本文以博主自己的一个具体任务为例,记录调用大模型来辅助设计奖励函数的过程。
注1:博主的目标是在强化学习过程中(CARLA环境十字路口进行自动驾驶决策控制),通过调用大模型API进行奖励函数设计,进而生成可执行的奖励函数代码,并完成自动调用。以大模型具备的丰富知识,辅助进行奖励设计,一定程度上解决人工设计奖励的局限性。
注2:该文只告诉模型生成奖励函数对应的函数名、输入参数和函数作用(为了方便后续处理和调用),函数内部具体逻辑由模型自己推理。
注3:该文调用的大模型为智谱清言的GLM4(新人注册有免费额度)。
之前发的原文:(一看就会)调用大模型API帮我写可执行代码? - 知乎 (zhihu.com)
该文为最新更新的版本。
接下来直接开始!
目录
一:注册账号,获取API_Key
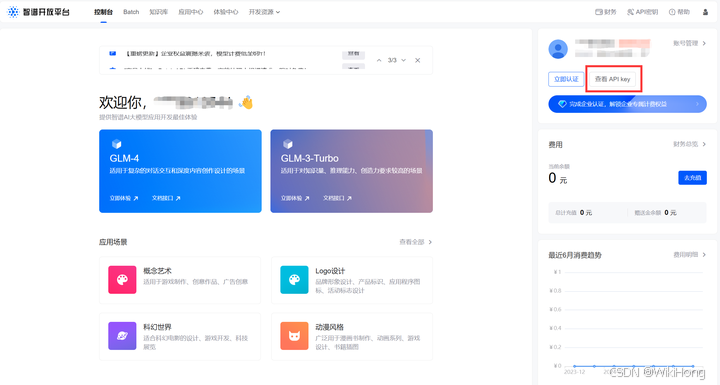
- 1 首先前往官网,进行注册,网址:智谱AI (zhipuai.cn)

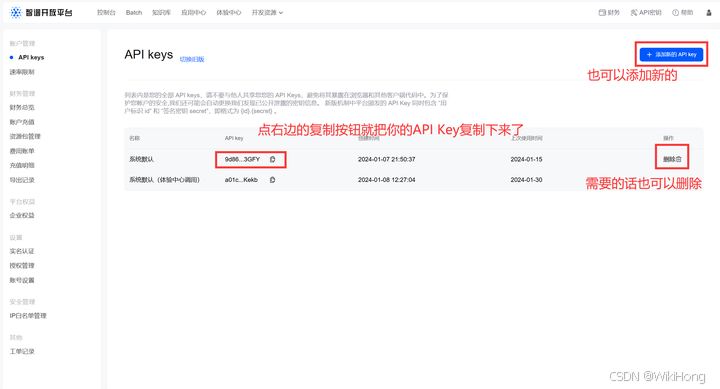
- 2 登录进去后,获取你的API_Key,在后续你调用模型的时候需要用到
注:API Key不要泄露出去了,如果不小心泄露了,记得删除重新添加
- 3 检查你的额度。新人注册的话,目前会赠送免费额度:GLM-4(500W tokens)GLM-3-Turbo(2000W tokens),限时一个月。

二:调用API,进行测试
- 1 安装最新版zhipuai包
pip install zhipuai
pip install --upgrade zhipuai- 2 基础调用与测试
from zhipuai import ZhipuAI
client = ZhipuAI(api_key=API_Key) # 这里的API_Key就是之前在官网上复制下来的那个API_Key
# 同步调用
# model和messages参数是必须的,其他接口请求参数可根据需要参考官方文档进行设定
response = client.chat.completions.create(
model="glm-4",
messages=[
{"role": "user", "content": '你好'}
],
)
text = response.choices[0].message.content
print(text)如果没有报错并正常输出如下,那就成功了
你好👋!我是人工智能助手智谱清言,可以叫我小智🤖,很高兴见到你,欢迎问我任何问题。
以上为同步调用的例子,其他异步调用、流式调用等方法以及其他接口请求参数,可参考官网接口文档:【开发资源-接口文档】智谱AI开放平台 (bigmodel.cn)
三:生成可执行奖励函数代码并自动调用
- 1 让模型根据你的提示(prompt_init_sys、prompt_user)生成可执行奖励函数代码,这里的prompt设计是非常关键的部分,文末会放上博主进行测试的prompt
from zhipuai import ZhipuAI
key = "XXXXXXXXXXXXXXXX"
client = ZhipuAI(api_key=key)
response = client.chat.completions.create(
model='glm-4',
messages=[
{'role': 'system', 'content': prompt_init_sys},
{'role': 'user', 'content': prompt_user}
]
)
result = response.choices[0].message.content # 这里返回的就是模型生成的回复了,除了代码主体可能还包含其他内容,需要过滤- 2 对模型的回复进行处理,筛选代码主体,剃掉多余的部分并保存
import re
def process_code_block(text: str) -> str:
code_block_regex = r"```(python)?\n?([\s\S]*?)```"
matches = re.findall(code_block_regex, text)
if matches:
code = "\n".join([m[1] for m in matches])
else:
code = text
return code
# 代码处理
code = process_code_block(result)
# 代码储存,方便后续随时调用,也可存下来备用或用于下次的优化基础
with open('reward_func.py', 'w') as f:
f.write(code)- 3 调用代码进行需要的操作。这里博主调用模型生成了四种奖励函数(距离奖励、动作奖励、安全奖励、其他奖励),在强化学习训练/测试过程中直接调用即可。
import os
# 导入模型生成的代码
if os.path.isfile(file_name):
try:
import reward_func as R
except Exception as e :
print('Error happened when import reward_func: ', e)
# 在需要的时候进行调用即可
if R:
try:
dis_reward = R.distance_reward('turn_left', 3.5, 2.6, 3.3, 4.6)
