一、源码:
GitHub - RVC-Boss/GPT-SoVITS: 1 min voice data can also be used to train a good TTS model! (few shot voice cloning)1 min voice data can also be used to train a good TTS model! (few shot voice cloning) - RVC-Boss/GPT-SoVITS https://github.com/RVC-Boss/GPT-SoVITS
https://github.com/RVC-Boss/GPT-SoVITS
下载必要的使用的包

注意:GPT-SoVITS支持的语言:中英日
二、制作数据集:
音频文件可以B站下载视频,用剪影分离音频,对音频进行单独保存
B站视频下载地址:
https://bilibili.iiilab.com/
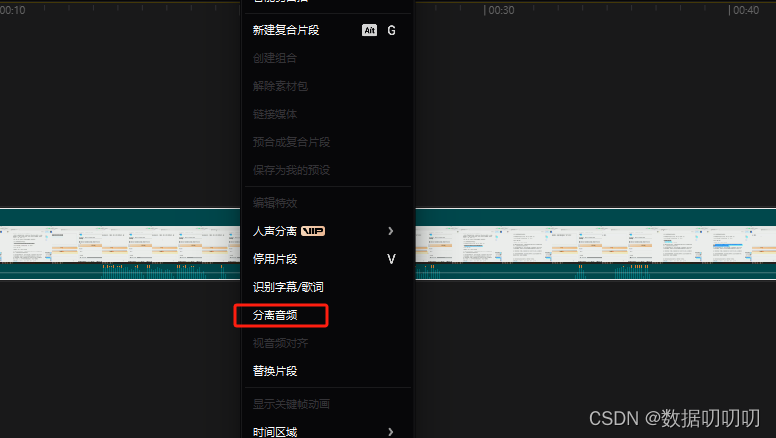
1、webUI使用:
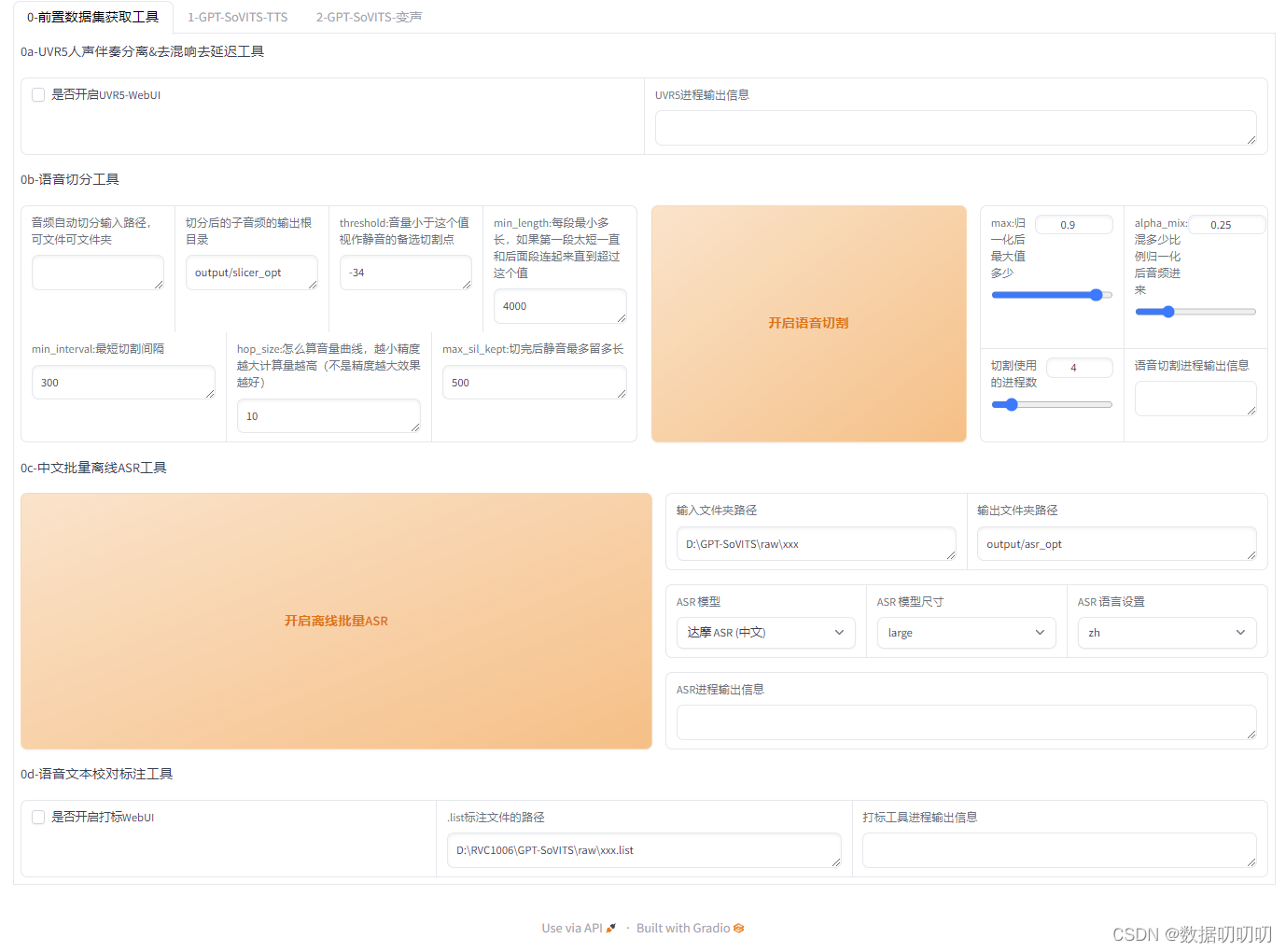
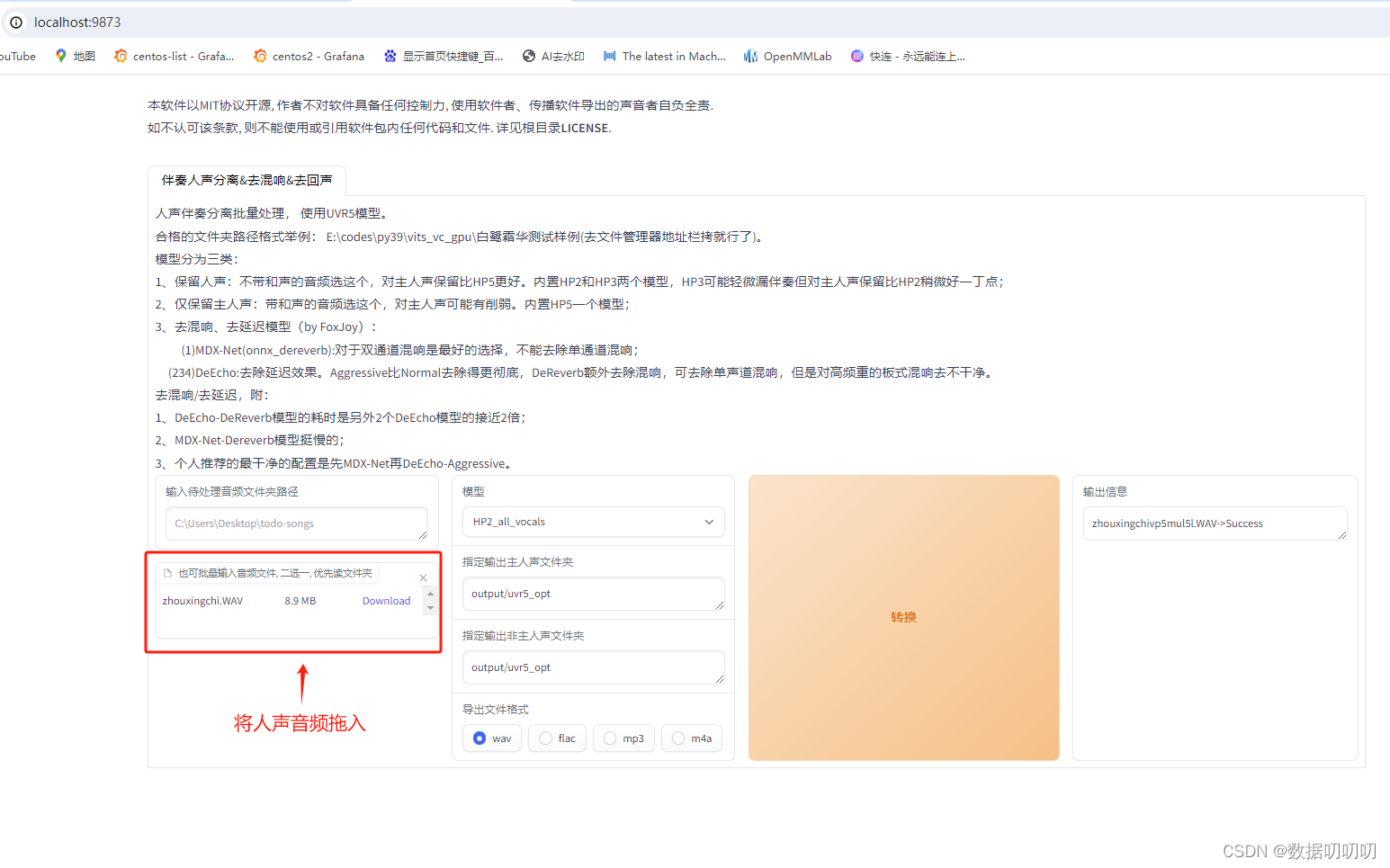
2、URV5去噪
开启UVR5-WebUI

拖入音频并转换
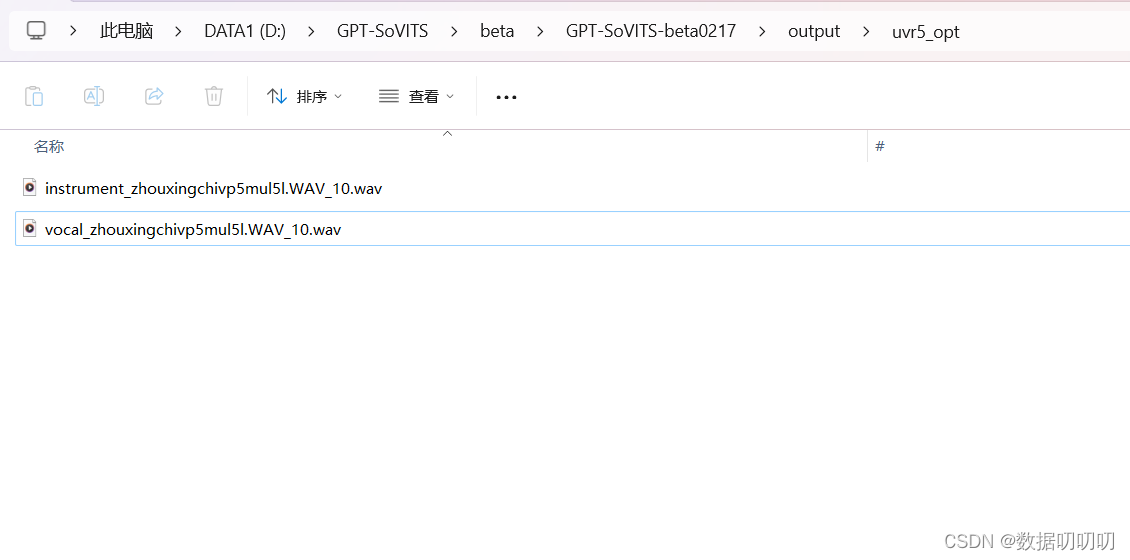
分割完生成两段音频,背景噪音和人声音频
3、切分音频段:
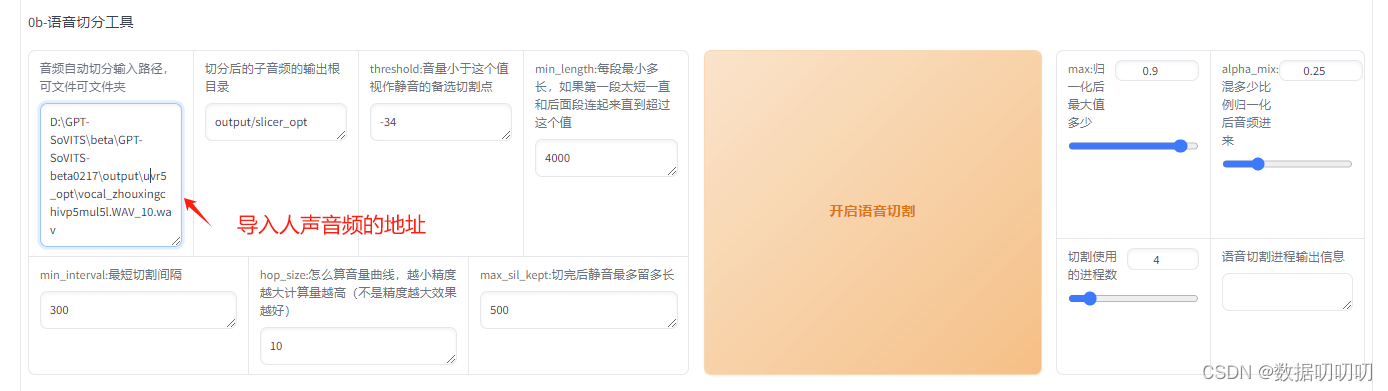
开启语音切割
切割结束后,生成音频文件
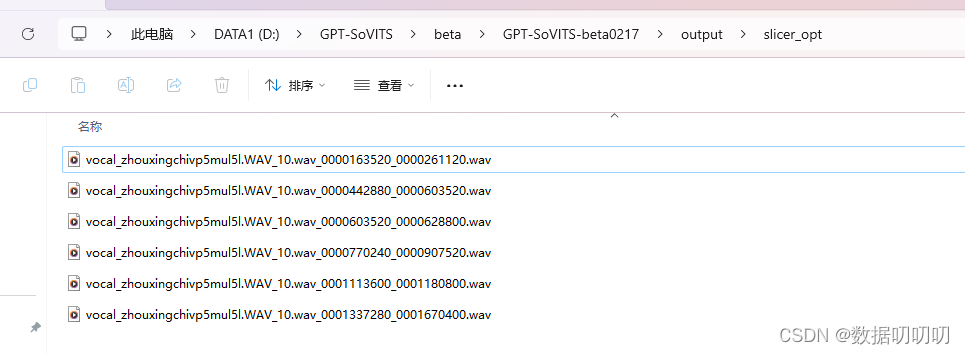
