需求:将swagger接口JSON文件转化为Excel格式查看,如下格式
| 路径 | 请求方法 | tags分类 | summary描述 |
|---|---|---|---|
| /login | post | 登录 | 登录接口 |
过程
先下载swagger接口的JSON文件,然后修改保存为txt文件。
举例几种下载swagger接口文件的格式地址:

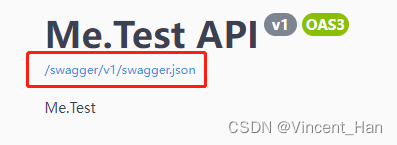

代码脚本将文件转化为Excel文档接口清单
import json
import xlwt
api_excel = xlwt.Workbook(encoding='utf-8') # 创建一个文档
api_sheet = api_excel.add_sheet('CRM接口') # 添加一个sheet
json_file = open('api-docs.txt', encoding='utf-8') # 打开保存的swagger文本文档
api_data = json.load(json_file) # 将文档json内容转换为Python对象
api = api_data['paths'] # 取swagger文件内容中的path,文件中path是键名
path_list = [] # 创建接口地址空列表
method_list = [] # 创建请求方式空列表
tags_list = [] # 创建接口分类空列表S
summary_list = [] # 创建接口描述空列表
for path in api.keys(): # 循环取key
values = api[path] # 根据key获取值
method = tuple(values.keys())[0] # 获取请求方式,文件中请求方式是key
path_list.append(path) # 将path写入接口地址列表中
method_list.append(method) # 将method写入请求方式列表中
if method == 'get': # key为get时从get里面取分类和描述,key为post时从post里面取分类和描述
tags = values['get']['tags'][0] # 获取接口分类
summary = values['get']['summary'] # 获取接口描述
tags_list.append(tags) # 将接口分类写入列表中
summary_list.append(summary) # 将接口描述写入列表中
if method == 'post':
tags = values['post']['tags'][0]
summary = values['post']['summary']
tags_list.append(tags)
summary_list.append(summary)
if method == 'delete':
tags = values['delete']['tags'][0]
summary = values['delete']['summary']
tags_list.append(tags)
summary_list.append(summary)
for i in range(len(path_list)): # 将接口path循环写入第一列
api_sheet.write(i, 0, path_list[i])
for j in range(len(method_list)): # 将请求方式循环写入第二列
api_sheet.write(j, 1, method_list[j])
for m in range(len(tags_list)): # 将接口分类循环写入第三列
api_sheet.write(m, 2, tags_list[m])
for n in range(len(summary_list)): # 将接口描述循环写入第四列
api_sheet.write(n, 3, summary_list[n])
api_excel.save('接口地址.xls') # 保存文件
结语
有些开发可能没有添加路径,导致导出的格式接口有遗漏,需要排查,所以尽可能让开发把接口文档写规范,再运行次脚本。或者有兴趣的高手优化一下,一起进步!
如下带路径和不带路径,不带路径的无法识别导出,有兴趣的可以优化一下,艾特博主,谢谢!
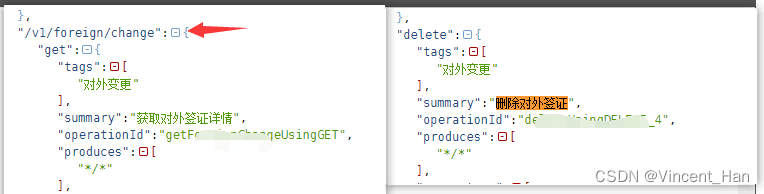
思路:
关于JSON
JSON是一个标记符序列。这套标记符包括:构造字符、字符串、数字和三个字面值。
构造字符
JSON包括六个构造字符,分别是:左方括号、右方括号、左大括号、右大括号、冒号与逗号。
JSON值
JSON值可以是对象、数组、数字、字符串或者三个字面值(false、true、null),并且字面值必须是小写英文字母。
对象
对象是由花括号括起来,逗号分割的成员构成,成员是字符串键和上面所说的JSON值构成,例如:
{"name":"jack","age":18,"address":{"country"}}
数组
数组是由方括号括起来的一组数值构成,例如:
[1,2,32,3,6,5,5]
字符串与数字想必就不用我过多叙述吧。
下面我就举例一些合法的JSON格式的数据:
{"a":1,"b":[1.2.3]}
[1,2,"3",{"a":4}]
3.14
"json_data"
为什么要使用JSON
JSON是一种轻量级的数据交互格式,它使得人们很容易的进行阅读和编写。同时也方便机器进行解析和生成。适用于进行数据交互的场景,比如网站前台与后台之间的数据交互。
JSON的使用方法
json.loads()
把JSON格式字符串解码转成Python对象,从JSON到Python类型转换表如下:
| JSON | Python |
|---|---|
| object | dict |
| array | list |
| string | str |
| number(int) | int |
| number(real) | float |
| true | True |
| false | False |
| null | None |
- 将数组转成列表对象
import json
strList = "[1,2,3,3,4]"
print(json.loads(strList))
print(type(json.loads(strList)))
试着运行上面的代码,你会发现已经成功的将strList转换为列表对象。
- 将对象转换成字典
import json
strDict = '{"city":"上海","name":"jack","age":18}'
print(json.loads(strDict))
print(type(json.loads(strDict)))
试着运行上面的代码,你会发现已经成功的将object转换为dict类型的数据。
json.dumps()
其实这个方法也很好理解,就是将Python类型的对象转换为json字符串。从Python类型向JSON类型转换的对照表如下:
| python | JSON |
|---|---|
| dict | object |
| list, tuple | array |
| str | string |
| int, float | number |
| True | true |
| False | false |
| None | null |
