Hashmap的实现原理:
import java.util.HashMap;
public class Node<K,V> {
private K key;
private Node<K,V> next=null;
private V obj;
public K getKey() {
return key;
}
public void setKey(K key) {
this.key = key;
}
public void setNext(Node<K,V> next) {
this.next = next;
}
public Node<K,V> getNext() {
return next;
}
Node(K key,V obj) {
this.key=key;
this.obj = obj;
}
public void setObj(V obj) {
this.obj = obj;
}
public V getObj() {
return obj;
}
}}
首先是链表的实现原理
1.节点node里存了k,v就是key和value两个值。
2.getnext用来获取下一个节点。
3.setnext用来设置下一个节点。
接口
public abstract class MyHashMap<K, V> {
abstract int size();
abstract boolean isEmpty();
abstract boolean containsKey(K key);
abstract V get(K key);
abstract V put(K key, V value);
abstract V remove(K key);
abstract void clear();
}
实现类
public class HashMap01<K, V> extends MyHashMap<K, V> {
private int size = 0;
private int cap = 16;
Node<K, V>[] array = new Node[cap];
private final double anInt = 0.75;
@Override
int size() {
return size;
}
@Override
boolean isEmpty() {
return size == 0;
}
@Override
boolean containsKey(Object key) {
Node n;
int i = key.hashCode() % cap;
if (array[i] != null) {
n = array[i];
while (null != n) {
if (!key.equals(n.getKey())) {
n = n.getNext();
} else return true;
}
}
return false;
}
@Override
V get(K key) {
Node n;
int i = key.hashCode() % cap;
if (array[i] != null) {
n = array[i];
while (null != n) {
if (!key.equals(n.getKey())) {
n = n.getNext();
} else return (V) n.getObj();
}
}
return null;
}
@Override
V put(K key, V value) {
judgmentCapacity();
Node n;
int nums = key.hashCode() % cap;
if (array[nums] == null) {
array[nums] = new Node<>(key, value);
size++;
return null;
}
n = array[nums];
if (key.equals(n.getKey())) {
n.setObj(value);
size++;
} else {
while (null != n) {
if (!key.equals(n.getKey())) {
n = n.getNext();
} else {
n.setObj(value);
return (V)n.getObj();
}
}
n = array[nums];
while (null != n) {
if (n.getNext() == null) {
Node node = new Node(key, value);
n.setNext(node);
size++;
return (V)n.getObj();
} else n = n.getNext();
}
}
return null;
}
@Override
V remove(K key) {
int nums = key.hashCode() % cap;
if (array[nums] == null) {
return null;
}
if (array[nums].getKey().equals(key)) {
if (array[nums].getNext() == null) {
array[nums] = null;
size--;
return null;
} else array[nums] = array[nums].getNext();
} else {
Node n;
n = array[nums];
while (null != n.getNext()) {
if (!key.equals(n.getNext().getKey())) {
n = n.getNext();
} else {
if (n.getNext().getNext() == null) {
n.setNext(null);
size--;
return null;
} else {
n.setNext(n.getNext().getNext());
size--;
return null;
}
}
}
}
return null;
}
private void put01(K key, V value, Node[] array1) {
Node n;
int nums = key.hashCode() % cap;
if (array1[nums] == null) {
array1[nums] = new Node<>(key, value);
return;
}
n = array1[nums];
if (key.equals(n.getKey())) {
