1 RCACHE框架介绍
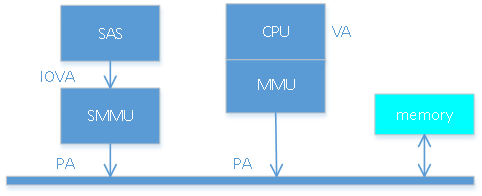
对于设备,其访问的地址称为IOVA(也称DMA地址),经过SMMU转换才是物理地址PA。IOVA的生成和释放是影响性能的重要一环。在进行一次转换时,首先会分配IOVA,然后将IOVA及对应的PA进行映射,这样CPU侧想要操作PA对应的数据时使用VA,而设备若访问对应的PA的数据时使用IOVA;在设备不需要使用数据时,取消IOVA和PA对应的映射。
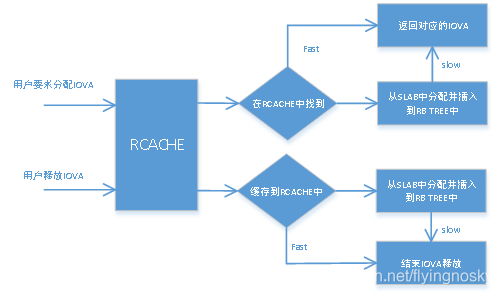
IOVA的真正分配是通过在SLAB中分配结构体[],并在IOVA所在范围里找到一个对齐于2^n * 4K大小的范围, 并加入到IOVA的红黑树RB TREE中; IOVA的真正释放是将该IOVA从IOVA的红黑树RB TREE中取出,并释放对应的结构体。可以看到,既需要在红黑树中频繁的查找/添加/删除,又需要不断的进行SLAB分配和释放。为了提升性能,采用***RCACHE机制***进行IOVA的分配和释放。
RCACHE机制如下:在申请分配IOVA时,首先从RCACHE中查找对应的大小的IOVA,若存在,直接返回使用; 若不存在,才真正去分配IOVA,并将其放入RB TREE中; 在释放IOVA时,首先尝试在RCACHE中查找是否存在对应大小IOVA的空闲位置,若存在,将要释放的IOVA放于RCACHE中缓存,若不存在,才去真正释放,同时将IOVA从RB TREE中删除。
IOVA的范围由函数iommu_dma_init_domain()决定,可通过ACPI指定,但不能为0,默认在48BIT系统中为[1 2^48-1]。
2 RCACHE相关的结构体
与RCACHE相关的结构体如下图所示:

其中iova_domain表示一个IOVA的地址空间,其中rb_root指向当前所使用的IOVA(包括缓存)的红黑树,rcaches结构体指向RCACHE所支持的缓存大小,目前支持4K/8K/.../128K。每个缓存大小又分为percpu的缓存和共享的缓存,percpu缓存有两个loaded和prev,每个链最多支持128个IOVA; 共享缓存有32组,每组包括128个IOVA。
3 IOVA分配和释放
IOVA的分配如下所示:
- 若IOVA的大小超过128K,需要真正分配IOVA,走步骤(3),否则走步骤(2);
- 根据IOVA的大小找到对应的RCACHE结点,首先检查percpu中loaded链是否存在可用的IOVA缓存,若存在返回使用,否则检查prev链是否存在可用的IOVA缓存,若存在返回使用,并交换loaded链和prev链,否则(loaded链和prev链都为空)检查depot[]是否存在空闲,若存在,将depot[]与loaded交换,并从中取空闲IOVA项,否则(loaded/prev/depot都为空)走步骤(3)真正分配IOVA;
- 从SLAB中分配IOVA,在RB TREE中查找合适的位置,赋值给IOVA,并将其插入到RB TREE中;
IOVA的释放如下所示:
- 若需要释放的IOVA超过128K,需要真正释放IOVA,走步骤(3),否则走步骤(2);
- 根据IOVA的大小找到对应的RCACHE结点,首先检查percpu中loaded链是否已满,若未满则将其放对应的缓存中,否则检查percpu中的prev链是否已满,若未满则放到对应链中缓存中,否则(loaded和prev链已满)检查共享缓存depot[]是否已满,若未满则放到depot[]中,否则(loaded/prev/depot都满)分配新的iova magazine,将原来的loaded释放,将新的iova magazine赋给loaded,从loaded找到空闲位置放置缓存;
- 在RB TREE中找到对应的IOVA,将其从RB TREE中删除,并释放IOVA;
4 IOVA框架存在问题
当前IOVA框架存在问题如下:
- 最大IOVA大小为128K,超过此大小就会真正分配和释放;
- 在缓存满时,会持续分配/释放IOVA,刷新缓存机制不完善;
- 当缓存满时,RB TREE过大,导致对RB TREE的操作比较花时间;