翻译自原论文《Multi-Interest Network with Dynamic Routing for Recommendation at Tmall》
1 介绍
天猫是中国最大的B2C电子商务平台,为数以十亿的用户提供数以十亿记的商品。2018的天猫双十一购物节,GMV达到2130亿元,相比2017年增长了26.9%。随着用户数量和商品数量的持续增长,为每一位用户找到感兴趣的商品变得越来越重要。天猫近些年在个性化推荐系统(RS)上有很大的投入,显著的提升了用户体验和商业价值。比如下图中,占天猫流量来源的一半的天猫APP首页,已经用个性化系统为每位用户展示个性化的产品。

由于天猫的用户数和商品数都很庞大,十亿量级的规模,所以天猫的推荐流程分为两个阶段:匹配(matching)和排序(ranking)。匹配阶段负责从大量的商品里获取几千个与用户兴趣点相关的备选商品。排序阶段负责预测每个备选商品被用户感兴趣的概率。因此,建模和表示用户的兴趣至关重要。然而,建模天猫用户的兴趣是不太容易的,因为用户兴趣的多样性。是以亿计的用户访问天猫,每个用户每天交互的商品成百上千。这些商品又分为不同的种类,暗示着用户的不同的兴趣点。如上图右边所示,同一个用户可能会对不同类型的商品感兴趣。因此,建模用户的不同兴趣点的能力对天猫的推荐系统来说至关重要。
现存的算法用了各种不同的方式建模和表示用户的兴趣。基于协同过滤的算法使用用户的历史物品[17]或则隐隐子[22]表示用户的兴趣,这样会有数据稀疏问题,或则计算量过大的问题。基于深度学习的算法通常用一个固定长度的embedding向量表示用户的兴趣。例如Youtube的基于神经网络的视频推荐算法,用一个固定长度的向量表示一个用户。单个embedding向量可能会成为多兴趣点表示的瓶颈,因为为了表示天猫用户的大量兴趣点,向量的纬度必须足够大。深度兴趣网络(DIN)[31]引入的注意力机制,来捕获用户的不同兴趣点。但是注意力机制的引入导致计算量的增加,使得此模型只适用于排序阶段。
本文中我们主要关注匹配阶段的多兴趣点建模问题。为了克服现存算法的限制,我们提出了动态路由多兴趣点网络(MIND)模型,在工业级推荐系统的匹配阶段,学习反应用户多兴趣点的。为了学习表示用户的向量,我们设计了一个全新的称为多兴趣抽取层的网络层,它采用动态路由算法[21]自适应的将用户的历史行为聚合成用户表示。动态路由的过程可以看成一种软聚类的过程,将用户的历史行为聚合成若干簇。每一簇的历史行为接下来用于推断用户某个特定兴趣点对应的用户表示向量。用户的表示向量只计算一次,用于推荐的匹配阶段从大量的商品中召回相关的商品。总而言之,本文的只要贡献有:
- 设计了多兴趣点抽取网络,采用动态路由算法聚合用户的历史行为,产生多个用户表示向量
- 在多兴趣点抽取网络层和标签感知注意力网络层基础上,我们设计一个用于个性化推荐的深度神经网络。对比现存的模型,MIND在多个公开数据集和一个天猫的数据集上,极大的提高了性能。
- 我们构建了一整套数据处理管道,包括数据收集,模型训练和在线服务,极大的提高了天猫APP首页的点击率(CTR)
2 相关工作
深度学习推荐模型:深度学习在计算机视觉和NLP领域取得了很大的成功,受此启发,很多工作投入到开发基于深度学习的推荐算法[3]。神经协同过滤(NCF)[11]、DeepFM[9]、深度举证分解模型(DMF)设计了由若个MLP组成的神经网络,建模用户与物品间的交互。[23]提出了一种topN推荐的系统。
用户表示:用向量表示用户的方法在推荐系统里广泛使用。传统模型使用有历史感兴趣的物品[4,12,22],关键字[5,8]和topic[29]构成的向量表示用户。随着分布式表示学习算法的兴起,通过神经网络获取的用户embedding得到广泛的使用。[6]采用RNN-GRU从用户时序有序的阅读文章中学习用户的embedding.[30]从词embedding向量中学习用户embedding,并用于推荐学术类微博。[2]提出了一种卷积神经网络,结合语音中提出的特征,学习和利用用户embedding.