act_reward = R.action_reward('turn_left', 0.5, 0.3, 0.5, 0.3, 0, 0)
print('dis_reward = ', dis_reward)
print('act_reward = ', act_reward)
except Exception as e:
print('Attention: ',e)四:博主的prompt
prompt的设计非常关键,它在很大程度上决定了生成代码的质量,以下是博主针对自己任务设计的提示词,能基本满足要求,但还存在许多优化空间,示例仅供参考。
- 1 prompt_init_sys 在这部分博主给模型假定一个身份,让其明白自己是谁,要做个什么事
prompt_init_sys = """
You are a reward engineer trying to write reward functions to solve reinforcement learning tasks as effective as possible.
Your goal is to write a reward function for the environment that will help the agent learn to complete the specific task at an intersection.
"""- 2 prompt_user 在这部分博主给模型设定了任务要求和奖励函数的设计准则
prompt_user = """
We have a description of an agent's infomation and we want you to turn that into the corresponding program with following functions:
```
def distance_reward(task_name, current_x, current_y, end_x, end_y)
```
task_name is one of ('turn_left','turn_right','go_straight').
current_x: the current x coordinate of ego agent, the type is float.
current_y: the current y coordinate of ego agent, the type is float.
end_x: the destination x coordinate of ego agent, the type is float.
end_y: the destination y coordinate of ego agent, the type is float.
```
def action_reawrd(task_name, throttle, last_throttle, steer, last_steer, brake, last_brake)
```
task_name is one of ('turn_left','turn_right','go_straight').
throttle: the current throttle (value from 0 to 1) inferred by ego agent, the type is float, it indicates the size of the car's throttle or the opening of the throttle.
steer: the current steer (value from -1 to 1) inferred by ego agent, the type is float, it indicates the size of the car's steering.
brake: the current brake state (value is 0 or 1) inferred by ego agent, the type is int, 0 means no brakes, 1 means brakes.
last_throttle: the throttle (value from 0 to 1) inferred by ego agent before one time step, the type is float, it indicates the size of the car's throttle or the opening of the throttle.
last_steer: the steer (value from -1 to 1) inferred by ego agent before one time step, the type is float, it indicates the size of the car's steering.
last_brake: the brake state (value is 0 or 1) inferred by ego agent before one time step, the type is int, 0 means no brakes, 1 means brakes.
