑗}), ..., (𝑣_{𝑖,𝐽} , 𝑏_{𝑖,𝐽} )]\\ 定义b_{i,j}表示S_i中u_i和第j个项目v_j之间交互的类型(查看,收藏等)
用户ui∈U存在behavior−aware交互序列Si=[(vi,1,bi,1),...,(vi,j,bi,j),...,(vi,J,bi,J)]定义bi,j表示Si中ui和第j个项目vj之间交互的类型(查看,收藏等)
任务制定:
我们将与我们想要预测的行为类型的交互作用视为目标行为。其他类型的用户行为被定义为辅助行为,提供关于用户不同偏好的各种行为上下文信息。
输入:每个用户的行为感知交互序列(到J为止)
输出:能预测用户(u)与项目(v_j+1)通过目标行为(确定的b)在下一步(J+1)交互的概率的函数
3 模型
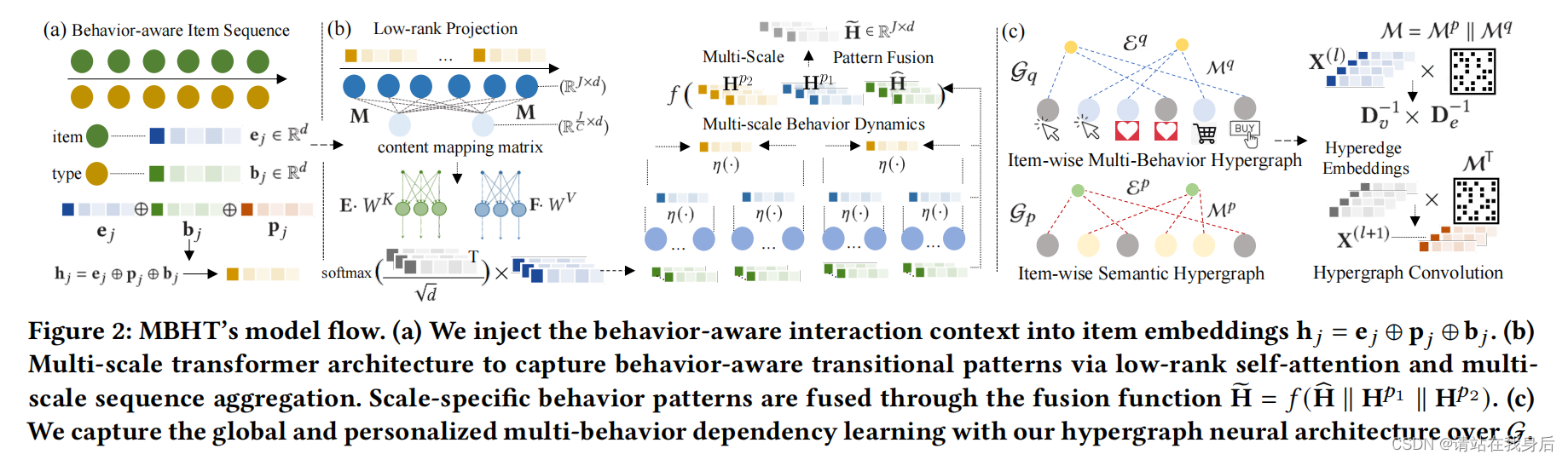
模型由三模块构成
1.对用户偏好的行为感知过渡形态的多尺度建模
Multi-scale modeling of behavior-aware transitional patterns of user preference
2.时间感知的用户交互的多行为依赖的全局学习
Global learning of multi-behavior dependencies of time-aware user interactions;
3.使用序列行为感知过渡模式和超图增强多行为依赖的编码表示的跨视图聚合
Cross-view aggregation with the encoded representations of sequential behavior-aware transitional patterns and hypergraph-enhanced multi-behavior dependencies.
