使用sklearn中的式子来可视化决策边界,支持向量,以及决策边界平行的两个超平面。
- 导入需要的模块
from sklearn.datasets import make_blobs #导入创造数据集的包
from sklearn.svm import SVC #支持向量机分类器
import matplotlib.pyplot as plt
import numpy as np
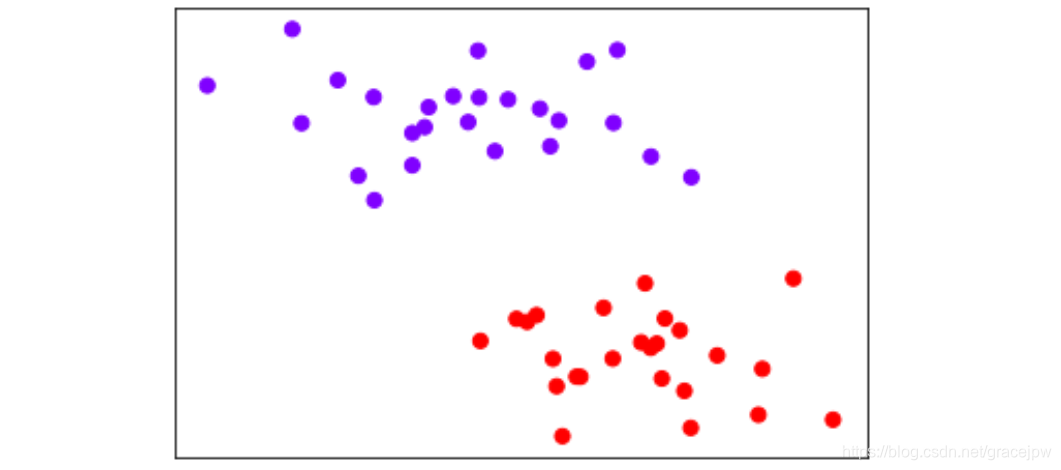
- 实例化数据集,可视化数据集
X,y = make_blobs(n_samples=50, centers=2, random_state=0,cluster_std=0.6)
plt.scatter(X[:,0],X[:,1],c=y,s=50,cmap="rainbow")
plt.xticks([]) #隐藏X轴刻度
plt.yticks([]) #隐藏Y轴刻度
plt.show()
画决策边界:理解函数contour
matplotlib.axes.Axes.contour([X, Y,] Z, [levels], **kwargs)
Contour是专门用来绘制等高线的函数。等高线,本质上是在二维图像上表现三维图像的一种形式,其中两维X和Y是两条坐标轴上的取值,而Z表示高度。Contour就是将由X和Y构成平面上的所有点中,高度一致的点连接成线段的函数,在同一条等高线上的点一定具有相同的Z值。我们可以利用这个性质来绘制我们的决策边界。
参数含义:
X,Y
选填。两维平面上所有的点的横纵坐标取值,一般要求是二维结构并且形状需要与Z相同,往往通过numpy.meshgrid()这样的函数来创建。如果X和Y都是一维,则Z的结构必须为(len(Y), len(X))。如果不填写,则默认X = range(Z.shape[1]),Y =range(Z.shape[0])。
Z
必填。平面上所有的点所对应的高度。
levels
可不填,不填默认显示所有的等高线,填写用于确定等高线的数量和位置。如果填写整数n,则显示n个数据区间,即绘制n+1条等高线。水平高度自动选择。如果填写的是数组或列表,则在指定的高度级别绘制等高线。列表或数组中的值必须按递增顺序排列。
回忆一下,我们的决策边界是,并在决策边界的两边找出两个超平面,使得超平面到决策边界的相对距离为1。那其实,我们只需要在我们的样本构成的平面上,把所有到决策边界的距离为0的点相连,就是我们的决策边界,而把所有到决策边界的相对距离为1的点相连,就是我们的两个平行于决策边界的超平面了。此时,我们的Z就是平面上的任意点到达超平面的距离。
那首先,我们需要获取样本构成的平面,作为一个对象。
#绘制原数据集散点图
plt.scatter(X[:,0],X[:,1],c=y,s=50,cmap="rainbow")
ax = plt.gca() #获取当前的子图,如果不存在,则创建新的子图
有了这个平面,我们需要在平面上制作一个足够细的网格,来代表我们“平面上的所有点”。
画决策边界:制作网格,理解函数meshgrid
#获取平面上两条坐标轴的最大值和最小值
xlim = ax.get_xlim()
ylim = ax.get_ylim()
#在最大值和最小值之间形成30个规律的数据
axisx = np.linspace(xlim[0],xlim[1],30)
axisy = np.linspace(ylim[0],ylim[1],30)
axisx,axisy = np.meshgrid(axisx,axisy)
#我们将使用这里形成的二维数组作为我们contour函数中的X和Y
#使用meshgrid函数将两个一维向量转换为特征矩阵
#核心是将两个特征向量广播,以便获取y.shape * x.shape这么多个坐标点的横坐标和纵坐标
xy = np.vstack([axisx.ravel(), axisy.ravel()]).T
#其中ravel()是降维函数,vstack能够将多个结构一致的一维数组按行堆叠起来
#xy就是已经形成的网格,它是遍布在整个画布上的密集的点
plt.scatter(xy[:,0],xy[:,1],s=