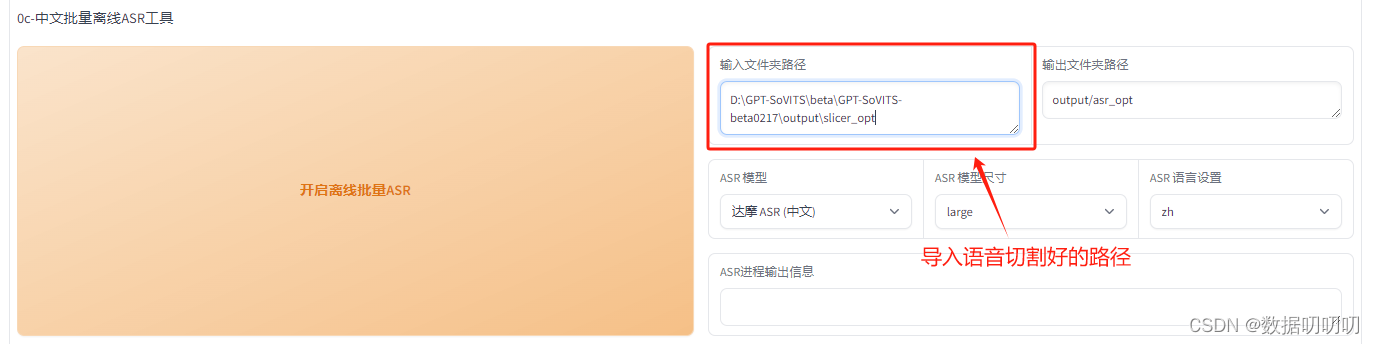
4、对语音内容识别生成文本:
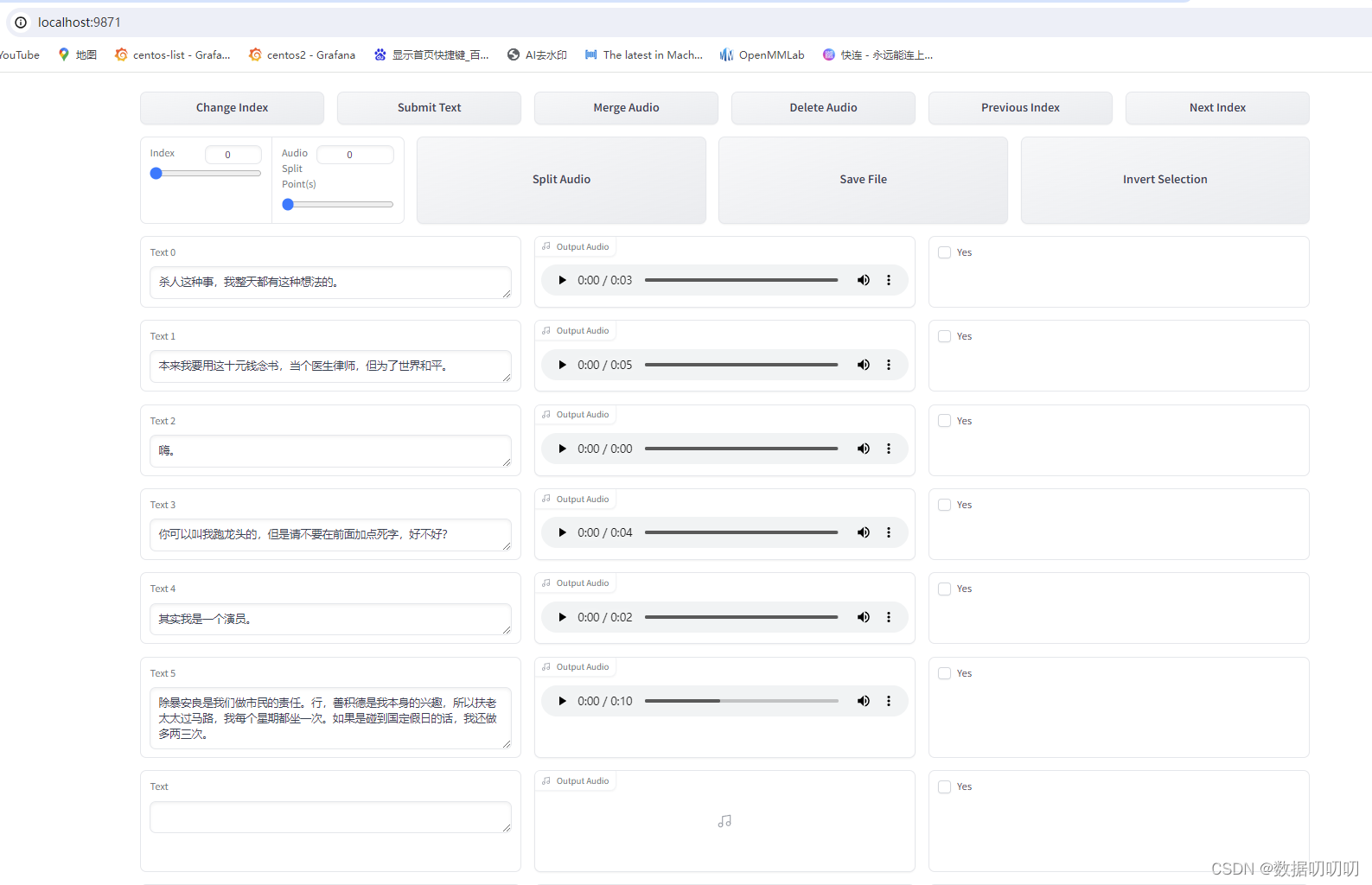
5、语音文本校对标注

如果音频文件不正确,需要开启打标webUI进行人工纠正,
校队好,点击submit text提交
三、模型训练:
注意:在模型训练的过程需要关闭其他占用显存过高的软件,以免造成内存溢出问题
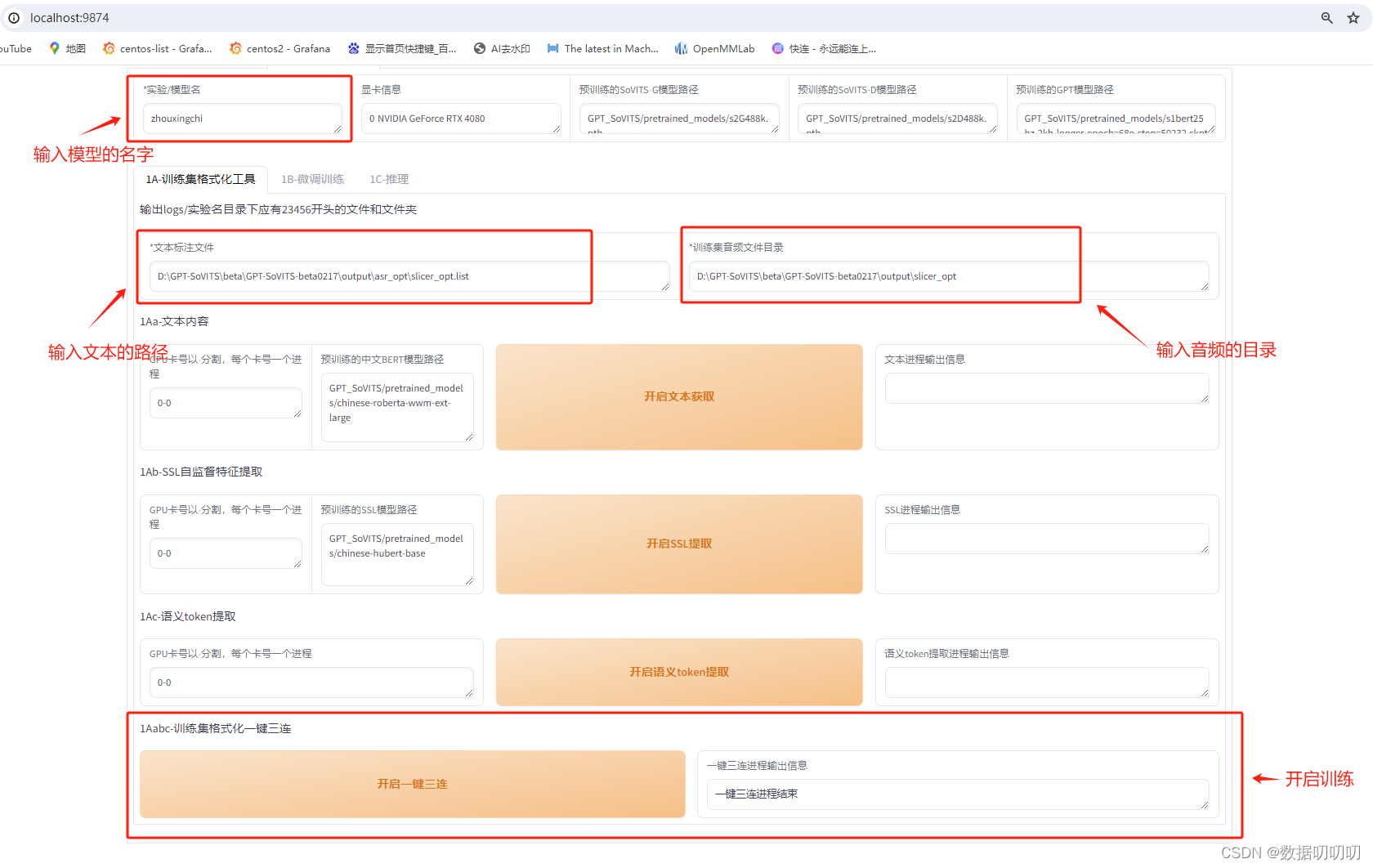
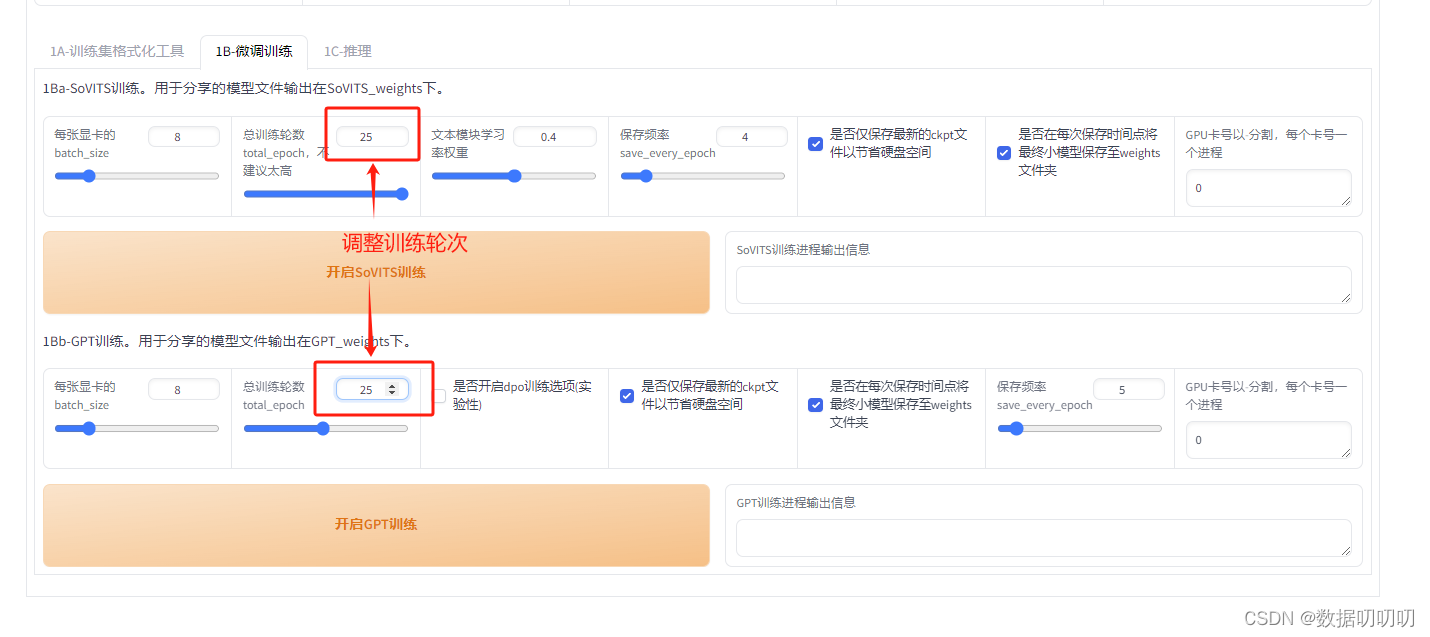
调整训练的轮次,我这里设置的是25轮
开启SoVITS训练

开启GPT训练
四、webUI使用:
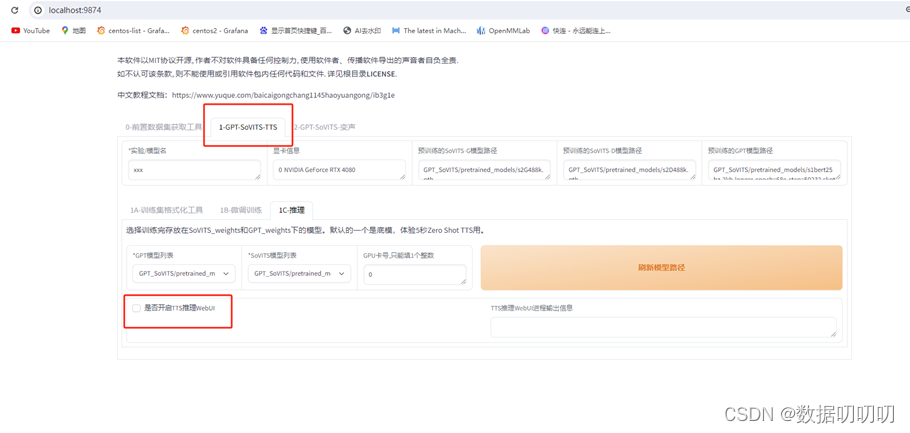
