还有一周时间,就要期末考试了,考试形式是上机操作,心里还是非常担心的,所以,记录一下,现在开始24小时,复习mapreduce。(现在是下午14:20)希望24小时后,可以复习完。
关于虚拟机的安装,完全分布式集群的部署就不说了,本人踩了很多坑,然后又忘记记录了,但是有一篇关于搭建集群的博客,讲的还是很详细的,不会的朋友可以看那篇博客安装。建议是安装2.x版本的,因为之前装3.x的时候,碰到了许多问题,比如说jar包不支持之类的,非常烦人。下面直接进入预习。
介绍mapreduce:
Hadoop由三个重要模块组成,hdfs(分布式文件存储)、mapreduce(分布式计算)、yarn(分布式资源调度),这里主要讲分布式计算。mapreduce分为两个阶段,map阶段和reduce阶段,map可以理解为分发数据的阶段,reduce理解为统计运算结果、输出数据的阶段。
常用的数据序列化类型:
| Java类型 | Hadoop Writable类型 |
| boolean | BooleanWritable |
| byte | ByteWritable |
| int | IntWritable |
| float | FloatWritable |
| long | LongWritable |
| double | DoubleWritable |
| String | Text |
| map | MapWritable |
| array | ArrayWritable |
hadoop中,数据类型与java中的数据类型区别较大的就是string,这个特别注意一下。
mapreduce编程规范:
我们编写程序分为三个部分:Mapper、Reducer、Driver。这里先展示这三个阶段分别需要做什么事情,然后再详细地从wordcount开始实操。



下面是官方的wordcount源码: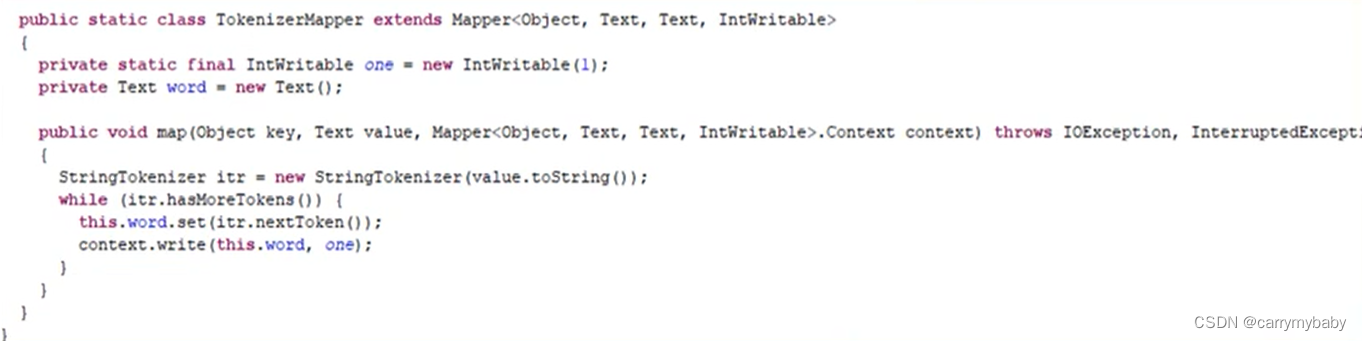
第一个继承父类不难理解,就是数据输入要符合Mapper<......>地数据定义类型;
第二个KV对,这个KV对就是<Text,IntWritable>,这就是一个键值对,比如说输入的一个文本,第一行地输入是:
”I love csy“
那么,这个键值对就是 0,I love csy 这个键就是第几行;
第三点,第四点都好理解,就是字面意思;
第五点,map方法(MapTask进程)对每个<K,V>调用一次,意思就是一个文本输入,读取每一行都会调用一次map方法。

第一点用户定义的Reducer要继承 自己的父类,和上面一样;
第二点,map运行完之后输出数据,这个输出的数据传给Reducer,所以数据类型需要对应;
第三点、第四点也都好好理解,进程对每一组相同的K的<K,V>组调用一次reduce方法,举个例子,输入是:
”I love csy“
”I love csy very much“
经过map处理后,输出就是:<I,1> <love,1> <csy,1> <I,1> <love,1> <csy,1> <very,1> <much,1>,然后就会变成:<I,(1,1)> <love,(1,1)> <csy,(1,1)> <very,1> <much,1>,这些输出发送到reduce进行迭代统计,这里就是有几个K值,就执行几次reduce,reduce里面是进行累加还是累乘,这就和业务逻辑有关系了。
(现在是15:30)
看一下wordcount案例:
要求是:在给定的文本文件中统计输出每一个单词出现的总次数。
按照MapReduce编程规范,分别编写Mapper,Reducer,Driver,如图所示。

手写源码如下:(运行Driver就行)
编写Mapper类
package com.csy.mapreduce;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 切割
String[] words = line.split(" ");
// 3 输出
for (String word : words) {
k.set(word);
context.write(k, v);
}
}
}
Reducer编写:
package com.csy.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
int sum;
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
// 1 累加求和
sum = 0;
for (IntWritable count : values) {
sum += count.get();
}
// 2 输出
v.set(sum);
context.write(key,v);
}
}
编写Driver
package com.csy.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordcountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1 获取配置信息以及封装任务
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 设置jar加载路径
job.setJarByClass(WordcountDriver.class);
// 3 设置map和reduce类
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
// 4 设置map输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
wordcount基本上就这些,后面关于其他的实验下一篇csdn再发,因为有些材料不全,而且上课讲的东西和hadoop的应用相差很大(序列化这些东西有没有讲,记不清了,我先去问问)
