在自然语言处理(NLP)领域,Seq2Seq(Sequence to Sequence)模型是一种强大的工具,它能够将一个序列转换为另一个序列。这个模型被广泛应用于机器翻译、文本生成、语音识别等任务中。本文将带你深入了解Seq2Seq模型的原理和应用。
什么是 Seq2Seq 模型?
Seq2Seq模型是一种神经网络架构,能够将一个输入序列(例如,一个句子)转换为另一个输出序列(例如,另一个语言中的翻译句子)。这个过程包括两个主要部分:编码器(Encoder)和解码器(Decoder)。
编码器(Encoder)
编码器的任务是读取并理解输入序列。它由一系列递归神经网络(RNN)或长短期记忆网络(LSTM)单元组成。每个输入的单词都会通过这些单元逐个处理,最终生成一个包含整个输入序列信息的上下文向量(Context Vector)。
设输入序列为 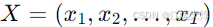
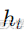
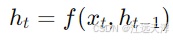
其中, f 是递归神经网络的计算单元(例如,LSTM或GRU)。
解码器(Decoder)
解码器接收编码器生成的上下文向量,并开始生成输出序列。与编码器类似,解码器也是由一系列RNN或LSTM单元组成。每个时间步,解码器生成下一个输出单词,并将其作为输入传递到下一个时间步中,直到生成完整的输出序列。
设输出序列为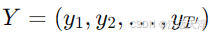
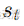
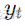
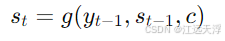
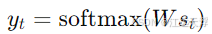
其中,g 是解码器的计算单元, c 是上下文向量, W 是用于生成输出的权重矩阵。
Seq2Seq 模型的训练
在训练过程中,我们使用配对的输入和输出序列(例如,英语句子和它的中文翻译)来训练模型。目标是最小化预测输出序列与实际输出序列之间的差异。
损失函数
常用的损失函数是交叉熵损失(Cross-Entropy Loss),它衡量预测分布与实际分布之间的差异。交叉熵损失的公式为:
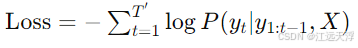
通过反向传播算法,模型参数会不断调整,以逐步减小损失值。
实际应用
机器翻译
Seq2Seq模型最经典的应用之一就是机器翻译,输入一个英语句子,通过编码器生成上下文向量,然后解码器将其转换为对应的中文句子。
文本摘要
另一个常见应用是文本摘要。给定一段长文本,Seq2Seq模型可以生成一个简短的摘要,提取出文本的关键信息。
聊天机器人
Seq2Seq模型还可以用于聊天机器人。输入用户的问题,编码器理解问题内容,解码器生成合理的回答。
注意力机制(Attention Mechanism)
虽然Seq2Seq模型功能强大,但它有一个明显的缺陷:长输入序列会导致上下文向量信息丢失。为了解决这个问题,引入了注意力机制(Attention Mechanism)。
如何工作
注意力机制允许解码器在每个时间步“关注”编码器输出的不同部分,而不是仅依赖单一的上下文向量。这样,解码器可以更好地理解并生成长序列输出。
注意力机制通过计算每个输入隐藏状态 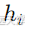
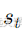
然后,解码器的上下文向量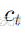
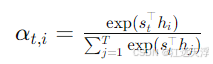
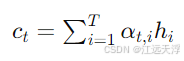
解码器的输出则由以下公式计算:
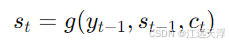
代码示例
下面是一个简单的Seq2Seq模型实现示例,使用TensorFlow和Keras库:
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, LSTM, Dense
# 定义模型参数
latent_dim = 256 # LSTM的潜在维度
num_encoder_tokens = 100 # 输入序列的词汇大小
num_decoder_tokens = 100 # 输出序列的词汇大小
# 编码器
encoder_inputs = Input(shape=(None, num_encoder_tokens))
encoder = LSTM(latent_dim, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_inputs)
encoder_states = [state_h, state_c]
# 解码器
decoder_inputs = Input(shape=(None, num_decoder_tokens))
decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_inputs, initial_state=encoder_states)
decoder_dense = Dense(num_decoder_tokens, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
# 构建模型
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
# 编译模型
model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
# 模型训练
# model.fit([input_data, target_data], target_data, batch_size=64, epochs=100)