一、说明
协方差量化了两个随机变量协同变化的程度。当一个变量的较高值与另一个变量的较高值对齐时,同样,对于较低的值,协方差为正。相反,如果一个变量的较高值与另一个变量的较低值一致,则协方差为负。
二、协方差和相关性
2.1 协方差的概念
这是协方差的公式:
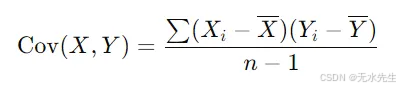
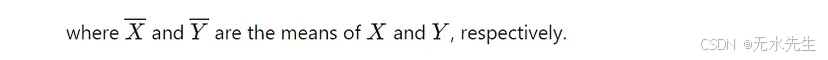
协方差提示
协方差表示变量之间线性关系的方向。
如果 X 和 Y 趋于一起增加,则它们的协方差为正。
如果 X 增加,而 Y 减少,则它们的协方差为负。
如果 X 和 Y 是独立的,则它们的协方差为零。
2.1 相关
相关性量化了两个变量的相关程度。它是协方差的归一化形式,其值范围为 -1 到 1。相关性 1 表示完全正关系,-1 表示完全负关系,0 表示无关系。
公式:
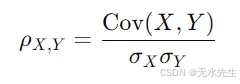

相关性提示:
相关性不仅衡量两个变量之间线性关系的方向,还衡量其强度。
正值表示正关系。
负值表示负关系。
接近零的值表示没有线性关系。
以下是一些用于更好地理解不同值相关性的图:
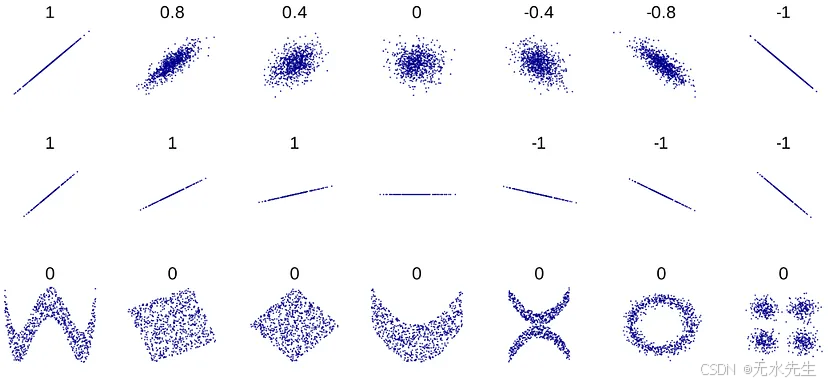
图 2.与不同值的相关性 [维基百科上的数据]
实例
示例 1:协方差计算
让我们考虑两个变量 X 和 Y,它们的值如下:
X = [2, 4, 6, 8]
Y = [1, 3, 5, 7]
协方差的 Python 代码:
import numpy as np
# Data
X = np.array([2, 4, 6, 8])
Y = np.array([1, 3, 5, 7])
# Mean of X and Y
mean_X = np.mean(X)
mean_Y = np.mean(Y)
# Covariance Calculation
covariance = np.sum((X - mean_X) * (Y - mean_Y)) / (len(X) - 1)
print(f"Covariance: {covariance}")
协方差:6.6666666666666667
示例 2:相关性计算
使用相同的变量 X 和 Y,我们计算它们的相关性。
用于关联的 Python 代码:
# Data
X = np.array([2, 4, 6, 8])
Y = np.array([1, 3, 5, 7])
# Standard deviations of X and Y
std_X = np.std(X, ddof=1)
std_Y = np.std(Y, ddof=1)
# Correlation Calculation
correlation = covariance / (std_X * std_Y)
print(f"Correlation: {correlation}")
相关性:1.00000000000000002
使用库进行协方差和相关性:
我们还可以使用该库直接计算协方差和相关性:numpy
# Covariance Matrix
cov_matrix = np.cov(X, Y)
print(f"Covariance Matrix:\n{cov_matrix}")
print()
# Correlation Matrix
corr_matrix = np.corrcoef(X, Y)
print(f"Correlation Matrix:\n{corr_matrix}")
这是上述代码的输出:

图 1.协方差和相关性的输出
可视化数据有助于了解变量之间的关系。
import matplotlib.pyplot as plt
plt.scatter(X, Y)
plt.title("Scatter Plot of X and Y")
plt.xlabel("X")
plt.ylabel("Y")
plt.show()
这是上述代码的输出:
图 3.X 和 Y 的散点图
三、有关关联的高级主题 (有关详细信息)
3.1 相关性和独立性
-
独立性的定义
如果一个变量的出现不会影响另一个变量的出现,则两个变量 X 和 Y 是独立的。从数学上讲,如果满足以下条件,X 和 Y 是独立的: -
相关性和独立性
独立性意味着零相关性:如果两个变量是独立的,则它们的相关性为零。然而,反之则不一定是正确的。
零相关性并不意味着独立性:两个变量的相关性可以为零,但仍以非线性方式相关。
3.2 零相关性和依赖性示例
将 X 视为 [−1, 1] 上的均匀分布随机变量,并设 Y=X²。在这里,X 和 Y 不是线性相关的(相关性为零),但它们显然是相关的(因为 Y 由 X 决定)。
import numpy as np
import matplotlib.pyplot as plt
# Generating data
X = np.random.uniform(-1, 1, 1000)
Y = X ** 2
# Calculating correlation
correlation = np.corrcoef(X, Y)[0, 1]
plt.scatter(X, Y)
plt.title(f"Correlation between X and Y is: {correlation:.4}")
plt.xlabel('X')
plt.ylabel('Y');
输出:
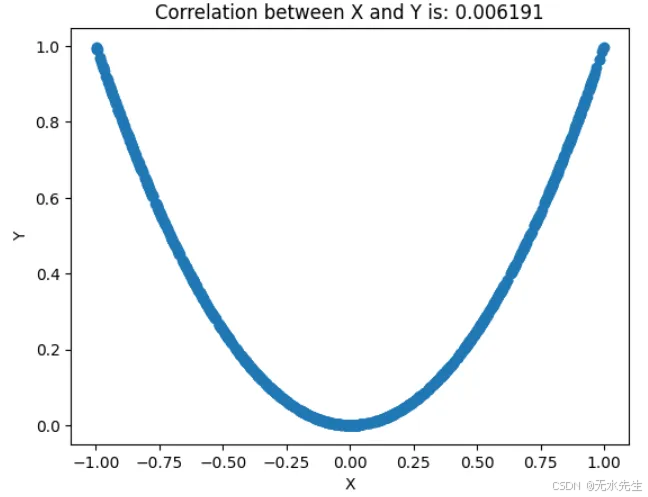
图 4. 零相关性和依赖性
四、相关性和因果关系
-
因果关系的定义
因果关系意味着一个变量的变化直接导致另一个变量的变化。建立因果关系需要的不仅仅是观察相关性;它需要对照实验或纵向研究。 -
相关性并不意味着因果关系
仅仅因为两个变量相关并不意味着一个变量导致另一个变量。相关性可能是由于:
巧合:变量是偶然相关的。
混杂变量:另一个变量影响这两个变量。
无因果关系的相关性示例
有研究表明,在某些地区,鹳的数量与人类出生率呈正相关!这种相关性可能会导致人们错误地得出鹳鸟接生婴儿的结论。然而,这种相关性背后的实际原因在于,较高的鹳数量和较高的出生率都与农村地区有关,而不是鹳和婴儿之间的因果关系。

图 5. 鹳和人类出生率
详细说明
鹳:一个区域中的鹳数量。
出生率:一个地区的人类出生人数。
农村:混杂变量。与城市地区相比,农村地区的鹳鸟数量和出生率往往更高。
Python 示例
让我们模拟数据来说明这个例子。
import numpy as np
import pandas as pd
# Data generation
np.random.seed(42)
num_villages = 100
villages = np.arange(1, num_villages + 1)
stork_population = np.random.poisson(lam=30, size=num_villages) # Simulating stork population
birth_rate = 0.5 * stork_population + np.random.normal(scale=5, size=num_villages) # Birth rate influenced by stork population
# Creating DataFrame
data = pd.DataFrame({
'Village': villages,
'Stork Population': stork_population,
'Birth Rate': birth_rate
})
# Correlation calculation
correlation = np.corrcoef(data['Stork Population'], data['Birth Rate'])[0, 1]
print(f"Correlation between Stork Population and Birth Rate: {correlation:.2f}")
鹳鸟种群与出生率的相关性:0.38
让我们可视化它以便更好地理解:
import matplotlib.pyplot as plt
plt.scatter(data['Stork Population'], data['Birth Rate'])
plt.title('Stork Population vs. Birth Rate')
plt.xlabel('Stork Population')
plt.ylabel('Birth Rate')
plt.show()
输出:
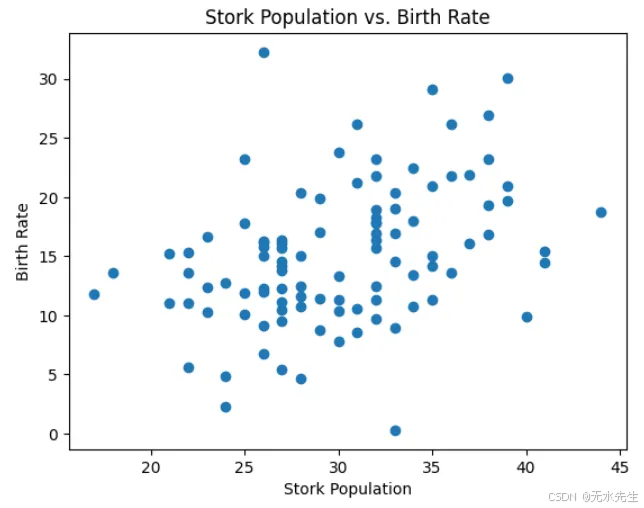
图 6. 鹳鸟种群与出生率
结果说明
正相关:计算将显示鹳鸟种群与出生率之间的正相关关系。
误解:如果不了解上下文,人们可能会错误地认为鹳是导致出生率增加的原因。
混杂变量:实际上,较高的鹳鸟数量和出生率在农村地区都是典型的,这是导致观察到的相关性的潜在因素。
此示例强调两个变量之间的相关性并不意味着直接的因果关系。可能还有其他潜在因素(混杂变量)有助于观察到的相关性。因此,在得出有关因果关系的结论之前,仔细分析和考虑所有可能的因素是必不可少的。
五、结论
在机器学习系列的第 31 天,我们深入研究了协方差和相关性的基本统计概念。通过实际的 Python 示例,我们演示了如何计算和解释这些指标,强调了区分相关性和因果关系的重要性,并了解混杂变量的作用。
保持好奇心,继续探索!您迈出的每一步都让您更接近掌握机器学习的艺术和科学。不要错过这个激动人心的旅程的下一章!