- 将Python列表对象转换为JSON字符串
import json
list_str = [1,2,3,6,5]
print(json.dumps(list_str))
print(type(json.dumps(list_str)))
试着运行上面的代码,你会发现成功的将列表类型转换成了字符串类型。
- 将Python元组对象转换为JSON字符串
import json
tuple_str = (1,2,3,6,5)
print(json.dumps(tuple_str))
print(type(json.dumps(tuple_str)))
试着运行上面的代码,你会发现成功的将元组类型的数据转换成了字符串。
- 将Python字典对象转换为JSON字符串
import json
dict_str = {"name": "小明", "age":18, "city": "中国深圳"}
print(json.dumps(dict_str))
print(type(json.dumps(dict_str)))
输出结果:
{"name": "\u5c0f\u660e", "age": 18, "city": "\u4e2d\u56fd\u6df1\u5733"}
<class 'str'>
看到上面的输出结果也许你会有点疑惑,其实不需要疑惑,这是ASCII编码方式造成的,因为json.dumps()做序列化操作时默认使用的就是ASCII编码,因此我们可以这样写:
import json
dict_str = {"name": "小明", "age":18, "city": "中国深圳"}
print(json.dumps(dict_str, ensure_ascii=False))
print(type(json.dumps(dict_str)))
输出结果:
{"name": "小明", "age": 18, "city": "中国深圳"}
<class 'str'>
因为ensure_ascii的默认值是True,因此我们可以添加参数ensure_ascii将它的默认值改成False,这样编码方式就会更改为utf-8了。
json.load()
该方法的主要作用是将文件中JSON形式的字符串转换为Python类型。
具体代码示例如下:
import json
str_list = json.load(open('position.json', encoding='utf-8'))
print(str_dict)
print(type(str_dict))
运行上面的代码,你会发现成功的将字符串类型的JSON数据转换为了dict类型。
代码中的文件position.json我也会分享给大家。
-
json.dump()
将Python内置类型序列化为JSON对象后写入文件。具体代码示例如下所示:
import json
list_str = [{'city':'深圳'}, {'name': '小明'},{'age':18}]
dict_str = {'city':'深圳','name':'小明','age':18}
json.dump(list_str, open('listStr.json', 'w'), ensure_ascii=False)
json.dump(list_str, open('dictStr.json', 'w'), ensure_ascii=False)
jsonpath
XML精彩强调的优点是提供了大量的工具来分析、转换和有选择地从XML文档中提取数据。Xpath是这些功能强大的工具之一。
对于JSON数据来说,是否应该出现jsonpath这样的工具来解决这个问题。
- 数据可以通过交互方式从客户端上的JSON结构提取,不需要特殊的脚本。
- 客户端请求的JSON数据可以减少到服务器的上的相关部分,从而大幅度减少服务器响应的带宽使用。
jsonpath表达式始终引用JSON结构的方式与Xpath表达式与XML文档使用的方式相同。
jsonpath的安装方法
pip install jsonpath
jsonpath与Xpath
下面表格是jsonpath语法与Xpath的完整概述和比较。
| Xpath | jsonpath | 概述 |
|---|---|---|
| / | $ | 根节点 |
| . | @ | 当前节点 |
| / | .or[] | 取子节点 |
| * | * | 匹配所有节点 |
| [] | [] | 迭代器标识(如数组下标,根据内容选值) |
| // | ... | 不管在任何位置,选取符合条件的节点 |
| n/a | [,] | 支持迭代器中多选 |
| n/a | ?() | 支持过滤操作 |
| n/a | () | 支持表达式计算 |
下面我们就通过几个示例来学习jsonxpath的使用方法。
我们先来看下面这段json数据
{ "store": {
"book": [
{ "category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{ "category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{ "category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{ "category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
}
}
获取符合条件的节点
假如我需要获取到作者的名称该怎么样写呢?
如果通过Python的字典方法来获取是非常麻烦的,所以在这里我们可以选择使用jsonpath.。
具体代码示例如下所示:
import jsonpath
author = jsonpath.jsonpath(data_json, '$.store.book[*].author')
print(author)
运行上面的代码你会发现,成功的获取到了所有的作者名称,并保存在列表中。
或者还可以这样写:
import jsonpath
author = jsonpath.jsonpath(data_json, '$..author')
print(author)
使用指定索引
还是使用上面的json数据,假如我现在需要获取第三本书的价格。
third_book_price = jsonpath.jsonpath(data_json, '$.store.book[2].price')
print(third_book_price)
运行上面的代码,你会发现成功的获取到了第三本书的价格。
使用过滤器
isbn_book = jsonpath.jsonpath(data_json, '$..book[?(@.isbn)]')
print(isbn_book)
print(type(isbn_book))
通过运行上面的代码,你会发现,成功的将含有isbn编号的书籍过滤出来了。
同样的道理,根据上面的例子,我们也可以将价格小于10元的书过滤出来。
book = jsonpath.jsonpath(data_json, '$..book[?(@.price<10)]')
print(book)
print(type(book))
通过运行上面的代码,你会发现这里已经成功的将价格小于10元的书提取出来了。
jsonpath其实是非常适合用来获取json格式的数据的一款工具,最重要的是这款工具轻量简单容使用。关于jsonpath的介绍到这里就结束了,有兴趣的就试试吧!