胶囊网络:胶囊Hinton[13]2011年提出,采用动态路由算法[21]学习胶囊间的连接权重。在采用EM算法[14]后克服了一些缺陷,并且达到了更好的准确率。SegsCaps[18]证明胶囊相遇传统卷积网络能更好的建模物体间的空间关系。[28]将胶囊用于文本分类,并对提升性能提出了2个策略。
3 方法
3.1 问题
推荐系统匹配阶段的目标,是从数以亿计的物品池 I I I里面为每个用户 u ∈ U u\in U u∈U获取一个大小为几千的物品子集合,集合内的每个物品都与用户的兴趣相关。为了实现目标,推荐系统收集历史数据依构建匹配模型。具体来说,每个实力可以表示为一个三元组 ( I u , P u , F i ) (I_u,P_u,F_i) (Iu,Pu,Fi),其中 I u I_u Iu表示用户u交互过的物品集合(也被称为用户行为)。 P u P_u Pu表示基本画像(比如年纪,性别等), F i F_i Fi表示目标物品的特征(比如物品id,类别ID)。
MIND的核心任务是学习到一个函数,将原始的特征映射成用户表示向量,如下:
V u = f u s e r ( I u , P u ) V_u=f_{user}(I_u,P_u) Vu=fuser(Iu,Pu)
其中 V u = ( v → u 1 , . . . , v → u K ) ∈ R d x K V_u=(\overrightarrow v_u^1,...,\overrightarrow v_u^K)\in R^{dxK} Vu=(vu1,...,vuK)∈RdxK表示用户u的表示向量。K表示向量的个数,如果K=1,则每个用户只有一个表示向量,比如Youtube的DNN.目标物品 i i i的表示向量通过下面的embedding函数获取:
e → i = f i t e m ( F i ) \overrightarrow e_i=f_{item}(F_i) ei=fitem(Fi)
其中 e → i ∈ R d x 1 \overrightarrow e_i\in R^{dx1} ei∈Rdx1表示物品i的表示向量。
当用户表示向量与物品表示向量都已经得到后,top N备选物品的获取方式是通过计算下面的得分函数:
f s c o r e ( V u , e → i ) = m a x 1 ≤ k ≤ K e → i v → u k f_{score}(V_u,\overrightarrow e_i)=max_{1\le k\le K}\overrightarrow e_i\overrightarrow v_u^k fscore(Vu,ei)=max1≤k≤Keivuk
3.2 Embedding 和 Polling 层
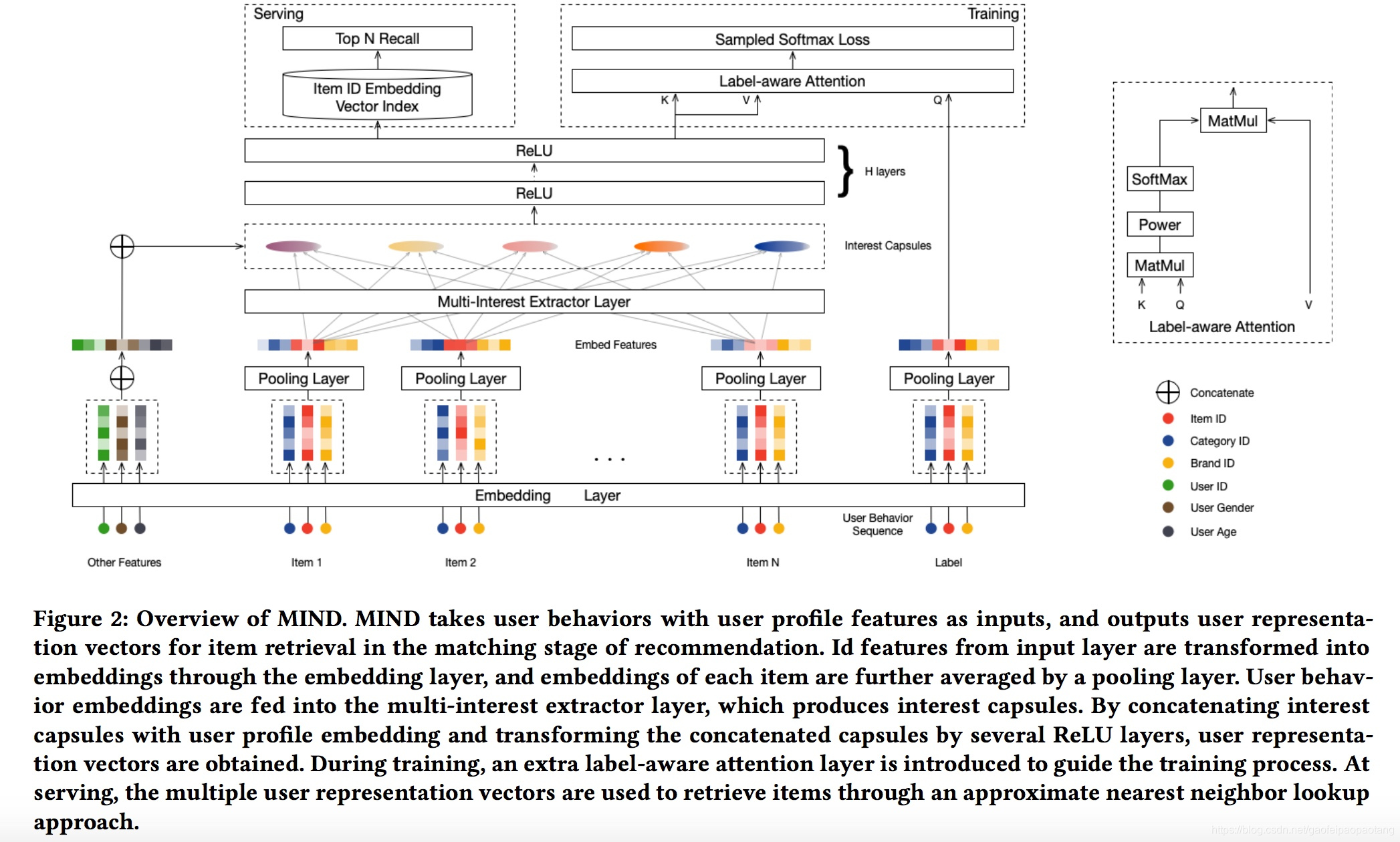
入上图所示,MIND的输入与三个部分组成:用户画像 P u P_u Pu,用户行为 I u I_u Iu,标记物品 F i F_i Fi。每部分包含若干个ID形式的特征,一般这些ID的one hot编码之后的纬度会很高。比如物品ID,one hot之后纬度是十亿级别。所以我们采用广泛被使用的embedding技术,将ID特征嵌入到低纬度的稠密矩阵中,极大的减少了模型的参数。对于画像中的ID特征(性别,年龄等),对应的embedding向量连接之后组成用户画像向量 p → u \overrightarrow p_u pu。对于标记物品ID特征,对应的embedding向量通过一个平均pooling层之后,产生标记物品向量 e → i \overrightarrow e_i ei。最后,用户行为集合 I u I_u Iu对应的embedding组成用户行为embedding向量 E u = { e → j , j ∈ I u } E_u=\{\overrightarrow e_j, j\in I_u\} Eu={ej,j∈Iu}
3.3 多兴趣点抽取层
我们说明了为什么用一个向量表示用户多个兴趣点的可能会是一个性能的瓶颈,因为需要将多兴趣点的所有信息都压缩到一个向量内。所有的信息都混合到一起,导致匹配阶段返回不正确的物品。相反,我们采用多个向量来表达用户的多个兴趣点。
