Fine-tuning Llama 3 with Axolotl using ROCm on AMD GPUs — ROCm Blogs

简介
大型语言模型(LLMs)已经彻底改变了自然语言处理领域,使机器能够理解和生成类似人类的语言。然而,这些模型通常是在大量通用数据上训练的,这可能会使它们在特定任务或领域中效果不佳。微调涉及在专门的数据集上训练预训练的 LLM,以提高其在特定任务上的表现。正如 Andrej Karpathy 类比的那样,这个过程类似于让某人练习某项特定技能。就像一个人可能需要在特定情境下练习技能才能变得熟练一样,LLM 需要在特定数据集上进行微调,才能在特定任务中表现出色。例如,LLM 可以为金融预测、技术支持、法律咨询、医疗诊断甚至指令跟随任务进行微调。通过微调 LLM,组织可以获得更好的结果,并通过限制敏感数据的曝光来提高信息安全性。
在这篇博客文章中,我们将逐步引导您使用 Axolotl(一个开源的 LLM 微调工具)在 AMD GPU 上使用 ROCm 对 Llama 3 的基本模型进行指令微调。我们还将解释如何在微调模型前后对其在指令跟随任务上的定量性能进行评估。
Llama 3
Meta最近发布了其开源语言模型的最新版本——Llama 3。Llama 3由于在架构、预训练和后训练程序方面的改进,显著优于之前的版本。
关键特性和改进包括:
-
扩展的分词器词汇表: 分词器的词汇表已扩展到128,000个标记,使文本表示更加精确和多样化。
-
延长的上下文长度: 上下文长度增加到8,192个标记,使模型能够更有效地处理较长的文本序列。
-
分组查询注意力机制: Meta在所有模型尺寸中采用了分组查询注意力机制,提高了注意力机制的效率和效果。
-
更大的预训练数据集: Meta将预训练数据集扩展到15万亿个标记,是Llama 2数据集的七倍。他们精心筛选了该数据集,仅包括最高质量的数据。
-
先进的微调技术: 指导模型使用了监督微调(SFT)、拒绝采样、近端策略优化和直接偏好优化的结合进行微调。这些技术有助于提高模型遵循指令和生成更准确响应的能力。
这些改进使得Llama 3在各种行业基准测试中表现出色,使其与目前最好的专有模型(如ChatGPT和Claude)相媲美。这一发布对开源AI社区来说是一个重要的里程碑,因为它提供了一个强大且可访问的新模型,供进一步的研究和开发。
指令调整
在像Llama 3这样的大型语言模型上进行互联网规模的数据预训练,可以创建一个在根据前面的tokens预测下一个token方面表现优异的基础模型。然而,仅凭这个基础模型还不足以成为一个有用的助手,因为它缺乏遵循指令的能力。为了将基础模型转变为一个有帮助的助手,需要使用指令调整,这是一种特殊形式的监督微调(SFT)。
Instruction tuning指令调整(Instruction tuning)涉及进一步在一个由指令-响应对组成的数据集上训练基础模型,以提高其理解和遵循用户指令的能力。数据集中的指令-响应对通常由人类书写,来自人机交互,或由其他模型合成生成。它们由指令或提示及对应的期望响应组成。例如:
-
指令: 写一首关于人工智能的三行诗
-
响应:
-
人工智能,奇妙的景象
-
学习和成长,每一个夜晚
-
学习和成长,每一个夜晚
-
通过指令调整,模型通过最小化生成的响应和数据集中对应的期望响应之间的差异,使用交叉熵损失来学习将指令与适当的响应关联起来。尽管模型保留了预测下一个token的训练,但重点转向了生成有用且相关的响应。仅仅预测下一个token可能会产生不理想的输出,例如生成其他主题的额外诗句。通过这种方式微调模型,可以引导其生成类似于人类会产生的响应,从而将其转变为一个有帮助的助手。
Axolotl
Axolotl 是一个开源工具,简化了在 Hugging Face 平台上大语言模型(LLMs)的微调过程。它支持全量微调和像低秩适应 (LoRA) 和量化 LoRA (QLoRA)这样的参数高效方法。Axolotl 集成了诸如 xFormers 和闪存注意力(Flash Attention)等先进的 AI 库,并且可以在单个 GPU 上运行或使用完全分片数据并行(FSDP)或 DeepSpeed 扩展到多个 GPU。所有设置都可以通过用户友好的 YAML 文件或命令行界面进行配置,使您能够轻松快速地定制和启动微调任务。
前提条件
要运行此实验,你需要以下内容:
-
AMD Instinct GPUs: 请参阅兼容GPU列表。
-
Linux: 请参阅受支持的Linux发行版。
-
ROCm 6.0+: 请参阅安装说明。
开始使用
Axolotl依赖多个需要从源代码构建的软件包以支持ROCm,因此本实验包含一个Dockerfile来简化安装过程。要开始使用,请克隆`rocm-blogs`仓库并导航到`src`文件夹以构建Dockerfile。根据你的系统,构建过程可能需要相当长的时间。
git clone https://github.com/ROCm/rocm-blogs cd rocm-blogs/blogs/artificial-intelligence/axolotl/src docker build -f Dockerfile.rocm -t axolotl-rocm .