```
def security_reward(task_name, ego_x, ego_y, other_x, other_y)
```
task_name is one of ('turn_left','turn_right','go_straight').
ego_x: the current x coordinate of ego agent, the type is float.
ego_y: the current y coordinate of ego agent, the type is float.
other_x: the current x coordinate of other three nearby vehicles, the type is list which consists of three float type elements.
other_y: the current y coordinate of other three nearby vehicles, the type is list which consists of three float type elements.
```
def extra_reward(task_name, ego_x, ego_y, other_x, other_y, throttle, last_throttle, steer, last_steer, brake, last_brake)
```
task_name is one of ('turn_left','turn_right','go_straight').
ego_x: the current x coordinate of ego agent, the type is float.
ego_y: the current y coordinate of ego agent, the type is float.
other_x: the current x coordinate of other three nearby vehicles, the type is list which consists of three float type elements.
other_y: the current y coordinate of other three nearby vehicles, the type is list which consists of three float type elements.
throttle: the current throttle (value from 0 to 1) inferred by ego agent, the type is float, it indicates the size of the car's throttle or the opening of the throttle.
steer: the current steer (value from -1 to 1) inferred by ego agent, the type is float, it indicates the size of the car's steering.
brake: the current brake state (value is 0 or 1) inferred by ego agent, the type is int, 0 means no brakes, 1 means brakes.
last_throttle: the throttle (value from 0 to 1) inferred by ego agent before one time step, the type is float, it indicates the size of the car's throttle or the opening of the throttle.
last_steer: the steer (value from -1 to 1) inferred by ego agent before one time step, the type is float, it indicates the size of the car's steering.
last_brake: the brake state (value is 0 or 1) inferred by ego agent before one time step, the type is int, 0 means no brakes, 1 means brakes.
Explanation:
distance_reward() consider the distance from now to destination.
action_reawrd() consider the action rationality inferred by ego agent, and also consider the driving efficiency of ego agent.
security_reward() consider the security of the ego agent, because if the distance between ego and others is too small, collision may occur.
extra_reward() takes into account potential reward content that may not have been taken into account in the preceding functions.
Remember:
1. Always format the code in code blocks. In your response all four functions above ( distance_reward, action_reawrd, security_reward, extra_reward ) should be included.
2. Do not invent new functions or classes. The only allowed functions you can use are the ones listed above. Do not leave unimplemented code blocks in your response.
3. The only allowed library is math. Do not import or use any other library.
4. If you are not sure what value to use, just use your best judge. Do not use None for anything.
5. In all functions, you should consider the calculation of reward may differ in different tasks, so attention the task_name.
6. If needed, you can add some constants and variables to help your reward function design.
7. The return value of all reward functions must be limited to 4 decimal places.
please give me your reward design.
"""五:其他要说的
注1:遇到问题主要参考官方接口文档
在调用模型过程中,想尝试更多东西或遇到什么问题,可参考官方接口文档,里面详细描述了模型调用的很多注意事项。官方接口文档地址:智谱AI开放平台 (bigmodel.cn)
注2:调用大模型API进行奖励设计的实时性问题
博主测试时,整个过程调用一次生成奖励函数的时间较长,故博主在进行强化学习训练/测试时,只在初始化阶段进行奖励设计大模型调用,在reset()和step()并不直接调用大模型,而是调用初始化阶段大模型已经生成的奖励函数。在后续会考虑实时调用大模型进行一些其他尝试。
注3:调用模型的功能
目前能免费调用的功能好像是用几个特定的通用大模型进行问答类语言任务,之前能支持是glm-4和glm-3-turbo模型,现在好像更多了,大家可以多尝试。包括:glm-4-0520, glm-4, glm-4-air, glm-4-airx, glm-4-flash等。
注4:如果需要进行模型微调等任务,需要付费。具体参数列表及操作示例可参考官方接口文档