系列文章
文章目录
3 程序的机器级表示
- 计算机执行机器代码,编译器基于编程语言的规则、目标机器的指令集,操作系统遵循的惯例生成机器代码。
- 汇编代码是机器代码的文本表示。高级代码可移植性较好,而汇编代码与特定机器密切相关。
- 现在不要求使用汇编语言编制程序,能够阅读和理解编译器转化的汇编语言的细节和方式,并分析代码中隐含的低效率。
- 精通细节是理解更深和更基本概念的先决条件。
3.1 历史观点
- Intel处理器系列俗称x86,每个后续处理器都是向下兼容的(所以指令集中会有一些奇怪的东西),x86(64位)。
- 摩尔定律: 晶体管数目18个月翻一番。
3.2 程序编码
- 使用较高级别优化的代码会严重变形(和源代码的格式),机器代码和初始源代码之间的关系难以理解。实际中,从程序性能考虑,较高级别的优化是较好的选择(O2用的比较多)。
- 汇编器产生的目标代码是机器代码的一种形式,它包含二进制形式表示的所有指令,但还没有填入全局值的地址。链接之后才形成可执行代码,可执行代码是机器代码的第二种形式。
3.2.1 机器级代码
- 对机器级编程尤为重要的两种抽象
1.指令集架构:定义了处理器状态、指令的格式、指令对状态的影响。
- 虚拟地址:机器级程序使用虚拟地址,即将内存看成一个按字节寻址的数组。
- 一些通常对语言级隐藏的处理器状态(机器级可见)
- 程序计数器(PC):下一条执行指令的地址
- 整数寄存器文件:保存临时数据或重要的程序状态
- 条件码寄存器:最近执行的算术或逻辑指令的状态信息
- 一组向量寄存器:保存一个或多个整数或浮点数值
- 机器代码和汇编代码中不区分有符号数和无符号数,不区分指针的不同类型,不区分指针和整数。
- 因为虚拟内存的大小通常比较大,程序实际使用和访问的内存大小通常远小于虚拟内存看起来的大小。所以在任意的时刻,只有有限的虚拟内存是合法的,操作系统负责管理虚拟内存(通过表翻译为实际的物理地址)。
- 一条机器指令只执行一个非常基本的操作。
3.2.2 代码示例
#include <stdio.h>
// 声明 multstore 函数
void multstore(long x, long y, long *dest);
// 声明 mult2 函数
long mult2(long a, long b);
int main() {
long d;
multstore(2, 3, &d);
printf("2 * 3 --> %ld\n", d);
return 0;
}
// 定义 multstore 函数
void multstore(long x, long y, long *dest) {
*dest = mult2(x, y);
}
// 定义 mult2 函数
long mult2(long a, long b) {
long s = a * b;
return s;
}
gcc -S a.c -o multstore.s
//部分汇编,不同优化等级和环境产生的不一样
//这个和书上差别有亿点大
63 mult2:
64 .LFB2:
65 .cfi_startproc
66 pushq %rbp
67 .cfi_def_cfa_offset 16
68 .cfi_offset 6, -16
69 movq %rsp, %rbp
70 .cfi_def_cfa_register 6
71 movq %rdi, -24(%rbp)
72 movq %rsi, -32(%rbp)
73 movq -24(%rbp), %rax
74 imulq -32(%rbp), %rax
75 movq %rax, -8(%rbp)
76 movq -8(%rbp), %rax
77 popq %rbp
78 .cfi_def_cfa 7, 8
79 ret
80 .cfi_endproc
- -S选项产生汇编代码
- 反汇编是根据机器代码反推出汇编的,逆向和一些安全漏洞分许就会用到这个
- 机器代码与反汇编表示的特性:
- x86-64 的指令长度范围为 1~15 字节。常用指令和操作数少的指令所需字节少。
- 指令格式设计方式为:可以将字节唯一的解码成机器指令。
- 反汇编器基于机器代码文件中的字节序列确定汇编代码,与源代码和编译时的汇编代码无关
- 指令结尾的 ‘q’ 是大小指示符,大多数情况下可以省略。
- 从源程序转换来的可执行目标文件中,除了程序过程的代码,还包含启动和终止程序的代码,与操作系统交互的代码。
3.2.3 关于格式的注解
81 .LFE2:
82 .size mult2, .-mult2
83 .ident "GCC: (GNU) 4.8.5 20150623 (Red Hat 4.8.5-44)"
84 .section .note.GNU-stack,"",@progbits
像这样的汇编代码,以 ‘.’ (点) 开头的行是指导汇编器和链接器工作的伪指令。我们一般忽略它们。
- 在汇编语言中,Intel 和 AT&T 是两种主要的语法格式它们在指令格式、操作数顺序、寄存器命名等方面有显著的区别。
- Intel 语法: 目的操作数在前,源操作数在后。
AT&T 语法: 源操作数在前,目的操作数在后。 - 操作数大小
Intel 语法: 操作数大小由操作码决定,不需要额外的后缀。
AT&T 语法: 使用后缀来指明操作数大小(b 表示字节,w 表示字,l 表示双字,q 表示四字)。 - 寄存器命名
Intel 语法: 寄存器名称直接使用。
AT&T 语法: 寄存器名称前面加 % 符号。 - 立即数
Intel 语法: 立即数不需要前缀。
AT&T 语法: 立即数前面加 $ 符号
- 还有一些符号上的小差距,总的来说两者操作数顺序恰好相反,
- 我个人觉得Intel语法在许多方面更加简洁
- 有些C语言访问不到的机器特性,我们可以考虑包含(asm伪指令)或者链接一部分汇编指令来优化程序。
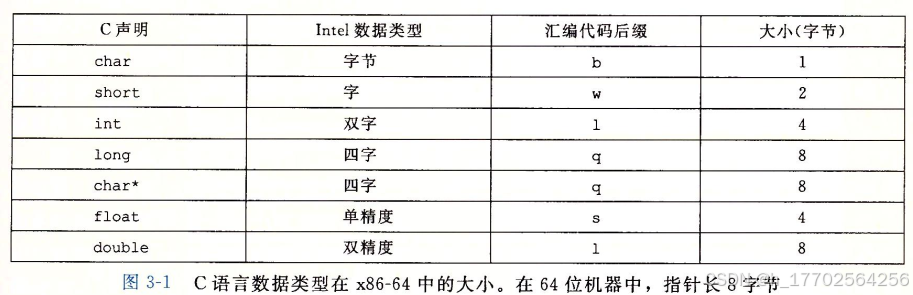
3.3 数据格式
汇编代码指令最后一个字符的后缀:movb, movw, movl, movq。
