FILTERXML函数?感觉似曾相识。还记得有一个强大的英汉互译公式吗?好象有它的身影:
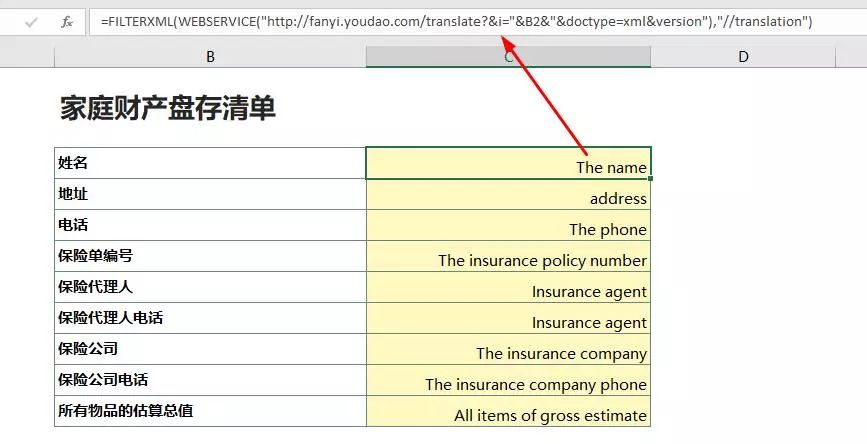
公式
=FILTERXML(WEBSERVICE("http://fanyi.youdao.com/translate?&i="&B2&"&doctype=xml&version"),"//translation")
在上面公式中,WEBSERVICE函数可以获取网页代码(代码中包话翻译完成的结果),而FILTERXML函数则是根据网页代码提取字符。
语法
FILTERXML(xml, xpath)
-
xml 有效 XML 格式的字符串
-
xpath 标准 XPath 格式的字符串
想完全掌握FILTERXML函数,你需要首先熟悉网页Xml代码的结构,然后再掌握它的提取格式代码Xpath。只是这些对于我们一般办公人员有些难度,而且我们平时也用不了那么深入。所以兰色就化繁为简,分享一个傻瓜式的FILTERXML公式套路。
按分隔符拆分是经常遇到的一个Excel难题。
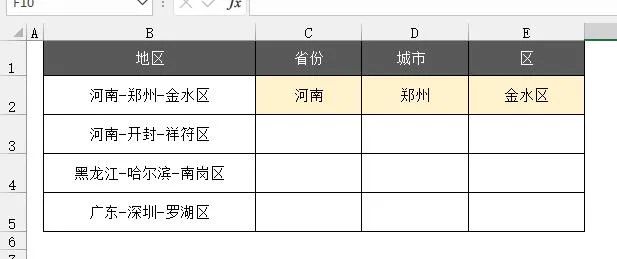
下面介绍一下如何使用FILTERXML公式套路解决这个难题。
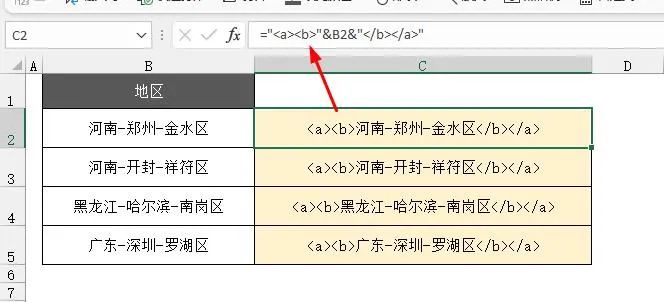
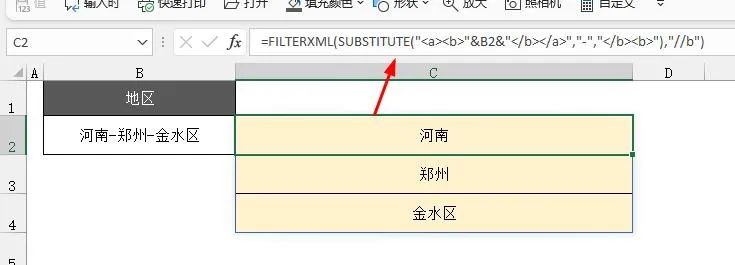
先在字符串前后分别添加<a><b>和</b></a>
="<a><b>"&B2&"</b></a>"
然后用substitute把分隔符-替换为</b><b>