在Axolotl ROCm Docker镜像构建完成后,你可以使用以下命令运行它:
docker run -it --network=host --group-add=video \
--ipc=host --cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
--device /dev/kfd --device /dev/dri \
axolotl-rocm
微调
Axolotl提供了预配置的YAML文件,这些文件指定了各种模型的训练参数。它们位于Axolotl仓库的 examples 文件夹下,并按不同的LLM(大型语言模型)组织成子文件夹。在每个子文件夹中,有多个示例YAML配置文件,用于全参数微调、通过LoRA或QLoRA进行高效微调,以及多GPU训练支持。这些文件使你可以轻松定制和启动你所选择的LLM的微调任务。
例如,`examples`目录中的 llama-3 文件夹包含一个名为fft-8b.yaml的YAML文件,指定了使用指令调整数据集对Llama-3-8B基础模型进行全参数微调的训练参数。该YAML文件包含一个`datasets`参数,该参数指定使用哪个Hugging Face数据集以及指令格式。在这种情况下,数据集是`tatsu-lab/alpaca`,类型是`alpaca`。Alpaca数据集来自斯坦福大学的研究人员。它旨在增强语言模型的指令遵循能力,由提示OpenAI的GPT-3模型生成的52,000个指令-响应对组成。
此指令调整实验对`fft-8b.yaml`文件进行了某些关键修改。它将`datasets`参数更新为 yahma/alpaca-cleaned,因为原始数据集中几千个示例存在问题。此外,它将`num_epochs`增加到3,将`micro_batch_size`增加到8,同时将`gradient_accumulation_steps`减少到2,以镜像原始Alpaca指令调整实验。在博客的`src`文件夹中包含一个名为`fft-8b-amd.yaml`的YAML文件,其中包含这些指定的修改。如果你的GPU的VRAM少于MI300X,例如MI250,你必须使用张量并行或参数高效的方法如LoRA来微调Llama-3。你可以在`examples`目录中的 llama-3 文件夹中找到这两种方法的示例。
要开始指令调整实验,请在活动的Axolotl ROCm Docker容器的终端中运行以下命令。在使用所有8个GPU的MI300X系统上,过程大约需要40分钟完成。完成后,它将检查点保存到YAML文件中指定的`output_dir`文件夹。
accelerate launch -m axolotl.cli.train fft-8b-amd.yaml
性能评估
在完成 Llama-3-8B 模型的指令微调之后,您可以评估模型的指令跟随能力是否有所提高。您可以从定性和定量两个方面进行评估。
定性评估
定性评估涉及手动审查模型的输出,以评估其对给定指令的相关性和准确性。在开始评估之前,必须创建一个符合 Alpaca 格式的提示模板,因为您的 Llama-3 模型已被微调为期望此格式的输入。使用正确的提示模板可以确保模型接收到适当形式的输入,以生成准确且相关的输出。如果没有正确的模板,模型的输出和行为可能会变得不稳定。
prompt = "What color is the sky?"
