以下参数中有sql字眼的一般只有spark-sql模块生效,如果你看过spark的源码,你会发现sql模块是在core模块上硬生生干了一层,所以反过来spark-sql可以复用core模块的配置,例外的时候会另行说明,此外由于总结这些参数是在不同时间段,当时使用的spark版本也不一样,因此要注意是否有效,验证的方法也很简单配置之后,如果当前版本有效,你就可以在任务ui的Environment参数列表中查到,如果本博主已经踩了坑的会直接说明。看完之后如果有core模块优化参数不多的感觉,无需自扰,因为core模块的开发本身就是80%依赖代码级优化实现的,比如rdd集的分区拆分、加盐、转换等等都是在代码级别完成的,而不是任务提交参数。
1、任务使用资源限制,基本参数,注意的是这些资源配置有spark前缀是因为他们是标准的conf配置,也就是submit脚本,你调用--conf参数写的,和--driver.memory这种属于不同的优先级,--driver.memory这种优先级比它高,对于spark来讲,数据量和计算量是两个不同的概念,计算任务本身不止有单一的MR架构那样一个map一个reduce的直白执行逻辑,还有很多复杂的任务task,所以随着执行计划的不同,往往计算量要大于数据量,而且这个差距是成正比的放大,要使用的计算资源也更多,除了计算任务本身,还有伴随计算产生的附加消耗,因此往往1G的数据要付出3G的计算资源,甚至更多,在具体计算的时候使用多少资源,就需要经验了,不过初学者可以参考一个公式min(计算数据大小/容器内存+20%左右的预留=容器个数,任务开始执行后配合其他参数可支持并行task最多时的容器个数)、driver的内存(spark.driver.memory)永远大于driver可收集数据集大小(spark.driver.maxResultSize) 、单容器的内存和核数的比例是10:1、单容器的大小不应太大一般在6C/60G左右就最多了
在容器资源的估算上,除了上面提到的用数据量来估算,也有的地方使用总核数来估算,也就是用总量可用有多少,再除以其他的相关数据值,这种情况是因为拥有的集群资源不多,没有办法支撑任务完全自主扩张,虽然两种估算方法最后的目的是一样的,但是后者对于大任务所需资源来讲,肯定会影响任务的运行,具体使用的时候看情况而定即可
在具体配置的时候,容器个数最好交给动态延展去处理,这样不会造成在启动容器量和在计算数据量上的不协调,除非你容器设置的本身不够。当你的任务特别大,大到超过了容器读写性能的瓶颈,再考虑用num的方式直接指定定额的容器个数,因为随着不同集群性能的影响,过大的任务在容器动态延展上会很吃力,任务会不稳定。
至于一个集群的性能读写瓶颈,如果你能拿到当前集群的冒烟测试结果,那是最好的,但是越大的集群,冒烟测试越不好做,所以除非是私有云的小项目,否则一般很难拿到,此时最直观的观察点就是这个集群的shuffer额度,在保证任务跑通的情况下,一个集群能容纳的shuffer量越高他的读写瓶颈就越高,本作者最高操作过读写瓶颈在10Tshuffer下保证任务运行,10t以上就不太好说了
spark.driver.memory=20G #applicationmaster启动的driver进程占用内存
spark.driver.cores=4 #applicationmaster启动的driver进程占用核数
spark.executor.cores=4 #容器占用核数
spark.executor.memory=40G #容器占用的内存数
spark.num.executors=10 #任务用到的总容器数
2、限制sql任务运行时拉取的分区数和拉去文件总大小的上线
spark.sql.watchdog.maxPartitions=2000
spark.sql.watchdog.maxFileSize=3t
3、文件聚合,文件聚合的阈值会参照分区大小决定,就是说去设置AQE
spark.sql.optimizer.insertRepartitionBeforeWriteIfNoShuffle.enabled=true #是否对不发生shuffer的stage做聚合
spark.sql.optimizer.insertRepartitionBeforeWrite.enabled=true #是否在写入文件之间聚合
spark.sql.optimizer.finalStageConfigIsolation.enabled=true #最后任务的最后阶段文件聚合,会有一个落盘前聚合的执行计划