=SUBSTITUTE("<a><b>"&B2&"</b></a>","-","</b><b>")
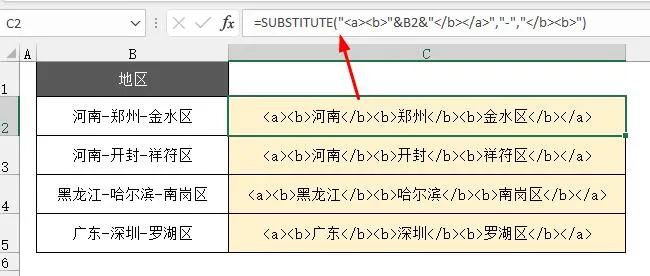
以上步骤的目的就是把我们要提取的内容,分别放在</b><b>中间,最外侧是<a>和</a>
<a><b>河南</b><b>郑州</b><b>金水区</b></a>
然后就可以用=FILTERXML(代码,"//b")提取出所有字符了。
=FILTERXML(SUBSTITUTE("<a><b>"&B2&"</b></a>","-","</b><b>"),"//b")
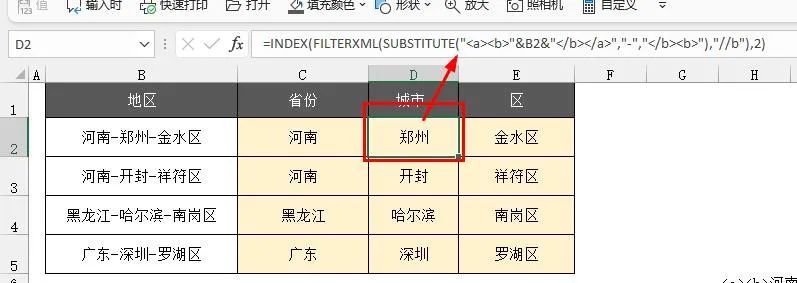
最后再用index(数组,序号)分别提取省市区
=INDEX(FILTERXML(SUBSTITUTE("<a><b>"&B2&"</b></a>","-","</b><b>"),"//b"),2)
可能有同学说这样的问题用Ctrl +E就可以轻松解决,为什么要学这么复杂的公式?
有些拆分用Ctrl+E可以,有些它就无能为力了。来看一个网友的真实提问。
如下图所示:把D列中的数字提取出来求和。注意:只提取 “ : ”后的数字,如成品检测1中的1不能参加运算。
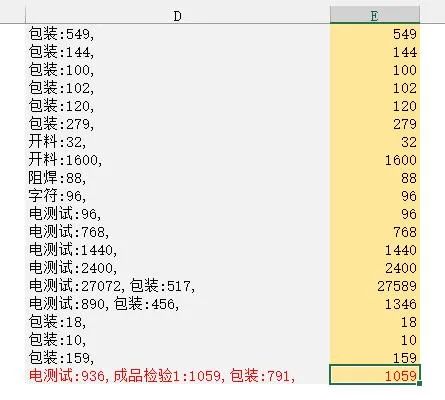
这个问题用一般的公式或Ctrl+E很难完成,而且用FILTERXML函数则可以完成。
=SUM(FILTERXML(SUBSTITUTE(SUBSTITUTE("<a>"&D1&"</a>",":","<b>"),",","</b>"),"//b"))
上面的公式中重点还是如何构造成xml格式代码,原理同本文开始,不再详述。