支持向量机(Support Vector Machine, SVM)的底层原理
支持向量机是一种用于分类和回归的强大机器学习算法,最常见的是用于二分类任务。SVM 的核心思想是通过找到一个最优超平面,将数据集划分成不同的类别。SVM 尤其擅长处理高维数据,且能在数据少的情况下提供较好的分类效果。
1. SVM 的基本概念
在 SVM 中,主要有几个核心概念:
- 超平面(Hyperplane):在特征空间中划分数据的决策边界。对于二维数据来说,超平面是一条线;对于三维数据来说,超平面是一个平面。
- 支持向量(Support Vector):离决策边界最近的样本点。支持向量是定义超平面位置和方向的关键数据点。
- 间隔(Margin):支持向量与超平面之间的距离。SVM 通过最大化间隔来优化超平面,使得分类更具泛化能力。
2. 线性可分的情况
在数据线性可分的情况下,支持向量机旨在找到一个超平面来将不同类别的数据完全分开,且间隔最大化。对于一个线性可分的数据集,我们可以用以下决策函数来表示:
其中,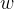
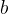
为了最大化间隔,我们要最小化 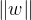
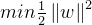
同时满足约束条件:
这个优化问题可以通过 拉格朗日乘子法 转化为对偶问题,并使用 SMO 算法或其它优化算法求解。
3. 线性不可分的情况:软间隔与惩罚项
在实际应用中,数据往往并非线性可分。为此,我们引入 软间隔(Soft Margin) 和 惩罚项,允许少量样本出现在错误的分类区域内。
- 定义松弛变量 ξiξi,表示每个样本点偏离其正确分类的程度。
- 优化目标变为最小化
的加权和。
优化问题变为:
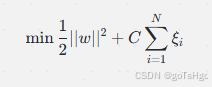
其中,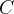
4. 核函数(Kernel Function)
当数据在低维空间中不可分时,SVM 通过核函数将数据映射到更高维空间,在更高维度下寻找线性可分的超平面。常用的核函数包括:
- 线性核:K(x,x′)=x⋅x′
- 多项式核:
- 高斯核(RBF 核):K(x,x′)=exp(
)
- Sigmoid 核:K(x,x′)=tanh(αx⋅x′+c)
核函数的作用是避免直接在高维空间中计算数据点的坐标,通过核技巧(Kernel Trick),可以在低维空间进行计算,降低计算复杂度。
5. SVM 的优化算法
SVM 的优化问题通常会通过 拉格朗日对偶 转换为对偶问题,从而简化求解过程。对于大规模数据集,SMO(Sequential Minimal Optimization) 是常用的优化算法,其基本思想是每次只优化两个变量,使得复杂的约束条件转换为二元约束问题,从而高效求解。
SVM 实现细节:Python 源码分析
在 scikit-learn 中,SVM 算法使用 SVC(支持向量分类)类实现,以下是基于 scikit-learn 的 SVC 类的代码示例:
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
# 加载数据集
iris = datasets.load_iris()
X = iris.data[:, :2] # 只取两个特征方便可视化
y = iris.target
y = y[y != 2] # 仅使用两类样本进行二分类
X = X[y != 2]
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 构建 SVM 模型
clf = SVC(kernel='linear', C=1.0)
clf.fit(X_train, y_train)
# 打印支持向量
print("支持向量:", clf.support_vectors_)
# 预测测试集
y_pred = clf.predict(X_test)
# 可视化决策边界
def plot_decision_boundary(clf, X, y):
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01),
np.arange(y_min, y_max, 0.01))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', marker='o')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('SVM Decision Boundary')
plt.show()
plot_decision_boundary(clf, X, y)
源码分析
scikit-learn 的 SVC 类是对 libsvm 的封装,核心参数和方法包括:
- kernel:指定核函数类型,包括
'linear'、'poly'、'rbf'、'sigmoid'等。 - C:惩罚系数,控制软间隔的程度。
- fit(X, y):训练模型。
- predict(X):对测试数据进行分类预测。
- support_vectors_:返回支持向量。
在 fit 方法中,scikit-learn 会调用 libsvm 的训练接口,根据给定的数据和参数进行支持向量求解,通过 SMO 或其他优化算法找到最优解。
SVM 的应用场景
SVM 适用于高维数据集和样本量较小的数据集。在文本分类、人脸识别、生物信息学等领域,SVM 都得到了广泛应用。
SVM 的优缺点
优点:
- 分类效果好:适合高维数据,且对样本量少的数据有很好的分类效果。
- 高泛化能力:通过最大化间隔使得模型具有更强的泛化能力。
- 多样性:可通过不同的核函数应对非线性问题。
缺点:
- 计算复杂度高:对于大规模数据集训练速度较慢,尤其是使用非线性核函数时。
- 对参数敏感:核函数类型、惩罚系数 C、核函数参数等对模型影响较大,需要通过调参找到最优组合。
- 解释性弱:相比于决策树等模型,SVM 的决策过程不易理解和解释。
SVM 的总结
SVM 是一种强大的分类算法,适用于高维和小样本数据。其主要思想是找到一个最优超平面,最大化不同类别数据的间隔。通过软间隔和核函数,SVM 可以处理线性不可分数据。优化算法主要使用 SMO 或对偶问题求解。虽然 SVM 在分类效果上表现出色,但训练复杂度较高,对参数敏感。