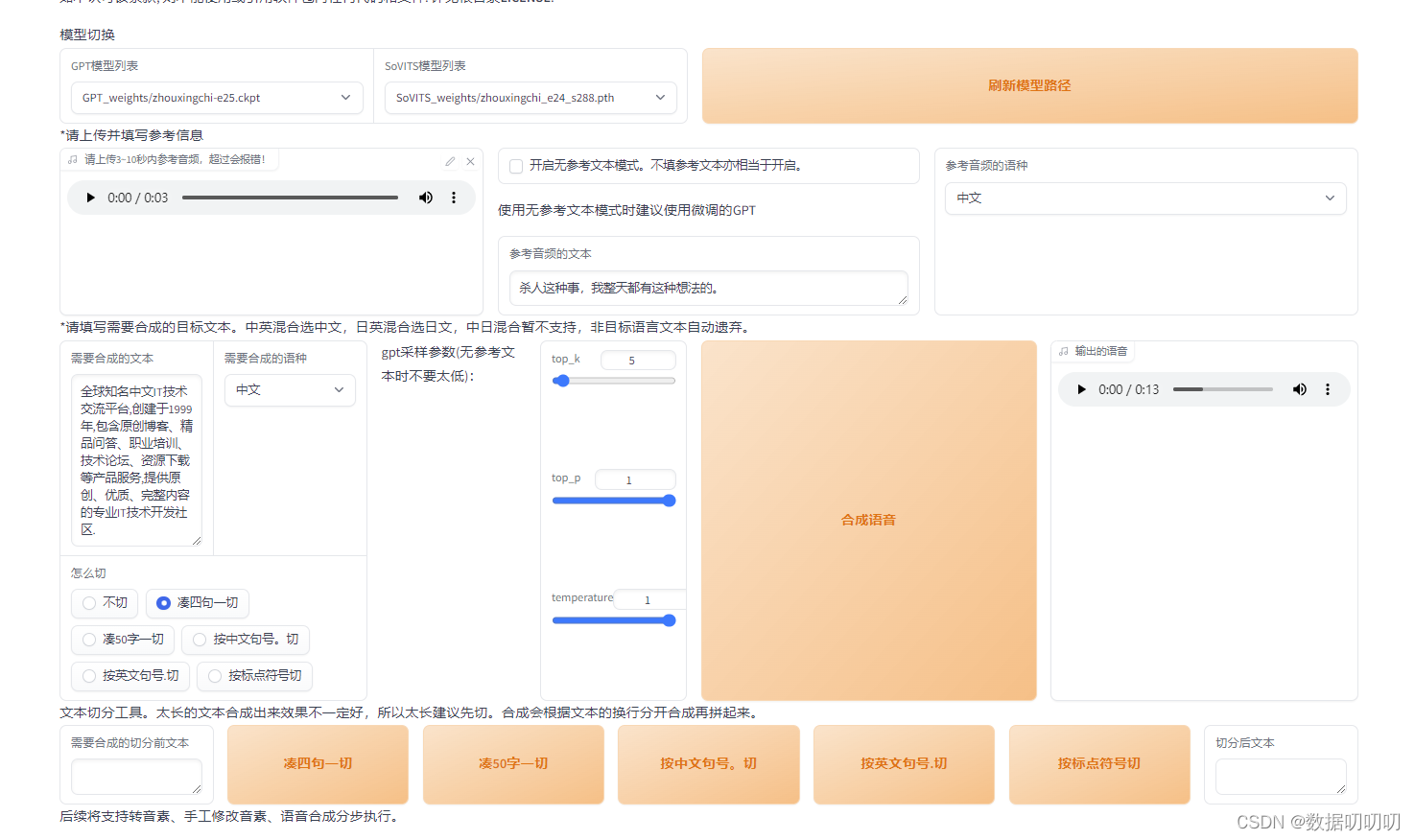
五、接口api的使用:
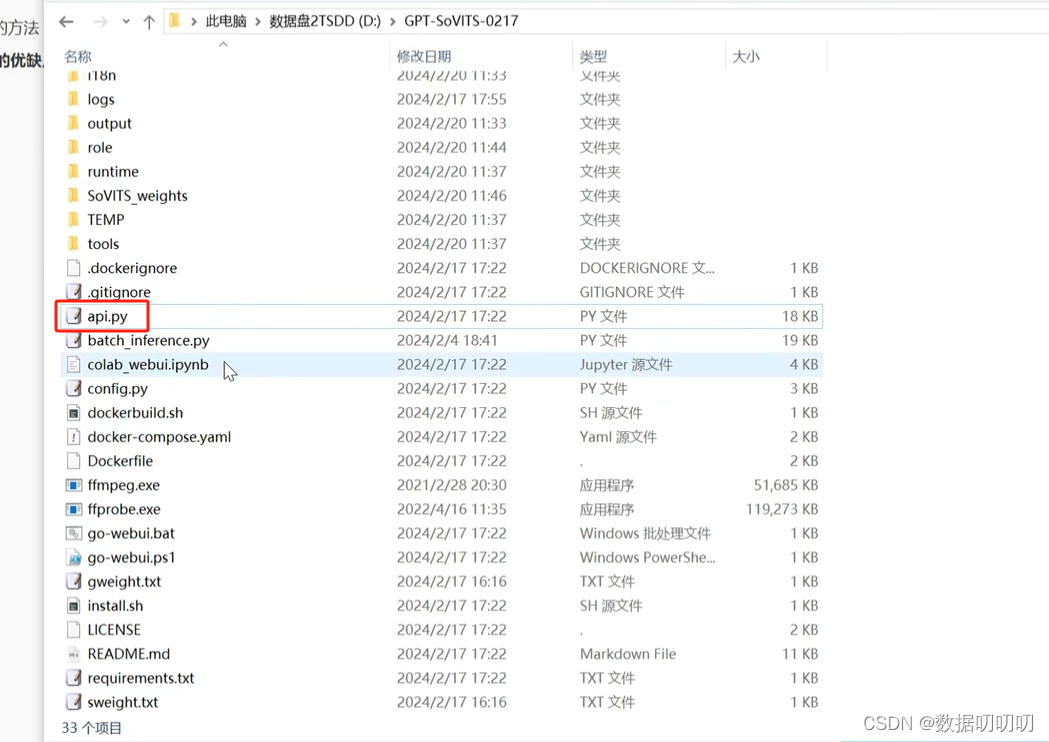
调用api.py
修改api.bat:打开api.bat文件,编辑里面的内容
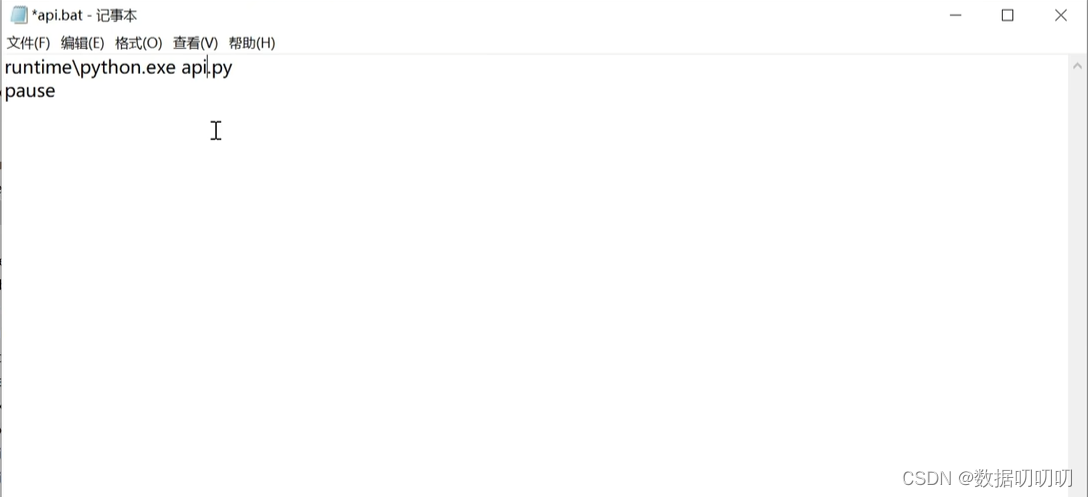
双击启动,api.bat
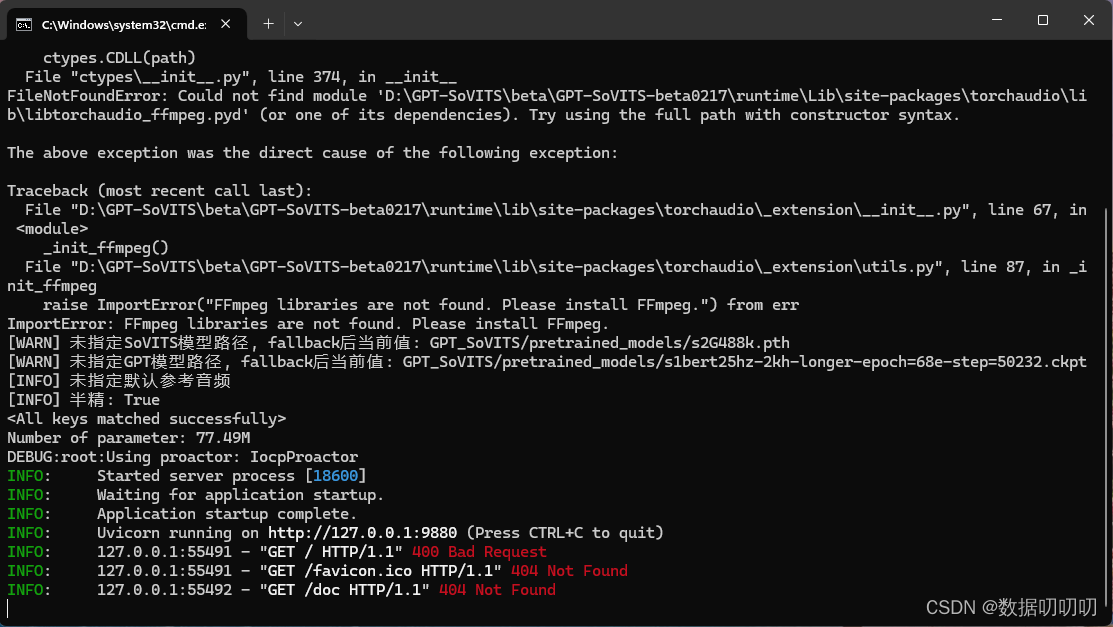
复制http://127.0.0.1:9880/docs到浏览器打开
报错:
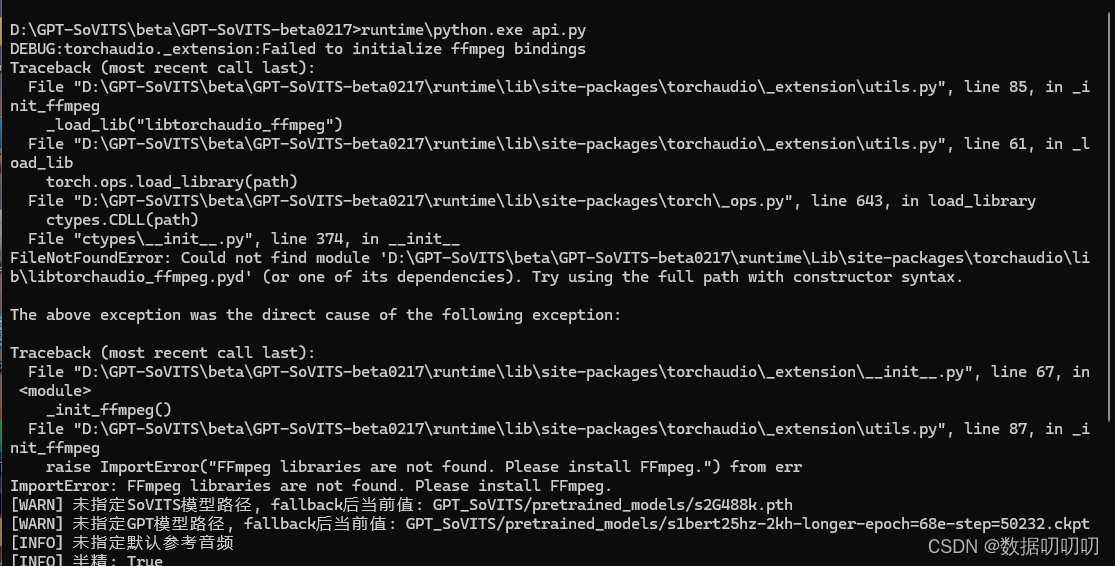
定位是ffmpeg的问题
进行解决
将host修改成0.0.0.0


问题:由于一句话太长,会出现播音错误的情况,需要对文本进行切词