n.setObj(value);
} else {
while (null != n) {
if (!key.equals(n.getKey())) {
n = n.getNext();
} else n.setObj(value);
}
n = array1[nums];
while (null != n) {
if (n.getNext() == null) {
Node node = new Node(key, value);
n.setNext(node);
} else n = n.getNext();
}
}
}
private boolean judgmentCapacity() {//判断是否满足扩容条件扩容
double nums = 0;
for (int i = 0; i < array.length; i++) {
if (array[i] != null) nums++;
}
if (nums / anInt >= array.length) {
cap = cap * 2;
Node<K, V>[] array1 = new Node[cap];
Node n;
for (int i = 0; i < array.length; i++) {
if (array[i] == null) {
continue;
} else {
n = array[i];
while (true) {
if (n.getNext() != null) {
K key = (K) n.getKey();
V value = (V) n.getObj();
put01(key, value, array1);
n = n.getNext();
} else break;
}
}
}
array = array1;
return true;
}
return false;
}
@Override
void clear() {
array=new Node[cap];
size=0;
}
}
然后就是put的实现原理:
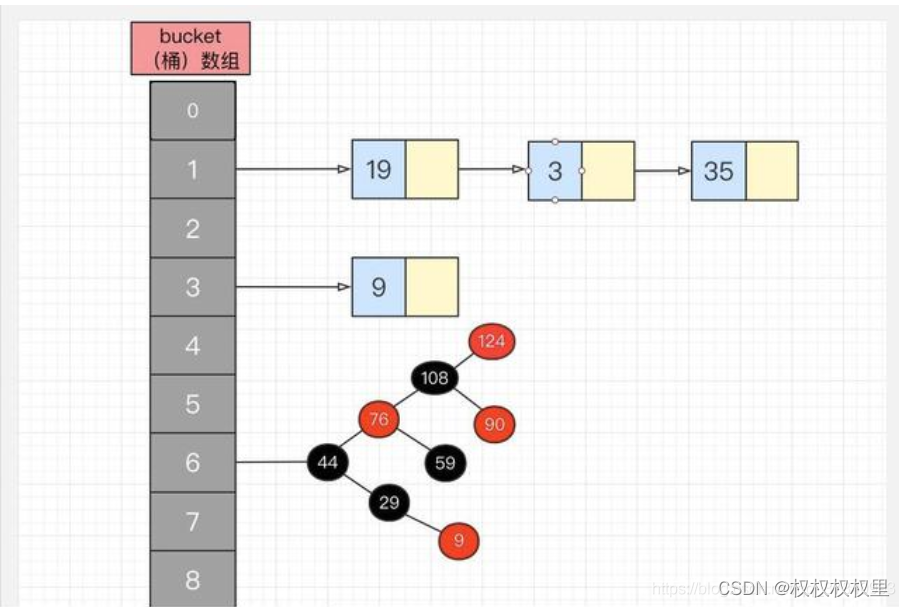
结构是数组加链表的形式 数组也就是桶子里只存放链表的节点(也就是地址)
1.每次put进去先判断满不满足扩容条件 :在桶子装满2/3的时候进行扩容 扩容为之前的2倍 也就是数组长度要扩容为之前的两倍
2.调用方法计算哈希值 这里我采用最简单的计算方法:key用哈希值计算以后直接对数组长度除余 得到的余数对应桶子(数组下标) 如果该桶子为空直接将结点放入桶子。
3.如果不为空就遍历该桶子对应的链表 查看有没有key相同的节点 替换里面的vaue值。
4.如果没有找到相同key的节点,就将该桶子里的链表最后一个节点的后继节点设为 刚刚put的节点也就是setnext() 方法
@Override
V put(K key, V value) {
judgmentCapacity();
Node n;
int nums = key.hashCode() % cap;
if (array[nums] == null) {
array[nums] = new Node<>(key, value);
size++;
return null;
}
n = array[nums];
if (key.equals(n.getKey())) {
n.setObj(value);
size++;
} else {
while (null != n) {
if (!key.equals(n.getKey())) {
n = n.getNext();
} else {
n.setObj(value);
return (V)n.getObj();
}
}
n = array[nums];
while (null != n) {
if (n.getNext() == null) {
Node node = new Node(key, value);
n.setNext(node);
size++;
return (V)n.getObj();
} else n = n.getNext();
}
}
return null;
}
然后就是get()的原理:
很简单
1.根据get进来的的key计算哈希值除余 找到对应的桶子如果桶子为空直接返回false
2.如果不为空就查找相同key的节点 然后返回value值。
@Override
V get(K key) {
Node n;
int i = key.hashCode() % cap;
if (array[i] != null) {
n = array[i];
while (null != n) {
if (!key.equals(n.getKey())) {
n = n.getNext();
} else return (V) n.getObj();
}
}
return null;
}
最重要的是扩容机制:
1.上面说了每次put了之后 必须先检查满不满足扩容条件 这里没有使用红黑树
2.遍历所有数组 判断有没有满足数组长度的2/3 如果满足就开始扩容
新建一个之前二倍长度的数组 然后把之前的hashmap里的值全都复制进来
3.将之前hashmap数组的指针指向这个新的数组 就完成了扩容。
private boolean judgmentCapacity() {//判断是否满足扩容条件扩容
double nums = 0;
for (int i = 0; i < array.length; i++) {
if (array[i] != null) nums++;
}
if (nums / anInt >= array.length) {
cap = cap * 2;
Node<K, V>[] array1 = new Node[cap];
Node n;
for (int i = 0; i < array.length; i++) {
if (array[i] == null) {
continue;
} else {
n = array[i];
while (true) {
if (n.getNext() != null) {
K key = (K) n.getKey();
V value = (V) n.getObj();
put01(key, value, array1);
n = n.getNext();
} else break;
}
}
}
array = array1;
return true;
}
return false;
}