a)将行为感知的交互上下文注入到条目嵌入中
b)基于低秩自注意和多尺度序列聚合的多尺度变压器结构捕获行为感知的过渡模式。通过融合函数融合尺度特定的行为模式
c)利用G上的超图神经架构来捕捉全局和个性化的多行为依赖性学习。
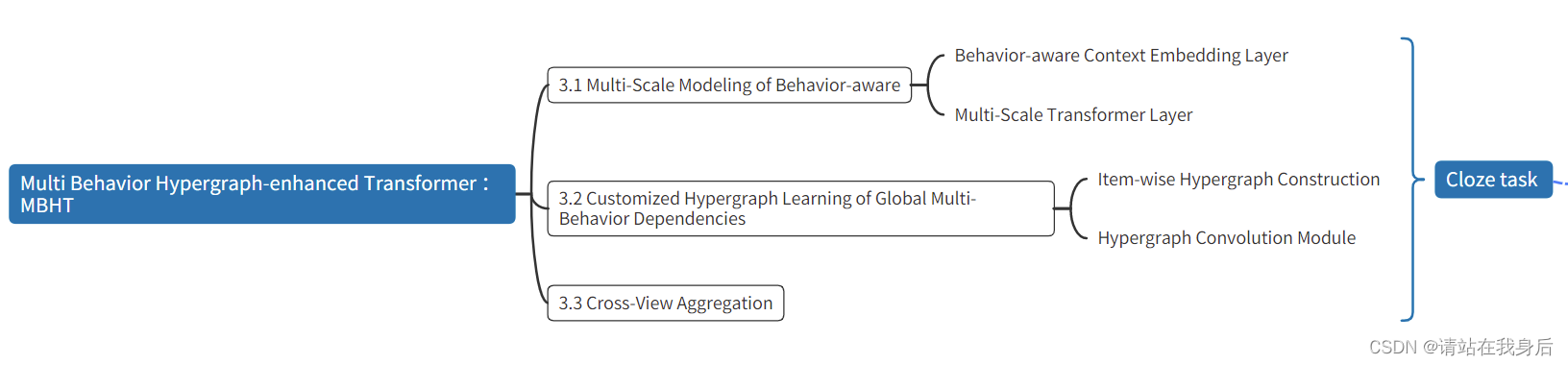
3.1 Multi-Scale Modeling of Behavior-aware
多尺度建模行为序列模式:多尺度建模行为序列模式使用多尺度动态捕获行为感知用户兴趣方面的技术细节
3.1.1 Behavior-aware Context Embedding Layer:
行为感知的上下文嵌入:
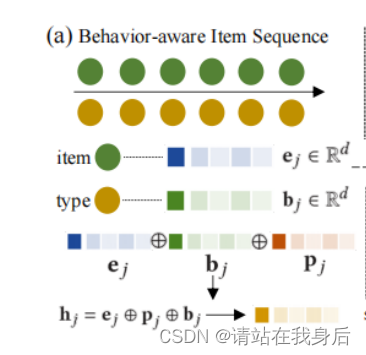
为了将交互信息引入序列学习框架,本节将单项信息与相应的交互行为上下文信号联合编码。将行为感知的潜在表示如下
h
j
=
e
j
⊕
p
j
⊕
b
j
e
j
为初始项嵌入,
b
j
为其交互类型的嵌入,
p
j
表示物品可选的位置嵌入
h_j = e_j \oplus p_j \oplus b_j\\ e_j 为初始项嵌入,b_j 为其交互类型的嵌入,p_j表示物品可选的位置嵌入
hj=ej⊕pj⊕bjej为初始项嵌入,bj为其交互类型的嵌入,pj表示物品可选的位置嵌入
p 用于区分不同交互物品的时间顺序信息
3.1.2 Multi-Scale Transformer Layer:
多尺度Transformer层:
在现实中,随着时间的推移,用户-物品交互偏好可能表现出多尺度的过渡形态。
例如我每周或每三天需要找不同类型的论文
为解决这个问题,提出了基于Transformer架构的多尺度序列偏好编码器来捕捉用户交互中的多粒度行为动态
多粒度表达式的粒度,可以理解成一种计算的方式。如果希望在计算的同时能排除掉另一维度对当前这个字段的影响,或者希望对当前这个字段进行计算的同时又能包含其他维度等类似的计算,多粒度就是指我们对于这样的计算可以有多种类型。它的存在是为了解决一些复杂计算,或者说给出一种更便捷的计算方式,相比以前的表达式,它的强大之处在于,可以仅通过一个式子就达到以前需要用多个表达式进行复杂调用的效果,另一方面,表达式的过多使用是会影响系统的性能的,现在一个多粒度表达式就能更加方便快捷的实现,所以从另一方面也是对系统性能进行了优化。
Low-Rank Self-Attention Module:
低秩自注意力:
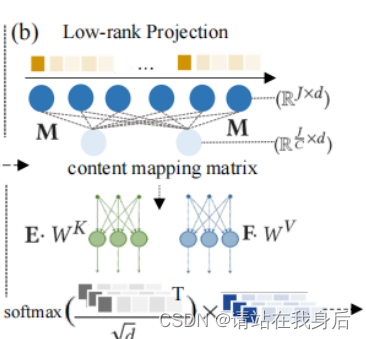
Transformer 很适合关系型数据建模,但其自注意力机制存在高计算成本问题,本文设计了一个不含二次注意操作的低秩自注意层来近似线性模型复杂度。
通过低秩分解产生多个较小的注意力操作来拟合原始注意力,首先定义两个可训练投影矩阵来进行低秩嵌入变换 :
E
∈
R
J
C
×
J
a
n
d
F
∈
R
J
C
×
J
C
代表低秩的尺度,
J
C
代表低秩潜在表示空间的数目
E \in R^{\frac JC \times J }and F \in R^{\frac JC \times J }\\ C代表低秩的尺度,\frac JC 代表低秩潜在表示空间的数目
E∈RCJ×JandF∈RCJ×JC代表低秩的尺度,CJ代表低秩潜在表示空间的数目
就此,将低秩自注意力表示如下
H
^
=
s
o
f
t
m
a
x
(
H
⋅
W
Q
(
E
⋅
H
⋅
W
K
)
T
d
)
⋅
F
⋅
H
⋅
W
V
W
为用于嵌入的可学习的变换矩阵,
E
,
F
被用于将
H
⋅
W
转化为低秩嵌入
H
^
\hat H = softmax(\frac {H \cdot W^Q(E \cdot H \cdot W^K)^T} {\sqrt d}) \cdot F\cdot H\cdot W^V\\ W为用于嵌入的可学习的变换矩阵,E,F被用于将H \cdot W 转化为低秩嵌入 \hat H
H^=softmax(dH⋅WQ(E⋅H⋅WK)T)⋅F⋅H⋅WVW为用于嵌入的可学习的变换矩阵,E,F被用于将H⋅W转化为低秩嵌入H^
通过对原始注意操作进行低秩因子分解,我们计算出上下文映射矩阵,比起原注意力网络的维度大大下降,降低了计算成本
O
(
J
×
J
)
t
o
O
(
J
×
J
C
)
J
C
<
<
J
O(J \times J)\ to\ O(J \times \frac JC)\\ \frac JC <<J
O(J×J) to O(J×CJ)CJ<<J
Multi-Scale Behavior Dynamics:
多尺度行为动态
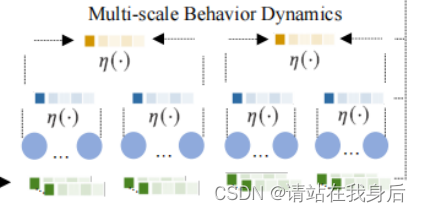
为了使MBHT具有多尺度行为过渡形态的有效学习,我们建议用一个分层结构来增强我们的基于低秩的转换器,从而捕获粒度特定的行为动态。
