文章目录
关于Log4j2、JUL(java.util.logging)、Logback三者之间的差异以及性能对比不在本篇博文范围之内。有兴趣的同学可参考 官方文档 Performance一节,里面给出了详细的数据。
本篇博文的目的不是日志框架的入门。如果是日志小白,请参考网上其他文章,例如以下问题都不在本篇博文范围内
- 为什么要使用日志框架,而不是系统输出?
- 各种日志框架的日志级别
- 各种日志框架的整合与配置
Log4j2和Slf4j
有过实际企业级开发的同学都知道,为了方便日后切换日志框架,通常都是用slf4j作为所有日志框架的门面。特别是这一准则还在阿里巴巴Java代码规范中提到。
但是此一时彼一时,真的要一直墨守成规么?答案显然不是。想必在所有开发者心中都会有这样的疑问。于是,带着这种疑问,直接去stackoverflow上看一看开发者们如何讨论的
- Is it worth to use slf4j with log4j2
- Can we use all features of log4j2 if we use it along with slf4j api?
上面两个问题都给出了很确定的答案。
简而言之,建议使用log4j2。log4j2的很多重要性功能(请看上述第二个问题的答案)在slf4j中都无法使用,而且log4j2基本已经把slf4j做的事,它也做了。所以没有什么理由不选择log4j2
理解Log4j2的架构
在系统性学习一个框架的时候,了解其架构是非常重要的。对于一些基础配置或者特殊配置可以通过查阅官方文档,不必死记硬背,做各种笔记。只要让自己熟悉官方文档的脉络,知道什么时候去文档的哪一章节找即可
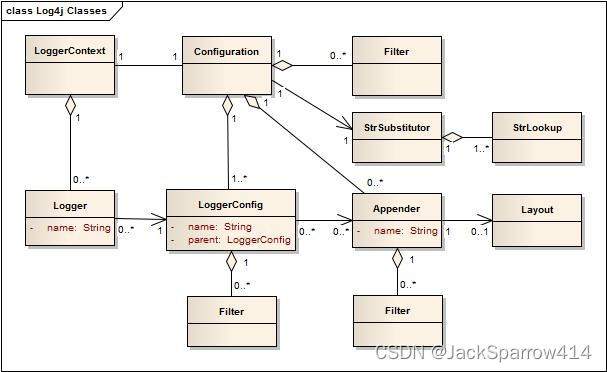
Log4j2贴心的提供了其架构图,在Architecture一节可以找到所有内容
要想看懂上面这张图,需要了解一下UML类图的表现形式
了解UML类图
UML类图示例
根据上面的UML类图示例,分别做以下说明
UML类图的主要表示方法
- 一个矩形分为三格
- 第一格为类名
- 第二格为权限 属性名 返回类型
- 第三格为权限 方法名(参数列表) :返回类型
其中权限分为四种
+Public-Private#Protected~Package/Internal
UML 类图常见的主要有以下几种关系
- 实现(Realization),用虚线+实心箭头表示,箭头指向被实现接口
- 继承(Inheritance),用实线+实现箭头表示,箭头执行被继承类
- 单向关联(Association),用带箭头的实线表示,如果一个类知道或者引用了另一个类,而另一个类不知道或者没有引用这个类,则这两个类是单向关联。箭头指向被引用或者被包含的类
- 双向关联(Link),用一条实现来表示,双向关联是两个类彼此都知道对方的存在
- 聚合(Aggregation),用实线+菱形表示,用来表示部分和整体的关系。菱形指向整体。在聚合关系中,部分可以脱离整体存在
- 组合(Composition),用实线+实心菱形表示,也是用来表示部分和整体的关系。菱形指向整体。在组合关系中,部分不可以脱离整体存在
推荐阅读文章以及阅读visual studio中关于uml的文档部分
在Markdown中画UML类图
参考mermaid中画类图一节,里面非常详细。同时也可以当做学习UML类图的基础知识
理解Log4j2中各个组件的作用
根据官方架构图
LoggerContext
The LoggerContext acts as the anchor point for the Logging system
Configuration
Every LoggerContext has an active Configuration.The Configuration contains (聚合)all the Appenders, context-wide Filters, LoggerConfigs and contains the reference to the StrSubstitutor.
Logger
As stated previously, Loggers are created by calling LogManager.getLogger. The Logger itself performs no direct actions. It simply has a name and is associated(单向关联) with a LoggerConfig.