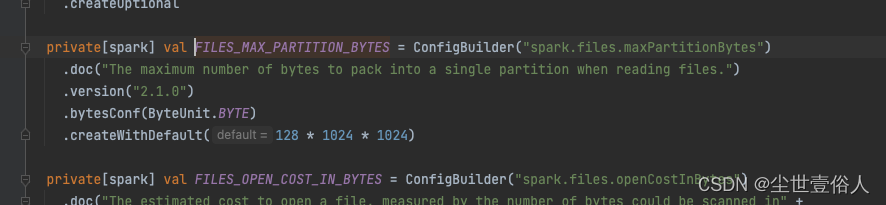
但是注意!!!上面这三个文件聚合不是Apache原生版本的参数,是kyuubi的,我写在这里是要告诉大家,开源社区对离线文件聚合这方面,只做了AQE的,其他可观测到的参数都是某个单独类库用的,比如spark.files.maxPartitionBytes这个配置其他文献会告诉你,它可以修改离线处理的分区大小,但是!!它只在BinaryFileRDD 这个RDD才用到这个参数,下面是spark源码
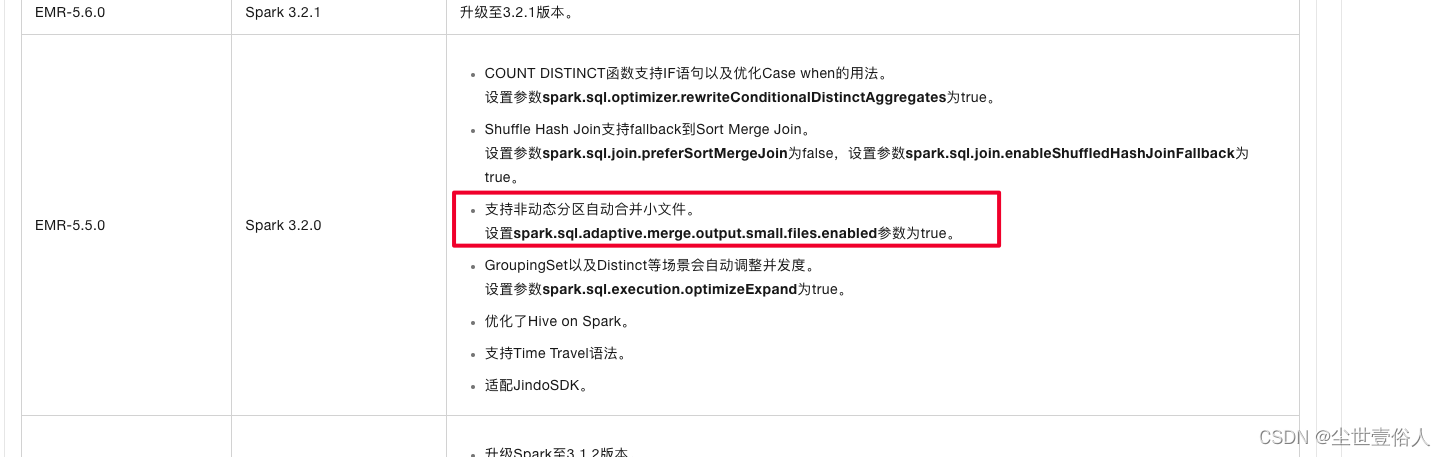
因此对于Apache原生版本来讲,处理小文件聚合的最可靠办法就是用AQE,在这一点上由于被白嫖太多,所以Apache原生团队就没继续做,但是国内大厂有自己的开发,基于已有的聚合代码做出了自己的东西,比如阿里基础架构计算引擎3.2.1升级点概要
中提到的支持非动态分区支持合并小文件
诸如此类的参数各家引擎提供商都不一样,因此如果你用的不是开源就问一下提供方是否有相关参数,同时这也更加突出了开发的重要,尤其是在这个AI满天飞的时代,很多公共的姿势资源差距被拉平了,所以大家努力共勉提升自己的技术水平还是很有必要的
4、任务最后阶段消耗资源多少,通常是配合压缩和自适应分区的相关配置来做任务优化,这两个参数同上也是kyuubi的,放在这里是想告诉大家不同版本下的spark架构有着不同的特点
spark.sql.finalWriteStage.executorMemory=10g
spark.sql.finalWriteStage.executorCores=2
5、文件压缩
mapreduce.output.fileoutputformat.compress=true #是否对任务的输出数据压缩
mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.GzipCodec #用到的压缩类
mapreduce.map.output.compress=true #是否对map阶段的输出进行压缩
mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.GzipCodec #同上
hive.exec.compress.output=true #hive端数据压缩,⭐️⭐️3.x的spark之后共用上面map的压缩策略,但是2.x的版本有一个mapred.map.output.compress.codec,使用的时候注意版本
spark.sql.parquet.compression.codec=snappy #如果表数据存储类型是parquet,那就要另行制定压缩方式,默认是snappy,可以选择gzip、lzo、或者uncompressed不压缩
6、sql任务的shuffer分为两个阶段,第一阶段叫shuffer-read,第二个阶段叫shuffer-write,使用下面的配置可以更改read阶段的并行度,但是这个配置的生效前提是其他算子在执行计划中的分区数失效了才使用它,所以大多情况下没有作用
spark.sql.shuffle.partitions=200
7、sql任务自适应分区数查询(AQE),注意同时配置了AQE的合并分区相关和倾斜时,会先合并,再调整倾斜,设计到的分区大小,建议50~300M
spark.sql.adaptive.enabled=true # 开启aqe
spark.sql.adaptive.forceApply=true #强制开启AQE,一般不带这个参数,当发现aqe的效果不明显的时候再用
spark.sql.adaptive.logLevel=info #aqe的日志级别,一般保持默认,不用改
spark.sql.adaptive.coalescePartitions.enabled=true # 自动合并分区
spark.sql.adaptive.coalescePartitions.initialPartitionNum=100 # 初始的分区数。默认为spark.sql.shuffle.partitions的值
spark.sql.adaptive.coalescePartitions.minPartitionNum=1 # 最小的分区数。默认为spark.sql.shuffle.partitions的值,一般不另行配置
spark.sql.adaptive.coalescePartitions.maxPartitionNum=1 # 最大的分区数。AQE的常用配置,一般不要太大