为了学习多个表示向量,我们采用聚类过程将用户的多个历史行为聚类成若干个簇。期望每一个簇内的物品比较相似,共同表达用户兴趣点的某一个方面。因为多兴趣点提取网络的设计灵感来自于近期动态路由算法在表示学习方面的应用[13,14,21],首先我们回忆一下相关的基础知识。
3.3.1 动态路由算法:我们简单介绍一下胶囊的动态路由算法。假设我们有两层胶囊,后面同意称他们为低层胶囊和高层胶囊。动态路由算法的目标是通过迭代计算,由低层胶囊的输出值计算高层胶囊的输出值。每次迭代计算中,给定低层胶囊的输出值 c → i l ∈ R N l x 1 , i ∈ { 1 , . . . , m } \overrightarrow c_i^l\in R^{N_lx1},i\in\{1,...,m\} cil∈RNlx1,i∈{1,...,m}和高层胶囊的输出值 c → j h ∈ R N h x 1 , j ∈ { 1 , . . . , n } \overrightarrow c_j^h\in R^{N_hx1},j\in\{1,...,n\} cjh∈RNhx1,j∈{1,...,n},路由参数 b i j b_ij bij的计算方式为:
b i j = ( c → j h ) T S i j c → i l b_{ij}=(\overrightarrow c_j^h)^TS_{ij}\overrightarrow c_i^l bij=(cjh)TSijcil
其中 S i j ∈ R N h x N l S_{ij}\in R^{N_hxN_l} Sij∈RNhxNl表示双线性映射举证,属于待学习的参数。
路由参数计算完成之后,计算高层胶囊 j j j的候选向量:
z → j h = ∑ i = 1 m w i j S i j c → i l \overrightarrow z_j^h=\sum_{i=1}^mw_{ij}S_{ij}\overrightarrow c_i^l zjh=i=1∑mwijSijcil
其中
w
i
j
w_{ij}
wij计算方法如下:
w
i
j
=
e
x
p
b
i
j
∑
k
=
1
m
e
x
p
b
i
k
w_{ij}=\frac{exp b_{ij}}{\sum_{k=1}^mexpb_{ik}}
wij=∑k=1mexpbikexpbij
最后,计算高层胶囊的输出:
c → j h = s q u a s h ( z → j h ) = ∣ ∣ z → j h ∣ ∣ 2 1 + ∣ ∣ z → j h ∣ ∣ 2 z → j h ∣ ∣ z → j h ∣ ∣ \overrightarrow c_j^h=squash(\overrightarrow z_j^h)=\frac{||\overrightarrow z_j^h||^2}{1+||\overrightarrow z_j^h||^2}\frac{\overrightarrow z_j^h}{||\overrightarrow z_j^h||} cjh=squash(zjh)=1+∣∣zjh∣∣2∣∣zjh∣∣2∣∣zjh∣∣zjh
b i j b_{ij} bij初始化为0,通常迭代计算3次。计算完成之后,高层胶囊的使出KaTeX parse error: Expected 'EOF', got '\overrigihtarrow' at position 1: \̲o̲v̲e̲r̲r̲i̲g̲i̲h̲t̲a̲r̲r̲o̲w̲ ̲c_j^h固定不变,作为后续网络层的输入。
3.3.2 B2I动态路由:简单来说,胶囊是一种新类型的神经元,用一个向量表示,而不是标量表示的传统神经元。基于向量的胶囊可以表示实体的多个属性,胶囊的方向表示一个特征,模表示特征存在的概率。对应的,多兴趣点抽取层的目标是学习到一组向量,表示用户的多兴趣点已经对应的兴趣点是否存在。胶囊与兴趣表示之间的关联,激发我们将行为/兴趣表示作为胶囊看待。但是处理图片数据的原始的动态路由算法不适合直接用于处理用户行为数据。所以我们设计了Behavior-to-Interest(B2I)动态路的算法,主要区别在在于一下三点.