在配置文件中的标签内配置,基本为下列格式
<Loggers>
<Root level="debug">
<AppenderRer ref="Console"/>
</Root>
<Logger name="logName" level="info">
<AppenderRef ref="Console"/>
</Logger>
</Loggers>
- Root标签代表项目全局log级别,如果没有额外在Logger标签内声明,则所有Logger的日志级别都会继承自Root
- Logger为特定的log指定日志级别
二者都需要指定AppenderRef,为什么?因为上面说了,Appender是代表日志实际输出的地方。既然打了日志,那肯定要指定日志的输出位置,否则不会输出
LoggerConfig
LoggerConfig objects are created when Loggers are declared in the logging configuration. The LoggerConfig contains a set of Filters that must allow the LogEvent to pass before it will be passed to any Appenders. It contains references to the set of Appenders that should be used to process the event
Filter
In addition to the automatic log Level filtering that takes place as described in the previous section, Log4j provides Filters that can be applied before control is passed to any LoggerConfig, after control is passed to a LoggerConfig but before calling any Appenders, after control is passed to a LoggerConfig but before calling a specific Appender, and on each Appender. In a manner very similar to firewall filters, each Filter can return one of three results, Accept, Deny or Neutral. A response of Accept means that no other Filters should be called and the event should progress. A response of Deny means the event should be immediately ignored and control should be returned to the caller. A response of Neutral indicates the event should be passed to other Filters. If there are no other Filters the event will be processed
Appender
The ability to selectively enable or disable logging requests based on their logger is only part of the picture. Log4j allows logging requests to print to multiple destinations. In log4j speak, an output destination is called an Appender.
也就是说,一个Appender代表日志输出的位置
Currently, appenders exist for the console, files, remote socket servers, Apache Flume, JMS, remote UNIX Syslog daemons, and various database APIs. See the section on Appenders for more details on the various types available. More than one Appender can be attached to a Logger
在配置文件中的标签内配置
Layout
The Layout is responsible for formatting the LogEvent according to the user’s wishes, whereas an appender takes care of sending the formatted output to its destination
以上所有内容均来自Architecture一节
示例配置
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<!-- onMatch匹配level及以上级别, 所以为了输出INFO, 这里拒绝WARN及以上级别的日志, 相反onMismatch的时候则要接受-->
<!-- Console Appender只输出WARN级别以下的日志-->
<ThresholdFilter level="WARN" onMatch="DENY" onMismatch="ACCEPT"/>
<PatternLayout pattern="%d{HH:mm:ss.SSS} [%t] %level %logger - %msg%n"/>
</Console>
<RollingFile name="MyFile" fileName="logs/app.log" immediateFlush="true"
filePattern="logs/$${date:yyyy-MM-dd}/app-%d{yyyy-MM-dd}-%i.log.gz">
<!-- RollingFile Appender只输出WARN及以上级别的日志-->
<ThresholdFilter level="WARN" onMatch="ACCEPT" onMismatch="DENY"/>
<JsonTemplateLayout eventTemplateUri="classpath:EcsLayout.json"/>
<Policies>
<TimeBasedTriggeringPolicy/>
<SizeBasedTriggeringPolicy size = "10KB"/>
</Policies>
<DefaultRolloverStrategy fileIndex="nomax"/>
</RollingFile>
</Appenders>
<Loggers>
<Root level="info">
<!-- 根据日志级别输出到不同的Appender -->
<AppenderRef ref="Console"/>
<AppenderRef ref="MyFile"/>
</Root>
<Logger name="com.example.log4j2.controller" level="debug" additivity="false">
<AppenderRef ref="MyFile"/>
</Logger>
</Loggers>
</Configuration>
主要看RollingFile Appender的配置
A RollingFileAppender requires a TriggeringPolicy and a RolloverStrategy. The triggering policy determines if a rollover should be performed while the RolloverStrategy defines how the rollover should be done
大白话就是,触发策略负责什么时候生成滚动文件。而滚动策略负责生成的滚动文件的%i策略
-
配置Appender类型为RollingFile,名字为MyFile,表示负责输出日志到文件
-
配置文件名字为logs/app.log
-
配置filePattern为年月日-%i.log.gz。以gz结尾会开启压缩
-
配置Filter为ThresholdFilter,filter负责判断满足条件的LogEvent才能被此Appender处理
-
配置Layout为EcsLayout.json,Layout负责格式化日志输出格式
-
配置Trigger Policy为两个,基于时间的和基于文件大小的。配置基于文件大小的policy的时候,filePattern中必须包含%i
-
配置RolloverStrategy为DefaultRolloverStrategy,fileIndex设置成nomax,意味着%i从1开始,并且没有最大值
inally, as of release 2.8, if the fileIndex attribute is set to “nomax” then the min and max values will be ignored and file numbering will increment by 1 and each rollover will have an incrementally higher value with no maximum number of files
实际开发中设置成nomax比较好
为具体Logger指定Appender为RollingFile
additivity表示在当前Logger输出后,不需要在其父Logger再输出,具体解释可见Architecture一节
上述配置中并没有网上的各种奇奇怪怪配置,例如
%-5level %logger{36}
配置这些属实没必要,直接使用默认配置即可。而且时间一长根本不知道什么意思。
In the example above the conversion specifier %-5p means the priority of the logging event should be left justified to a width of five characters.