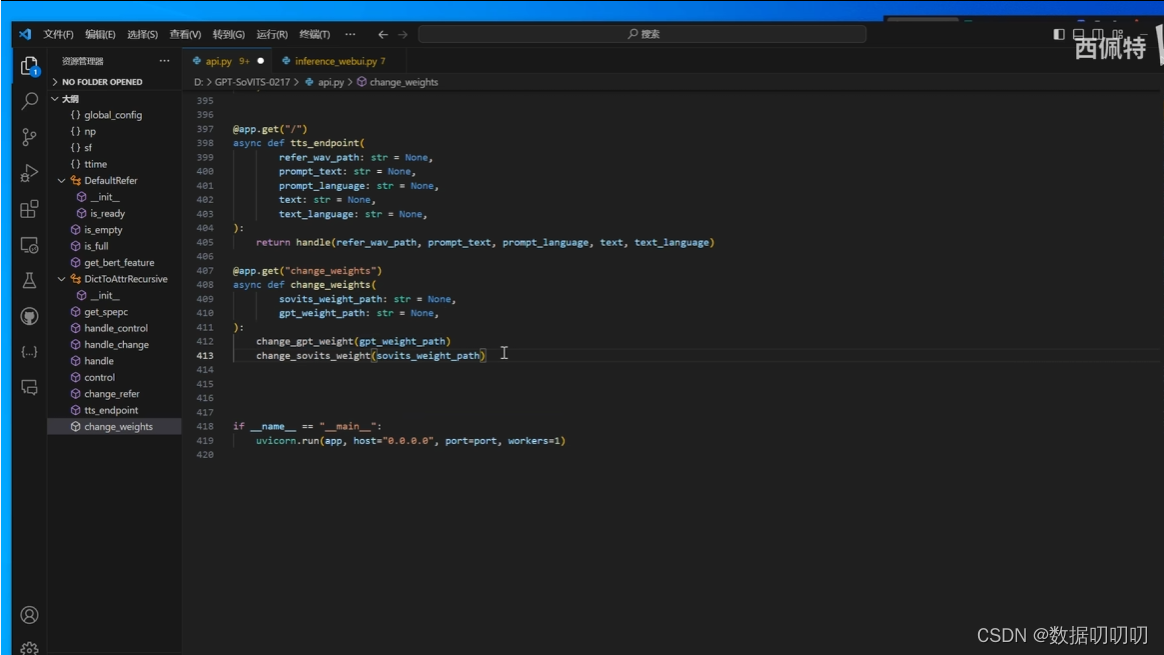
修改api。py代码增加该改变模型的选项
http://127.0.0.1:9880?refer_wav_path=D:\GPT-SoVITS\beta\GPT-SoVITS-beta0217\output\slicer_opt\vocal_zhouxingchivp5mul5l.WAV_10.wav_0000163520_0000261120.wav&prompt_text=杀人这种事,我整天都有这种想法的。&prompt_language=中文&text=你好&text_language=中文
四、API改良:
源码:GitHub - jianchang512/gptsovits-api: 适用于 GPT-SoVITS 的api调用接口