spark.sql.adaptive.advisoryPartitionSizeInBytes=128M # 每个分区建议大小(默认单位字节)
spark.sql.adaptive.shuffle.targetPostShuffleInputSize=128M #设置shuffer阶段后下一阶段任务输入预期的数据大小,一般不另行配置
spark.sql.adaptive.fetchShuffleBlocksInBatch=true #默认是true,当获取连续的shuffle分区时,对于同一个map的shuffle block可以批量获取,而不是一个接一个的获取,来提升io提升性能
spark.sql.adaptive.localShuffleReader.enabled=true #允许在自适应时采用本地进程优化shuffer,分险是如果报错,这部分日志无法聚合到yarn
spark.sql.adaptive.skewJoin.enabled=true # 开启join时的数据倾斜检测
spark.sql.adaptive.skewJoin.skewedPartitionFactor=5 # 默认5,当某个分区大小大于所有分区的大小中间值5倍,就打散数据
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes=256M #通过直接指定分区大小的阈值来决定是否打散分区, 默认256M,和上面的参数一起生效,用来因对不同的情况
spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin=0.2 #参与join的表非空分区对于整体任务而言占比小于该比例,那么该表不会被作为广播表去使用,默认0.2,一般不改,因为通常广播能力是禁用掉的,广播会非常耗driver的内存,尤其是在TB级数据处理中,随意广播是一个比较危险的操作
spark.sql.autoBroadcastJoinThreshold=-1 #这个配置通常保持-1,它是指给一个字节大小,小于这个字节的表都会在join操作时被广播,-1表示禁用广播能力
spark.sql.mergesmallfilesize=256M #分区建议大小 ⭐️⭐️注意这个配置在3.x之后废弃,2.x需要试一下你用的版本
对于AQE的分区数,一定要知道不是说你设置多少,web页面上就能直观的体现出来多少,执行计划上是以task的形式展示执行计划的,而task和分区是两个东西,因此你要有那种感觉,来调整分区数,这种感觉只能靠经验去喂,就和神枪手一样。
而且AQE的coalescePartitions对数据集倾斜的作用很明显,但是对join是发生的热点key倾斜就不太有力了,所以如果有join倾斜一定要开启skewJoin
8、任务容器的动态伸缩,建议一般情况下不要使用直接指定,而是尽量使用动态扩容,来规定任务的容器个数,因为直接指定时,很容易造成资源的倾斜,除非你的任务特别大,这个时候动态扩容的能力会成为累赘,至于如何判断你可以在任务启动之后spark页面的excutor页面看到实际启动了多少个容器,如果total个数和单个容器使用资源综合考虑后的结果,反馈出任务最终使用的计算资源超过了有预留后的总资源,或者该任务的shuffer无论你如何调整,它的shuffer大小都较高,甚至逼近当前集群的shuffer能力上限,这种情况就不建议用动态容器扩展了
spark.dynamicAllocation.enabled=true # 开启动态收缩容器资源默认false
spark.dynamicAllocation.shuffleTracking.enabled=true # shuffle动态跟踪,默认true
spark.dynamicAllocation.initialExecutors=10 # 初始化申请资源
spark.dynamicAllocation.maxExecutors=100 # 最大容器个数
spark.dynamicAllocation.minExecutors=10 # 最小容器个数
spark.dynamicAllocation.executorAllocationRatio=1 # 这个用来设置动态容器资源模式下,任务可尝试的最多资源占比,默认为1,本身是个浮点数值也就是0.1到~,一般不另行配置
9、是否对分区做动态裁剪,默认true,这个配置一般不关,它目的就是优化执行,开启后你可以在spark的任务web界面看到有的执行计划就被skip了,当然skip不全是因为它,容器的动态伸缩和自适应分区数也会造成。