- 共享双向映射矩阵:
b i j = u → j T S e → i , i ∈ I u , j ∈ { 1 , . . . , K } b_{ij}=\overrightarrow u_j^TS\overrightarrow e_i,i\in I_u,j\in\{1,...,K\} bij=ujTSei,i∈Iu,j∈{1,...,K}
-
随机初始化路由参数:
-
动态兴趣点数:用户的兴趣点数可能不懂他,我们引入了一个启发式规则,自适应的挑战K的数值:
K ′ = m a x ( 1 , m i n ( K , l o g 2 ( ∣ I u ∣ ) ) ) K'=max(1,min(K,log_2(|I_u|))) K′=max(1,min(K,log2(∣Iu∣)))
3.4 标签感知注意力层
通过多兴趣抽取层之后,由用户行为embedding生成了若干个兴趣胶囊。每个兴趣胶囊表示用户兴趣的不同方面,相关的兴趣胶囊用户评价用户在特定物品上的兴趣。因此,训练期间,我们设计了一种标签感知注意力层。具体来说,就是对于某个具体的目标物品,我们计算物品embedding与行胶囊间的匹配程度,对胶囊进行加权求和,得到的求和值作为在目标物品上用户的表示向量:
v
→
u
=
A
t
t
e
n
t
i
o
n
(
e
→
i
,
V
u
,
V
u
)
\overrightarrow v_u=Attention(\overrightarrow e_i,V_u,V_u)
vu=Attention(ei,Vu,Vu)
=
V
u
s
o
f
t
m
a
x
(
p
o
w
(
V
u
T
e
→
i
,
p
)
)
=V_usoftmax(pow(V_u^T\overrightarrow e_i,p))
=Vusoftmax(pow(VuTei,p))
其中 p p p属于超参,当 p p p趋近于0的时候,对各个兴趣胶囊的注意力趋向于相等。当 p p p趋向与变大的时候,注意力机制趋向于选择注意力最大的胶囊而忽略其他胶囊。实验中我们发现使用较大的 p p p值训练收敛的更快。
3.5 训练与服务
当用户向量 v → u \overrightarrow v_u vu和标记物品向量 e → i \overrightarrow e_i ei计算完成之后,我们计算用户u与标记样本i的交互概率:
P r ( i ∣ u ) = P r ( e → i ∣ v → u ) = e x p ( v → u t e → i ) ∑ j ∈ I e x p ( v → u t e → j ) Pr(i|u)=Pr(\overrightarrow e_i|\overrightarrow v_u)=\frac{exp(\overrightarrow v_u^t\overrightarrow e_i)}{\sum_{j\in I}exp(\overrightarrow v_u^t\overrightarrow e_j)} Pr(i∣u)=Pr(ei∣vu)=∑j∈Iexp(vutej)exp(vutei)
然后,训练MIND的整体目标函数为:
L = ∑ ( u , i ) ∈ D l o g P r ( i ∣ u ) L=\sum_{(u,i)\in D}logPr(i|u) L=(u,i)∈D∑logPr(i∣u)
其中D是包含用户-物品交互的训练数据。因为物品的量级是十亿级别,以上公式中的归一化部分计算量过于庞大,因此我们采用采样softmax技术[7]使得目标函数可跟踪,并使用Adam优化器[16]训练MIND.
训练完成之后,除了标记感知注意力层,其他网络可以作为用户表达映射函数 f u s e r f_{user} fuser. serving的时候,用户的行为序列和用户画像输入函数 f u s e r f_{user} fuser,产生多个用户表示向量。然后使用这些向量通过近似最近邻居[15]方式获取top N物品。与用户表示向量相似度最高的被匹配上,组成匹配阶段生成的候选集合。需要注意的是,当用户产生了新的行为,他的行为集合 I u I_u Iu会发生变化,进而产生的用户向量表达也会发生变化。因此MIND可以用于实时的个性化推荐。