也就是左对齐,宽度为5个空格
来自Layout一节解释
而36更没必要知道了用了,我们只需要知道log4j2默认输出logger的全名就完事儿,如果真的想要了解。参考PatternLayout
如何将UncaughtException也交给Log4j处理?
在Java中,对于UncaughtException,默认情况下会使用System.err.print进行输出。
什么是UncaughtException?简单理解就是未进行try-catach处理的UnCheckedException。 你可能会有疑问,在web应用中,在Spring中不是有全局的ExceptionHandler吗?但是实际上的情况可能是下面这种
new Thread(() -> {
int a = 1/0;
}).start();
这种在单独线程里进行业务处理,并且没有对UnCheckedException异常进行处理的代码,将会直接把错误输出到控制台
Exception in thread
这就导致了,我们输出的日志格式不全是Log4j指定的。还有一种稍微复杂一点的情况是,如果我们希望将所有日志输出到文件而不是控制台(产品环境里很常见),那么对于System.err/out这种情况,我们会丢失这部分日志。
解决方法:
实现UncaughtExceptionHandler 接口并在该类中使用Log4j打印异常
public class GlobalUncaughtExceptionHandler implements Thread.UncaughtExceptionHandler {
private static final Logger LOGGER = LogManager.getLogger();
@Override
public void uncaughtException(Thread t, Throwable e) {
LOGGER.warn("DEV-18493: UnCaughtException", e);
}
}
在应用程序最开始执行的地方,通常是某个Listener
Thread.setDefaultUncaughtExceptionHandler(new GlobalUncaughtExceptionHandler());
关于JVM如何处理未捕获异常的更多细节请参考这篇文章或Thread#setDefaultUncaughtExceptionHandler 注释
其他开源库对UncaughtException的处理,例如
- org.apache.kafka.common.utils.KafkaThread#configureThread
- canal下的CanalLauncher


Log4j2中的各种桥接器
实际情况中,我们的项目中没使用log4j2之前,可能存在多种日志框架,例如JUL、Apache Commons Logging。当我们决定使用Log4j2时,为了减少代码的改动,Log4j2为我们提供了各种桥接器。可以在不改动代码的情况下,使用Log4j2输出
- Apach Commons Logging桥接器
- JUL桥接器
使用异步日志
Log4j2最高性能就是开启异步日志之后,性能可提高数十倍
开启异步日志
引入依赖
<!-- https://mvnrepository.com/artifact/com.lmax/disruptor -->
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
<version>3.4.4</version>
</dependency>
启动配置
-Dlog4j2.contextSelector=org.apache.logging.log4j.core.async.AsyncLoggerContextSelector
如何确定开启异步日志?
How to verify log4j2 is logging asynchronously via LMAX disruptor?
同时启动时配置
-Dlog4j2.debug=true
在控制台如果看到类似以下字样
Starting AsyncLogger disruptor…
即代表开启异步日志成功
官方非常不建议开启异步日志的时候输出location信息。所谓location信息是指className, methodName、lineNumber等。如果输出这些信息,性能会降低几十倍。那么如何能不能曲线救国输出className呢?可以
private static final Logger LOGGER = LogManager.getLogger();
这种格式下,Logger名字就是className.这样输出loggerName就和className是等价的