spark.sql.optimizer.dynamicPartitionPruning.enabled=true
10、spark-sql提供了Hint,需要你去查看官方文档https://spark.apache.org/docs/3.5.2/sql-ref-syntax-qry-select-hints.html#content,看的时候注意你用的版本,这个就是在写sql的时候加入建议的执行计划,比如当你希望sql执行的时候直接指定希望的分区数,你可以写成如下的格式,但是这种方式其实就是嫌少了用户使用时的代码量,一般用的不多
SELECT /*+ COALESCE(3) */ * FROM t;
11、core任务中rdd的默认分区数,这个配置一般不直接在任务外配置,有需要的话调用算子的parallelism方法了
spark.default.parallelism=10
12、存储内存占用比例,这个配置越大留给shuffer和计算本身的内存就越少,反之越小跑任务的时候数据暂时落盘的次数就越频繁,默认值0.5
spark.memory.storageFraction=0.5
对于落盘的阈值,在整个spark中有个spark.reducer.maxReqSizeShuffleToMem参数,用来直接用数据大小来控制落盘时机,但是该参数变动很频繁,不同版本名称也不一样,所以一般不用,这里的落盘是指计算过程中随着计算任务的output输出,或者input来的数据太多,使得容器内部用来存储数据的那部分堆内存到了上限之后,数据就会被暂时写在文件里面,当恢复平衡之后会逐步再读取出来处理
13、下面22点修改kryo序列化后还可以更改使用的缓存大小,这个配置是当driver调用collect等算子回收大量数据到driver端,可能会抛buffer limit exceeded异常,这个时候就要调大该参数
spark.kryoserializer.buffer=64k
14、第13点设置的是缓存大小,这个配置设置的是driver收集数据使用的内存资源最大是多少,默认1g,0表示不限制
spark.driver.maxResultSize=1g
15、下一个数据块定位次数,在数据落盘的时候如果网络延迟等极端原因会导致driver定位数据块写入位置时,收不到任何datanode的回馈,这个时候可以尝试调大这个值,一般不会遇到,博主只遇到过一次,出现问题的时候会抛出Unable to close file because the last block does not have enough number of replicas异常,对应的bug在spark2.7.4已修复,这个配置的默认值是5,挂了就设置为6
dfs.client.block.write.locateFollowingBlock.retries=5
16、shuffle write时,会先写到BufferedOutputStream缓冲区中,然后再写到磁盘,该参数就是缓存区大小,默认32k,建议设置为64k,这个配置是数据量不较大的时候,减少一些系列化次数,和让小文件聚合异曲同工,设置的时候注意要和17平衡
spark.shuffle.file.buffer=32k
17、shuffle溢写磁盘过程中需要将数据序列化和反序列化,这个参数是一个批次处理的条数,默认是10000,需要的话调大该值,2万5万都可以,但是一定要成比例的设置16的配置值
spark.shuffle.spill.batchSize=10000
18、shuffle read拉取数据时,由于网络异常或者gc导致拉取失败,会自动重试,改参数就是配置重试次数,在数据量达到十亿、百亿级别的时候,最好调大该参数以增加稳定性,默认是3次,建议设置为10到20。
spark.shuffle.io.maxRetries=3
19、该参数是 spark.shuffle.io.maxRetries的重试间隔,默认是0.5s。
spark.shuffle.io.retryWait=500
20、shuffle read拉取数据时的缓存区大小,也就是一次拉取的数据大小,默认64,计算单位是M,要注意的它是从n个节点上,一次总共拉取64M数据,而不是从单个节点获取64M。并且它拉取数据时,并行的发送n个请求,每个请求拉取的最大长度是 64M / n,但是实际拉取时都是以block为最小单位的,所以实际获取的有可能会大于64M / n。所以这个配置就有点迷,属于理论上不行,但实际由于block大小而不得不行的配置