3.6 与已有模型的比较
这节我们分析一下MIND与其他两种模型的相同点和区别。
Youtube DNN:两种算法都采用深度神经网络从行为数据中建模产生用户表示向量,都用于推荐系统的匹配阶段。区别在于Youtube DNN采用一个向量,而MIND采用多个向量。当MIND的K取1时,MIND退化成Youtube DNN模型。因此MIND可以看成Youtube DNN的延伸和泛化。
DIN:在捕获用户多样兴趣点方面,MIND和DIN目标相似。然而,他们的区别在于实现目标的方式和适用范围。DIN采用无哦级别的注意力机制,MIND采用动态路由算法产生兴趣胶囊并在兴趣级别考虑多样性。而且,DIN关注与排序阶段,MIND关注与匹配阶段。
REFERENCES
[1] Christopher R Aberger. 2016. Recommender: An analysis of collaborative ltering techniques. Technical Report.
[2] Silvio Amir, Byron C. Wallace, Hao Lyu, Paula Carvalho, and Mario J. Silva. 2016. Modelling Context with User Embeddings for Sarcasm Detection in Social Media. In Proceedings of The 20th SIGNLL Conference on Computational Natural Language Learning. Association for Computational Linguistics, 167–177.
[3] Zeynep Batmaz, Ali Yurekli, Alper Bilge, and Cihan Kaleli. 2018. A review on deep learning for recommender systems: challenges and remedies. Arti cial Intelligence Review (2018), 1–37.
[4] Robert M Bell and Yehuda Koren. 2007. Improved neighborhood-based collabora- tive ltering. In KDD cup and workshop at the 13th ACM SIGKDD international conference on knowledge discovery and data mining. Citeseer, 7–14.
[5] Iván Cantador, Alejandro Bellogín, and David Vallet. 2010. Content-based recom- mendation in social tagging systems. In Proceedings of the fourth ACM conference on Recommender systems. ACM, 237–240.
[6] Tao Chen, Ruifeng Xu, Yulan He, Yunqing Xia, and Xuan Wang. 2016. Learn- ing user and product distributed representations using a sequence model for sentiment analysis. IEEE Computational Intelligence Magazine 11, 3 (2016), 34–44.
[7] Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep neural networks for youtube recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems. ACM, 191–198.
