1. 实战概述
- 今天我们将深入探讨 Apache Spark 中的两种核心数据结构:RDD(弹性分布式数据集)和 DataFrame。这两种结构是大数据处理的基石,为分布式计算提供了强大的支持。RDD 提供了对分布式数据集的基本操作,而 DataFrame 则在此基础上增加了对结构化数据的支持,使得数据处理更加高效和易于理解。了解它们的特性、优势以及适用场景,对于在 Spark 上进行高效的大数据处理至关重要。通过实际案例,我们将展示如何利用这些数据结构来解决实际问题。
2. RDD(弹性分布式数据集)
2.1 RDD概念
- RDD,即弹性分布式数据集(Resilient Distributed Dataset),是Apache Spark中最基本的数据结构。它是一个不可变的、分布式的数据集合,由多个分区的数据组成,每个分区可以分布在集群的不同节点上。RDD提供了丰富的操作,包括转换(transformation)和行动(action),来处理数据。它的设计允许系统自动进行容错处理,即在数据丢失时能够自动恢复。RDD的不可变性意味着一旦创建,就不能更改其内容,只能通过转换操作生成新的RDD。这些特性使得RDD非常适合进行大规模并行数据处理。
2.2 RDD特点
- 以数据类型作为参数,例如
RDD[User]。 - 只知道存储的数据是特定类的实例,但无法感知数据的内部结构,如列名和数据类型。
2.3 实战操作
- 在
net.huawei.sql包里创建RDDDemo对象
package net.huawei.sql
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
case class User(name: String, gender: String, age: Long)
object RDDDemo {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("SparkSQLTest")
.master("local[*]")
.getOrCreate()
import spark.implicits._
val users = Seq(
User("陈燕文", "女", 30),
User("张三丰", "男", 25),
User("李文军", "男", 35),
User("郑智化", "男", 40)
)
val userRDD: RDD[User] = spark.sparkContext.parallelize(users)
val userRDD1: RDD[User] = userRDD.filter(user => user.age > 30)
val userRDD2: RDD[(String, Long)] = userRDD1.map(user => (user.name, user.age))
userRDD2.collect().foreach(println)
}
}
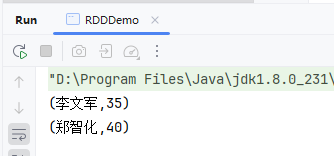
- 运行程序,查看结果
3. DataFrame(数据帧)
3.1 DataFrame概念
- DataFrame 是 Apache Spark 中一种高级的数据结构,以表格形式组织数据,提供了丰富的数据操作功能。与 RDD 相比,DataFrame 能够理解数据的模式,即知道数据存储在哪些列中,以及每列的数据类型。这种结构不仅使得数据操作更加直观和方便,还支持 SQL 查询和多种数据源的读取,极大地简化了数据分析和处理过程。DataFrame 的引入,使得 Spark 在处理结构化数据时更加高效和强大。
3.2 DataFrame优点
- 支持使用 SQL 语句进行数据分析。
- 在大部分数据分析场景下比使用 RDD 更加简洁和方便。
3.3 实战操作
- 在
net.huawei.sql包里创建DataFrameDemo对象
package net.huawei.sql
import org.apache.spark.sql.SparkSession
case class User(name: String, gender: String, age: Long)
object DataFrameDemo {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("SparkSQLTest")
.master("local[*]")
.getOrCreate()
import spark.implicits._
val users = Seq(
User("陈燕文", "女", 30),
User("张三丰", "男", 25),
User("李文军", "男", 35),
User("郑智化", "男", 40)
)
val userDF = users.toDF()
userDF.createOrReplaceTempView("user")
val userDF1 = spark.sql("SELECT name, age FROM user WHERE age > 30")
userDF1.show()
}
}
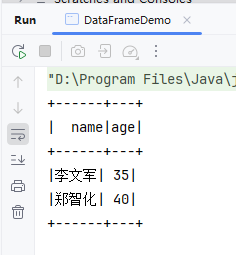
- 运行程序,查看结果
4. 实战小结
- 通过本次实战,我们掌握了 Apache Spark 中 RDD 和 DataFrame 的基本概念和操作。RDD 提供了对分布式数据集的基本操作,适用于需要自定义分区和转换的场景。DataFrame 则为结构化数据提供了更高效的处理方式,支持 SQL 查询和数据分析。在实际应用中,我们可以根据数据特性和处理需求,灵活选择使用 RDD 或 DataFrame。通过对比,我们发现 DataFrame 在处理表格数据时更为直观和高效,而 RDD 在需要细粒度控制时更为适用。