这里说的都是整数,浮点数使用一组完全不同的指令和寄存器,“l”既可以表示四字节整数,也可以表示8字节的双精度浮点数。
3.4 访问信息

- 名称
- 起初的8086只有8个16位的寄存器:%ax到%bp (r是特殊的栈指针)
- 后面IA32架构,扩展至32位,前缀一个e,也就是%eax到%ebx
- x86-64架构,扩展至16个64位,自带一个r,大小由尾缀决定,编号也挺草率的,几个版本主打一个风格迥异。
- 低位操作的规则:
- 将寄存器作为目标位置时,生成字节和字的指令会保持剩下的字节不变。(放字节,字(2字节)的时候就不改其他位的值了)
- 生成双字的指令会把高位四字节置为 0。(32位扩展的一部分内容)
- 16个寄存器的作用
a:返回值
s:栈指针
d, s, d, c, 8, 9:第 1 到第 6 个参数
b,bp, 12~15:被调用者保存
10, 11:调用者保存
3.4.1 操作数指示符
- 三种主要的操作数类型:
- 立即数 (Immediate),表示常数值
考研好像是Intel格式
//Intel 语法示例
mov eax, 10 ; 将立即数 10 移动到寄存器 eax
add eax, 5 ; 将立即数 5 加到寄存器 eax
//AT&T 语法示例
movl $10, %eax ; 将立即数 10 移动到寄存器 eax
addl $5, %eax ; 将立即数 5 加到寄存器 eax
- 寄存器 (Register),使用寄存器中的全部位或者低位的内容
//Intel 语法示例
mov eax, ebx ; 将寄存器 ebx 的值移动到寄存器 eax
add eax, ecx ; 将寄存器 ecx 的值加到寄存器 eax
//AT&T 语法示例
movl %ebx, %eax ; 将寄存器 ebx 的值移动到寄存器 eax
addl %ecx, %eax ; 将寄存器 ecx 的值加到寄存器 eax
- 内存引用 (Memory Reference),寻址,可以是直接地址、间接地址或基于寄存器的地址计算。带了()或者[],和解引用指针很像。
//Intel 语法示例
mov eax, [ebx] ; 将内存地址 [ebx] 的值移动到寄存器 eax
mov [ecx + 4], edx ; 将寄存器 edx 的值移动到内存地址 [ecx + 4]
add eax, [esi + edi*4] ; 将内存地址 [esi + edi*4] 的值加到寄存器 eax
//AT&T 语法示例
movl (%ebx), %eax ; 将内存地址 (%ebx) 的值移动到寄存器 eax
movl %edx, 4(%ecx) ; 将寄存器 edx 的值移动到内存地址 4(%ecx)
addl (%esi, %edi, 4), %eax ; 将内存地址 (%esi, %edi, 4) 的值加到寄存器 eax
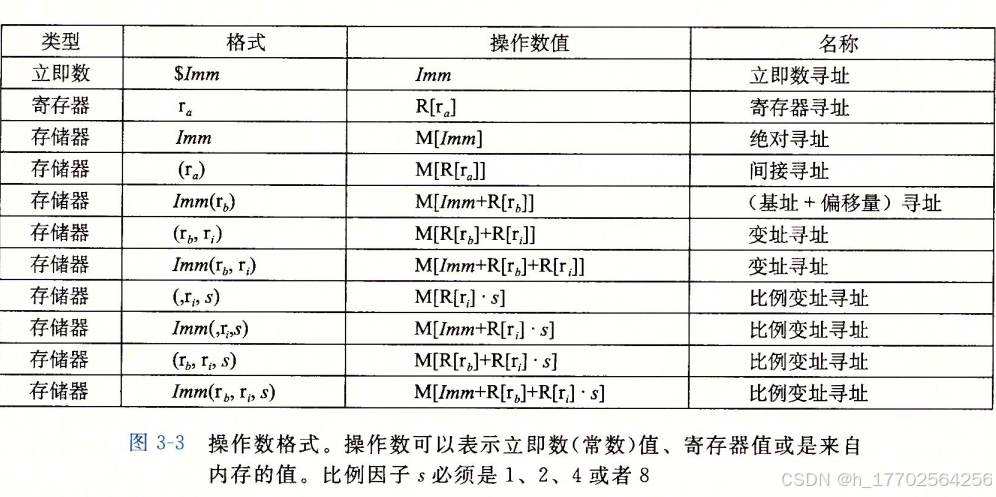
- 最后一种最常用也最重要(其他格式是它的一个特例)
- Imm(rb, ri, s)
