转载自:https://blog.csdn.net/baidu_26646129/article/details/80464447
本文主要介绍百度地图POI数据获取:从百度地图得到POI数据,以json格式保存;
POI数据获取的原理部分还可以参照零基础掌握百度地图兴趣点获取POI爬虫(python语言爬取)(基础篇)。
POI数据获取
百度地图POI数据可以从百度地图提供的API——兴趣点坐标获取得到。得到的POI信息包括了名称、经纬度坐标、地址等等,具体的接口使用说明可以参考百度地图WEB服务api说明中的地点检索。
从说明文档我们可以发现,POI数据获取的关键在于构造出合适的url,访问该url便能请求到相应的POI数据。因此,我们先对百度地图WEB服务api中的url进行详细的说明。
http://api.map.baidu.com/place/v2/search?query=银行&bounds=39.915,116.404,39.975,116.414&output=json&ak={您的密钥} //GET请求
以上是百度地图说明文档提供的一个搜索url示例,我们可以将其划分为以下几个部分:
前缀部分:无论进行何种搜索,需要的数据格式如何,请求的url都需要这一部分
http://api.map.baidu.com/place/v2/search?
参数部分:对请求的数据进行定制,你可以指定特定的关键词、搜索区域、输出类型以及你的ak(access key)
query=银行&bounds=39.915,116.404,39.975,116.414&output=json&ak={您的密钥}
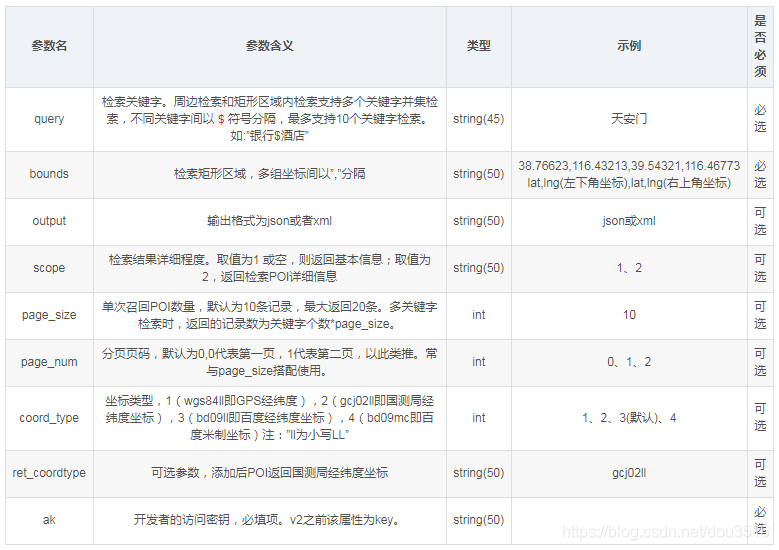
前缀部分对所有请求都一致不需要过多的说明,而参数部分影响搜索的结果,需要详细说明。由于百度地图提供了三种POI搜索方式,即行政区划区域搜索、周边搜索、矩形区域搜索,但这几种搜索仅仅在一些参数上存在差异,大部分参数都是相同的,返回的结果也是相同的,本文仅以矩形区域搜索请求参数举例说明:
返回参数
需要特别注意的是:
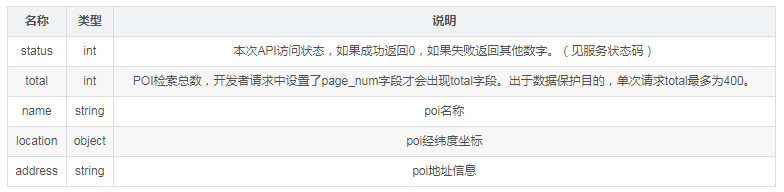
百度地图为了保护数据,单次请求total最多为400,也就是只能搜出400个结果,如果搜索结果大于400个的时候只显示400条记录;
百度地图为非认证开发者提供的配额为2000次请求/每天,并发访问的限制为120。
第一个问题的解决可以通过划分子搜索区域,将需要搜索的矩形区域划分为多个面积更小的矩形区域,将他们的搜索结果进行合并即得到了需要的搜索结果。
第二个问题的解决通过申请多个ak,交替使用,同时减缓请求速度。
最后实现的代码如下:
# -*- coding: utf-8 -*-
# 第一行必须有,否则报中文字符非ascii码错误
import urllib
import json
import time
#ak需要在百度地图开放平台申请
ak = "XXX"
#关键词
query=["社会福利院"]
page_size=20
page_num=0
scope=1
#范围:
#左下坐标 30.379,114.118
#右上坐标 30.703,114.665
#中间坐标 30.541,114.3915
bounds=[
[30.379,114.118,30.541,114.3915],
[30.379,114.3915,30.541,114.665],
[30.541,114.118,30.703,114.3915],
[30.541,114.3915,30.703,114.665]
]
new_bounds = []
# col_row 将bounds的每一小块继续细分为3行3列,可以防止区域内的搜索数量上限400
col_row = 3
for lst in bounds:
distance_lat = (lst[2] - lst[0])/col_row
distance_lon = (lst[3] - lst[1])/col_row
for i in range(col_row):
for j in range(col_row):
lst_temp = []
lst_temp.append(lst[0]+distance_lat*i)
lst_temp.append(lst[1]+distance_lon*j)
lst_temp.append(lst[0]+distance_lat*(i+1))
lst_temp.append(lst[1]+distance_lon*(j+1))
new_bounds.append(lst_temp)
queryResults = []
for bound in new_bounds:
np=True
a=[]
while np==True:
#使用百度提供的url拼接条件
url="http://api.map.baidu.com/place/v2/search?ak="+str(ak)+"&output=json&query="+str(query[0])+"&page_size="+str(page_size)+"&page_num="+str(page_num)+"&bounds="+str(bound[0])+","+str(bound[1])+","+str(bound[2])+","+str(bound[3])
#请求url读取,创建网页对象
jsonf=urllib.urlopen(url)
page_num=page_num+1
jsonfile=jsonf.read()
#判断查询翻页进程
s=json.loads(jsonfile)
total=int(s["total"])
a.append(total)
queryResults.append(s)
max_page=int(a[0]/page_size)+1
#防止并发过高,百度地图要求并发小于120
time.sleep(1)
if page_num>max_page:
np=False
page_num=0
print "search complete"
print "output: "+str(bound)
print "total: "+str(a[0])
print ("")
results=open(".\results.txt",'a')
results.write(str(queryResults).decode('unicode_escape'))
results.close()
print "ALL DONE!"