GPT-SoVITS项目的API改良与使用_gpt-sovits api-CSDN博客
api2.py和官方原版api.py 一样都不支持动态模型切换,也不建议这样做,因为动态启动加载模型很慢,而且在失败时也不方便处理。
解决方法是: 一个模型起一个api服务器,绑定不同的端口,在启动 api2.py 时,指定当前服务所要使用的模型和绑定的端口。
比如起2个服务,一个使用默认模型,绑定 9880 端口,一个绑定自己训练的模型,绑定 9881 端口,命令如下
默认模型 9880 端口: http://127.0.0.1:9880
.\runtime\python api2.py -dr "5.wav" -dt "今天好开心" -dl zh
自己训练的模型: http://127.0.0.1:9881
.\runtime\python api2.py -p 9881 -s "SoVITS_weights/mymode-e200.pth" -g "GPT_weights/mymode-e200.ckpt" -dr "wavs/10.wav" -dt "御弟哥哥,为什么甘愿守孤灯" -dl zh
五、调用接口API
# -*- coding: gbk -*-
import requests
def download_audio(url, save_path):
# 发起GET请求
response = requests.get(url)
# 检查响应状态码
if response.status_code == 200:
# 打开文件并写入音频内容
with open(save_path, 'wb') as f:
f.write(response.content)
print("音频下载完成!")
else:
print("下载失败,状态码:", response.status_code)
# 示例音频文件的URL
audio_url = r'http://127.0.0.1:9880?refer_wav_path=D:\GPT-SoVITS\beta\GPT-SoVITS-beta0217\output\slicer_opt\vocal_zhouxingchivp5mul5l.WAV_10.wav_0000163520_0000261120.wav&prompt_text=杀人这种事,我整天都有这种想法的。&prompt_language=中文&text=你好&text_language=中文'
# 保存音频文件的路径和名称
save_path = 'audio.wav'
# 调用下载函数
download_audio(audio_url, save_path)