爬取京东商城上的食品评论:王小卤

废话不多说直接开始

打开并登录京东商城:京东,在主页面搜索“王小卤”,点击第一个商品,查看商品评价,选择“只看当前商品评价”。

1、按F12跳出开发者工具;
2、点击Network;
3、刷新网址;刷新之后可以看到在左侧的Name里面会出现很多信息
4、点击Preview
找到评论数据,如下图

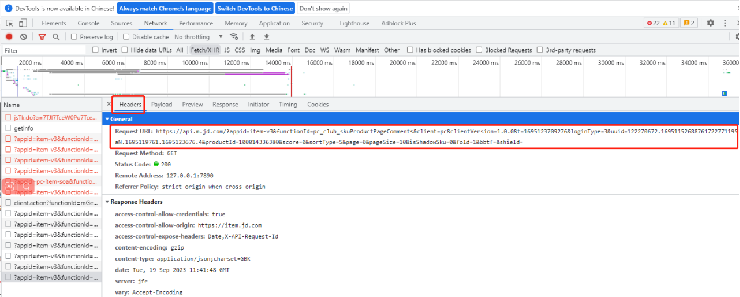
将url和user-agent分别填入请求网址和请求头中
url = 'https://api.m.jd.com/?appid=item-v3&functionId=pc_club_skuProductPageComments&client=pc&clientVersion=1.0.0&t=1696496033135&loginType=3&uuid=122270672.16964955125501525477821.1696495513.1696495513.1696495707.2&productId=100014336380&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1&bbtf=&shield='
time.sleep(1) # 防止操作过快,网站防爬
# 请求头
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
}
# 发送请求
response = requests.get(url=url, headers=headers)接着查看网络请求的响应信息,找到关键字

#评论的ID和内容
comments = re.findall(r'"content":"(.*?)",', response.content.decode('gbk'))
names = re.findall(r'"nickname":"(.*?)",', response.content.decode('gbk'))
抓取10页
for page in range(10): # 爬取10页评论数据修改请求网址中page的值:

写入Excel表,结果如下图所示:

完整代码
import requests
import re
import time
import openpyxl
comments_list = []
names_list = []
for page in range(10): # 爬取10页评论数据
# 请求网址
url = 'https://api.m.jd.com/?appid=item-v3&functionId=pc_club_skuProductPageComments&client=pc&clientVersion=1.0.0&t=1696496033135&loginType=3&uuid=122270672.16964955125501525477821.1696495513.1696495513.1696495707.2&productId=100014336380&score=0&sortType=5&page='+str(page)+'&pageSize=10&isShadowSku=0&fold=1&bbtf=&shield='
time.sleep(1) # 防止操作过快,网站防爬
# 请求头
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
}
# 发送请求
response = requests.get(url=url, headers=headers)
# 解决网页数据乱码
response.encoding = 'gbk'
#评论的ID和内容
comments = re.findall(r'"content":"(.*?)",', response.content.decode('gbk'))
for comment in comments:
comments_list.append(comment)
names = re.findall(r'"nickname":"(.*?)",', response.content.decode('gbk'))
for name in names:
names_list.append(name)
print(comments_list)
print(names_list)
workbook=openpyxl.Workbook()
sheet=workbook.active
sheet['A1']='ID'
sheet['B1']='评论内容'
for i, value in enumerate(names_list, start=2):
sheet.cell(row=i, column=1).value=value
for i, value in enumerate(comments_list, start=2):
sheet.cell(row=i, column=2).value=value
workbook.save('王小卤.xlsx')喜欢的话点个赞再走吧~~~