[8] Ali Mamdouh Elkahky, Yang Song, and Xiaodong He. 2015. A multi-view deep learning approach for cross domain user modeling in recommendation systems. In Proceedings of the 24th International Conference on World Wide Web. International World Wide Web Conferences Steering Committee, 278–288.
[9] HuifengGuo,RuimingTang,YunmingYe,ZhenguoLi,andXiuqiangHe.2017. DeepFM: A Factorization-machine Based Neural Network for CTR Prediction. In Proceedings of the 26th International Joint Conference on Arti cial Intelligence (IJCAI’17). AAAI Press, 1725–1731.
[10] Ruining He and Julian McAuley. 2016. Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative ltering. In proceedings of the 25th international conference on world wide web. International World Wide Web Conferences Steering Committee, 507–517.
[11] Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, and Tat-Seng Chua. 2017. Neural collaborative ltering. In Proceedings of the 26th International Conference on World Wide Web. International World Wide Web Conferences Steering Committee, 173–182.
[12] Jon Herlocker, Joseph A Konstan, and John Riedl. 2002. An empirical analy- sis of design choices in neighborhood-based collaborative ltering algorithms. Information retrieval 5, 4 (2002), 287–310.
[13] Geo rey E Hinton, Alex Krizhevsky, and Sida D Wang. 2011. Transforming auto-encoders. In International Conference on Arti cial Neural Networks. Springer, 44–51.
[14] Geo rey E Hinton, Sara Sabour, and Nicholas Frosst. 2018. Matrix capsules with EM routing. In International Conference on Learning Representations.
[15] Je Johnson, Matthijs Douze, and Hervé Jégou. 2017. Billion-scale similarity search with gpus. arXiv preprint arXiv:1702.08734 (2017).
[16] Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic opti- mization. arXiv preprint arXiv:1412.6980 (2014).
[17] Yehuda Koren, Robert Bell, and Chris Volinsky. 2009. Matrix factorization tech- niques for recommender systems. Computer 8 (2009), 30–37.
[18] Rodney LaLonde and Ulas Bagci. 2018. Capsules for Object Segmentation. arXiv preprint arXiv:1804.04241 (2018).
[19] Yann LeCun, Yoshua Bengio, and Geo rey Hinton. 2015. Deep learning. nature 521, 7553 (2015), 436.
[20] JulianMcAuley,ChristopherTargett,QinfengShi,andAntonVanDenHengel. 2015. Image-based recommendations on styles and substitutes. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 43–52.
[21] Sara Sabour, Nicholas Frosst, and Geo rey E Hinton. 2017. Dynamic routing between capsules. In Advances in Neural Information Processing Systems. 3856– 3866.
[22] BadrulSarwar,GeorgeKarypis,JosephKonstan,andJohnRiedl.2001.Item-based collaborative ltering recommendation algorithms. In Proceedings of the 10th international conference on World Wide Web. ACM, 285–295.
[23] Jiaxi Tang and Ke Wang. 2018. Personalized top-n sequential recommenda- tion via convolutional sequence embedding. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining. ACM, 565–573.
[24] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems. 5998–6008.
[25] JizheWang,PipeiHuang,HuanZhao,ZhiboZhang,BinqiangZhao,andDikLun Lee. 2018. Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD ’18). 839–848.
[26] Jason Weston, Ron J Weiss, and Hector Yee. 2013. Nonlinear latent factorization by embedding multiple user interests. In Proceedings of the 7th ACM conference on Recommender systems. ACM, 65–68.
[27] Hong-Jian Xue, Xinyu Dai, Jianbing Zhang, Shujian Huang, and Jiajun Chen. 2017. Deep Matrix Factorization Models for Recommender Systems… In IJCAI. 3203–3209.
[28] Min Yang, Wei Zhao, Jianbo Ye, Zeyang Lei, Zhou Zhao, and Soufei Zhang. 2018. Investigating Capsule Networks with Dynamic Routing for Text Classi cation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 3110–3119.
[29] Hongzhi Yin, Bin Cui, Ling Chen, Zhiting Hu, and Xiaofang Zhou. 2015. Dynamic user modeling in social media systems. ACM Transactions on Information Systems (TOIS) 33, 3 (2015), 10.
[30] Yang Yu, Xiaojun Wan, and Xinjie Zhou. 2016. User embedding for scholarly microblog recommendation. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Vol. 2. 449– 453.
[31] Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep interest network for click-through rate prediction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM, 1059–1068.