利用一个粒子感知聚合器来生成例子特定的表示g_p,保留短期行为的动态,将p定义为特定例子的子序列长度,呈现例子感知的嵌入生成如下
Γ
p
=
{
γ
1
,
…
,
γ
J
P
}
=
[
η
(
h
1
,
…
,
h
p
)
;
…
:
η
(
h
J
−
p
+
1
,
…
,
h
J
)
]
\Gamma ^p = \{ \gamma _1,…,\gamma_{\frac JP}\}=[\eta(h_1,…,h_p);…:\eta(h_{J-p+1},…,h_J)]
Γp={γ1,…,γPJ}=[η(h1,…,hp);…:η(hJ−p+1,…,hJ)]
这里利用平均池来执行嵌入聚合,之后,我们将粒度感知的行为表示输入到自我注意层,编码粒度特定的行为模式,如下所示:
H
𝑝
=
s
o
f
t
m
a
x
(
Γ
𝑝
⋅
𝑊
𝑝
𝑄
(
Γ
𝑑
⋅
𝑊
𝑝
𝐾
)
T
)
d
⋅
Γ
𝑝
⋅
𝑊
𝑝
𝑉
H^𝑝 = softmax( \frac{ \Gamma ^𝑝 ·𝑊_𝑝^𝑄 (\Gamma ^𝑑 ·𝑊_𝑝^𝐾)^T ) }{\sqrt d}· \Gamma ^𝑝 ·𝑊_𝑝^𝑉
Hp=softmax(dΓp⋅WpQ(Γd⋅WpK)T)⋅Γp⋅WpV
在我们的MBHT框架中,我们设计了一个具有两种不同规模设置(𝑝1𝑝2)的分层Transformer网络。相应地,我们的多尺度Transformer可以产生三个特定尺度的序列行为嵌入
H
^
∈
R
J
×
d
,
H
p
1
∈
R
J
p
1
×
d
,
H
p
2
∈
R
J
p
2
×
d
\hat H \in R^{J \times d},H^{p_1} \in R^{\frac J{p_1} \times d},H^{p_2} \in R^{\frac J{p_2} \times d}
H^∈RJ×d,Hp1∈Rp1J×d,Hp2∈Rp2J×d
Multi-Scale Behaviour Pattern Fusion:
多尺度行为模式融合
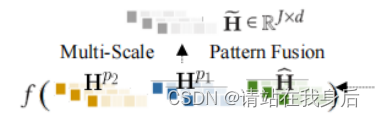
为了将多尺度动态行为模式集成到一个共同的潜在表示空间中,我们提出将上述编码的尺度特定嵌入集合成一个融合层,如下所示:
H
~
=
f
(
H
^
∣
∣
H
p
1
∣
∣
H
p
2
)
f
为投影函数,将
R
(
𝐽
𝐶
+
J
𝑝
1
+
𝐽
𝑝
2
)
×
d
投影到
R
j
×
d
∥表示对不同嵌入向量的拼接操作。
\tilde H =f(\hat H ||H^{p_1}||H^{p_2})\\ f为投影函数,将R^{(\frac 𝐽𝐶 +\frac J𝑝_1 +\frac 𝐽 𝑝_2 )\times d}投影到 R^{j\times d}\\∥表示对不同嵌入向量的拼接操作。
H~=f(H^∣∣Hp1∣∣Hp2)f为投影函数,将R(CJ+pJ1+pJ2)×d投影到Rj×d∥表示对不同嵌入向量的拼接操作。
Multi-Head-Enhanced Representation Spaces:
多头增强的表征空间
在这一部分中,我们提出赋予行为感知的条目序列编码器联合参与多维交互语义的能力。特别地,我们的多头序列形态编码器将H投射到𝑁潜在表示空间,并并行执行头部特定的注意力机制进行计算。
H
~
=
(
h
e
a
d
1
∣
∣
h
e
a
d
2
∣
∣
…
∣
∣
h
e
a
d
N
)
W
D
h
e
a
d
n
=
f
(
H
^
n
∣
∣
H
n
p
1
∣
∣
H
n
p
2
)
\tilde H = (head_1 || head_2||…||head_N)W^D\\ head_n =f(\hat H_n ||H_n^{p_1}||H_n^{p_2})\\
H~=(head1∣∣head2∣∣…∣∣headN)WDheadn=f(H^n∣∣Hnp1∣∣Hnp2)
其中
H
是计算头部特定的投影矩阵
,
W
是输出变换矩阵。多个注意头允许我们的多尺度
T
r
a
n
s
f
o
r
m
e
r
架构在
𝑆
𝑖
中对项目之间的多维依赖关系进行编码。
其中H是计算头部特定的投影矩阵,W是输出变换矩阵。多个注意头允许我们的多尺度Transformer架构在𝑆𝑖中对项目之间的多维依赖关系进行编码。
其中H是计算头部特定的投影矩阵,W是输出变换矩阵。多个注意头允许我们的多尺度Transformer架构在Si中对项目之间的多维依赖关系进行编码。
Non-linearity Injection with Feed-forward Module:
利用FFN进行非线性注入
在多尺度 Transformer 中,使用逐点FFN将非线性注入到新生成的表征中。表示为下式:
在我们的前馈模块中,我们采用了两层非线性变换,并集成了中间非线性激活GELU(·)。另外W1,W2,b1,b2,是投影矩阵和偏差项的可学习参数。这里,𝑙表示第l层多尺度Transformer层