- Imm(立即数偏移) + R[rb] (基址) + R[ri] (变址)s (比例因子)
- s 只能是 1,2,4,8 中的一个
3.4.2 数据传送指令
- 简单的四种mov指令
movb, movw, movl,movq:传送字节、字、双字、四字 - movabsq(move absolute quadword):传送绝对的四字。用于将一个 64 位的立即数传送到一个 64 位寄存器中。用于初始化寄存器或处理大数,机器码九字节(1+8),较大。
- mov的五种组合:
- 立即数到寄存器 (Immediate to Register)
将一个立即数传送到一个寄存器中。 - 立即数到内存 (Immediate to Memory)
将一个立即数传送到一个内存位置中。 - 寄存器到寄存器 (Register to Register)
将一个寄存器的值传送到另一个寄存器中。 - 内存到寄存器 (Memory to Register)
将一个内存位置的值传送到一个寄存器中。 - 寄存器到内存 (Register to Memory)
将一个寄存器的值传送到一个内存位置中。
- 示例
; Intel 语法
; 立即数到寄存器
mov eax, 10
; 立即数到内存
mov [var1], 20
; 寄存器到寄存器
mov ebx, eax
; 内存到寄存器
mov ecx, [var1]
; 寄存器到内存
mov [var2], ebx
; AT&T 语法
; 立即数到寄存器
movl $10, %eax
; 立即数到内存
movl $20, var1
; 寄存器到寄存器
movl %eax, %ebx
; 内存到寄存器
movl var1, %ecx
; 寄存器到内存
movl %ebx, var2
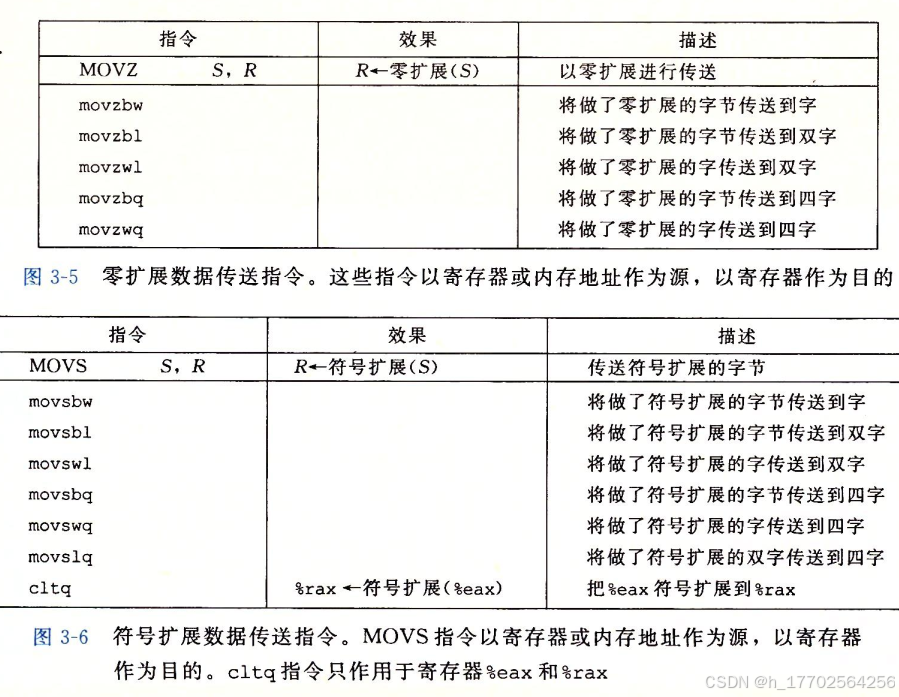
- 将较小的源值复制到较大的目的地使用movz或者movs
他们的后缀字符第一个指定源的大小,第二个指定目的大小
movz,将剩余部分填充为0。
movs,将剩余部分填充为符号位。
3.4.3 数据传送示例
- 3.4.2已经示范差不多了
- 局部变量通常保存在寄存器中。
- 函数返回指令 ret 返回的值为寄存器 rax 中的值
- 强制类型转换可通过 mov 指令实现的。
- 当指针存在寄存器中时,a = p 的汇编指令为: mov (rdi), rax
3.4.4 压入和弹出栈数据
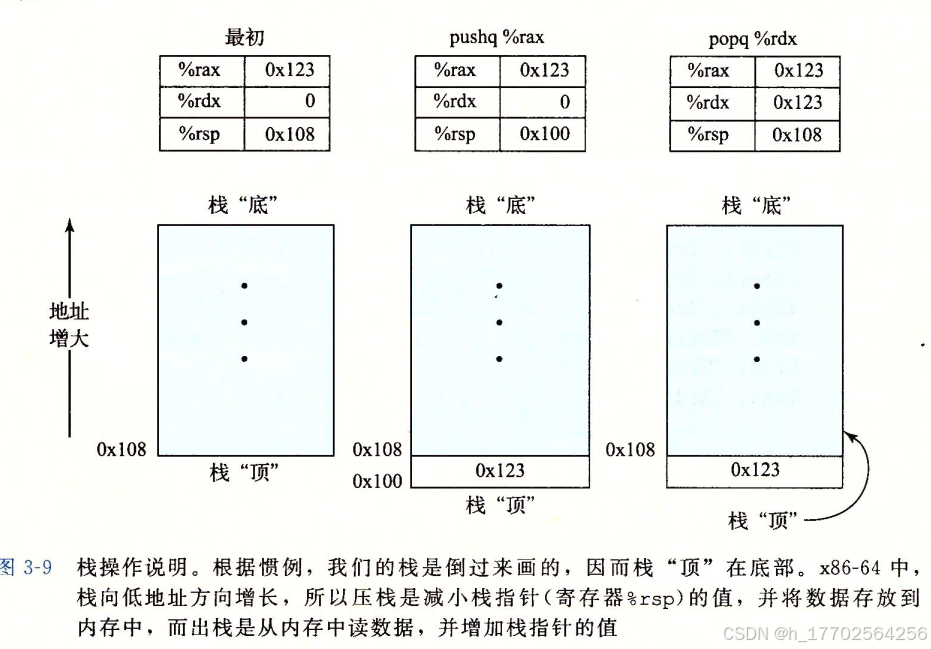
- 栈:向下增长(所以压栈时减[%rsp]),后进先出
- push:压栈
- pop:出栈
- %rsp:(64位) 栈指针,栈顶元素的地址
- 指令尾缀代表操作的大小(bwlq)
- 其实压栈操作等价于先减栈指针值,再将指定寄存器的值写入栈,反之,出栈先读出栈顶数据到指定寄存器,在加栈指针的值。而push,pop只被编码为一个字节即可完成这两步需要8个字节指令大小的操作。
- 使用 mov 指令和标准的内存寻址方法可以访问栈内的任意位置,而非仅限于栈顶。