spark.reducer.maxSizeInFlight=64
在你对上面缓存区的大小做修改的时候,不要设置的太大,因为要考虑下面的这个配置
spark.reducer.maxReqsInFlight=Int.MaxValue
该配置用来限制每个批次拉数据时,能够发出的请求数上限,默认是scala中Int类型的最大值,一般不另行改动,但是如果你缓存区大小设置的不合理,或者碰上任务生产的中间文件普遍不大,造成spark为了靠近你设置的缓存区大小文件请求一次性发出去很多,这就会造成大量的网络IO导致任务失败,遇到这种情况,要先使用文件聚合,然后考虑AQE、最后调整任务资源,因为前面两个对资源的消耗是有一定的影响的,总之再次就是想告诉你有这种顾虑存在,至于这个上限限制一般不改
21、spark允许你限制每个reduce任务,能够对执行计划中的某个datanode上获取最多多少个数据块,不过一般遇不到改的情况,和上面缓存区面临的请求数一样是一个要知道的概念
spark.reducer.maxBlocksInFlightPerAddress=Int.MaxValue
注意:列出18-21的配置是为了引对一种极端情况,如果你的上游开发不是你,但是上游表生成了巨量的小文件,导致你的任务在执行计划中看到的情况明显具体计算参与率很低,大量的开销都耗在了拉数据和数据倾斜上,同时伴随着网络套接字断开的问题,联系上游人家不鸟你,那你只能注意文件聚合、调整任务资源、配置数据倾斜之外,在把拉取的数据批次大小放低,重试和重试间隔放大,最后就阿弥陀佛吧
22、修改系列化方式,这里的序列化是针对shuffle、广播和rdd cache的序列化方式,默认使用java的序列化方式org.apache.spark.serializer.JavaSerializer性能比较低,所以一般都使用org.apache.spark.serializer.KryoSerializer ,至于spark task的序列化由参数spark.closure.serializer配置,目前只支持JavaSerializer。
spark.serializer=org.apache.spark.serializer.KryoSerializer
23、如果你的数据类型是Parquet,且使用spark计算引擎处理hive数据,要注意这个配置,用来决定是否采用spark自己的Serde来解析Parquet文件;Spark SQL为了更好的性能,在读取hive metastore创建的parquet文件时,会采用自己Parquet Serde,而不是采用hive的Parquet Serde来序列化和反序列化,由于两者底层实现差异比较大,所以很容易造成null值和decimal精度问题,默认为true,设为false即可(会采用与hive相同的Serde)。
spark.sql.hive.convertMetastoreParquet=false
当你操作spark要对hive表的Parquet类型数据写入的时候一定要注意下面的配置。
spark.sql.parquet.writeLegacyFormat=true
这个参数用来决定是否使用hive的方式来写Parquet文件,这是由于对数据精度的把控上,两个计算框架不一样,比如decimal精度上两者的实现就有差别,导致hive读取spark创建的Parquet文件会报错,在hive中decimal类型是固定的用int32来表示,而标准的parquet规范约定,根据精度的不同会采用int32和int64来存储,而spark就是采用的标准的parquet格式,所以对于精度不同decimal的,底层的存储类型有变化,所以使用spark存储的parquet文件,在使用hive读取时报错,因此要将spark.sql.parquet.writeLegacyFormat(默认false)配置设为true,即采用与hive相同的format类来写parquet文件
24、和上面的Parquet一样,orc数据spark和hive的底层实现也不太一样,因此如果你用spark处理hive的orc数据,要注意下面的配置
spark.sql.hive.convertMetaStoreOrc=false
上面这个配置用来决定spark读取orc的时候是否转换成spark内部的Parquet格式的表,如果你的orc数据来自于hive,就要设置为false,如果为true发生兼容性问题的概率很大
orc.force.positional.evolution=true