3.2 Customized Hypergraph Learning of Global Multi-Behavior Dependencies
利用超图学习全局多行为依赖
在我们的MBHT框架中,我们的目标是将长期的多行为依赖纳入用户兴趣进化的学习范式。然而这并不简单。为了实现我们的目标,首先需要解决我们的学习模式中的两个关键挑战:
1.Multi-Order Behavior-wise Dependency多阶行为依赖:考虑到不同类型的用户行为之间的综合关系,项目间的多行为依赖关系不再是二元的。推荐商品不仅要看购买记录,还要看浏览收藏等交互行为。
2.Personalized Multi-Behavior Interaction Patterns个性化的多行为交互模式:,多行为模式可能因多类型用户-项目交互中具有不同相关性的用户而异。有些用户喜好广泛的添加收藏,而有些只有在想购买时添加收藏。
为了解决上述挑战,本文在超图神经架构上构建了我们的全局多行为依赖编码器。受超图通过单个边连接多个节点的灵活性的启发,我们利用超边结构来捕获四元或更高阶的多行为随时间的依赖关系。此外,考虑到不同用户的行为感知交互序列,我们在交互行为序列上构建了不同的超图结构,目的是以定制的方式编码多行为依赖
总体来说,利用超图结构捕获高阶多行为依赖关系,并通过构建不同的超图进行个性化定制
3.2.1 Item-wise Hypergraph Construction
逐项目的超图构建
在我们的超图框架中,我们生成了两种基于项目超边连接,分别对应于
1)项目之间的长期语义关联;
2)项目特定的跨时间的多行为依赖关系。
Item Semantic Dependency Encoding with Metric(度量) Learning.
利用度量学习进行项目语义依赖编码
为了编码随时间变化的物品语义和基于相同用户兴趣(例如,食物,户外活动)的潜在长期物品相关性,我们引入了一种基于度量学习框架(metric learning framework)的物品语义编码器。
在数学中,一个度量(或距离函数)是一个定义集合中元素之间距离的函数。一个具有度量的集合被称为度量空间。
度量学习也叫作相似度学习,这就好理解了
具体来说,我们设计了可学习的指标𝛽,项目之间的多通道权重函数𝜏(·)表示如下:
β
^
j
,
j
′
n
=
τ
(
w
n
⊙
v
j
,
w
n
⊙
v
j
′
)
我们将权重函数
τ
定义为基于第
n
个表示通道的可训练权重的余弦相似度估计
⊙
表示嵌入投影操作
\hat \beta^n_{j,j^\prime} = \tau(w^n \odot v_j,w^n\odot v_{j^\prime})\\ 我们将权重函数\tau定义为基于第n个表示通道的可训练权重的余弦相似度估计 \\ \odot表示嵌入投影操作
β^j,j′n=τ(wn⊙vj,wn⊙vj′)我们将权重函数τ定义为基于第n个表示通道的可训练权重的余弦相似度估计⊙表示嵌入投影操作
所有已学习通道特定的项目语义依赖评分都应用平均池化操作,获得最终的相关性beta
β
j
,
j
′
=
1
N
∑
n
=
1
N
β
^
j
,
j
′
n
;
v
j
=
e
j
⊕
b
j
\beta_{j,j^\prime} = \frac 1N \sum \limits ^N_{n=1}\hat \beta^n_{j,j^\prime};v_j = e_j \oplus b_j\\
βj,j′=N1n=1∑Nβ^j,j′n;vj=ej⊕bj
Item-wise Semantic Dependency Hypergraph
逐项目的语义依赖超图
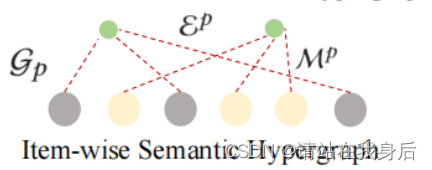
通过编码不同项目之间的语义依赖关系,我们通过同时连接多个高度依赖的项目和超边来生成项目级语义超图。
超边数代表着交互序列不同类型的个数,每个唯一的项目将在𝜖∈E𝑝中分配一个超边。根据学习到的项目-项目语义依赖评分𝛽,连接top-𝑘语义依赖项目。
我们定义项目与超边之间的连接矩阵为
m
p
(
v
j
,
ϵ
j
′
)
=
{
β
j
,
j
′
v
j
,
j
′
∈
A
j
;
0
o
t
h
e
r
w
i
s
e
;
m^p(v_j,\epsilon_{j^\prime}) = \begin{cases} \beta_{j,j^\prime} \ \ v_{j,j^\prime}\in A_j;\\ 0 \ \ \ otherwise; \end{cases}
mp(vj,ϵj′)={βj,j′ vj,j′∈Aj;0 otherwise;
Item-wise Multi-Behavior Dependency Hypergraph.