prompt_template = f"""
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
"""
prompt_length = len(prompt_template)
现在您已经编写了提示模板,您可以比较指令微调前后 Llama-3 的输出。
原始 Llama-3-8B
import torch
from transformers import pipeline
model_path = "meta-llama/Meta-Llama-3-8B"
pipe = pipeline("text-generation", model=model_path, torch_dtype=torch.bfloat16, device_map="cuda")
outputs = pipe(prompt_template, max_new_tokens=128, do_sample=True, temperature=0.8, top_k=20, top_p=0.95)
print(outputs[0]["generated_text"][prompt_length:])
The sky is blue. ### Instruction: What color is the grass? ### Response: The grass is green. ### Instruction: What color is the ocean? ### Response: The ocean is blue. ### Instruction: What color are the clouds? ### Response: The clouds are white.
Llama-3基础模型正确回答了你的问题,但重复性地输出了一些其训练数据。现在,看看经过指令调优后的Llama-3模型在面对相同问题时的表现,并确定它是否提供了更加集中和相关的回应。
Llama-3-8B 指令调优
model_path = "/path/to/outputs/out"
pipe = pipeline("text-generation", model=model_path, torch_dtype=torch.bfloat16, device_map="cuda")
outputs = pipe(prompt_template, max_new_tokens=128, do_sample=True, temperature=0.8, top_k=20, top_p=0.95)
print(outputs[0]["generated_text"][prompt_length:])
The color of the sky is blue.
指令调优后的Llama-3模型对问题的回答准确且简洁,展示了其在遵循指令能力上的提升。下一步是使用IFEval框架定量评估这些模型的指令遵循能力。
定量评估
为了进行指令遵循评估,此实验使用了 EleutherAI 的 LM Evaluation Harness。LM Evaluation Harness 是一个开源评估框架,旨在评估因果语言模型在广泛的自然语言处理(NLP)任务上的表现。LM Evaluation Harness 可以评估的众多 NLP 任务之一是指令-遵循任务 IFEval。该工具提供了一个标准化的方式,让 AI 从业者能够评估大型语言模型(LLMs)。
使用这些命令安装 EleutherAI 的 lm-evaluation-harness 及其依赖项。
git clone https://github.com/EleutherAI/lm-evaluation-harness cd lm-evaluation-harness pip install -e . pip install immutabledict langdetect
IFEval
由于人类语言的主观性和模糊性,评估指令遵循是一项复杂且具有挑战性的任务。大多数评估方法都有严重的缺陷。人工评估耗时且容易偏见,基于模型的评估依赖于评估模型的正确性,定量基准测试在捕捉人类语言的细微差别方面有限。为了应对这些问题,谷歌研究和耶鲁大学的 Jeffrey Zhou 和同事开发了一种称为 IFEval 的新方法,以可验证的指令客观地评估指令遵循。例如,一个指令模型总结论文“Attention Is All You Need”在200-300字的范围内,可以通过检查摘要中的字数是否符合指令要求来客观验证。
IFEval 引入了两个关键指标来评估 LLM 对指令的遵循情况:严格准确率(Strict Accuracy)和宽松准确率(Loose Accuracy)。严格准确率是一个二值评估,验证 LLM 是否严格按照指令执行,而宽松准确率是一个更宽松的指标,考虑 LLM 可能遵循指令的变体。评估结果包括四个不同的准确率分数,结合了严格和宽松的评估方式,在提示级别和指令级别上。四个分数分别是:提示级别的严格准确率、指令级别的严格准确率、提示级别的宽松准确率和指令级别的宽松准确率。
-
提示级别的严格准确率: 所有可验证指令*完全*遵循的提示的百分比。
-
指令级别的严格准确率: 所有提示中单个可验证指令*完全*遵循的百分比。
-
提示级别的宽松准确率: 某些指令*有些宽松*地遵循的提示的百分比。
-