上面这个配置决定spark读取orc时,是否强制解析orc数据,这里的强制说的是,由于orc是列式存储,在不同版本之间很容易发生字段底层存储的顺序不同,或其他不兼容问题,为true时,意味着强制解析这些数据,为数据分析提供了一定的兼容性保证。一种常见的需要强制解析场景就是,当你对orc格式的表,修改了字段名,或者增加列,并且你没有刷新数据的话,不强制解析的情况下,select出来的列名就是数据里面真实存储的字段名,也就是原来的字段名
spark.hadoop.hive.exec.orc.split.strategy=BI
上面这个配置是用来决定,spark读取orc文件时的切分策略,有三种可选值,分别为BI(文件级别)、ETL(stripe条带级别)、HYBRID(混合默认),在网上能找到的其他文献中说这个配置的默认值是BI,但本博主在使用spark3.2.1的时候遇到了一次读取orc数据报数组下标越界问题,规避了空值影响之后,发现ETL模式在参与计算的数据切片较大时不太稳定,而在spark3.2.1的源码里面在读取orc数据时数据切分用的是混合模式,因此在发生同样问题的时候,直接指定BI就行,注意这个问题如果大家遇到了,那如果上游任务数据生成时的文件切片数可以放大,让每个文件的大小缩小,也是可以解决的

hive.exec.orc.default.stripe.size=67108864
上面这个配置用来决定spark读取orc文件时混合切分策略的阈值,默认是256MB,如果你任然向使用混合模式,哪就调小至64M。 ⭐️⭐️⭐️但是要注意,这个参数在3.x之后失效了,去更改分区大小来控制
spark.sql.orc.impl=hive
上面该配置决定spark用那种方式写入orc数据,默认是native,即内置的类库,但是如果数要流向hive,就要配置成hive
hive.merge.orcfile.stripe.level=true
上面这个参数用来控制orc数据写入时进行的合并策略,为true使用stripe级别进行,而当该参数设置为false时,合并操作会在文件级别进行。这种合并操作是通过启动一个独立的map-reduce任务来实现的,旨在优化存储和提升查询效率。具体来说,ORC文件的合并有助于减少小文件的数量,从而避免因大量小文件而导致的处理效率低下问题。此外,ORC文件的索引结构(如行组级别、条带级别的索引)使得查询时能够快速定位到需要的数据块,避免了不必要的磁盘和网络I/O,进而提高了查询效率。
这种配置对于处理大量小文件特别有用,尤其是在数据仓库环境中,可以显著提升数据处理的速度和效率。通过合理地配置这个参数,可以根据具体的业务需求和数据特点,优化Hive处理ORC文件的策略,从而达到更好的性能表现。
注意:操作orc和Parquet格式时,一定要合理的带上上面的参数,否则轻则数据精度丢失,重则不可识别数据文件导致任务在读取文件阶段就失败了
25、任务重试次数,这个配置在工作中不同的开发版技术环境是不同的值,如果有需要可以更改,默认的原生栈是2
spark.yarn.maxAppAttempts=2
26、有的时候spark任务,当你不太愿意给再多的资源时候,但任务缺失由于数据太多,比如数据块拉去比较耗时之类的,会触发任务超时,这个时候你可以设置下面的两个参数,把超时时间延长,或者设置为0不预防超时
spark.network.timeout=600s #网络超时时间,默认单位毫秒,默认值10000
spark.task.timeout=100 #task任务超时时间,默认单位秒,默认值3
27、推测执行,这个配置和hive任务的推测执行一样的目的,启动另一个相同的task并行,那个先成功就用那个,另一个关闭,通常情况下为了任务的稳步运行和资源的择优,要确保是关闭的,但如果集群部分节点的状态不佳,导致任务执行缓慢等,就开启这个配置,开启后再执行任务会看到job有skip的就是一个成功后另一个暂停的表现
spark.speculation=false
28、这个参数是容器和driver的心跳机制间隔,
spark.executor.heartbeatInterval=20s #默认单位毫秒,默认值在 Spark 1.6 版本之前,默认值是 10000 ,在 1.6 及之后的版本中,默认值是 3000
29、如果你的sql要使用模糊匹配字符,涉及了字母的大小写,你可以设置下面这个参数为false,忽略大小写,这样就不需要LOWER或UPPER函数了
spark.sql.caseSensitive=false