逐项目的多行为依赖超图
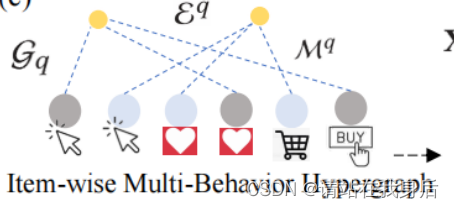
为了在时间感知环境中捕获个性化的商品智能多行为依赖,我们进一步生成一个超图结构G𝑞,基于观察到的用户𝑢𝑖和特定商品𝑣𝑗在不同时间戳之间的多类型交互(例如,页面视图,添加到购物车)。
超边的个数等于与用户有多类型交互的项目数,考虑到用户对其交互物品具有不同的多行为模式,构建的多行为依赖超图因用户而异。
m
q
(
v
j
b
,
ϵ
j
b
′
)
=
{
1
v
j
b
∈
E
j
q
0
𝑣
𝑗
𝑏
表示项目
𝑣
𝑗
在
𝑏
−
t
h
行为类型下与用户
𝑢
𝑖
交互
m^q(v^b_j,\epsilon^{b^\prime}_{j}) = \begin{cases} 1 \ \ \ v_j^b\in \cal{E}^q_j\\ 0 \end{cases}\\ 𝑣^𝑏_𝑗表示项目𝑣_𝑗在𝑏-th行为类型下与用户𝑢_𝑖交互
mq(vjb,ϵjb′)={1 vjb∈Ejq0vjb表示项目vj在b−th行为类型下与用户ui交互
之后进一步通过将两种连接矩阵连接成列整合构建的两个超图结构,集成超图的连接矩阵M= M_p || M_q
不同的行为感知交互序列对不同的用户产生不同的超图结构,这使得我们的MBHT模型能够以自定义的方式编码个性化的多行为依赖模式。
3.2.2 Hypergraph Convolution Module(超图卷积模块)
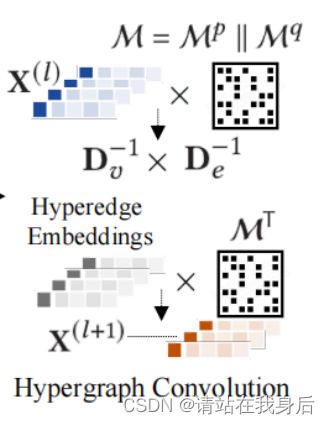
在这个模块中,我们引入了带卷积层的超图消息传递范式,以捕获随时间变化的全局多行为依赖关系.超图卷积层通常包含两级信息传递,节点-超边和超边-节点嵌入传播以及超图连接矩阵M来细化项目表示
卷积层设计如下:
X
l
+
1
=
D
v
−
1
⋅
M
⋅
D
e
−
1
⋅
M
T
⋅
X
(
l
)
X
(
l
)
为第
l
层项嵌入,
D
v
,
D
e
分别是基于顶点度和边度的归一化对角矩阵。
X^{l+1} = D^{-1}_v \cdot M \cdot D_e^{-1} \cdot M^T \cdot X^{(l)}\\ X^{(l)}为第l层项嵌入,D_v,D_e分别是基于顶点度和边度的归一化对角矩阵。
Xl+1=Dv−1⋅M⋅De−1⋅MT⋅X(l)X(l)为第l层项嵌入,Dv,De分别是基于顶点度和边度的归一化对角矩阵。
3.3 Cross-View Aggregation
跨视图聚合
在MBHT框架的预测层,我们提出了从不同属兔融合学习到的项目表示:
1)结合Transformer挖掘的多尺度行为感知序列模式;
2)超图框架的个性化全局多行为依赖。
为了以一种自适应的方式实现这种跨视图聚合,我们开发了一个注意力层来学习特定于视图的项嵌入的显式重要性。在形式上,聚合过程如下:
α
i
=
A
t
t
n
(
e
i
)
=
e
x
p
(
α
T
⋅
W
a
e
i
)
∑
i
e
x
p
(
α
T
⋅
W
a
e
i
)
e
i
∈
{
h
~
i
,
x
~
i
}
;
g
i
=
α
1
⋅
h
~
i
⊕
α
2
⋅
x
~
i
h
,
x
为项目从两个视图的嵌入
为了消除图卷积的过度平滑效应,
x
~
i
是所有卷积层中
x
(
l
)
的平均值。最后,序列中第
i
个商品为商品
v
j
的概率估计为
y
^
i
,
j
=
g
i
T
⋅
v
j
\alpha_i = Attn(e_i) = \frac {exp(\alpha ^T \cdot W_a e_i)}{\sum_iexp(\alpha^T \cdot W_a e_i)}\\ e_i \in \{ \tilde h_i,\tilde x _i\} ; g_i =\alpha _1 \cdot \tilde h _i \oplus \alpha _2 \cdot \tilde x_i h,x 为项目从两个视图的嵌入\\ 为了消除图卷积的过度平滑效应,\tilde x_i 是所有卷积层中x^{(l)}的平均值。最后,序列中第i个商品为商品v_j 的概率估计为\\ \hat y_{i,j}=g^T_i \cdot v_j
αi=Attn(ei)=∑iexp(αT⋅Waei)exp(αT⋅Waei)ei∈{h~i,x~i};gi=α1⋅h~i⊕α2⋅x~ih,x为项目从两个视图的嵌入为了消除图卷积的过度平滑效应,x~i是所有卷积层中x(l)的平均值。最后,序列中第i个商品为商品vj的概率估计为y^i,j=giT⋅vj
3.4 Model Learning And Analysis
以适应我们的多行为顺序推荐场景,采用Cloze task作为训练目标,用交叉熵定义优化的目标损失如下:
L
=
1
∣
T
∣
∑
t
∈
T
,
m
∈
M
−
l
o
g
(
e
x
p
y
^
m
,
t
∑
j
∈
V
e
x
p
y
^
m
,
j
)
L = \frac 1 {|T|} \sum \limits_{t \in T ,m\in M} -log(\frac {exp\hat y_{m,t}}{\sum_{j\in V}exp \hat y_{m,j}})
L=∣T∣1t∈T,m∈M∑−log(∑j∈Vexpy^m,jexpy^m,t)
屏蔽序列中的所有与目标行为类型(例如,购买)相同的交互商品。为了避免标签泄漏问题,用特殊标记 [mask] 替换了屏蔽的商品以及相应的行为类型embedding,在超图构建中省略掩码商品,对于掩码商品,通过在掩码位置周围的上下文邻居的超图embedding上采用滑动窗口(m-q1,m+q2)平均池化函数,生成其超图embedding 。模型基于行为交互序列中编码的周围上下文embedding对掩码商品进行预测