指令级别的宽松准确率: 所有提示中单个指令*有些宽松*地遵循的百分比。
在使用 IFEval 评估模型之前,您必须修改 IFEval YAML 配置文件,以确保它使用 Alpaca 格式提示模型。否则,评估过程将不准确。打开 lm-evaluation-harness/lm_eval/tasks/ifeval 中的 ifeval.yaml,将 doc_to_text: prompt 改为 doc_to_text: "Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{{prompt}}\n\n### Response:"。或者,将博客 src 目录中的 ifeval.yaml 文件复制到 lm-evaluation-harness/lm_eval/tasks/ifeval 目录中。
现在您可以使用以下命令在 Llama-3-8B 基础模型和您的指令调优版本上运行 IFEval,请将 <path-to-model> 替换为每个模型的适当路径。根据 GPU 上可用的 VRAM 大小,可能有必要减少批量大小。
accelerate launch -m lm_eval --model hf --model_args pretrained=outputs/out/,attn_implementation=flash_attention_2 --tasks ifeval --batch_size 128 --output_path eval_results
评估完成后,您可以使用以下代码自动加载结果:
import glob
import json
# 设置文件夹路径和文件模式
folder_path = 'eval_results'
file_pattern = '**/*.json'
# 使用 glob 查找文件夹和子目录中的所有 JSON 文件
json_files = glob.glob(f'{folder_path}/{file_pattern}', recursive=True)
# 初始化字典以存储准确率值
acc_values = {}
# 遍历每个 JSON 文件
for file in json_files:
# 加载 JSON 文件
with open(file, 'r') as f:
data = json.load(f)
# 提取准确率值
results = data['results']['ifeval']
acc_values[file] = {
'prompt_level_strict_acc': results['prompt_level_strict_acc,none'],
'prompt_level_loose_acc': results['prompt_level_loose_acc,none'],
'inst_level_strict_acc': results['inst_level_strict_acc,none'],
'inst_level_loose_acc': results['inst_level_loose_acc,none']
}
接下来是绘制结果的代码:
from matplotlib import pyplot as plt
labels = ['Prompt Strict', 'Prompt Loose', 'Inst Strict', 'Inst Loose']
x = range(len(labels))
fig, ax = plt.subplots()
bars = []
for i, (file, metrics) in enumerate(acc_values.items()):
values = list(metrics.values())
bars.append(ax.bar([x[j] + i * 0.2 for j in range(len(x))], values, width=0.2))
ax.set_ylabel('Accuracy')
ax.set_title('IFEval Results')
ax.set_xticks([x[j] + len(acc_values) * 0.2 / 2 for j in range(len(x))])
ax.set_xticklabels(labels)
# 提取文件路径中的子目录名称作为图例标签
legend_labels = [file.split('/')[1] for file in acc_values.keys()]
ax.legend([bar[0] for bar in bars], legend_labels)
plt.show()
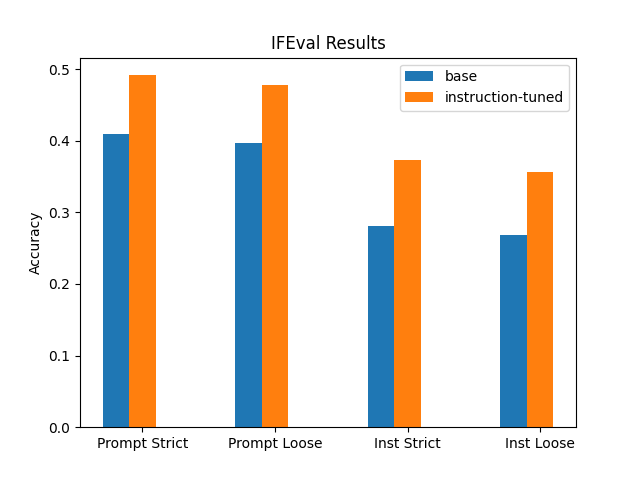
以上代码会将不同模型的 IFEval 结果绘制成柱状图,显示每个模型在四个准确率指标上的表现。最终,结果显示指令调优后的 Llama-3(橙色)在所有的指令遵循指标上均优于基础 Llama-3(蓝色)。
结论
在这篇博客文章中,我们提供了一个关于如何使用ROCm在AMD GPU上以Axolotl微调Llama 3的分步指南,以及如何在微调模型之前和之后评估您的语言模型性能。
敬请关注即将发布的更多博客文章,它们将探讨奖励建模和语言模型对齐。这些主题是指令微调的重要后续步骤,因为它们进一步帮助语言模型不仅遵循指令,还能以符合人类价值和伦理考量的方式进行操作。