30、在3.x之前sparksql操作数据,是不能向一个非空路径下建表并写数据的,会抛出运行异常,而3.x之后可以,但是这需要注意写入数据和已有元数据不一致的风险,通过设置下面的参数实现
spark.sql.legacy.allowNonEmptyLocationInCTAS=true
31、当select的表,路径下存在非数据文件的路径时,在数据分析的时候会报错,这个时候需要用下面的参数,让spark强制对目录递归读取
mapred.input.dir.recursive=true;
mapreduce.input.fileinputformat.input.dir.nonrecursive.ignore.subdirs=true;
mapreduce.input.fileinputformat.input.dir.recursive=true;
32、关闭sql计算时的全段代码融合能力,默认值是true,在sql计算的时候,如果你时常关注任务的web执行计划,你会发现spark的sql架构常常会将多个有关联可以并行的执行计划融合成一个阶段执行,这种能力可以优化内部算子的调用开销,但是在大任务处理的时候会发生编译错误,因此如果你的任务很大,那么最好把这个能力关掉,虽然这会影响一些任务的性能和增加一些计算开销
spark.sql.codegen.wholeStage=false
spark.sql.codegen.aggregate.map.twolevel.enabled=false
33、节点黑名单,该功能在spark2.2开始支持,这些配置通常可以被配置在spark-defaults.conf中做为默认参数存在,这是一种保障机制,当你的集群中存在某些节点状态异常,你可以配置黑名单的方式,使得调度器开始记录任务失败情况,达到一个阈值的时候尽量不再向该节点上运行task,注意是尽量!!除非达到黑名单阈值的上限,并且当你有黑名单能力需求的时候,通常会一起打开推测执行。不过要注意的是spark的节点黑名单最小的管控单位是以执行器为单位的也就是executor,这就导致很容易出现一种情况就是同一节点重启了一个executor,这种时候就会越过executor的黑名单拦截,不过spark还提供了对executor失败使得节点进入黑名单的设置
spark.blacklist.enabled
这个参数用于启用或禁用节点黑名单功能。如果启用,Spark会记录任务失败的节点,并尝试避免在这些节点上重新调度任务。默认值是false。
spark.blacklist.application.maxFailedTasksPerExecutor
这个参数定义了当前任务,单个executor上允许失败的task数量。当一个executor上失败task数量达到这个阈值时,该executor会被列入黑名单。默认值通常是2。
spark.blacklist.application.maxFailedExecutorsPerNode
这个参数定义了一个节点上允许失败的执行器数量。当一个节点上的失败执行器数量达到这个阈值时,该节点会被列入黑名单。默认值通常是2。
执行器失败一般很少发生,因为执行器的失败虽然和task失败的原因很多是一样的,但是执行器本身只是负责对task监工的进程,所以失败的概率甚少,除非是服务器本身存在故障这种硬性错误,而向OOM等这种软性错误一般不发生
------------上面这两个是当一个任务所有task执行中阈值以上的失败发生,则对应发生失败的执行器或者失败执行器所在节点进入黑名单
spark.blacklist.stage.maxFailedTasksPerExecutor
这个参数定义了一个阶段(stage)中一个执行器上允许失败的任务数量。当一个执行器在当前阶段中的失败任务数量达到这个阈值时,该执行器会被列入黑名单。默认值通常是2。
spark.blacklist.stage.maxFailedExecutorsPerNode
这个参数定义了一个阶段中一个节点上允许失败的执行器数量。当一个节点在当前阶段中的失败执行器数量达到这个阈值时,该节点会被列入黑名单。默认值通常是2。
-------------上面这两个和开头两个的区别是生效范围在一个stage中,也就是单个的taskset中
spark.blacklist.task.maxTaskAttemptsPerExecutor
这个参数定义了一个执行器上尝试执行一个task的最大次数。当一个task在一个执行器上的尝试次数达到这个阈值时仍然无法正常执行,该执行器会被列入黑名单。默认值通常是1。注意这个参数的生效前提是,设置的值小于等于执行器或节点进入黑名单的阈值,并且这个配置是指单个的task原地重试