4 实验

列出以下问题
•RQ1:在不同的设置下,我们的MBHT与各种最先进的推荐方法相比表现如何?
•RQ2: MBHT中的关键模块(如多尺度注意力编码器、多行为超图学习)的有效性如何?
•RQ3:当与基线比较时,MBHT如何缓解项目序列数据稀缺的问题
•RQ4:不同的超参数如何影响模型性能?
4.1 实验设置
**数据集:**淘宝,Retailrocket,IJCAI
**评估方案:我们采用leave-one-out策略进行性能评估。利用了三个评估指标:命中率(HR@N)、归一化折现累积增益(NDCG@N)和平均倒数秩(MRR)
基线:
General Sequential Recommendation Methods.
Graph-based Sequential Recommender Systems.
Multi-Behavior Recommendation Models.
4.2 Performance Evaluation (RQ1)
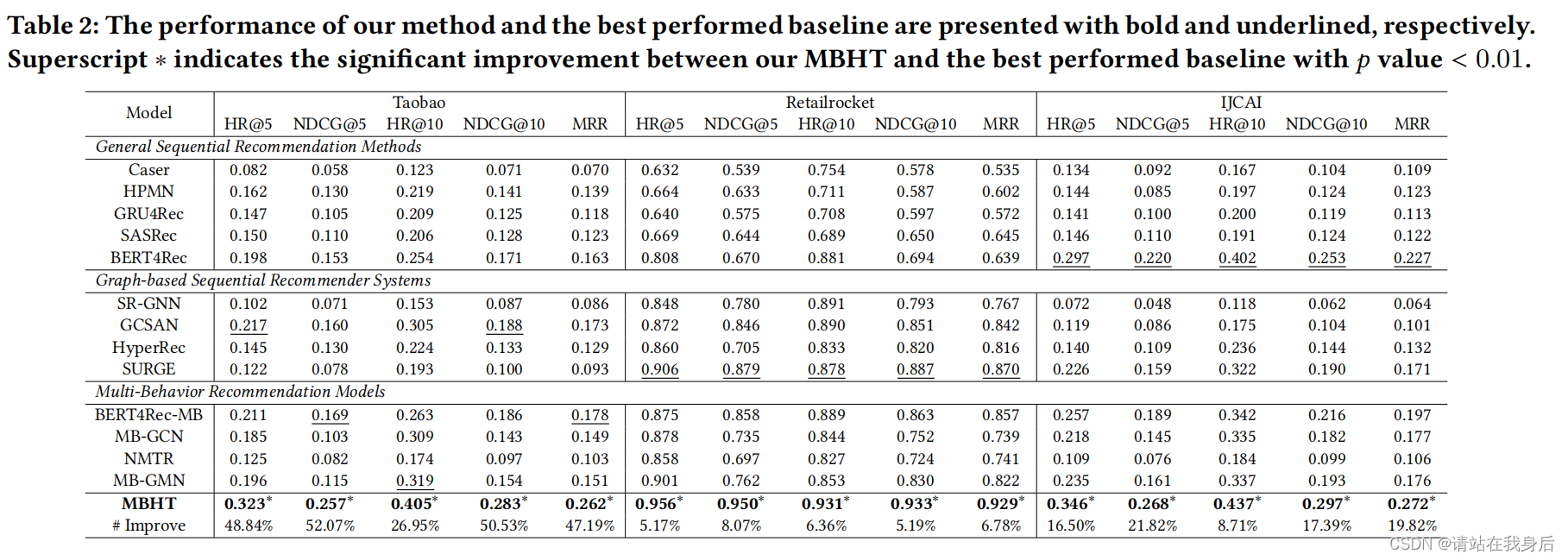
分析如下
1.MBHT始终优于所有类型的基线
2.MBHT对于不同的推荐场景具有鲁棒性
3.基于图的顺序推荐方法(如SR-GNN,GCSAN, SURGE)在IJCAI数据集上的性能比一般的序列推荐基线更差,很难捕获项目的长期依赖关系
4.多行为推荐模型(如MB-GCN, MB-GMN)的性能与其他基线相当。这些观察结果表明,将多行为环境纳入用户偏好学习过程的有效性。
4.3 Ablation Study (RQ2)
Effects of Key Components
生成了四个变体
MB-Hyper:不包括以项为单位的多行为依赖的超图来捕捉长期的跨类型行为相关性。
ML-Hyper.:去掉了通过条目语义依赖的超边传递的超图消息
Hypergraph.:禁用整个超图逐项依赖学习,只依赖于多尺度转换器来为顺序行为模式建模。
MS-Attention.:用原来的多头注意操作替换我们的多尺度注意层。
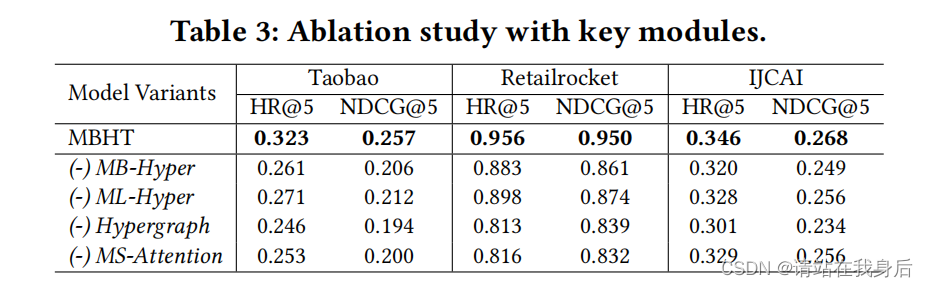
表明了各个组件都有其作用
Contribution of Learning Views.
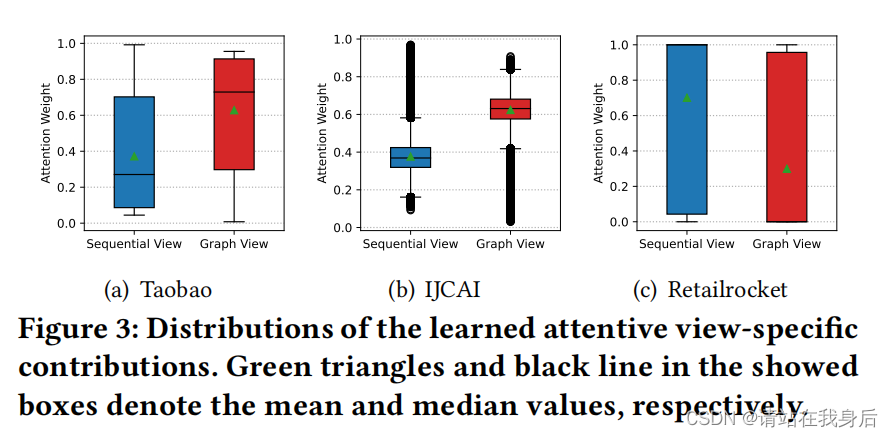
研究了顺序学习和超图学习视图的贡献,超图学习观点对长项目序列的动态多行为模式(如淘宝和IJCAI))的有效建模贡献更大。这进一步证实了我们的行为感知超图学习组件在捕获多关系顺序推荐中的长项目依赖性方面的有效性。
4.4 Model Benefit Study (RQ3)
Performance w.r.t Sequence Length 序列长度性能