spark.blacklist.task.maxTaskAttemptsPerNode
这个参数定义了一个节点上尝试执行一个任务的最大次数。当一个任务在一个节点上的尝试次数达到这个阈值时,该节点会被列入黑名单。默认值通常是2。这个配置和上面的spark.blacklist.task.maxTaskAttemptsPerExecutor一样都是对task原地重试,不同的是重试放在了同节点的其他执行器上,生效前提也是小于等于上面的节点配置
--------------上面这两个在正常配置的时候往往会使得进入黑名单的阈值小于开头的4个配置
spark.blacklist.timeout
这个参数定义了一个节点被列入黑名单的时间。超过这个时间后,节点会被自动移出黑名单。默认值通常是-1(表示不会自动移出黑名单)。配置的时候注意,改配置单位是小时
spark.blacklist.static.hosts=host1,host2,host3
spark.blacklist.static.executors=executor1,executor2,executor3
静态黑名单列表,这个配置指向的节点和执行器会始终在黑名单之中
34、上面提到对于分区大小、分区数在sql模块上用的是aqe去把控。但是core模块只有从新调整分区数的方法,而直接改动分区大小的方法在早起的版本中用到的是上面提到的spark.sql.mergesmallfilesize,但是在后续的版本中官方可能是觉得两个维度调整在使用上有冲突,所以将分区大小的直接控制融合在了conbiner算法中,你可以在源码中看到这个方法,使用上只需要通过修改分区数这一种方法来优化任务的执行就可以了,具体的流程可以在web的执行计划上看到,程序会经过conbiner。
总体上core模块中提供了五种不同情况下的分区个数修改方法
a、使用repartition()方法:
repartition()方法可以用于重新分区RDD,并返回一个新的RDD。
它允许用户指定新的分区数,并会触发shuffle操作来重新分配数据。
示例代码:newRDD = rdd.repartition(numPartitions),其中numPartitions是新的分区数。
b、使用coalesce()方法:
coalesce()方法也可以用于调整RDD的分区数,但它主要用于减少分区数,以减少小任务的数量和降低调度开销。
与repartition()不同,coalesce()在减少分区数时默认不会触发shuffle操作(除非设置了shuffle=true),这在处理大数据集时更为高效。
示例代码:newRDD = rdd.coalesce(numPartitions),其中numPartitions是新的分区数。
c、在读取数据时指定分区数:
当使用Spark的API(如textFile()、parquetFile()等)读取外部数据源时,可以通过可选的参数minPartitions来指定最小的分区数。
这有助于在数据读取阶段就控制RDD的分区数,以便后续处理。
d、配置Spark的默认并行度:
可以通过设置Spark配置参数spark.default.parallelism来指定默认的并行度(即RDD的分区数)。
这个参数会影响所有没有显式指定分区数的RDD操作。
示例配置:val conf = new SparkConf().setAppName("appName").setMaster("masterURL").set("spark.default.parallelism", "numPartitions")。
e、使用自定义分区器:
对于需要基于特定逻辑进行分区的场景,可以使用自定义分区器。
自定义分区器需要继承Partitioner类并实现numPartitions和getPartition方法。
使用自定义分区器可以精确地控制数据的分区方式,以满足特定的业务需求。
而至于sql模块的aqe在实际使用中会发现分区具体大小生效的优先级高于分区个数。
35、在spark3.x之后,sql模块对底层处理时间格式化的类不在使用之前的simpledateformat,因为simple它对时间数据的校验不严谨,造成数据生成会携带后缀。但类库的变动,导致用spark3.x去处理2.x的时间数据就会报错,因此spark提供了如下配置,在运行时修复此问题。但是效果不太理想最直接的方法是用substr函数截取对应位数的时间字符串数据
spark.sql.legacy.timeParserPolicy=LEGACY