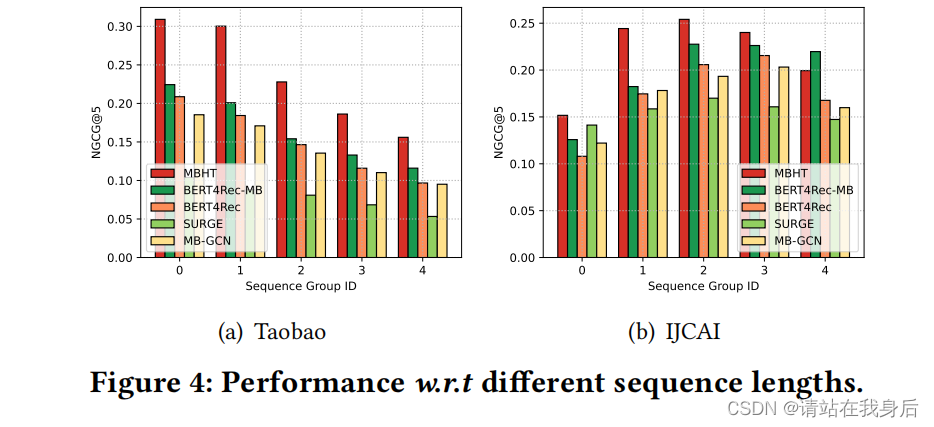
为了进一步研究我们的模型的鲁棒性,我们评估了不同长度的项目序列的MBHT。MBHT不仅在较短的条目交互序列上优于几个代表性的基准,而且在较长的条目交互序列上也优于其他基准
Model Convergence Study 收敛性
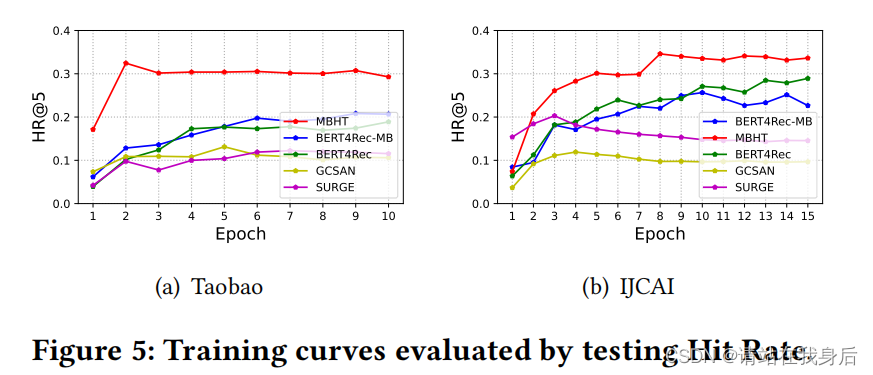
模型训练过程中,MBHT比大多数竞争方法具有更快的收敛速度。
4.5 Case Study
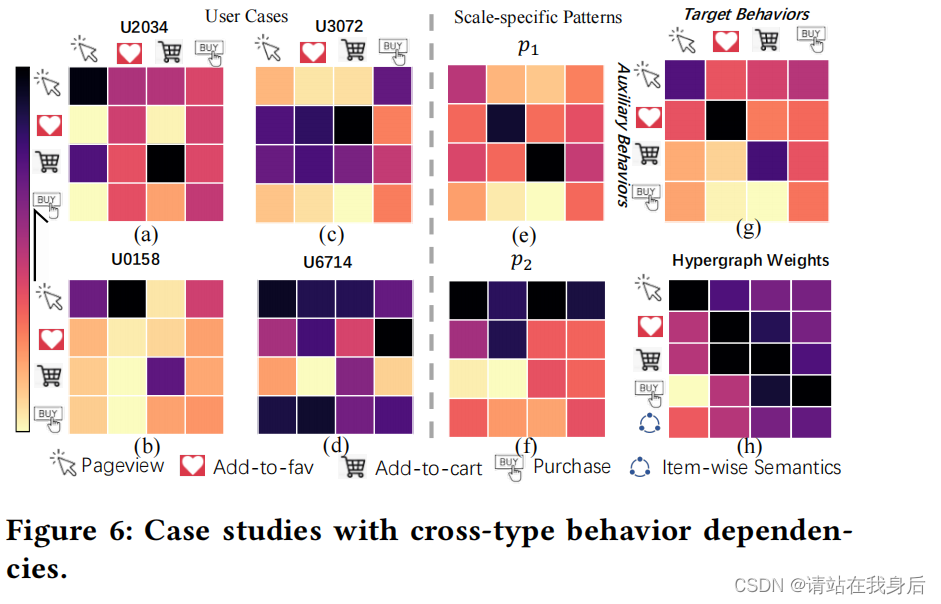
a-d 展示了特定于用户的跨类型行为依赖关系。通过考虑它们在用户𝑢𝑖的特定序列𝑆𝑖中的行为感知交互来计算条目之间的相关性
e-f 显示了在我们的行为感知序列模式的多尺度建模中,特定于尺度的多行为依赖关系
g 展示了不同类型行为在最终预测目标行为时的总体相关性得分。
h 基于超图的项目相关性
5 总结
在本文中,我们提出了一个新的顺序推荐框架MBHT,它明确地捕捉了短期和长期的多行为依赖。MBHT设计了一个多尺度
代表性的基准,而且在较长的条目交互序列上也优于其他基准
Model Convergence Study 收敛性
[外链图片转存中…(img-6GIKunDI-1661160872255)]
模型训练过程中,MBHT比大多数竞争方法具有更快的收敛速度。
4.5 Case Study
[外链图片转存中…(img-aGS0YrN1-1661160872255)]
a-d 展示了特定于用户的跨类型行为依赖关系。通过考虑它们在用户𝑢𝑖的特定序列𝑆𝑖中的行为感知交互来计算条目之间的相关性
e-f 显示了在我们的行为感知序列模式的多尺度建模中,特定于尺度的多行为依赖关系
g 展示了不同类型行为在最终预测目标行为时的总体相关性得分。
h 基于超图的项目相关性
5 总结
在本文中,我们提出了一个新的顺序推荐框架MBHT,它明确地捕捉了短期和长期的多行为依赖。MBHT设计了一个多尺度
Transformer在细粒度和粗粒度级别上对行为感知的顺序模式进行编码。为了捕获全局的跨类型行为依赖关系,我们赋予MBHT多行为超图学习组件。在几个真实数据集上的经验结果验证了我们的MBHT在与最先进的推荐方法竞争时的优势。
贡献:
1.这项工作提出了一个名为MBHT的新框架,用于顺序推荐,它揭示了底层的动态和多行为用户项交互模式。
2.为了对具有行为类型感知的多粒度项目转换进行建模,我们设计了一个多尺度的Transformer,它具有低秩和多尺度的自我注意投影,以维护不断发展的关系感知的用户交互模式。
3.为了捕获不同的、长期的多行为项目相关性,我们提出了一个多行为超图学习范式,通过全局和自定义的顺序上下文注入来提取项目特定的多行为相关性